A High Speed FIR Filter Architecture Based on Higher
Radix Algorithm
B. Sagar
P.G. Scholar (M. Tech), Dept. of ECE, Mallareddy Engineering College,
Secunderabad
C. Silpa
Associate. Professor, Dept. of ECE, Mallareddy Engineering College,
Secunderabad
Dr. M. J. C. Prasad
Professor & HOD of ECE, Mallareddy Engineering College,Secunderabad
Abstract – Digital Signal Processing (DSP) is a field of utmost importance as it performs the processing of a digital signal. DSP techniques improve signal quality or extract important information by removing unwanted parts of the signal which is possible with the help of filters. A Finite Impulse Response (FIR) filters play a crucial role in many of the signal processing applications. The output is computed using Multiply And Accumulate (MAC) operations. In a conventional multiplication, the number of partial product rows is same as the number of bits in multiplier. Since the amount of hardware and the delay depends on the number of partial products to be added. The number of partial products can be reduced by using radix algorithm. A FIR filter based on radix-256 booth encoding is implemented which reduces the number of partial product rows in any multiplication by 8 fold. The obtained partial product rows are added using carry free RB addition. Then the RB output is converted back to Natural Binary (NB) form using RB to NB converter. The performance of radix-256 multiplier architecture for FIR filter is compared with computation sharing multiplier (CSHM). The radix-256 multiplication method for FIR filter
is found to be faster in comparison to CSHM
implementation.
Keywords–FIR Filter, Multiplier, Radix-256, CSHM, RB Addition.
I. I
NTRODUCTIONRapid growth in mobile communication systems, wireless communication systems leads to high performance and low power VLSI digital signal processing systems. Filters and other signal processing units used in these systems need to have high speed and low power realization. Finite impulse response (FIR) filters play a crucial role in many signal processing applications due to its absolute stability and linear-phase property. Hence, various architectures and implementation methods have been proposed to improve the performance of filters in terms of speed and complexity.
Since complexity reduction of FIR filter leads to high performance as well as low-power design, authors of [1]-[4] have focused on the implementation of FIR filters with discrete coefficient values selected from the powers-of-two coefficient space. By using add and shift operations FIR filter structure can be simplified. Optimization algorithm is used by Mustafa et. all in [5] to find the coefficients with reduced number of signed-power- of-two. The Differential Coefficients Method is proposed by Sankarayya in [6] and by A. P. Vinod in [7]. This involves using various orders of differences between coefficients, along with stored intermediate results, rather than using the coefficients themselves directly for computing the
partial products in the FIR equation. In [8] authors have tried to implement the FIR filter in cascade form. However the numerical design and optimization of such structure are of much more difficult than the single-stage.
In the present work, simple and high performance FIR filter architecture is proposed. This is based on the Novel Partial product Generation method using Higher radix-256 Booth encoding (NPGHB) which reduces the number of partial product rows by 8-fold. Hence for a 16-bit coefficient multiplication with input, only two rows of partial products will be obtained. The obtained partial product rows are added using carry free RB addition which makes multiplication operation much faster. As the proposed work is based on CSHM algorithm [9], same is discussed in brief in section II. The RB number system and the higher radix booth encoding is discussed in section III. The proposed architecture and its implementation with comparison are discussed in section IV and V. Finally the concluding remark is given in section VI.
II. C
OMPUTATIONS
HARINGM
ULTIPLICATION INFIR F
ILTERA simple filter computation using convolution is given as
Y[n] =∑ x[n − k] (1)
Where f[k]’s filter coefficients and X (n-k) is the input to the filter delayed by k units.
Fig.1. FIR filter transposed form structure
Copyright © 2013 IJECCE, All right reserved obtained by selecting from the outputs of a precomputer
and then shifting as required. Finally a multiplication result of a coefficient with input is obtained by adding the alphabet multiplication results with required shifting.
For illustration of use of CSHM algorithm, a 16-bit coefficient C0 = 1010 1101 1011 0110 can be divided into four alphabets
a3=1010, a2=1101, a1=1011 and a0 = 0110
An alphabet of 4-bit, can have possible decimal values of 0, 1, ----, 14 or 15. All these alphabet multiplications can be obtained from few fundamental alphabet multiplications i.e. 1X, 3X, 5X, 7X, 9X, 11X, 13X and 15X, where X is the input. Hence these fundamental alphabet multiplications are obtained using pre-computer stage as shown in Figure 2. Then based on the alphabets of each coefficient, outputs of pre-computer are selected and finally added to get the coefficient multiplication using select and add units(S &A). For the present illustration, the multiplication of coefficient with X is:
C*X = 212(a3*X) + 28(a2*X) + 24(a1*X) + (a0*X) Here a3*X = (1010)2 = (10)10*X can be obtained by selecting the fundamental alphabet multiplication 5X from precomputer output and shifting by one bit. Similarly all other alphabet multiplications can be obtained by selecting the proper fundamental alphabet multiplication and then shifting as required using the S & A unit. Then alphabet multiplications are aligned properly and then added to get coefficient multiplication of C0 with X.
Fig.2. FIR filter using CSHM algorithm
III. R
EDUNDANTB
INARYN
UMBERS
YSTEM ANDA
RITHMETICB
ASICSA. RB number system
A redundant binary representation (RBR) is a numeral system that uses more bits than needed to represent a single binary digit so that most numbers have several representations. A RBR is unlike usual binary numeral systems, including two's complement, which use a single bit for each digit. Usually, a RBR allows negative values. There is no single sign bit that tells if a RBR represented number is positive or negative. Most integers have several possible representations in an RBR. An integer value can be converted back from a RBR using the following formula, where n is the number of digit and dk is the interpreted value of the k-th digit, where k starts at 0 at the rightmost position.
1 0 2 n kk k
d
The conversion from a RBR to two's complement can be done in O(log(n)) using prefix adder where n is the number of digit.
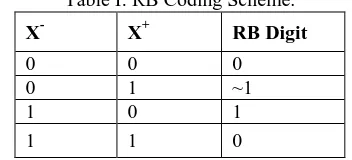
The mostly commonly used coding scheme is show in the Table I which is given below.
Table I: RB Coding Scheme.
X- X+ RB Digit
0 0 0
0 1 ~1
1 0 1
1 1 0
B. Addition of two NB numbers to give RB number
The addition of A and B is expressed as [11]
1
, 1)
(
B A B A B A B A A B
A
Hence this expression indicates that two NB numbers can be added to give the result by just taking the combination of A and complement of B. However to find out the actual value of A+B, 1 is to be subtracted.
C. Addition of two RB numbers
Not all RBR have the same properties. For example, using the translation table on the right, the number 1 can be represented in this RBR in many ways: "01·01·01·11", "01·01·10·11", "01·01·11·00", "11·00·00·00". Also, for this translation table, flipping all bits (NOT gate) corresponds to finding the additive inverse of the integer represented.[12]
dk { -1, 0, 1 }
Carry propagation free addition is performed in two
steps:
1) First step:
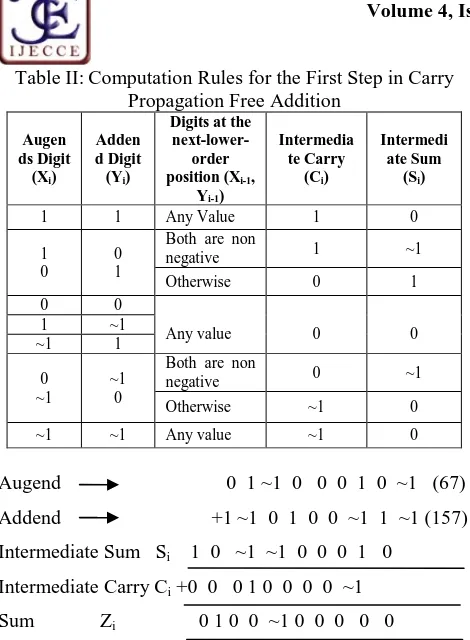
In this step intermediate carry Ci{ ( 1,0, 1)} and the intermediate sum digit Si{ (1, 0, 1)}
are determined to satisfy the equation ai + bi = 2Ci + Si where ai and bi are augends and addend digits, respectively. However Ciand Siare determined such that
both Siand Ci-1are neither 1’s, nor 1’s. Hence the rules for
computation for intermediate sum Siand carry Cilooking
to the augends and addend digit (Xi, Yi) and the digits at the next lower – order position (Xi-1, Yi-1) is given in
Table II.
2) Second step:
In the second step, the sum digit Zi{ (1, 0, 1)} is obtained at each position by adding the intermediate sum digit Si and the intermediate carry Ci-1
Table II: Computation Rules for the First Step in Carry Propagation Free Addition
Augen ds Digit
(Xi)
Adden d Digit (Yi)
Digits at the
next-lower-order position (Xi-1,
Yi-1)
Intermedia te Carry
(Ci)
Intermedi ate Sum
(Si)
1 1 Any Value 1 0
1 0
0 1
Both are non
negative 1 ~1
Otherwise 0 1
0 0
Any value 0 0
1 ~1 ~1 1 0 ~1 ~1 0
Both are non
negative 0 ~1
Otherwise ~1 0
~1 ~1 Any value ~1 0
Augend 0 1 ~1 0 0 0 1 0 ~1 (67) Addend +1 ~1 0 1 0 0 ~1 1 ~1 (157) Intermediate Sum Si 1 0 ~1 ~1 0 0 0 1 0
Intermediate Carry Ci+0 0 0 1 0 0 0 0 ~1
Sum Zi 0 1 0 0 ~1 0 0 0 0 0
Example I: Carry propagation free addition. Thus in redundant binary number system, parallel addition of two numbers by a combinational circuit is performed in a constant time, independent of word length of operands.
D. RB to NB conversion
RB numbers are advantageous because of its unique carry propagation free addition property. However the real world interface must be in NB form. Hence finally the results obtained in RB form must be converted to NB form.
The conversion of an n-digit redundant binary integer Zi
= [zn-1zn-2. . . z0] SD2 where yibelongs to {~1, 0, 1}
into the equivalent (n+1) bit 2’s complement binary integer Ui= [unun-1…..u0] where Uibelongs to {0,1} is
performed by subtracting Zi-from Zi+where Zi+and Zi-are
n bit unsigned binary integers formed from the positive digits and negative digits in Zi, respectively.
Example II: RB to NB conversion
Now the sum (Zi) is converted in to NB form from RB
form. So now the output is natural binary form.
E. Booth encoding for high speed multiplication
In a non Booth conventional multiplication, the number of partial product rows is same as the number of bits in multiplier. An N-bit two’s complement binary multiplier C can be represented as (CN-1 CN-2 ……. C2 C1 C0). The
decimal value of this number will be:
C = -CN-1. 2N-1+∑ . 2I (2)
Booth algorithm [15] divides C into [N/K] groups, each with k-bits using radix-2k encoding. Hence each group of k+1 overlapping multiplier bits are mapped to a singed digits Di, where i = 0, 1, [N/K]-1. The digit Di can be
obtained from k+1 bits, i.e. Di= - C(i.k)+1Ci.k C(i.k)-1where
C(i.k)-1is overlapping bit. This C(i.k)-1is the most significant
bit of the previous digit Di-1 and is zero for i =0. The decimal value of digit Di can be given as:
Di= - Ci.k+k-1. 2k-1+∑ Cj. 2j+ C(i.k)-1 (3)
A digit Difor a radix-2k encoding can take one value
from (-2k-1,-2k-1 +1, …,1, 0, 1, …., 2k-1-1, 2k-1 ). Hence a multiplication of multiplier/coefficient C with multiplicand X can be given as:
C . X =∑[ / ] 2k-1. Di. X
In this 2k-ican be obtained just by shifting. Hence only Di.X has to obtain. A table for different higher radix booth
encoding is given in Table III
Table III: Different Radix Booth Encoding
K Radix 2k
No of PP rows for 16-bit opera nd
Possible Di.X
values
FDMPP required to be computed
2 Radix-4 8 X,0,X,2.X
-2.X,-All can be obtained from X. No FDMPP computation required
3 Radix-8 6
-4.X, -3.X,…,
-X,0,X,…,3.X,4.
X
3.X
4 Radix-16 4
-8.X,-7.X…,
-X,0,X,…,7.X,8.
X
3.X,5.X, and 7.X
5 Radix-32 4
-16.X,-15.X,..,-X,0,X,..,31.X,3
2.X
3.X,5.X,7.X,11.X,13. X and 15.X
6 Radix-64 3
-32.X,-31.X,..,-X,0,X,...,15.X,1 6.X 3.X,5.X,7.X,11.X,13. X,15X,…,27.X,29.X and 31.X 7 Radix-128 3 -64.X,-63.X,…,-X, 0,X,…,63.X,64. X 3.X,5.X,7.X,13.X,15. X,…,59.X,61.X and 63.X 8 Radix-256 2 -128.X,- 127.X,..,-X,0,X,...,127.X, 128.X 3.X,5.X,7.X,…,125.
X and 127.X. Use of RB arithmetic will
Copyright © 2013 IJECCE, All right reserved For various values of k, we can get different higher
radix booth encoding. For k = 3, the encoding is Radix-8 booth encoding. The number of partial product rows will be [16/3] = 6. Hence this need possible partial product values to be obtained are -4.X, -3.X, …,-X, 0, X, …., 3.X, 4.X.
All these can be obtained by shifting from X and 3.X. Hence the fundamental digit multiplied partial product (FDMPP) row need to be computed is 3.X. Similarly for k = 2, 4, 5, 6, 7 and 8 all those values are obtained and noted in Table III. For Radix-256, the number of FDMPP is large.
However the use of RB arithmetic using the proposed algorithm will require only 3.X, 5.X and 7.X as FDMPP as are required in Radix-16.
This also will generate only two partial product rows. Hence, Radix-256 booth encoding is used for the 16-bit input operand.
F. Novel Partial product generation using Higher
Radix-256 Booth Encoding
In the present work a Novel Partial product Generation method using higher radix-256 Booth encoding (NPGHB) is used. Use of this new scheme reduces the number of partial product rows to only two, with small additional complexity. For generating the partial product rows, addition of S-groups and T-groups, is used. Hence the four partial product rows generated using radix-256 can be added using RB adders in three stages. This reduces both delay and hardware requirement.
In radix-256 encoding, the binary number in two’s complement form is partitioned to overlapping group of nine bits to form digit Di. This Dican have one of the 257
values from –128, -127…-1, 0, 1… 127, 128. The partial product generation for digit Di in the form of 2m (where m=1, 2, 3, 4, 5, 6, 7) is easy, as can be obtained just by shifting. Generation of other partial products for digits, like 3, 5, 7, 9, 11, ---, 127 will be difficult. In the present work all partial products corresponding to different digits Di in RB form are generated by only adding a S-group digit multiplied partial product(SGDMPP) with T-group digit multiplied partial product(TGDMPP). The SGDMPP are ZERO, X, 2X, 3X, 4X, 5X, 6X, 7X, 8X and the TGDMPP are ZERO, 16X, 32X, 48X, 64X, 80X, 96X, 112X, 128X. All SGDMPP and TGDMPP coefficients are obtained from the nine bits of the digit Di using the algorithm given below.
Algorithm
The following is the algorithm to find the fundamental S-group and T-group digits to represent a digit Di.
Assume the digit D0 is made of lower eight bits of
coefficient and an overlapping bit C7C6C5C4C3C2C1C0C-1.
Here S-group and T-group are temporary variables to store intermediate value. The S_digit and T_digit are the final digit values.
S-group = 4 * C2+ 2 * C1+ 1 * C0+ 1 * C-1
T-group = 16 * (4 * C6+ 2 * C5+ 1 * C4+ 1 * C3)
If C7= 0 and C3= 0
Then S_digit = S_group and T_digit = T_group else if C7= 0 and C3= 1
Then S_digit = S_group-8 and T_digit = T_group else if C7= 1 and C3= 0
Then S_digit = S_group and T_ digit = T_group-128 else if C7= 1 and C3= 1
Then S_digit = S_group-8 and T_ digit = T_group-128 End
An example of multiplication using radix-256 encoding is given below
Here inputs are X and Y, where
Y = 206 =00000000000000000000000011001110. This coefficient can be grouped into four digits with D0=
-50, D1= 1, D2= 0, D3= 0.
Hence Y = 232.D3+2 16
.D2+2 8
. D1+ D0and
Y.X = 232. (D3.X)+216. (D2.X)+28.(D1.X) + (D0.X) Here D0.X can be obtained by adding -2X (the SGDMPP) with - 48X (the TGDMPP). This SGDMPP can be obtained by shifting -X, 4-bit position. Similarly the TGDMPP can be obtained by shifting -3X by 3-bit position.
Similarly D1.X also can be obtained by selecting proper
SGDMPP and TGDMPP and grouping them for addition. Finally D0.X, and D1.X shifted by 8-bit positions are added
using RB adders.
IV. P
ROPOSEDFIR F
ILTERA
RCHITECTUREB
ASED ONNPGHB
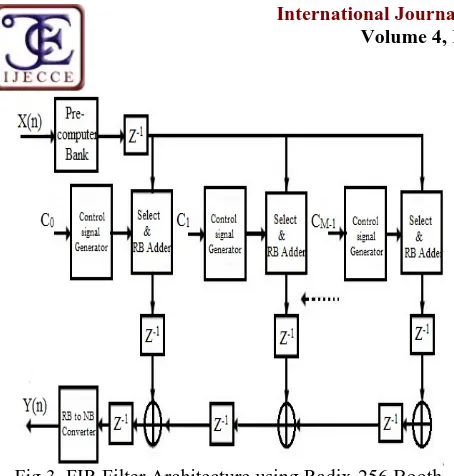
The architecture of improved FIR filter using CSHM multiplier with RB arithmetic and Radix-256 encoding is given in Figure 3. The input to this filter is X and the coefficients at each tap point are C0, C1… CM-1. Both input
and the coefficient are assumed to be of bits. Each 16-bit coefficient is grouped in to two digits D0 and D1. To
generate a DMPP, D0.X or D1.X, a SGDMPP need to be
subtracted from a TGDMPP. The SGDMPP and TGDMPP are obtained from FDMPP. The FDMPP are generated using a precomputer stage.
To select proper SGDMPP and TGDMPP from all FDMPPs, control signals are generated using control signal generator from the bits of digit Di. The select and add unit consists of a select unit and a RB adder. The selector selects proper SGDMPP and TGDMPP from FDMPPs, which forms the DMPP in RB form.
The two DMPPs, D0X and D1X shifted by 8-bit
Fig.3. FIR Filter Architecture using Radix-256 Booth Encoding and RB Adder
A. Precomputer
The precomputer, computes Fundamental Digit Multiplied Partial Products (FDMPPs) i.e. -1X, 3X, -3X, 5X, -5X, 7X and -7X. From these all other SGDMPP and TGDMPPs can be obtained by proper shifting. The computation for these basic FDMPPs is given in table 4. All of them are implemented using ripple carry adder except -5X computations. To have uniform propagation delay for all FDMPP computations in pre-computer -5X is implemented using square root select adder.
Table IV: All FDMPP Computation method used in Precomputer
FDMPP Computation method
-X ~X+1
3X X<<1+1
-3X X+~(X<<2)+1
5X X<<2+X
-5X ~5X+1
7X X<<3+~X+1
-7X X+~8X+1
B. Control Signal generator
A DMPP corresponding to digit Di can be obtained by selecting proper SGDMPP and TGDMPP and the grouping them for subtraction. For proper selection of SGDMPP and TGDMPP, specific control signals need to be given to selector unit of select and add unit.
These control signals are obtained by control signal generator using the bits of digit. For a digit Di =
C7C6C5C4C3C2C1C0C-1, the Boolean expression of the
control signals which will select one each from TGDMPP (16X, 32X, 48X, 64X, 80X, 96X, 112X,128X) and SGDMPP (-8X, -7X, …..,-1X, 0, 1X, ……,7X,8X) can be obtained using the booth encoding algorithm.
C. Selector
Selector is a part of select and add unit. This selects one SGDMPP and other TGDMPP based on select signal for generation of a DMPP. The S-selector and T-seletor circuits for getting single bit of a RB digit of DMPP are shown below.
(a)
(b)
Copyright © 2013 IJECCE, All right reserved Here PTiand Psiare pair of bits corresponding to the ith
RB digit of first row of partial product row corresponding to digit D0. In this work, the coefficient is considered of
16-bits, hence for two digits D0and D1, two select units
are needed for generation of two RB partial product rows.
D. RB Adder
A RB adder has unique characteristic of carry propagation free addition. This is implemented using the algorithm given in Table II. RB adders are used in two places of FIR filter. First the two DMPPs are obtained in RB form. Then, from the selector circuits, these are added using RB adder and latched in registers. Then in the next clock cycle the multiplication result of one tap point and the previous tap point are added using RB adders.
E. RB to NB Converter
To convert the final output of FIR filter into NB form, RB to NB converter is used. This can be implemented using a carry look ahead adder.
V. I
MPLEMENTATION ANDC
OMPARISONAn 11-tap FIR filter using the proposed architecture was implemented. An 11- tap FIR filter based on CSHM architecture have also been implemented and compared in terms of delay. In the verification process identical inputs are used for both the architectures.
A. Implementation method used for FIR filter
The FIR filter using the NPGHRB and RB arithmetic is implemented at gate level using Verilog coding. The functionality of the filter architecture was verified for large number of random input patterns using Xilinx ISE simulator. Then the architecture is synthesized using Xilinx XST. Same methodology and technology is also used to synthesize FIR filter based on CSHM architecture. The post synthesis layout results are summarized in Table V.Table V: Post Synthesis Results. Filter Based on Delay(T) in ns
NPGHB 33.63ns
CSHM 40.761ns
B. Post synthesis results and comparisons
After synthesizing the proposed architecture, the delay summary is obtained. Based on delay summery, the critical delay (T) is found to be 33.63ns in proposed architecture. The critical delay for filter based on CSHM is found to be the 40.761ns. Hence the proposed filter architecture is faster than the filter based on CSHM implementation.
In the proposed architecture the critical delay path is, through select and RB Adder to the latch where the coefficient multiplied input in RB form is stored. As control signals for selection purpose are already available and RB addition is carry free addition, the delay is small in the proposed architecture. However in terms of area (A) and power (P) the proposed architecture is slightly consuming more than CSHM implementation. This is
because of the hardware expensive RB adders used in our architecture. For high speed applications in digital signal process (DSP), this architecture can be used.
VI. C
ONCLUSIONAn FIR filter based on NPGHB and RB arithmetic is proposed. The use of radix-256 reduces the number of partial product rows in any multiplication by 8 fold. Thus a multiplication of 16-bit input results only two partial product rows in RB form. The obtained partial products in RB form are added using RB adder, which is much faster as no carry propagation occurs. The proposed multiplication method based on NPGHRB for FIR filter is found to be faster in comparison to CSHM implementation. This can be used to implement DSP algorithms for high speed applications.
R
EFERENCES[1] Y. C. Lim, S. R. Parker, and A. G. Constantinides, “Finite word
length FIR filter design using integer programming over a
discrete coefficient space,” IEEE Trans. Acoustics, Speech
Signal Processing,vol. ASSP-30, pp. 661–664, Aug. 1982. [2] Y. C. Lim andS. R. Parker, “FIR filter design over a discrete
power-of two coefficient space,” IEEE Trans. Acoustics, Speech
Signal Processing, vol. ASSP-31, pp. 583–591, June 1983. [3] H. Samueli, “An improved search algorithm for the design of
multiplier less FIR filter with powers-of-two coefficients,” IEEE
Trans. Circuits Syst. vol. 36, pp. 1044–1047, July 1989. [4] Hai Huyen Dam, Cantoni A., Kok Lay Teo, Nordholm S.,"FIR
Variable Digital Filter With Signed Power-of-Two Coefficients," IEEE Transactions on Circuits and Systems I, Volume: 54 , Issue: 6, pp. 1348 - 1357, June 2007.
[5] Mustafa Aktan, Arda Yurdakul, and Günhan Dündar. "An Algorithm for the Design of Low-Power Hardware-Efficient FIR Filters," IEEE Transactions on Circuits and Systems I, VOL. 55, NO. 6, pp. 1536-1545, JULY 2008.
[6] N. Sankarayya, K. Roy, and D. Bhattacharya, “Algorithms for
low power and high speed FIR filter realization using differential
coefficients,” IEEE Trans. Circuits Syst., vol. 44, pp. 488–497, June 1997.
[7] Vinod A.P., Singla A., Chang C.H., "Low-power differential coefficients-based FIR filters using hardware-optimised multipliers, " IET, Circuits, Devices & Systems, Volume: 1 Issue:1, pp.13-20, February 2007.
[8] Dong Shi, Ya Jun Yu, "Design of Discrete-Valued Linear Phase FIR Filters in Cascade Form," IEEE Transactions on Circuits and Systems I, Volume: 58 , No. 7, pp. 1627 - 1636, July 2011. [9] Jongsun Park, Woopyo Jeong, Hamid Mahmoodi-Meimand,
Yongtao Wang, Hunsoo Choo, Kaushik Roy., Computation sharing programmable fir filter for low-power and high-performance applications. IEEE Journal of Solid-State Circuits. 2004, 39: 348-357.
[10] Avizienis, “Signed-digit number representation for fast parallel
arithmetic,” IRE Trans. Electron. Computer., vol.EC-10, pp. 389-400, Sept.1961.
[11] N. Takagi, H. Yasura and S. Yajima., “High-speed VLSI
multiplication algorithm with a redundant binary addition tree,”
IEEE Transactions on Computers, C-34(9 ): 217-220, Sept.1985. [12] S. Kuninobu, T. Nishiyama, T. Edamatsu, T. Taniguchi, and N.
Takagi, “Design of high speed MOS multiplier and divider using redundant binary representation,” In Proc. 8th Symp. Computer
Arithmetic, Italy, pp. 80-86, May 1987.
[13] A.D. Booth, “A signed binary multiplication technique,”
Quarterly J. Mech. Appl. Math, Vol. 4, Part 2, pp. 236-240, 1951.
[15] Y. Harata, Y. Nakamura, H. Nagese, M. Takigawa, and N.
Takagi, “A high-speed multiplier using a redundant binary adder
tree,” IEEE J. Solid-State Circuits, Vol. 22, pp. 28-34, Feb. 1987.
A
UTHOR’
SP
ROFILEB. Sagar
is presently pursuing final semester M.Tech in Digital Systems & Computer Electronics at Mallareddy Engineering college, Secunderabad. He received degree B.E in Electronics and communication From SSIT. His areas of interest are Signal Processing, VLSI, DSP algorithm And Architecture.
C. Silpa
is presently working as a Associate Professor in the department of Electronics and Communication Engineering, MREC, Secunderabad, Andhra Pradesh, India. She is having 7 years of teaching experience. Her areas of interest are Communication systems, Network security, Image Processing. Digital signal processing.
Dr. M. J. C. Prasad