Research Article
a
October
2017
Computer Science and Software Engineering
ISSN: 2277-128X (Volume-7, Issue-10)
Evaluation of Project Work Using Clustering and Pattern
Mining of Online Collaborative Data
Nikitaben P. Shelke, Poonam Gupta
Computer Engineering, GHRCEM, Savitribai Phule Pune University, Pune, Maharashtra, India
Abstract— Group work is widespread in software development life cycle. The huge data can be generated by increasing use of online tools which supports group work. The aim is to exploit this group data to evaluate performance with the presentation of constructive high-level views of information about the team, along with desirable patterns identifying the behavior of strong groups. The key purpose of this work is to facilitate the groups and their coordinators, so that they can observe the applicable aspects of the software team’s functions, provide feedback and point out where are the issues. The context for this work is software development project where team members use online collaborative tools. The clustering and pattern mining techniques can be useful to explore the possibilities of finding the patterns distinguishing strong group from weaker group and get the vision of the factors such as importance of leadership and effective team interaction, which could lead to the success of group. The results can be helpful to offer recommendations for potential and poor practices at the early stages accompanied with remediation of poor practices.
Keywords— Clustering, Educational Data Mining, Group Work, Pattern Mining, Online Collaboration
I. INTRODUCTION
Group work has very common part in almost all aspects of life, particularly in the place of work where there are situations that involve small groups of team members to work collectively to accomplish a goal. For example, an assignment that requires multifaceted skills may only be completed if a team of members, with diverse skills, works together. One more example, in a given strict deadline of any assignment, it may be necessary to combine efforts of a group of people to achieve a task before the deadline. However, there is an issue with the effective group operation to achieve productivity and satisfaction within group. There has been huge research on how to achieve high productivity in group work along with satisfaction among group members and how to train team members to learn relevant skills.
The context can be e-workers, iWorkers, or Web Workers, where the group members are distributed and they use the software to support their collaboration. Along with these remote workers the team members who work in premises of the organization, they must also be supported by a range of online collaborative tools, such as e-mail, chat, webinars, online meetings and wikis. These types of tools can build up huge amount of data and generate huge electronic traces of their utilization over a period of time. This data can be used to reflect the importance of group work at workplace.
This paper road map is arranged as follows: Section 2 states survey of papers describing the efficiency, drawbacks of work done till time. Section 3 explores the input data of online collaborative tools to be used for the further analysis. Section 4 has includes the proposed method for the analysis the collected data. Then, section 5 concludes this paper.
II. RELATED WORK
The research community of data mining has emerged in such a way which exploits the data from the communication among different people using online collaboration tools [1][2]. Range of techniques of data mining techniques are getting used for promising results [3][4][5]. The area of data mining is establishing the new requirements for efficient mining and analysis of collaborative data. This paper is in the continuation of exploring the base for this area, taking context of group work using online collaboration.
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 65-69
Talavera and Gaudioso [6] have presented some preliminary experiments for evaluation of collaborative activities to reflect the user behaviors with the help of clustering and the results were motivating for the further research avenues in several directions [6]. Data in this study was collected using LMS from 3 online tools: forums, chat, and e-mail services. The main point noticed in this study is that some add-on information might have enhanced their results, viz., passive interactions [6].Further research and experiential facts were needed in order to be more selective on the type of data needed and to relate this selection to particular pedagogical settings or goals [6].
J. Perera, Judy Kay [7] has done the experiment of extraction of patterns which differentiate the strong group or individual from the weaker one and identify the success factors. The results of clustering and sequential pattern mining which shows the significance of group communication as well as leadership [7], and it also shows potential indications of their occurrence [7].Their work has highlighted some of the data mining challenges of the educational data; such as temporal, noisy, correlated, incomplete data. The quality of the data is essential, e.g., one of the groups was reluctant to use the ticketing system, which resulted in non-representative ticketing data; this can be alleviated by better linking of the course assessment to the use of the system[7].
Shelke and Gadage[8] have analyzed different data mining approaches available for performance evaluation. The data mining techniques discussed are clustering, sequential pattern mining, classification, decision tree, and text mining. The authors have done extensive literature review on this topic of performance analysis and evaluation.
III. INPUT DATA EXPLORATION
The data has been collected from the Apache community of open-source software projects. The Apache projects are defined by collaborative based processes. The data include SVN, Issue Tracking, and E-mailing archive list. This includes the electronic traces of activities performed by the users who all are working on these 3 online collaborative tools. The logs of each of these events are stored including time and group The data has been collected from the Apache community of open-source software projects. The Apache projects are defined by collaborative based processes. The data include SVN, Issue Tracking, and E-mailing archive list. This includes the electronic traces of activities performed by the users who all are working on these 3 online collaborative tools. The logs of each of these events are stored including time and group.
A. SVN
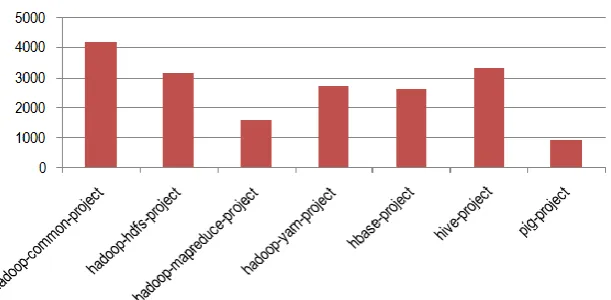
One of the three tools considered here is SVN (Subversion) repository. SVN is the version control system which stores the collection of files for any software creation or changes made over the period of time. Each group or project team has its own SVN repository. Each project team or group has number of SVN committed (i.e. either the full changes happen as expected or it is rolled back). The data we have collected has total number of SVN committed by each member of each project team as well as the total number of group-wise SVN count. Following are the data statistics of the SVN system, considered in the project:
Fig. 1 : Total SVN Count (project-wise) Considered for the Project
Here, there is an assumption that the extensive use of SVN system will be done by the effective group or project team. The patterns emerging, after the analysing the use of SVN system by various members individually in addition to as a project group collectively, can help discover the effective ways to work with online collaborative tool SVN.
B. Issue Tracking System
tracking system has the ability to keep the track of status of the jira created for any type of task. The task can be the change request from client or a bug fix. Following are the number of jira counts of the issue tracking system considered in the project:
Fig. 2: Total JiraCount (project-wise) Considered for the Project
Here, there is an assumption that the strongest project team will have highest number of jira count. However, there are other factors to consider such as jira type and the jira priority because the lower priority jira may be completed in shorter time and if any project team work only on low priority jira then they will have high number of jira count. Hence, only jira count should not be considered. Hence, the jira data collected here has few parameters as well such as jira_count, jira_type, jira_priority, watches, and votes. These parameters are important for the analysing the effective patterns to be followed by the effective individual member as well as a whole project team.
C. E-mail:
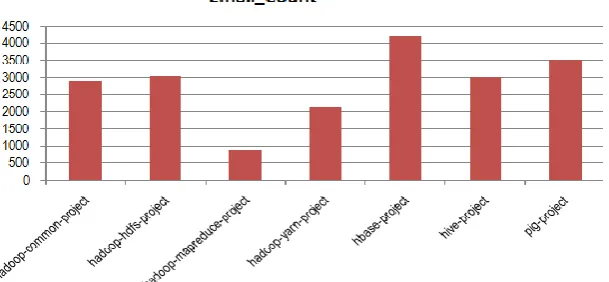
The third tool used is the e-mailing system. The total number of the emails sent by individual team member as well as for the whole project team. Following are the number of e-mail counts of the issue tracking system considered in the project:
Fig. 3: Total E-mail Count (project-wise) Considered for the Project
These three tools contribute to significant collection of data useful for the project work evaluation on individual and project group basis. These tools have high web presence and the electronic footprints created from these tools will help to find the clusters of similar behaviour team members and teams as well as discover the meaningful patterns.
IV. PROPOSED METHODOLOGY
A. Proposed Objectives:
1) A system will be developed which will be helpful to evaluate the project work performed by different teams by integrating different collaborative tools and their respective parameters.
2) This proposed system will be used by team members to analyze and reflect on their approach and facilitators or trainers to have an overview of approach of team members‟ work and where to focus on their training efforts to develop the relevant skills.
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 65-69 B. Proposed System Flow
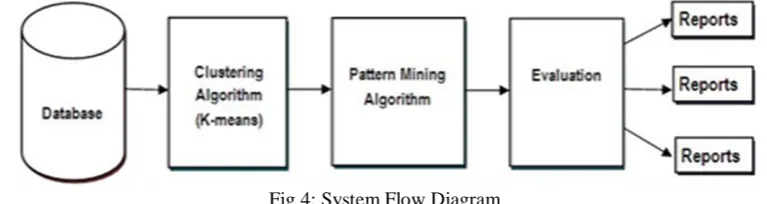
The proposed system flow diagram is as follow. The various modules of this flow diagram have been described in this section.
Fig 4: System Flow Diagram
1) Database:The database mainly stores the information about the events as well as logs from system where the different online collaborative tools are used by the users. Evaluation system will also point to the same database so that the algorithm can be run on same database and less burden of the database synchronization can be achieved.
2) Clustering: The given algorithm clusters the observations or events into „k‟ groups, where input parameter will
be „k‟. Now, based upon the proximity of the observations to the mean on cluster, it will then assign each observation to clusters. The mean of cluster is then re-calculated and the process begins again creating the loop till the result is achieved. It partitions the „n‟ number of sets into „k‟ clusters and work on the greedy algorithm concept. A clustering possibly can be used to identify different styles of groups, which may benefit from different styles of intervention. However, this kind of analysis for small groups can only be done by the facilitator. As a main clustering algorithm, k-means algorithm is selected, which is the most popular. It is also simple, effective, and relatively efficient [9], [10].
3) Pattern Mining: A data mining technique that considers this temporal aspect is pattern mining. It finds interesting or useful patterns occurred in the given data set with minimum level of occurrences called support [11]. Pattern mining has been previously used in e-learning although for different goals than others: to support personalized course delivered based on the learner characteristics [12] and to recommend sequences of resources for users to view in order to learn about a given topic [13].
C. Attributes:
The attribute selection is very crucial part before the start of the clustering algorithm. If the quality of attributes is good then performance of the clustering algorithm will be improved. The attributes for clustering the group as well as individual team member for 3 online collaborative tools are under consideration. The attributes under consideration are email_count, svn_count, watches, votes, jira_count, jira_type and jira_priority
D. Algorithm:
1) K-means Algorithm: The K-means algorithm works in the following three steps:
The algorithm starts with some n-dimensional vectors representing points in n-dimensional space. As input, a set of k vectors can be taken representing the centroids of the clusters.
With a loop, the cluster vectors are moved until a minimum threshold or a number of iterations have been done.
The initial centroids can be chosen from some initial points or randomly. The power of the K-means algorithm is due to the fact that even if random initial centroids are chosen, the output can be displayed. [14].
2) Pattern Mining Algorithm: The algorithm works by using a divide and conquer strategy. In the first part, it creates a list of frequent items ordered by their frequency in descending order, so from the most frequent item present in all transactions to the one that is least present [14]. The second part is the recursive construction of the so-called Frequent Pattern Tree or FP-tree. The FP-tree is a particular type of graph structure where a principal node (sometimes called the root node) and all the other nodes are edged with this principal one [14]. The steps of the algorithm are as shown below:
Read the frequency items file
Read the frequency patterns file and compute the support and confidence values for the set of items involved in the transaction, for every single transaction
V. CONCLUSIONS
Thus, the conclusion is that this project will enable us to provide the facility to evaluate the performance and give regular feedback to team members if their work efficiency is more likely to be associated with productive or negative results. These patterns can be useful to help the individual to evaluate himself and find the poor practices for the work behavior. This system will help to automate the identification of the most salient patterns and rectify the ineffective patterns of collaborative system for more effective work patterns.
ACKNOWLEDGMENT
I am thankful to my project guide Prof (Mrs.) Poonam Gupta for her constant encouragement and expert guidance. I am also thankful to Prof. (Dr.) J. B. Sankpal, Director of G.H. Raisoni College of Engg. & Mgmt, Prof. (Mrs.) Vidya Dhamdhere, Coordinator, Post Graduate Programme, Computer Engineering Department, for their valuable support.
REFERENCES
[1] Educational Data Mining Events, http://www.educationaldatamining.org/EDM2012/ , 2012 [2] Educational Data Mining, http://www.educationaldatamining.org, 2008.
[3] Merceron and K. Yacef, “Clustering students to Help Evaluate Learning” Technology Enhanced Learning, J.-P. Courtiat,C. Davarakis, and T. Villemur, eds., vol. 171, pp. 31-42, Springer, 2005.
[4] C. Romero, S. Ventura, C.d. Castro, W. Hall, and N.H. Ng, “Using Genetic Algorithms for Data Mining in Web-Based Educational Hypermedia Systems” Proc. Workshop Adaptive Systems for Web-Based Education, 2002.
[5] R. Mazza and V. Dimitrova, “CourseVis: Externalising Student Information to Facilitate Instructors in Distance Learning”Proc. 11th Int’l Conf. Artificial Intelligence in Education (AIED), 2003
[6] L. Talavera and E. Gaudioso, “Mining Student Data to Characterize Similar Behavior Groups in Unstructured Collaboration Spaces” Proc. 16th European Conf. Artificial Intelligence (ECAI), 2004.
[7] D Perera, J Kay, I Koprinska, K Yacef, and OR. Zaiane,- “Clustering and Sequential Pattern Mining of Online Collaborative Learning Data” in IEEE Transactions On Knowledge And Data Engineering, (vol. 21 no. 6) pp. 759-772, June 2009
[8] Shelke and Gadage, International Journal of Advanced Research in Computer Science and Software Engineering 5(4), April- 2015, pp. 456-459
[9] P.-N. Tan, M. Steinback, and V. Kumar, Introduction to Data Mining, Pearson Addison Wesley, 2006.
[10] I. Witten and E. Frank, “Data Mining: Practical Machine Learning Tools and Techniques” Morgan Kaufmann, 2005.
[11] J. Kay, N. Maisonneuve, K. Yacef, and O. Zaı¨ane, “Mining Patterns of Events in Students‟ Teamwork Data,”
Proc. Workshop Educational Data Mining at the Eighth Int’l Conf. Intelligent Tutoring Systems, C. Heiner, R. Baker, and K. Yacef, eds.,pp. 45-52, 2006.
[12] W. Wang, J.-F. Weng, J.-M. Su, and S.-S. Tseng, “Learning Portfolio Analysis and Mining in SCORM Complaint Environment,” Proc. 34th ASEE/IEEE Frontiers in Education Conf. (FIE), 2004.
[13] D. Cummins, K. Yacef, and I. Koprinska, “A Sequence Based Recommender System for Learning Resources,”