634 | P a g e
Experimental and Performance Analysis of Big Data
technologies like Hadoop
Pooja
1, Ms. Seema
2, Mr. Rajiv Sharma
31
M.Tech. (CSE) Student, SBMNEC, Rohtak, Haryana
2,3
Asst. Professor, Dept. of CSE, SBMNEC, Rohtak, Haryana
ABSTRACT
From big consumer stores mining shopper data to Google using online search to predict incidence of the
flu, companies and organizations are using troves of data to spot trends, combat crime, and prevent
disease. Online and offline actions are being tracked, aggregated, and analyzed at dizzying rates. For
instance, questions like, what number of calories we expended for breakfast, what number of we consumed
on our keep going run, and to what extent we spend utilizing different applications on our PC, can be
recorded and broke down. We can get thinner by acknowledging we tend to rampage spend on Thursdays.
We can be more effective at work by acknowledging we invest energy more than we thought on Facebook.
Data warehousing and data mining are connected terms, as is NoSQL. With data immovably close by and
with the capacity given by Big Data Technologies to successfully store and examine this data, we can
discover answers to these inquiries and work to enhance each part of our conduct. Amazon can know each
book you at any point purchased or saw by dissecting Big data assembled throughout the years.
Keywords: textiles, sustainable behavior, industry, environment.
I.INTRODUCTION
This paper focuses on Big data technologies like Hadoop, NoSQL, Messaging Queues etc. helps in BigData
analytics, drive business growth and to take right decisions in time. These Big Data environments are very
dynamic and complex; they require performance validation, root cause analysis, and tuning to ensure success. In
this paper we talk about how we can analyse and test the performance of these systems. We display the
imperative factors in a major data that are essential possibility for execution testing like data ingestion limit and
throughput, data handling limit, recreation of expected use, outline occupations et cetera and propose measures
to enhance execution of bigdata. Enormous data (Petabytes or Exabyte) depicts vast measure of both organized
and unstructured data that is hard to process utilizing customary database and programming procedures. The
data is inexactly organized and inadequate that will be disapproved for data. It incorporates data accumulated
635 | P a g e
logging of organized and unstructured data. Big Data is portrayed by 3Vs (Fig-1) as high volume, speed and
assortment data resources that require savvy and imaginative types of data handling for basic leadership. The
advances related with Big data examination incorporate NoSQL databases, Hadoop and Map Reduce [10].
Data has been a spine of any venture and will do as such advancing. Putting away, removing and using data has
been vital to numerous organization's activities. In the past when there were no interconnected frameworks, data
would stay and be devoured at one place. With the beginning of Internet innovation, capacity and necessity to
share and change data has been a need. This imprints innovation of ETL. ETL encouraged changing, reloading
and reusing the data. Organizations have had Big interest in ETL framework, the two data warehousing
equipment and programming, faculty and abilities.
With the appearance of advanced innovation and keen gadgets, a lot of computerized data is being created each
day. Advances in computerized sensors and correspondence innovation have tremendously added to this
immense measure of data, catching significant data for undertakings, organizations. This Big data is difficult to
process utilizing regular innovations and calls for enormous parallel handling. Advancements that can store and
process exabytes, terabytes, petabytes of data without colossally raising the data warehousing cost is a need of
time. Capacity to get experiences from this monstrous data can possibly change how we live, think and work.
Advantages from Big data examination run from medicinal services area to government to back to promoting
and numerous more [1]. Enormous data open source advances have picked up a lot of footing because of the
exhibited capacity to parallelly process a lot of data. Both parallel handling and method of conveying calculation
to data has made it conceivable to process substantial datasets at rapid. These key highlights and capacity to
process immense data has been an extraordinary inspiration to investigate the design of the business driving
enormous data handling system by Apache, Hadoop. See how this Big data stockpiling and investigation is
accomplished and exploring different avenues regarding RDBMS versus Hadoop condition has demonstrated to
give an extraordinary understanding into much discussed innovation.
II.NEED OF BIG DATA ANALYTICS
With the previously mentioned properties of enormous data, data is monstrous, comes at a speed and
exceptionally unstructured that it doesn't fit traditional social database structures. With so much understanding
covered up in this data, an elective method to process this gigantic data is necessary. Big partnerships could be
all around resourced to deal with this assignment yet the measure of data being produced each day effectively
exceeds this limit. Less expensive equipment, distributed computing and open source advancements have
empowered preparing enormous data at a considerably less expensive cost.
Parcel of data implies part of shrouded bits of knowledge. The capacity to rapidly investigate Big data implies
the likelihood to find out about clients, showcase patterns, promoting and publicizing drives, gear observing and
execution examination and substantially more. Also, this is a critical reason that numerous Big undertakings are
636 | P a g e
make utilization of in-memory data question standard. Questions are performed where the data is put away,
dissimilar to traditional business knowledge (BI) programming that runs inquiries against data put away on
server hard drive. In-memory data investigation has fundamentally enhanced data question execution. Big data
investigation not simply enables endeavors to settle on better choices and pick up an edge into constant
preparing, it has likewise propelled organizations to determine new measurements and increase new wellsprings
of income out of bits of knowledge picked up.
Note that worldly data normally prompts Big Data, as does spatial data. Early endeavors to manage extensive
stockrooms, including non-scalar data, utilized purported ORDBMS [5], i.e. protest relations databases.
Enormous Data outflanks ORDBMS in different ways, including the requirement for more muddled
reinforcements, recuperation and speedier pursuit calculations, past RDBMS files. Advantages of utilizing Big
Data Technologies may come at a drawback of lost protection of the data. As far as security, a few organizations
pitch client data to different organizations, and this can be an issue
III.HADOOP DEFINITION AND ARCHITECTURE
Formal meaning of Hadoop by Apache: "The Apache Hadoop programming library is a structure that takes into
consideration the circulated preparing of Big data collections crosswise over groups of PCs utilizing
straightforward programming models. It is intended to scale up from single servers to a Big number of
machines, each offering nearby calculation and capacity. As opposed to depend on equipment to convey
high-accessibility, the library itself is intended to identify and handle disappointments at the application layer, so
conveying a profoundly accessible administration over a bunch of PCs, every one of which might be inclined to
disappointments" [6]. Hadoop was at first roused by papers distributed by Google, sketching out its way to deal
with handle a torrential slide of data, and has since turned into the standard for putting away, preparing and
dissecting many terabytes, and even petabytes of data. Hadoop system improvement was begun by Doug
Cutting and the structure got its name from his child's elephant toy [7].
Hadoop has drawn the motivation from Google's File System (GFS). Hadoop was spun from Nutch in 2006 to
wind up a sub-undertaking of Lucene and was renamed to Hadoop. Yippee has been a key supporter of Hadoop
development. By 2008 hurray web search tool list was being produced by a 10,000 center Hadoop group.
Hadoop is an open source system by Apache, and has imagined another method for putting away and preparing
data. Hadoop does not depend on costly, high effectiveness equipment. Rather it influences on profits by
appropriated parallel preparing of gigantic measures of data crosswise over item, ease servers. This framework
stores and procedures the data, and can without much of a stretch scale to evolving needs. Hadoop should have
boundless scale up capacity and hypothetically no data is too enormous to deal with appropriated engineering
[8].
Hadoop is intended to keep running on ware equipment and can scale up or down without framework intrusion.
637 | P a g e
utilized by enormous companies like Yahoo, eBay, LinkedIn and Facebook. Ordinary data stockpiling and
investigation frameworks were not manufactured remembering the requirements of enormous data. Also,
subsequently no longer effortlessly and cost-successfully bolster the present Big data collections.
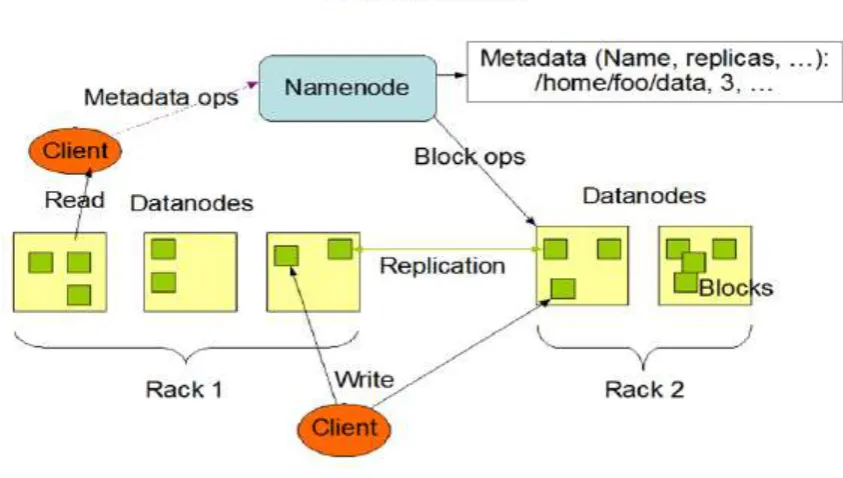
Figure 1. Hadoop detailed architecture.
IV.PERFORMANCE ANALYSIS OF HADOOP CLUSTER
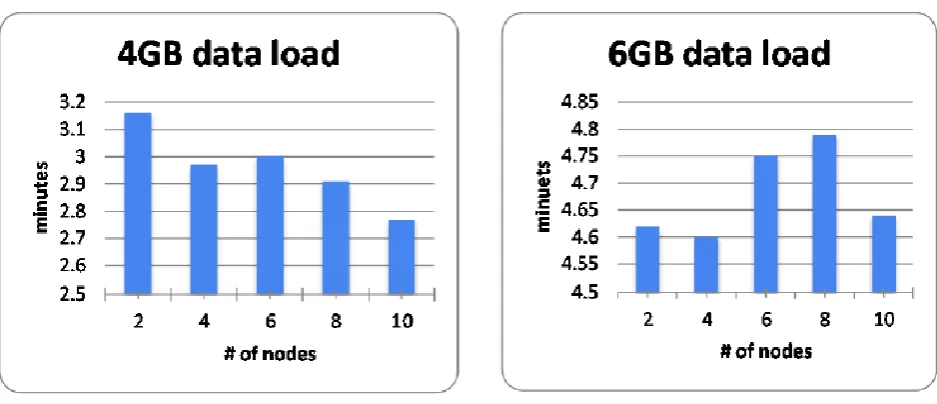
This experiment focuses on change in data load time in hive table with increasing number of nodes on Hadoop
cluster. Experiment is done for two data sizes - 4 GB and 6 GB.
1. WinScp to AWS hadoop master node to get access to the local file system
2. Copy csv data to the root (/home/hadoop)
3. SSH to master node. This should launch hadoop command line.
4. To launch hive command line run command > hive on hadoop command line.
5. Create table command > create table ratings (userid string, col1 string, movieid string, col2 string, rating
638 | P a g e
6. Load sample data into created table > load data local inpath './ratings4gb.csv' overwrite into table ratings; See
Figure 6.4.
7. Note data load time for 4GB data size
8. Go to AWS management console
9. Select the created console and increase number of cores to 4, 6, 8 and then 10, each times re-creating hive
table and re-loading it with 4GB data set.
10. There were five readings taken per data size and per node size to allow for any latencies. Average of 5
readings is considered while evaluating the performance.
11. Repeat above steps for 6GB data size.
639 | P a g e
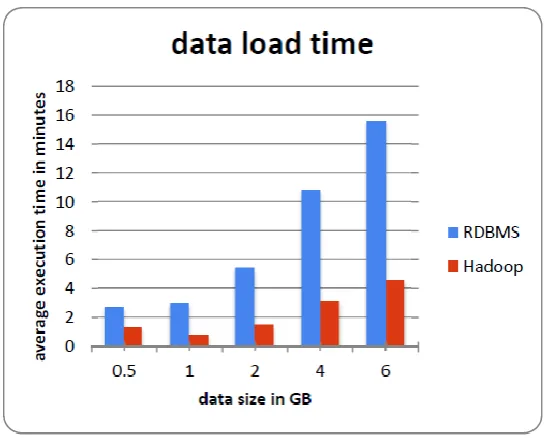
Figure 3. Bar graph visualization for experiment RDBMS vs HadoopV.CONCLUSION
Big data has become highly prevalent in organization‟s day-to-day activities. Amount of big data and rate at which it‟s growing is enormous. And big data technology is sure to soon knock on the door of every enterprise,
organization, and domain. RDBMS, even with multiple partitioning and parallelizing abilities fails to easily and
cost-effectively scale to growing data needs. At the same time it expects data to be structured and is not so
capable of storing and analyzing raw unstructured data which is common to encounter with the advent of
wearable technologies, smartphones, and social networking websites.
Hadoop is the most widely accepted and used open source framework to compute big data analytics in an easily
scalable environment. It‟s a fault tolerant, reliable, highly scalable, cost-effective solution that‟s supports
distributed parallel cluster computing on thousands of nodes and can handle petabytes of data. Two main
components HDFS and MapReduce contribute to the success of Hadoop. It very well handles storing and
analyzing unstructured data. Hadoop is a tried and tested solution in the production environment and well
adopted by industry leading organizations like Google, Yahoo, and Facebook.
REFERENCES
[1]. EA Bhardwaj, RK Sharma, EA Bhadoria, A Case Study of Various Constraints Affecting Unit
Commitment in Power System Planning, International Journal of Enhanced Research in Science
640 | P a g e
[2]. V. Mayer-Schoönberger and K. Cukier. Big data – a revolution that will transform howwe live, work, and
think. Eamon Dolan/Houghton Mifflin Harcourt, Chicago, Illinois 2013.
[3]. Wikipedia. Big data, 2014. http://en.wikipedia.org/wiki/Big_data, accessed April 2014.
[4]. VITRIA. The Operational Intelligence Company, 2014. http://blog.vitria.com, accessed April 2014.
[5]. E. Dumbill. What is Big Data? An Introduction to the Big Data Landscape, 2012.
http://strata.oreilly.com/2012/01/what-is-big-data.html, accessed April 2014.
[6]. M. Stonebraker, P. Brown, and D. Moore. Object-relational DBMSs, tracking the nextgreat wave. Morgan
Kauffman Publishers, Inc., San Francisco, California, 2 edition, 1998.
[7]. Apache Hadoop. What Is Apache Hadoop?, 2014. http://hadoop.apache.org/, accessed April 2014.
Wikipedia. Apache Hadoop, 2014. http://en.wikipedia.org/wiki/Apache_Hadoop, accessed April 2014.
[8]. T. White. Hadoop – the definitive guide. O‟Reilly Media, Inc., Sebastopol, California, 1 edition, 2009.
[9]. V. S. Patil and P. D. Soni. Hadoop Skeleton and Fault Tolerance in Hadoop Clusters, 2011.
[10]. Apache Hadoop. MapReduce Tutorial, 2013. https://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html,
accessed April 2014.
[11]. Apache Hadoop. HDFS Architecture Guide, 2013. http://hadoop.apache.org/docs/r1.2.1/hdfs_design.html,
accessed April 2014.
[12]. K. Kline, D. Kline, and B. Hunt. SQL in a nutshell, a desktop quick reference. O‟Reilly Media,
Sebastopol, California, 3 Edition, 2008.
[13]. P. J. Sadalage, and M. Fowler. NoSQL distilled, a brief guide to the emerging world ofpolygot persistence.
Addison-Wesley, Reading, Massachusetts, 3 edition, 2013.
[14]. Bhardwaj, Amit. "Literature Review of Economic Load Dispatch Problem in Electrical Power System
using Modern Soft Computing," International Conference on Advance Studies in Engineering and
Sciences, (ICASES-17), ISBN: 978-93-86171-83-2, SSSUTMS, Bhopal, December 2017.
[15]. S. Johnston. Seminar on Collaboration as a Service – Cloud Computing, 2012.
http://www.psirc.sg/events/seminar-on-collaboration-as-a-service-cloud-computing, accessed April 2014.
[16]. Nagdive A S, Tugnayat R M & Tembhurkar M P. Overview on Performance Testing Approach in Big
Data. International Journal of Advanced Research in Computer Science, 5(8).
[17]. Gudipadi M, Rao S, Mohan D N &Gajja N K. Bigdata: Testing approach to overcome quality challenges
in
[18]. Infosys lab Briefings 11(1).
[19]. Er Amit Bhardwaj, Amardeep Singh Virdi, RK Sharma, Installation of Automatically Controlled
Compensation Banks, International Journal of Enhanced Research in Science Technology & Engineering,
2013.
[20]. Abramova V, and Bernardino J “NoSQL databases: MongoDB vs cassandra” In Proceedings of the
International C* Conference on Computer Science and Software Engineering pp. 14-22 ACM.
[21]. http://en.wikipedia.org/wiki/big_data.
[22]. Manoj V “Comparative Study of NoSQL Document, Column Store Databases and Evaluation of
641 | P a g e
[23]. 2014 International Journal of Database Management Systems (IJDMS) Vol, 6.
[24]. Abramova V, Bernardino J and Furtado P “Testing Cloud Benchmark Scalability with Cassandra” In
Services (SERVICES), 2014 IEEE World Congress on pp. 434-441 IEEE.
[25]. Gandini A, Gribaudo M, Knottenbelt W. J, Osman R and Piazzolla P, „Performance evaluation of NoSQL
database.
[26]. Vikram Kumar Kamboj, S.K. Bath, J. S. Dhillon, “Multiobjective multiarea unit commitment using hybrid
differential evolution algorithm considering import/export and tie-line constraints”, Neural Computing
and Applications (ISSN: 1433-3058), Vol.28, No.11, 2017, pp. 3521–3536, DOI