A SELECTION ALGORITHM OF
TERMS FROM OWL ONTOLOGY FOR
SEMANTICALLY CLASSIFY
MESSAGES
SAADIA LGARCH
Mohammadia Engineering School, Mohamed V– Agdal University, Rabat, Morocco
[email protected] MOHAMMED KHALIDI IDRISSI
Mohammadia Engineering School, Mohamed V– Agdal University, Rabat, Morocco
[email protected] SAMIR BENNANI
Mohammadia Engineering School, Mohamed V– Agdal University, Rabat, Morocco
[email protected] Abstract:
In E-Learning systems, tutoring plays an important role in supporting learners in overcoming several problems such as feelings of isolation that learners feel, and so ensure monitoring and a quality learning. To collaborate, tutor uses communication tools, particularly the asynchronous tools, like discussion forums. This type of tools allows flexibility in terms of time offered. However, asynchronous tools generate a volume of messages accumulate over time, and that makes the exploitation of the communication space very complex to manage. To help tutor to manage this mass of messages, we proposed a semantics classification tool, which is based on the LSA and ontology. After proving the usefulness of integrating OWL ontology, we propose in this work, to improve the prototype that we implemented in proposing an algorithm for selecting new terms from ontology, based on those introduced by the user. Our algorithm is based on SPARQL, which allows querying OWL ontology.
Keywords: Semantic Classifier of message; formal Ontology; OWL; Selection algorithm; SPARQL; LSA; Tutoring; Discussion Forum.
1. Introduction
To enable collaboration in a tutoring system in e-learning, the use of collaborative tools is essential. The tutor and learners can then communicate via synchronous or asynchronous tools. The discussion forum like other asynchronous tools, offers the user a freedom of expression without temporal or spatial constraint, because they don't require the presence of all players in the same time slot, or even place to discuss between them, or with their tutor. However, this type of collaboration tools is sometimes not easy to handle. Indeed, the volume of messages accumulated over time in a progressive manner, and that makes use of communications space very complicated in terms of finding relevant information. Hence the need for tools for message classification, and organization of this area of communication in order to facilitate research and access to the targeted information in a simple and effective manner.
We will adopt the following plan. In Section 2 we mention the importance of collaboration tools for tutoring especially, those asynchronous as the discussion forum, while presenting the problem that this type of tool generates. In section 3, we describe, the essential elements on which is based the semantic classification tool presented in [13]. The insufficiencies identified in the use of the thesaurus are also presented in the third section. Reinforcement the semantic classifier with an ontology, which we propose to conceive and build, will be explained in the fourth section. In this section we also present the selection algorithm that we conceived. Section five is dedicated to the implementation of a prototype of our semantic classifier, and for testing the relevance of the proposed selection algorithm. At the end we give a conclusion and prospects for our next works.
2. Asynchronous tools and collaboration between tutor and learners
The success of any work performed by several actors who have to work together to achieve a common goal, depends on collaboration tools available to them. When the work to achieve successfully is a work of distance learning, success becomes a challenge to all intervenors in this work, the fact that they are far away geographically and temporally. There where collaborative learning is organized by interactions both synchronous and asynchronous, between learners and their tutor has shown its advantages in the success of online formation [10] [20].
The tutor is a key player in the environment of E-Learning, because he overcomes several problems that learner encounter during his learning pathways, and in particular the problem of isolation that he feels and that presents a real obstacle in the continuity of his formation [7], hence the need for collaboration tools, especially those asynchronous, thanks to their flexibility.
The asynchronous communication tools, particularly discussion forums allow the exchange of information in flexible way. But in return they generate a large mass of messages. We thus see that the volume of messages exchanged generates noise, proportional to the number of intervenors. This makes the exploitation of this mass a heavy and impractical. The undesirable mixture of messages from different contexts and different objectives generates a block and slowness in reply's time. A member of a working group that is remote, Requires functionalities to be included in the asynchronous communication tools to facilitate to him the task of researching the desired information in a very fast way and depending on the intended context [5].
To meet those needs, we proposed in [13] a tool for semantic classification of messages of a discussion forum
3. The first semantic classifier proposed
The classification tool introduced in [13] is based on LSA (Latent Semantic Analysis) with a reinforcement of the classification by integrating a thesaurus.
Based on the singular value decomposition (SVD), the LSA method allows to find similarities between the documents (texts, sentences, words) [3] [14].
In order to have relevant results we have proposed to widen the scope of research while respecting the context requested. The use of the technologies proposed by the Semantic Web in particular those that enable the organization of vocabularies in a semantic way, was necessary
.
For this, we first chose the thesaurus.3.1.Semantic Web
The term Semantic Web attributed to Tim Berners-Lee [2] denotes a set of technologies to make the content of resources on the World Wide Web accessible and usable by software agents and programs, through a system of formal metadata, including using the family of languages developed by W3C.
The Semantic Web does not call into question the classic web, because it is based on it, especially a means of publication and consultation documents. The automatic processing of documents via the semantic web is done by adding formalized information (markers) that describe their content and their functionalities instead of texts written in naturals languages (French, Spanish, Chinese, etc..) [24]. Moreover, for the manipulation of semantic markers, we need semantic resources that help to define a vocabulary for such markers and also allow concepts sharing and interoperability. Among these resources we find the taxonomies, semantic networks, thesaurus and ontologies [13].
3.2.Thesaurus
The international standard ISO 2788 (1986) defined the thesaurus as the « vocabulary of a controlled indexing language formally organized in order to explicit the relationship priori between notions (eg relationship generic / specific) ». According to the same standard, an indexing language is a « set of controlled terms and selected from a natural language and used to represent in condensed form, the contents of documents ».
more or less similar semantically. The thesaurus is as an instrument of control and structuring of the vocabulary; it contributes to the consistency of indexing and facilitates information retrieval [19].
The terms in a thesaurus are conceptually organized and interconnected by semantic relations. These relations are of three types: hierarchical, equivalence and association [13].
The possibility that the thesaurus gives in terms of semantic classification of terms of a given vocabulary, we have encouraged on one hand to integrate it as an essential component in the classification presented in [13]. On the other hand, the simplicity of relations and of terms that the thesaurus presents, has facilitated the implementation of the classifier and to see the first results when a semantic resource of organization of words is integrated.
3.3.Proposed approach based on the Thesaurus and LSA
To help a user find a message posted to a discussion forum, most methods of classification provides a research based on keywords. The research results obtained are dependent and proportional to the relevance of keywords chosen by the user [13].
We presented in [13] a tool for classifying the messages of a discussion forum that is based on a semantic approach. This approach allows managing the mass of messages accumulated with applying a classification according to their semantic context. The classification made is based primarily on the LSA method. In order to increase the performance of the method chosen by extending the terms used in the construction of Table lexical (words / documents) and thus improve the classification, we thought to organize these terms with other terms in a hierarchical manner using a thesaurus.
Our implementation was done in three stages. In the first one, we only implemented the LSA. The integration of the thesaurus as a resource semantics has been the subject of two approaches. The first approach is to include more keywords specified by the user, the specific terms that are associated through the thesaurus, avoiding repetitions [13].
This approach demonstrates that the results generated are more interesting in terms of semantics as those generated by the LSA method only, because messages of semantics close to that desired are generated without these messages contain the specified keywords. But messages of different semantics are also returned, since they contain terms that are linked to a few key words only and not all of these keywords [14]
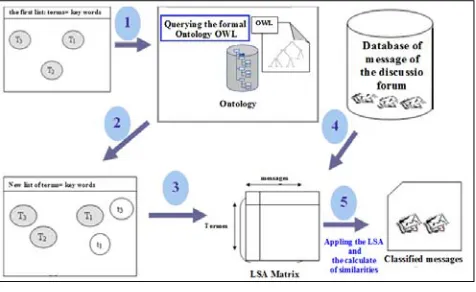
To overcome the problem of side messages, an improvement to semantic approach of classification is made [13]. In this case and to build the lexical table, we include in addition to the keywords specified by the user, specific terms defined by the thesaurus, common to those (figure 1):
The Improvement made to our basic approach leads to more relevant results than those generated from the first approach. The messages returned are only in the same desired context.
The improved semantic approach allows classifying messages according to a set of terms that belong to the desired themes, based on semantic relations that exist between these terms. The terms used so to enable this classification, are ranked according semantic relations using a thesaurus. The latter is constructed from a corpus of messages of different topics. The application of this approach on a corpus of messages posted through a forum discussion, showed results relevant and rich in semantics, which approves the use of thesaurus prior to the LSA.
The results thus found by using a thesaurus seem satisfactory. However it is necessary to highlight some insufficiencies in the use of thesaurus [15].
3.4. Insufficiencies of Thesaurus
The thesaurus has been created to assist archivists in their task of indexing and queries formulation [11]. The thesaurus is characterized by a degree of semantic precision given for the presentation of knowledge that limits its use for automatic indexing. This is explained partly because a terminology dictionary, incarnates a representation of a domain (a lexicalization of a conceptualization), which is not as complete as the formal semantics provided by the conceptual representation, and its modest structure, is therefore unsuitable for advanced semantic applications. On the other hand, and in particular, relations linking terms (controlled vocabulary to represent concepts) in a thesaurus (BT, NT, RT) are generally not sufficient for a profound analysis of the semantics of indexed documents [1].
The thesaurus also lacks a conceptual level of abstraction. These are collections of terms that are organized under a single hierarchy or multiple hierarchies but with basic relations between terms. The distinction between a concept and its lexicalization is not clearly established. The thesaurus does not reflect how the world can be understood in terms of meaning. In addition, coverage semantic thesaurus is limited. The concepts are generally not differentiated from their abstract type (such as substances, processes). The relations between terms are vague and ambiguous. The relation “is related to” is often difficult to exploit because it connects the terms by implying different types of semantic relations. It is often difficult to determine the properties of relations "more specific», «more generic» which can combine the relations «is an instance of» or «is part of». The thesaurus also lack consistency and may contain conflicting information [11].
The gains made by reuse, are many. It was perceived for a long time as a means to improve quality and reduce costs and delays in production. Yet like in other areas, reuse in e-learning has become a discipline and focus of research in its own right [12]. In this context, we are interesting to the reuse of knowledge bases, something that a thesaurus can not satisfy.
We conducted then an investigation on the side of the ontology. This last allows reuse by creating and maintaining reusable knowledge. The ontology allows also the assembly of knowledge bases from reusable modules. The sharing of knowledge and communication is also possible with ontologies since they provide interoperability between systems and enable the exchange of knowledge between these systems [6].
The ontology can thus overcome the insufficiencies of the thesaurus through the opportunity to represent the knowledge of a domain by identifying and modelling concepts and conceptual relations. The ontology can also formalize the conceptualization and corresponding vocabulary, this formalization which also targets to remove any ambiguity [8].
All these qualities that ontology possesses render its degree of semantic precision for the presentation of knowledge higher. We then propose to adapt our classifier to ontology instead of a thesaurus.
3.5.Ontologies
Ontology is an explicit specification of a conceptualization of a domain, formed by concepts and relations that allow humans and machines have everything they need to understand and reason about an area of interest or a portion of the universe [18]. On one hand, ontologies allow to describe the knowledge of a specific area, and on the other hand to represent complex relations between concepts, axioms and rules [21]. Ontologies have become a central component in many applications, and they are called to play a key role in building the future “Semantic Web” [4].
A thesaurus or even a taxonomy are forms of ontology whose grammar has not been formalized. When we establish a category and a hierarchy of this categorization, we establish dependencies between these terms. These hierarchies are meaningful outside the vocabulary itself. For example, when we say «this term is a subcategory of that other term», we come giving sense of this relation, we draw a "arrow" between the two by qualifying the arrow and asserting what kind of relation that meant. Ontology corresponds therefore to a controlled and organized vocabulary, and to explicit formalization of relations established between the different vocabulary terms. To realize this formalization, we can use a particular language. Among the languages used to describe the relations between various terms of vocabulary, there are RDF (S) and OWL [9]. All the benefits listed above and relating to ontologies encouraged us to propose a future work using an ontology instead of a thesaurus for controlling our vocabulary.
4. Reinforcing the semantic classifier tool using ontology
The possibility that ontology provides to overcome the limitations of the thesaurus encouraged us to use it to control our vocabulary [17]. We then proposed to formalize the ontology using OWL language (Web Ontology Language) [17]. This formalization will allow the querying of ontology during the stage of searching of terms which are semantically related with those explained by the user (tutor).
symmetry, the transitivity, the cardinality, etc.. These properties allow defining complex relationships between resources [22].
The adaptation of the tool [13] will be at the research phase of semantically similar terms using a formal ontology OWL. To classify messages of different contexts and following the wanted context, the tutor should enter a set of keywords (terms). Terms entered target the desired context and represent the input parameters of the query operation of the ontology while the output parameter is in addition to the keywords specified by the tutor, we find those defined by semantic relationships in formal ontology, common to them.
To query the ontology we chose the SPARQL language, because it has the necessary capabilities for querying and optional graph patterns with their conjunctions and disjunctions. According to Tim Berners-Lee, the director of the W3C “Trying to use the Semantic Web without SPARQL, is equivalent to running a relational database without SQL”. The conception of SPARQL was in order to be used across the web and thus enables queries over distributed data sources, regardless of format. Creating a query with SPARQL become easier, at lower costs and provides richer and precise results. The results of SPARQL queries can be sets of results or RDF graphs [25].
4.1.Design and creation of our ontology
We have created a first version of our ontology reflecting the domain of “informatique” [17] in French language, and we propose to improve it in this work for getting more relevant description of the vocabulary of “informatique”.
The construction of the ontology is done from a whole corpus of messages of different topics (routage, protocole, IGP, dynamique, web, etc ...) which are posted via the platform of e-learning moodle. To find all terms that make up our ontology, we do a search on each message and we select only terms which give to message more information [13]. The terms found are organized in a hierarchical manner following the UML conceptual model which is the class diagram. The class diagram offers also the possibility of linking concepts between them following semantic relationships such as association relationship and the relationship of composition, for example.
4.1.1.The Class diagram of our ontology
In this work, we propose to elaborate a conceptual model of the domain of "informatique" based on the UML (Unified Modeling Language) and in particular class diagram.
In the model (Figure 2), we represent in first step the different classes and different properties of a class. After identification of all classes of our domain, we use the inheritance relationships to create a hierarchy between classes and their subclasses. In the example at Figure 2, the class "routing" has three subclasses “dynamique”, “statique” and “mixte”, which means that the “routage” can take three forms: “routage dynamique”, “routage statique” and “routage mixte”.
Associations between classes were also well presented, as in the case of the relationship “utilise_externe_protocole” defined between the class “externe_routage” and “externe_protocole”.
The richness of UML for model development and in particular the class diagram was very useful, and it allows us to define and introduce the set of concepts (classes) and relations between these concepts (inheritance, composition association) to migrate to formal ontology with very high semantic precision and without ambiguity.
4.1.2. Elaboration of the ontology with “protégé”
In developing the ontology, we chose the editor "protégé" in the version 3.4.1. “protégé” [26] is a software that edits, develops the OWL ontologies, and other forms of ontologies. We have chosen “protégé” because its interface is very intuitive and the software is mature enough.
The hierarchical organization provided by the class diagram, are translated easily with the functionalities provided by “protégée”. For this reason we have used the relations “SuperClass” and “SubClass” that define a mother class and a child class of another class, respectively.
The notion of attribute in a class is also described in ontology; it can be defined by the functionality “DatatypeProperty”. For class “metrique” for example we can define “translation” as “DatatypeProperty”, and in this case we assign to its instance “saut” value “jump” as the English translation of “saut” for example.
After the hierarchy of relationships, we proceed to migrate the semantic relationships of composition and association based on the feature “ObjectProperty”. And so if R1 is an association which the original is C1 and C2 is the destination, we translate this using “ObjectProperty” functionality, whose name is R1 and whose “domain” and “range” are equal to C1 and C2 respectively. For example, the relationship of association “utilise_protocole” defined between “dynamique” and “routage_protocole” will be translated into “protégé” by creating a “ObjectProperty” which “domain” and “range” have such values “dynamique” and “routage_protocole” respectively.
The last step in creating the ontology is to assign to each final class (final class has no daughter class or SubClass) its own instances. For example the “interne_protocole” class owns “IGP”, “RIP”, “OSPF”, “IGRP” as instances, while “BGP” and “EGP” are instances of “externe_protocole” class (figure 3).
After building the ontology using “protégé”, it will be exported to OWL formalism, one thing that the structure of the ontology allows in the difference of the thesaurus. The choice of OWL came after showing it has more advantages compared to RDF (S) [15]. The OWL file generated described clearly and unambiguously the semantic relationships between the concepts of ontology. In Figure 4, the OWL code describes clearly semantic relations between concepts, such as the relationship “utilise_metrique" between “dynamique” and “metrique”.
The clarity of the formal representation of the vocabulary, which is provided by ontology, and in particular the OWL formalism, allows the querying of ontology with a very precise way.
To query the OWL ontology, and thus generate only the relevant terms, we propose an algorithm that allows a deep search in ontology and then selects the semantically similar terms to those introduced by the user.
4.2.Our algorithm for selecting terms from the ontology
In our work [16], we conducted a set of tests that have approved that the use of functionalities like “Class”, “SuperClass”, “SubClass”, “ObjectProperty” and “DatatypeProperty” generates interesting results in the semantics of messages returned.
Based on the keywords entered by the user, we propose in this work an algorithm to select terms semantically closest to those introduced by the user through the ontology. All selected terms will be later incorporated into the construction phase of the LSA matrix. The implementation of the algorithm selection will be based primarily on the ontology query language SPARQL.
4.2.1.The logic of our selection algorithm from the ontology
To classify messages according to a given topic, the user is asked to enter a set of keywords that target the desired theme.
Let T1, T2, ..., Tn the keywords entered by user. The proposed algorithm is based on the one hand on relations of hierarchies (SubClass or SuperClass proposed by OWL formalism) as an essential representative of semantic relationships between concepts of ontology. On the other hand, our selection algorithm uses the relations of associations that can link two concepts which are described by the element “ObjectProperty” provided by the OWL formalism.
The main objective of the algorithm is to identify all direct subgraphs formed by the set of keywords in our ontological graph. In this first part we will use the relationship hierarchies. In this case, we say that the nodes A, B form a direct subgraph in the ontological graph, if they verify the following expression (1):
ASuperClassOf B orBSuperClasssOf A
true (1)We can then say that A, B, C form a direct subgraph in the ontological graph, if {A, B}, {A, C} and {B, C} verify the expression (1).
All nodes of each identified subgraph, forms the skeleton of all new terms to be generated from that subgraph.
Take for example the set of keywords KEY = {C0, A1, C1, C2, D3, E1, E6} (Figure 5), we notice that G1 = {A1, C1, E1} forms a direct subgraph, because the expression (2) is true:
C SuperClassOf E orE SuperClasssOf C
trueand A sOf SuperClass E or E Of SuperClass A and A sOf SuperClass C or C Of SuperClass A 1 1 1 1 1 1 1 1 1 1 1 1 (2)
Similarly we identify the subgraph G2 = {C2, D3, E6} and G3 = {C0}.
After the identification of subgraphs, we pass to the identification of all TGk sets of terms that must be generated from Gk. For the sous-graphe G1 for exemple, the first generated terms are A1, C1 and E1 because they are mentioned by the user and thus TG1 = {A1, C1, E1}. B1 is a concept, whose semantics is a specification of A1, but it generalizes C1, its integration in the set of terms generated involves the integration of C2 of different semantic of C1. So B1 is excluded from TG1 and similarly for D1 which will also be excluded from TG1. E1 is the subclass of all other classes of G1, and then it describes more the theme requested by the user. For this, all subclasses of E1 are then included in TG1 without forgetting their instances. And so TG1 = {A1, C1, E1, F1, J1, J2}.
Similarly we identify TG2 = {C3, D3, E6, S1} and TG3 = {C0, D0}.
The TG set of terms from the ontology is then equal to the union of all TGk (Eq. (3)):
TG
i1 TG
k i (3)
In this case the TG of generated terms based on the first set of key word KEY= {C0, A1, C1, C2, D3, E1, E6} is equal to:
A
C
E
F
J
J
C
D
E
S
C
D
TG
i 1 1 1 1 1 2 3 3 6 1 0 03 1 , , , , , , , , , , ,
TG
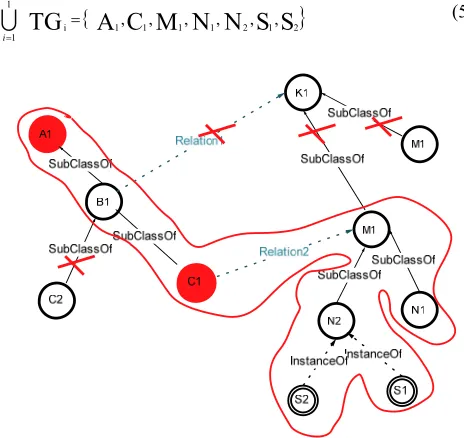
iIn the second part we will see how the association relationship can also generate new terms. Take for example the set KEY = {A1, C1} of keywords, in this case we identify a single graph G1 = {A1, C1} (Fig. 6). Following the logic of the first part, we find that TG1 = {A1, C1}. Figure 6 also shows the existence of the relationship “Relation2” which is defined between C1 and M1. This relationship generates the integration of M1 concept into TG1, and all its instances (N1 and N2) without forgetting their instances (S1 and S2). Then TG1 = {A1, C1, M1, N1, N2, S1, S2}.
The “Relation1” between B1 and K1 is excluded, because it is a relationship that can generated terms that may be in semantic relation with C2 (B1 is a super class of C2) and that are semantically far from C1.
The set TG of terms generated from the ontology is equal to Eq. (5):
A
C
M
N
N
S
S
TG
i 1 1 1 1 2 1 21
1
, , , , , ,
TG
i
(5)
Fig. 5 – Identification of sub-graphs and terms generated, based on relationships of hierarchy
4.2.2.Our algorithm of selection of terms from ontology
5. Implementation and testing
5.1.Implementation
The purpose of this implementation is to measure the impact of the integration of the ontology to our classifier, and in particular, to test the effectiveness of the algorithm of selection in the choice of new terms to be included in the classification.
To test our approach, we worked on a corpus of messages from a discussion forum addressing various topics (eg routing, Language, Semantic Web, System, etc). Messages were posted using the platform of e-learning moodle.
The querying of the formal ontology OWL is done by applying the algorithm of selection (Section 4.2). To implement this algorithm we have used the Jena API. Dedicated to the creation of semantic web applications, Jena allows the manipulation of ontologies by providing Java APIs [27]. To represent and reason about OWL information, we appealed to Pellet. Pellet is an engine designed for reasoning on description logics, and it accepts input OWL files. In addition to the fact that it is free, Pellet also allows reasoning about instances of concepts, unlike some Reasoners who can reason at terminological level only (that is to say at level of concepts and properties) [23].
Initialisation:
KEY= {T1,.., Tn} ; // set of key words ng=1 ; // number of Graphs
G1= {T1} ;
begin
for Tj in KEY-{T1} do { // We treat all keywordsKEY-{T1}
for Gk in {G1,.., Gng} do { // We treat all graphs Gk
DansUnGraph=true;
// We treat all elements of the graphe Gk
for Ti in Gk do {
If ((Tj not in SubClassOf (Ti)) and (Tj not in SuperClassOf (Ti)) then { DansUnGraph=False;
Break; // Exit From « for Ti in Gk»
}
} //Fin Pour Ti dans Gk faire if (DansUnGraph==true) then { Gk=Gk+ {Tj} ;
Break; // Exit From “for Gk in {G1,.., Gng}”
}
Esle if (k==ng) { ng++;
Gng= {Tj}; }
} //Fin “for Gk in {G1,.., Gng}”
} //Fin “for Tj in KEY-{T1}”
// Integration of other concepts and instances. For k in {1,.., ng} do
{
Take Tsb / Tsb in SubClassOf (Ti) for Ti in Gk and Ti ≠ Tsb
Take Tsp / Tsp in SuperClassOf (Ti) for Ti in Gk and Ti ≠ Tsp
TGk= {Tsp , Tsb}
+ {C0/ C0 in SubClassOf (Tsp) and C0 in SubperClassOf (Tsb) }
+ {C1/ C1 in SubClassOf (Tsb)}
+ {I/ I=InstanceOf (C1)}
+ {C2/ C2 =Range (R) and Tsb =Domain(R)}
} TG=vide;
For k in {1,..,ng} do
TG=TG+TGK; // the set of generated terms
The proposed algorithm is also based on a set of SPARQL queries constructed in order to return new terms from OWL ontology. To find for example all instances of the “metrique” concept, we build the following SPARQL query (Figure 7):
To implement the LSA, we used the Jama package which allows for the singular value decomposition [13]. We also use the cosinus similarity measure [14] for calculating similarities.
5.2.Tests
To classify messages of the discussion forum following the “routage dynamique interne” theme, the user is called to enter the three key words “routage”, “dynamique” and “interne” through the user interface of the semantic classification tool which appears on the Figure 8:
The keywords introduced are then organized in the ontological tree as follows (figure 9):
Fig 7. SPARQL query example using « protégé »
Fig 8. The user interface of the semantic classification tool
The application of the selection algorithm identifies a single graph, to which the three key words belong (Figure 10).
And so the set of terms generated is TG = {interne, dynamique, Routage, metrique, interne_protocole, saut, MTU, charge, delai, cout, fiabilite, IP, RIP, RARP, IS-IS, OSPF, ARP, EIGRP, IGP, MPLS, Routeur, Cisco}. Following our proposal [17], the term “interne_protocole” will be interpreted as two terms “interne” and “protocole” that will be incorporated into TG rather than “interne_protocole”, while avoiding repetition.
TG is then equal to {interne, dynamique, Routage, metrique, protocole, saut, MTU, charge, delai, cout, fiabilite, IP, RIP, RARP, IS-IS, OSPF, ARP, EIGRP, IGP, MPLS, Routeur, Cisco}.
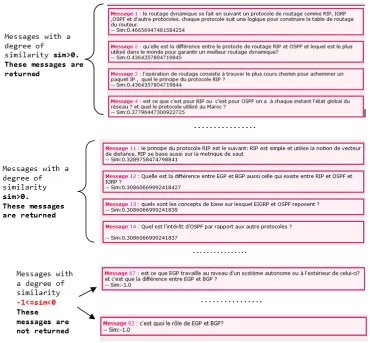
The integration of TG at the stage of building LSA matrix, and applying then of the calculation of similarity, returns the messages of Figure 11, while mentioning the similarity value of each message, relative to the user query. For messages to be returned, we consider only those with a degree of similarity sim(Message, UserQuery) between 1 and 0, while those with a degree of similarity sim(Message, UserQuery) between -1 and 0, are considered semantically far from the user query.
The result thus found is relevant, because on the one hand, there is generation of messages as message 4, 11, 12, 13 and 14, whose contexts are part of the thematic “routage interne dynamique”, without terms “routage”, “ dynamique” et “interne” appear in these messages (Figure 11).
On the other hand, the user query targets exactly the messages whose the context is a part of “routage dynamique interne” , and not those whose context is part of the theme “routage dynamique externe” or the theme of “routage statique” for example.
The application of the selection algorithm, allows to focus on messages which treat only the theme of “routage dynamique interne” (Figure 11), and this is due to the exclusion of “statique” and “externe”, and to neglecting the relationships between “dynamique” and other concepts such as the relationship “utilise_protocole” and “utilise_metrique”. Neglect of the relationship “utilise_protocole” for example, has caused the exclusion of “routage_protocole” concept, its subclass “externe_protocole” and these instances “BGP”, “EGP”, etc... (Figure 10). In this case, messages like 67 and 92 which deal with the theme of “protocoles de routage externs” each have a Degree of similarity equal to -1, those that mean they are completely different from the user query, and thus they are not returned (Figure 11).
Fig 10. Identification of a single graph by applying the selection algorithm
SubClassOf SubClassOf SubClassOf SubClassOf Routage dynam ique interne externe statique routage_protocole externe_protocole interne_protocole SubClassOf SubClassOf protocole SubClassOf securite_protocole application_protocole SubClassOf SubClassOf RIP CIDR InstanceOf InstanceOf EGP InstanceOf IGRP InstanceOf ARP InstanceOf RARP InstanceOf OSPF InstanceOf IP InstanceOf BGG InstanceOf BGP InstanceOf metrique utilise_metrique utilise_protocole UseInterneProtocol UseMetrique UseExterneProtocol f iabilite jump cout InstanceOf InstanceOf delai charge MTU InstanceOf InstanceOfInstanceOf InstanceOf
6. Conclusion and prospects
The prototype of system developed allows the classification of messages according to a set of terms that belong to the desired theme, based on semantic relationships between terms such as relationship of hierarchy and the relationship of association described with the OWL formalism, by “SubClass / SuperClass” and “ObjectProperty” respectively. The classification of message is based on the querying of a formal OWL ontology, which uses an algorithm of selection of terms semantically closest to those introduced by the user. The proposed algorithm is mainly based on the SPARQL language that has all the capabilities needed to query OWL ontology with high accuracy.
The done tests approve the importance of integrating a formal ontology, thanks to these benefits versus a thesaurus. The relevance of the selection algorithm has targeted terms that are closer to those contained in the user query. Thus we see that this algorithm has improved the semantics of message classification.
In order to ensure the reuse and interoperability with systems which requesting for its service of classification, our classification tool will be improved by implementing it, based on the service oriented architecture concept.
Indeed, the adoption of SOA in our tool will play a role to make it reusable and interoperable. The test of reuse and of interoperability of the classification tool will be the object of a future work.
References
[1] Angela Biasiotti M., Fern_andez-Barrera M. (2009). Enriching thesauri with ontological information: Eurovoc thesaurus and DALOS domain ontology of consumer law, 3rd Workshop on Legal Ontologies and Artificial Intelligence Techniques joint with, LOAIT '09, Barcelona, Spain.
[2] Berners-Lee T.; Hendler J.; Lassila O.(2001). The semantic web, A new form of web content that is meaningful to computers will unleash a revolution of new possibilities. Scientific American, pages 35–43.
[3] Bestgen Y. (2004). Analyse sémantique latente et segmentation automatique des textes ” Actes des 7es Journées internationales d'Analyse statistique des Données Textuelles, Louvain-la-Neuve, Presses universitaires de Louvain : 172-173.
[4] Boutet M., Canto A., Roux E. (2005). Plateforme d'étude et de comparaison de distances conceptuelles, Rapport de Master, Ecole Supérieure En Sciences Informatiques, Université Nice Sophia-Antipolis.
[5] Bouzidi D. (2004). Collaboration dans les cours hypermédia du système de télé- enseignement SMART-Learning, Doctoral thesis, Mohammadia Engineering School, Mohamed V– Agdal University, Rabat, Morocco.
[6] Charlet J. (2002). Ontologie, STIM/DSI/AP–HP & Université. Paris 6 & groupe « Terminologie et Intelligence Artificielle » Séminaire ISDN/Web sémantique.
[7] Charlier B. ; Daele A. ; Docq F. ; Lebrun M. ; Lusalusa S. ; Peeters R. ; Deschryver N. (1999). Tuteurs en ligne : quels rôles quelle formations, in Actes du Symposium international du C.N.E.D, Poitiers.
[8] Corby O. (2004). Modélisation des Connaissances et Web sémantique : Ontologie, INRIA, Sophia Antipolis, cours essai http://www-sop.inria.fr/acacia/cours/essi2004/index.html/ontologie2.ppt
[9] Dubost K. (2004). Ontologie, thésaurus, taxonomie et Web sémantique. http://www.la-grange.net/2004/03/19.html
[10] Henri F. ; Lundgren-Cayrol K. (1996). Apprentissage collaboratif à distance, téléconférence et télédiscussion, internal report n°3.Montréal, Canada; Centre de recherche LICEF.
[11] Hernandez N. (2005), Ontologie de domaine pour la modélisation du contexte en recherché d’information. Doctoral thesis,Paul Sabatier University, Toulouse, p63.
[12] Kara Terki H. ; Chikh A. (2007). Patterns d’analyse pour l’ingénierie des besoins en e-learning , Rapport de Magiter, Université de Tlemcen, Faculté des sciences de l’ingénieur.
[13] Lgarch S., Bouzidi D., Bennani S. (2008). Une approche sémantique de classification de messages d’un forum de discussion basée sur la méthode LSA, 1er Workshop sur les Nouvelles Générations de Réseaux : La Mobilité, WNGN’08, FST de Fès.
[14] Lgarch S. (2008). Une approche sémantique de classification de messages d’un forum de discussion basée sur la méthode LSA, Rapport de DESA, Mohammadia Engineering School, Mohamed V– Agdal University, Rabat, Morocco
[15] Lgarch S.; Idrissi M. K. ; Bennani S. (2010). Adaptation of classification semantic approach of messages of a discussion forum based on the LSA method to ontology. In the proceedings of SIIE '10, pages 29-36 Sousse, Tunisia.
[16] Lgarch S.; Idrissi M. K. ; Bennani S. (2010). Reinforcing semantic classification of message based on LSA, The third edition of the International Conference on Web and Information Technologies, 16-19 June ISBN 978-9954-9083-0-3, Marrakech, Morocco. [17] Lgarch S.; Idrissi M. K. ; Bennani S. (2010). Toward a use of ontology to reinforcing semantic classification of message based on
LSA, in the proceedings of ICEEEL '10. Paris, France.
[18] Moujane A.; Chiadmi D. ; Benhlima L. (2006). Semantic Mediation: An Ontology-Based Architecture Using Metadata. CSIT2006, Amman, Jordanie.
[19] Saadani L. ; Bertrand-Gastaldy S. (2000). Cartes conceptuelles et thésaurus : essai de comparaison entre deux modèles de représentation issus de différentes traditions disciplinaires, Canadian Association for Information Sciences, Procedings of the 28th Annual Conference.
[20] Walckiers M. ; De Praetere T. (2004). L’apprentissage collaboratif en ligne, huit avantages qui en font un must, distances et savoirs 2004 (Volume 2), ISSN 1765-0887, page 53 à 75.
[21] Zargayouna H. (2005). Indexation sémantique de documents XML, Doctoral thesis, Paris-Sud university, Paris, France. [22] http://websemantique.org/OWL
[23] http://www.standard-du-web.com/web_ontology_language.php [24] http://fr.wikipedia.org