2017 2nd International Conference on Artificial Intelligence: Techniques and Applications (AITA 2017) ISBN: 978-1-60595-491-2
A Lip Reading System Based on OLSDA
Yuan-yao LU, Ying CAI* and Qing-qing LIU
School of Electronic and Information Engineering, North China University of Technology, Beijing, China, 100144
*Corresponding author
Keywords:Lip reading, Geometrical model, OLSDA, SVM.
Abstract.Lip features extraction is a very crucial part in lip reading system, accurate and effective features can promote the recognition rate of system. In this paper, we propose a features extraction method which is based on geometrical model and Optimized Locality Sensitive Discriminant Analysis (OLSDA). First, the key points in the lip area are extracted artificially, lip visual features are obtained by mathematical treatment. Then, the dimension of these features are reduced by OLSDA and processed features maintain the ability of recognize. We verify the method by SVM classifier and experimental results show that this system has a high recognition rate.
Introduction
Lip reading is a technology that comprehends discourse content by speaker’s lip movement sequence. Like audio channel in Automatic Speech Recognition, lip movement sequence in lip reading is a video channel of comprehend the human discourse. Automatic lip reading has been paid widely attention in pattern recognition, human-computer interaction and artificial intelligence, because its application in behavioral analysis, speaker recognition and face recognition [1].
Features extraction and classification are essential steps of automatic lip reading system. Features extraction consists of three ways. The first way is geometric model based on lip contours; the second way is based on pixel; the third way combines the above two methods. In recent years, the mainstream features extraction is pixel-based methods. However, there is great research potential in features extraction method of geometric model based on lip contours. In this paper, we combine two methods to get more accuracy result. In the first place, we extract the geometric model of lip contour, then reduce dimension by the pixel-based method.
For the geometrical model of lip contour, the key points of contour need to be found artificially, and then obtain lip features by mathematical treatment. Artificial calibration and measurement can get the data accurately and avoid the unnecessary mistakes. E. Petajan et al. [2] first proposed that feature vector is extracted by the geometrical model, they extracted width, height and area of lip as features. In many later years, more researchers studied the shape model of lip and proposed different methods to get features. S.L. Wang et al. [3] chose width and height of lip, Active Shape Model (ASM) and the open-close degree of lip as features for lip reading. S.S. Morade et al. [4] found that width, height and area have most information in geometrical features. Therefore, the variations of parameters between adjacent frames (height difference, width difference and area difference of lip) are used as feature vector. However, little research considers lip contour curve and geometrical features together as feature vector. Thus, this paper does research from this aspect.
performances. But some extreme cases may happen, such as the sample cannot find near neighbors and result in decreasing the performance of LSDA. Meanwhile the weight matrix is also improved. In the recognition phase, SVM is used as classifier.
Preprocessing of Lip Movement Sequence
[image:2.612.105.502.182.233.2]In order to get the lip area as less interference as possible, we need to preprocess the lip movement sequence before extracting the features. Figure 1 shows the flowchart of lip reading system.
Figure 1. Lip reading system.
Extraction of Key Frames
The time duration varies with difference of pronunciation, this results in the different number of frames in each pronunciation. We need to set the length of pronunciations to be consistent so that the size of feature vector of each pronunciation is consistent. First we obtain the time of each pronunciation through segmenting the sample videos, and then divide the time duration to 10 same parts as the key frame of each pronunciation. Thus, each pronunciation is expressed by 10 images and the size of feature vector is consistent.
Face and Mouth Localization
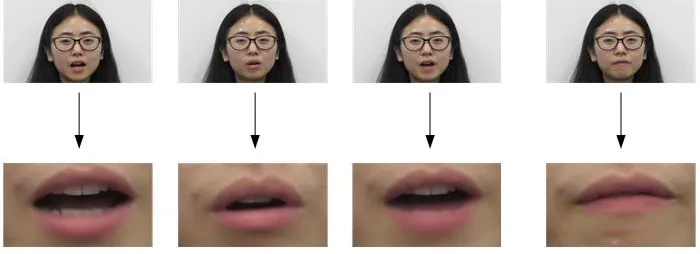
After extracting the key frame, we research face detection and lip area localization and segmentation. We use Adaboost cascade classifier which combines Haar-like feature by Viola and Jones [12]. The performance of this method has been confirmed that better than most facial recognition methods. According to the physical structure of human face, we choose the bottom 1/3 of face as lip area [13]. The obtained lip areas are shown in Figure 2.
Figure 2. Lip detection.
Features Extraction
Features Extraction Based on Geometrical Model
[image:2.612.131.481.452.579.2] + + = + + = + + = 3 2 2 1 3 3 2 2 1 2 3 2 2 1 1 c x c x c y b x b x b y a x a x a y (1)
take the 9 parameters in the curves as the shape feature vector V1, shown as:
) , , , , , , , ,
( 1 2 3 1 2 3 1 2 3
1 a a a b b b c c c
V = (2) To provide more information for classifier, we also select the aspect ratio of lip R1, the height ratio of upper and lower lip R2, the perimeter of lip contour P and the area of lip S as the geometrical feature vector V2:
) , , , ( 1 2 2 R R P S
V = (3) R1 and R2 contain the information of the openness of the mouth as well as avoid the problem of normalizing the lip images. P and S add the feature information of the variation of lip shape. We combined the feature vectors V1 and V2 as the lip visual feature V:
) , (V1V2
V= (4)
Reducing Dimensions of Feature Vector Based on OLSDA
A review of LSDA. In this section, we will introduce LSDA briefly. LSDA is a features extraction method with supervised manifold learning. It can display discrimination ability and geometric structure of high dimensional data compared with the traditional unsupervised manifold learning because of utilizing label information of the samples. The main frame of LSDA is based on two graphs: within-class graph Gw and between-class graph Gb. Gw contains sample point and their near neighbors in the same class, Gb contains sample point and near neighbors in the different class. Ww,ij and Wb,ij are weight matrix of Gw and Gb respectively.
∈ ∈ = otherwise x N x or x N x if
Wbij i b j j b i , 0 ) ( ) ( , 1
, (5)
∈ ∈ = otherwise x N x or x N x if
Wwij i w j j w i
, 0 ) ( ) ( , 1
, (6)
where Nb(xi) and Nw(xi) denote k near neighbors of between class and within class.
Assume that take y=(y1,y2,...,ym)T as a mapping which makes the within-class graph and between-class graph in a plane, makes the points in Gw as close as possible and the points in Gb as distant as possible. This map can simplify as following equations:
− −
∑
∑
j i ij b j i j i ij w j i W y y W y y , , 2 , , 2 ) ( max ) ( min (7)There exists a project-vector a makes yi=aTxi. In the case of conforming to the constraint condition aTXDwXTa=1, the objective function can simplify as:
a X W L
X
aT b w T
a ( (1 ) )
max
arg µ + −µ (8)
a X XD a X W L
X(µ b+(1−µ) w) T =λ w T (9)
OLSDA. The aim of LSDA is to find out data points in its k near neighbors to structure within-class graph and between-class graph. But in case of special status, for instance, we cannot find near neighbors of sample point in the same class. That makes it is impossible to minimize the within-class distance, the performance of LSDA is affected. Therefore we improve LSDA through determining the number of within-class and between-class near neighbors artificially, instead of determining the holistic k number of near neighbors to divide into within-class points and between-class points. We structure the near neighbors of within-class graph and between-class graph respectively. The number of near neighbors in the same class and near neighbors in the different class are all set to n, n is a constant. From this, for arbitrary point xi, it can obtain n near neighbors with the same label and n near neighbors with the different labels.
If the number of sample c of class xi is less than n, we take c as the number of near neighbors of sample point within-class graph as well as between-class graph because we can’t get n near neighbors in the same class. The number of different class of training data may be different. In order to make data samples of each class has the same importance, we improve LSDA by changing the weight matrix:
≥ ∧ ∈ ∈ < ∧ ∈ ∈ = otherwise n c x N x or x N x n c x N x or x N x c n
W i b j j b i
i b j j b i ij b , 0 )] ( ) ( [ , 1 )] ( ) ( [ , /
, (10)
≥ ∧ ∈ ∈ < ∧ ∈ ∈ = otherwise n c x N x or x N x n c x N x or x N x c n
W i w j j w i
i w j j w i ij w , 0 )] ( ) ( [ , 1 )] ( ) ( [ , /
, (11)
Experimental Result
Data
This paper established an audio-video database that includes the English digits from zero to nine, and it is applied to lip reading. The resolution of video is 1920*1080 and frame rate is 25 frames per second. We choose 21 groups for experiments. (11 groups for training and 10 groups for testing in recognition phase)
Features Extraction
After obtaining the lip area by Adaboost algorithm, we get 9 parameters of lip contour curves as geometric features through fitting the key points of lip. The shape features includes aspect ratio of lip, height ratio of upper and lower lip, perimeter and area of lip contour. Hence, the 13 parameters are extracted as the lip visual features. Because the each utterance is represented by 10 frames and 21-group utterance is used, so the dimension of original feature vector is 210*130. (including 10 different classes, each class corresponds to one of utterance) We use respectively LSDA and OLSDA to reduce dimension and compare their performance.
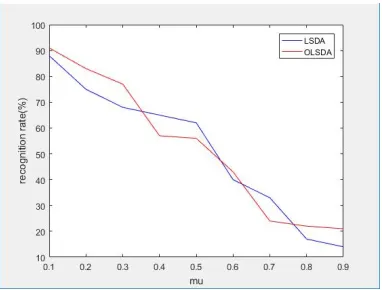
Figure 3. Classification accuracy based on LSDA and OLSDA against the parameter µ.
[image:5.612.104.506.223.383.2]
(a) (b)
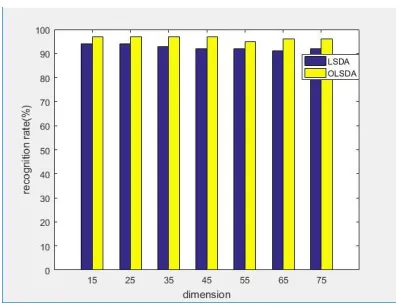
Figure 4. Classification accuracy against the number of near neighbors: (a) the whole number of near neighbors k; (b) the number of within-class near neighbors n (also between-class near neighbors).
Recognition
Hidden Markov model (HMM) is a classifier which is the most widely used in lip reading, but HMM needs a large number of samples for training. Due to the limited database, HMM is not applicable. SVM is also mainstream identification method and suit the condition of small data, has better performance. So SVM is used as classifier in this paper.
Table 1 demonstrates the best results of three different methods. Recognition rate based on the original feature vector is only 79%. After reducing dimension by LSDA, the result rises to 94% and the feature vector has a dimension of 25. The OLSDA method has the best result that classification accuracy is 97%. The experiment shows that OLSDA is the practical method for reducing dimensions and has the better results.
Table 1. The recognition rate of each feature.
Feature Original feature vector Dimension reduction
based on LSDA
Dimension reduction based on OLSDA
Dimension 130 25 25
Recognition rate (%) 79 94 97
Figure 5. The changed tendency of classification accuracy.
Conclusion
In this paper, we have extracted the lip visual features and proposed an optimized methodology (OLSDA) to reduce the dimension of feature vector for lip reading. This method solves influence on the uncertainty of the number of within-class and between-class near neighbors. Moreover, the unbalance data can be solved by OLSDA. SVM is applied as classifier. Compared with original feature vector, dimension reduction based on LSDA and OLSDA, OLSDA is more effective method to reduce dimension. There are still many aspects to be studied and the lip reading system will be widely used in the future.
Acknowledgment
The research was supported by the National Natural Science Foundation of China (61571013) and by the Beijing Natural Science Foundation of China (4143061). The authors thank the anonymous reviewers for their invaluable comments and suggestions, all the partners and the participants in the experiment for their help.
References
[1] Bor-Shing Lin, Yu-Hsien Yao, Ching-Feng Liu, Development of novel lip-reading recognition algorithm, IEEE Journals & magazines. (2017) Vol. 5. pp. 794-801.
[2] E. Petajan, B. Bischoff, D. Bodoff, An improved automatic lip reading system to enhance speech recognition, CHI’ 88 (1988) 19–23.
[3] S.L. Wang, W.H. Lau, A.W.C. Liew and S.H. Leung, Automatic lipreading with limited training data, ICPR’06 (2006)
[4] Sunil S. Morade, S. Patnaik, A novel lip reading algorithm by using localized ACM and HMM: Tested for digit recognition, Optik 125. (2014), 5181–5186.
[5] N. Puviarasan, S. Palanivel, Lip reading of hearing impaired persons using HMM, Expert Systems with Applications 38. (2011), 4477–4481.
[6] X. Hong, H. Yao, Y. Wan, et al., A PCA based visual DCT feature extraction method for lip-reading, Intelligent Information Hiding and Multimedia Signal Processing,(2006) pp. 321-326.
[7] G. Potamianos, H. P. Graf, and E. Cosatto, An image transform approach for HMM based automatic lip reading, ICIP, (1998), pp. 173-177.
[9] D. Cai, X. He, K. Zhou, J. Han, and H. Bao, Locality sensitive discriminant analysis,” IJCAI, (2007) pp. 708–713.
[10] Y. L. Liang, W. J. Yao, M. H. Du, Feature extraction based on LSDA for lipreading, ICMT, (2010) pp.
[11] Sunil S. Morade, S. Patnaik, Lip reading using DWT and LSDA, IEEE International Advance Computing Conference, (2014) , pp. 1013-1018.
[12] Viola, Paul, Jones, Robust real-time object detection, IEEE Transactions on Computer Vision, (2004), pp. 137-154.