Cross-Lingual Sentiment Classification with Bilingual Document
Representation Learning
Xinjie Zhou,Xianjun WanandJianguo Xiao
Institute of Computer Science and Technology, Peking University The MOE Key Laboratory of Computational Linguistics, Peking University
{zhouxinjie,wanxiaojun,xiaojianguo}@pku.edu.cn
Abstract
Cross-lingual sentiment classification aims to adapt the sentiment resource in a resource-rich language to a resource-poor language. In this study, we propose a representation learning approach which simultaneously learns vector representa-tions for the texts in both the source and the target languages. Different from pre-vious research which only gets bilingual word embedding, our Bilingual Document Representation Learning model BiDRL directly learns document representations. Both semantic and sentiment correlations are utilized to map the bilingual texts into the same embedding space. The experiments are based on the multilingual multi-domain Amazon review dataset. We use English as the source language and use Japanese, German and French as the target languages. The experimental results show that BiDRL outperforms the state-of-the-art methods for all the target languages.
1 Introduction
Sentiment analysis for online user-generated con-tents has become a hot research topic during the last decades. Among all the sentiment analysis tasks, polarity classification is the most widely s-tudied topic. It has been proved to be invaluable in many applications, such as opinion polling (Tang et al., 2012), customer feedback tracking (Gamon, 2004), election prediction (Tumasjan et al., 2010), stock market prediction (Bollen et al., 2011) and so on.
Most of the current sentiment classification sys-tems are built on supervised machine learning algorithms which require manually labelled
da-ta. However, sentiment resources are usually un-balanced in different languages. Cross-lingual sentiment classification aims to leverage the re-sources in a resource-rich language (such as En-glish) to classify the sentiment polarity of texts in a resource-poor language (such as Japanese). The biggest challenge for cross-lingual sentimen-t classificasentimen-tion is sentimen-the vocabulary gap besentimen-tween sentimen-the source language and the target language. This problem is addressed with different strategies in different approaches. Wan (2009) use machine translation tools to translate the training data di-rectly into the target language. Meng et al. (2012) and Lu et al. (2011) exploit parallel unlabeled da-ta to bridge the language barrier. Prettenhofer and Stein (2010) use correspondence learning al-gorithm to learn a map between the source lan-guage and the target lanlan-guage. Recently, repre-sentation learning methods has been proposed to solve the cross-lingual classification problem (Xi-ao and Guo, 2013; Zhou et al., 2015). These meth-ods aim to learn common feature representations for different languages. However, most of the cur-rent researches only focus on bilingual word em-bedding. In addition, these models only use the se-mantic correlations between aligned words or sen-tences in different languages while the sentiment correlations are ignored.
In this study, we propose a cross-lingual repre-sentation learning model BiDRL which simulta-neously learns both the word and document repre-sentations in both languages. We propose a joint learning algorithm which exploits both monolin-gual and bilinmonolin-gual constraints. The monolinmonolin-gual constraints help to model words and documents in each individual language while the bilingual con-straints help to build a consistent embedding space across languages.
For each individual language, we extend the paragraph vector model (Le and Mikolov, 2014)
to obtain word and document embeddings. The traditional paragraph vector model is fully unsu-pervised without using the valuable sentiment la-bels. We extend it into a semi-supervised manner by forcing the positive and negative documents to fall into different sides of a classification hyper-plane. Learning task-specific embedding has been proved to be effective in previous research. To ad-dress the cross-language problem, different strate-gies are proposed to obtain a consistent embedding space across different languages. Both sentiment and semantic relatedness are exploited while pre-vious studies only use the semantic connection be-tween parallel sentences or documents.
The performance of BiDRL is evaluated on a multilingual multi-domain Amazon review dataset (Prettenhofer and Stein, 2010). By selecting En-glish as the source language, a total of nine tasks are evaluated with different combinations of three different target languages and three different do-mains. The proposed method achieves the state-of-the-art performance on all the tasks.
The main contributions of this study are sum-marized as follows:
1) We propose a novel representation learn-ing method BiDRL which directly learns billearn-ingual document representations for cross-lingual senti-ment classification. Different from previous stud-ies which only obtain word embeddings, our mod-el can learn vector representations for both words and documents in bilingual texts.
2) Our model leverages both the semantic and sentiment correlations between bilingual docu-ments. Not only the parallel documents but al-so the documents with the same sentiment are re-quired to get similar representations.
3) Our model achieves the state-of-the-art per-formances on nine benchmark cross-lingual sen-timent classification tasks and it consistently out-performs the existing methods by a large margin.
2 Related Work
Sentiment analysis is the field of studying and an-alyzing people’s opinions, sentiments, evaluation-s, appraisalevaluation-s, attitudeevaluation-s, and emotions (Liu, 2012). Most of the previous sentiment analysis research-es focus on customer reviews and classifying the sentiment polarity is the most widely studied task (Pang et al., 2002).
Cross-lingual sentiment classification is a pop-ular topic in the sentiment analysis community
which aims to solve the sentiment classification task from a cross-language view. It is of great im-portance for the area since it can exploit the ex-isting labeled information in a source language to build a sentiment classification system in any other target language. It saves us from manually label-ing data for all the languages in the world which is expensive and time-consuming. Cross-lingual sentiment classification has been extensively stud-ied in the very recent years. Mihalcea et al. (2007) translate English subjectivity words and phrases into the target language to build a lexicon-based classifier. Banea et al. (2010) also use the machine translation service to obtain parallel corpus. It in-vestigates several questions based on the parallel corpus including both the monolingual sentiment classification and cross-lingual sentiment classifi-cation. Wan (2009) translates both the training da-ta (English to Chinese) and the test dada-ta (Chinese to English) to train different models in both the source and target languages. The co-training algo-rithm (Blum and Mitchell, 1998) is used to com-bine the bilingual models together and improve the performance. In addition to the translation-based methods, several studies utilize parallel corpus or existing resources to bridge the language barrier. Balamurali (2012) use WordNet senses as features for supervised sentiment classification. They use the linked WordNets of two languages to bridge the language gap. Lu et al. (2011) consider the multilingual scenario where small amount of la-beled data is available in the target language. They attempted to jointly classify the sentiment for both source language and target language. Meng et al. (2012) propose a generative cross-lingual mixture model to leverage unlabeled bilingual parallel da-ta. Prettenhofer and Stein (2010) use the structural correspondence learning algorithm to learn a map between the source language and the target lan-guage. Xiao and Guo (2014) treat the bilingual feature learning problem as a matrix completion task.
cor-pus. Xiao and Guo (2013) learn different repre-sentations for words in different languages. Part of the word vector is shared among different lan-guages and the rest is language-dependent. Kle-mentiev et al. (2012) treat the task as a multi-task learning problem where each task corresponds to a single word, and task relatedness is derived from co-occurrence statistics in bilingual parallel data. Hermann and Blunsom (2015) propose the bilin-gual CVM model which directly minimizes the representation of a pair of parallel documents. The document representation is calculated with a com-position function based on words. Chandar A P et al. (2014) and Zhou et al. (2015) use the autoen-coder to model the connections between bilingual sentences. It aims to minimize the reconstruction error between the bag-of-words representations of two parallel sentences. Luong et al. (2015) pro-pose the bilingual skip-gram model which lever-ages the word alignment between parallel sen-tences. Pham et al. (2015) extend the paragraph vector model to force bilingual sentences to share the same sentence vector.
This study differs with the existing works in the following three aspects, 1) we exploit both the se-mantic and sentiment correlations of the bilingual texts. Existing bilingual embedding algorithm-s only ualgorithm-se the algorithm-semantic connection between par-allel sentences or documents. 2) Our algorithm learns both the word and document representation-s. Most of the previous studies simply compute the average of the word vectors in a document. 3) Sentiment labels are used in our embedding algo-rithm by introducing a classification hyperplane. It not only helps to achieve better embedding perfor-mance in each individual language but also helps to bridge the language barrier.
3 Framework
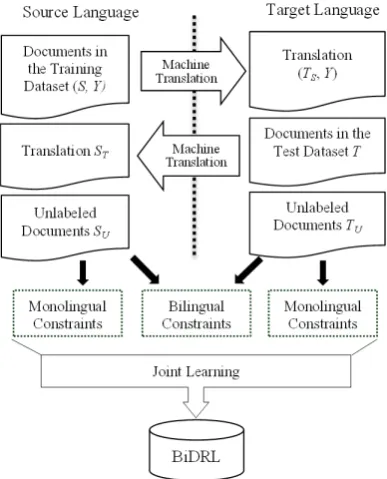
Firstly we introduce several notations used in BiDRL. LetSandSudenote the documents from the training dataset and the documents from the unlabeled dataset in the source language respec-tively. For each documentd ∈ S, it has a senti-ment labely ∈ {1,−1}. We denote the sentiment label set of all the documents in S asY. Let T
andTudenote the documents from the test dataset and the documents from the unlabeled dataset in the target language. The documents in the training and test datasets in the source and target languages are translated into the other language using the
on-Figure 1: Framework of BiDRL
line machine translation service - Google Trans-late1. We denote them asTs(the translation ofS)
and St (the translation of T). We wish to learn aD-dimensional vector representation for all the documents in the dataset.
The general framework of BiDRL is shown in Figure 1. After we obtain the data in the source and target languages, we propose both the mono-lingual and bimono-lingual constraints to learn the mod-el. The monolingual constraints help to model words and documents in each individual language. The bilingual constraints help to build a consis-tent embedding space across different languages. The joint learning framework is semi-supervised which uses the sentiment labelsY of the training documents.
3.1 Monolingual Constraints
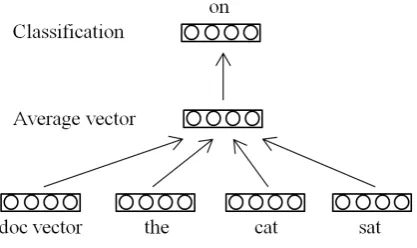
In this subsection, we describe the representation learning algorithm for the source and target lan-guages. We start from the paragraph vector model (Le and Mikolov, 2014) which has been proved to be one of the state-of-the-art methods for doc-ument modeling. In the paragraph vector frame-work, both documents and words are mapped to unique vectors. Each document is treated as a u-nique token which is the context of all the words in the document. Therefore, each word in the
[image:3.595.321.515.63.303.2]Figure 2: Paragraph vector
ument can be predicted by the context tokens and the document as shown in Figure 2. The idea leads to the following function,
arg maxX d∈D
X
(w,C)∈d
logp(w|C, d) (1)
where D is the document set, w and C are the word and its context in a documentd. The only d-ifference between paragraph vector algorithm and the well-known word2vec algorithm (Mikolov et al., 2013) is the additional document vector.
The conditional probability of predicting a word from its context is modeled via softmax which is very expensive to compute. It is usually ap-proximately solved via negative sampling. A log-bilinear model is used instead to predict whether two words are in the same context. For a word and context pair(w, C)in a documentd, the objective function becomes,
L1=−logσ(vwT·k+ 11 ·(vd+X c∈C
vc))−
n
X
i=1
Ew0∈pn(w)(logσ(−vw0T· 1
k+ 1·(vd+ X
c∈C
vc))) (2)
whereσ(·)is the sigmoid function,cis a contex-t word inC,k is the window size,vw andvcare the vectors for words and context words,vdis the vector for the documentd,w0is the negative sam-ple from the noise distribution Pn(w). Mikolov et al. (2013) setPn(w)as the 34 power of the uni-gram distribution which outperforms the uniuni-gram and the uniform distribution significantly.
The paragraph vector model captures the se-mantic relations between words and documents. In addition, we hope that the vector representation
of a document can directly reflect its sentimen-t. The document vectors associated with different sentiments should fall into different positions in the embedding space. We introduce a logistic re-gression classifier into the embedding algorithm. For each labeled documentdwith the labely, we use it to classify the sentiment based on the cross entropy loss function,
L2 =−ylogσ((xTvd+b)
−(1−y) logσ(−xTv
d−b)) (3)
wherexis the weight vector for the features andb
is the bias,vdis the document vector.
Combining the above two loss functions, we ob-tain the monolingual embedding algorithm. For the source language, we get the word and docu-ment representations via
arg minLs= X
d∈S∪Su X
(w,C)∈d
L1+X d∈S
L2 (4)
The embedding for the target language is ob-tained similarly,
arg minLt= X
d∈T∪Tu X
(w,C)∈d
L1+
X
d∈Ts
L2 (5)
where the labeled datasetTsis translated from the source language.
3.2 Bilingual Constraints
The key problem of bilingual representation learn-ing is to obtain a consistent embeddlearn-ing space across the source and the target languages. We propose three strategies for BiDRL to bridge the language gap.
original documents and the translated documents. Such word or document based regularizer is wide-ly used in previous works (Gouws et al., 2015; Zou et al., 2013). We simply measure the differences of two documents via the Euclidean Distance. The parallel documents refer to the documents inSand
Tand their corresponding translations (StandTs). It leads to the following loss function,
L3 =
X
(ds,dt)∈(S,Ts)
kvds −vdtk2
+ X
(ds,dt)∈(St,T)
kvds−vdtk2
(6)
where(ds, dt)is a pair of parallel documents and
v∗is their vector representations.
Our third strategy aims to generate similar rep-resentations for texts with the same sentiment. The traditional paragraph vector model focuses on modeling the semantic relationship between words and documents while our method aims to preserve the sentiment relationship as well. For each doc-umentd ∈ S in the source language, we findK
least similar documents with the same sentimen-t. The document similarity is measured by cosine similarity using TF-IDF features. We hope that theseK documents should have similar represen-tation with documentddespite of their textual d-ifference. We denote theKdocuments asQsand their parallel documents in the target language as
Qt. It leads to the following loss function,
L4 =
X
d∈S
( X
ds∈Qs
kvds −vdk2
+ X
dt∈Qt
kvdt −vdk2)
(7)
where v∗ denotes the vector representation of a document.
Combining the monolingual embedding algo-rithm and the cross-lingual correlations, we have the overall objective function as follows,
arg minL=Ls+Lt+L3+L4 (8)
which can be solved using stochastic gradient de-scent (SGD).
After learning BiDRL, we represent each doc-ument in the training and test dataset by the con-catenation of its vector representation in both the source and the target languages. In particular, for each training documentd∈ S, we represent it as [vdvd0] where d0 is its corresponding translation
andv∗ is the learned document representation in BiDRL. Similarly, for each test documentd∈T, we represent it as[vd0 vd]. Afterwards, a logistic
regression classifier is trained using the concate-nated feature vectors ofS. The polarity of the re-views inT can be predicted by applying the clas-sifier on the concatenated feature vectors ofT.
4 Experiments
4.1 Dataset
We use the multilingual multi-domain Amazon re-view dataset2 created by (Prettenhofer and Stein,
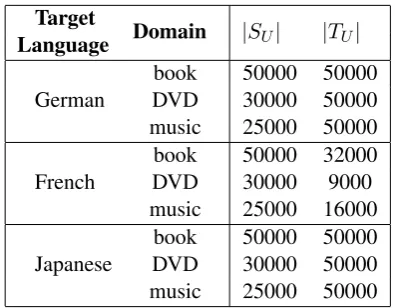
2010). It contains three different domains book, DVD and music. Each domain has reviews in four different languages English, German, French and Japanese. In our experiments, we use English as the source language and the rest three as target lan-guages. Therefore, we have a total of nine tasks with different combinations of three domains and three target languages. For each task, the training and test datasets have 1000 positive reviews and 1000 negative reviews. There are also several t-housand of unlabeled reviews but the quantity of them varies significantly for different tasks. Fol-lowing (Prettenhofer and Stein, 2010), when there are more than 50000 unlabeled reviews we ran-domly selected 50000 of them, otherwise we use all the unlabeled reviews. The detailed statistics of the dataset are shown in Table 1.
We translated the 2000 training reviews and 2000 test reviews into the other languages using Google Translate. Prettenhofer and Stein (2010) has already provided the translation of the test da-ta. We only need to translate the English training data into the three target languages. All the review texts are tokenized and converted into lowercase. We use Mecab3to segment the Japanese reviews.
4.2 Implementation
In the bilingual representation learning algorithm, we set the vector size as 200 and the context win-dows as 10. The learning rate is set to 0.025
fol-2https://www.uni-weimar.de/medien/
webis/corpora/corpus-webis-cls-10/
Target Language Domain MT-BOW MT-PV CL-SCL BSE CR-RL Bi-PV BiDRL
German DVDbook 79.6877.92 79.9080.09 79.5076.92 80.2777.16 79.8977.14 78.6079.51 84.1484.05 music 77.22 80.71 77.79 77.98 77.27 82.45 84.67
French DVDbook 80.7678.83 80.1481.49 78.4978.80 -- 78.2574.83 79.6084.25 84.3983.60 music 75.78 81.92 77.92 - 78.71 80.09 82.52
[image:6.595.82.280.266.420.2]Japanese DVDbook 70.2271.30 67.4568.86 73.0971.07 70.7574.96 71.1173.12 75.4071.75 73.1576.78 music 72.02 74.53 75.11 77.06 74.38 75.45 78.77 Average Accuracy 75.97 77.23 76.52 74.26 76.08 78.57 81.34 Table 2: Cross-lingual sentiment classification accuracy for the nine tasks. For all the methods, we get ten different runs of the algorithm and calculate the mean accuracy.
Target Domain |S
U| |TU|
Language
German DVDbook 50000 5000030000 50000 music 25000 50000
French DVDbook 50000 3200030000 9000 music 25000 16000
Japanese DVDbook 50000 5000030000 50000 music 25000 50000 Table 1: The amount of unlabeled reviews used in the experiments. There are also 1000 positive and 1000 negative reviews both for training and test in each task, i.e.|S|=|T|= 2000.
lowingword2vecand it declines with the train-ing procedure.Kis empirically chosen as 10. The algorithm runs 10 iterations on the dataset.
4.3 Baseline
We introduce several state-of-the-art methods used for comparison in our experiment as follows.
MT-BOW: It learns a classifier in the source language using bag-of-words features and the test data is translated into the source language vi-a Google Trvi-anslvi-ate. We directly use the experi-mental results reported in (Prettenhofer and Stein, 2010).
MT-PV:We translate the training data into the target language and also translate the test data into the source language. In both the source and target languages, we use the paragraph vector model to learn the vector representation of the documents. Therefore, each document can be represented by
the concatenation of the vector in two languages. A logistic regression classifier is trained using the concatenated feature vectors similarly to BiDRL. MT-PV can be regarded as a simplified version of BiDRL without theL2,L3andL4regularizers.
CL-SCL:It is the cross-lingual structural corre-spondence learning algorithm proposed by (Pret-tenhofer and Stein, 2010). It learns a map between the bag-of-words representations in the source and the target languages. It also leverages Google Translate to obtain the word translation oracle.
BSE: It is the bilingual embedding method of (Tang et al., 2012). It aims to learn two differen-t mapping madifferen-trices for differen-the source and differen-targedifferen-t lan-guages. The two matrices map the bag-of-words representations in the source and the target lan-guages into the same feature space. Tang et al. (2012) only report their results on 6 of the 9 tasks.
CR-RL:It is the bilingual word representation learning method of (Xiao and Guo, 2013). It learn-s different reprelearn-sentationlearn-s for wordlearn-s in different languages. Part of the word vector is shared a-mong different languages and the rest is language-dependent. The document representation is calcu-lated by taking average over all words in the doc-ument.
vector representation for the training and test da-ta using both the original and the translated texts. Each pair of parallel documents shares the same document representation.
We also implement the method of (Zhou et al., 2015) which is originally designed for the English-Chinese cross-lingual sentiment classifi-cation task. We find that it is not very adapt-able in our case because the negation pattern and sentiment words are hard to choose for our target languages. The results of our replication do not achieve comparable results with the rest method-s and are not limethod-sted here to avoid mimethod-sleading the readers.
4.4 Results and Analysis
Table 2 shows the experimental results for all the baselines and our method. For all the nine tasks, our bilingual document representation learning method achieves the state-of-the-art performance. The two most simple approaches MT-BOW imple-mented by (Prettenhofer and Stein, 2010) and MT-PV implemented by us are both strong baselines. They achieve comparable results with the more complex baselines on many tasks. MT-PV per-forms better than MT-BOW on most tasks which proves that the representation learning method is more useful than the traditional bag-of-words fea-tures.
The three word-based representation learning methods CL-SCL, BSE and CR-RL achieve sim-ilar results with the simple model MT-BOW and only outperform it on some tasks. However, the document representation learning methods MT-PV, Bi-PV and BiDRL performs much better. It shows that capturing the compositionality of words is important for sentiment classification. The isolated word representations are not enough to model the whole document. The Bi-PV model outperforms MT-PV on most tasks and shows that the authors idea of learning a single representation for a pair of parallel documents is more useful than learning them separately.
For all the baselines and our method, the perfor-mance of the English-Japanese tasks is lower than that of the English-German and English-French tasks. It is reasonable because the English lan-guage is much closer to German and French than Japanese. The machine translation tool also per-forms better when translating between the Western languages.
Our BiDRL model outperforms all the existing methods on all the tasks. The accuracy is over 80% on all the six tasks for the two European tar-get languages. The mean accuracy of the nine tasks shows a significant gap between BiRDL and the existing models. It achieves an improvement about 3% compared to the previous state-of-the-art methods.
4.5 Parameter Sensitivity Study
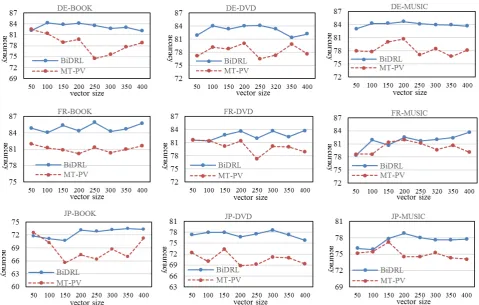
In this subsection, we investigate the influence of the vector size of our representation learning algo-rithm. We conduct the experiments by changing the vector size from 50 to 400. For each parameter setting, we run the algorithm for ten times and get the mean accuracy.
The results of MT-PV and BiDRL on all the nine tasks are shown in Figure 3. For almost all the tasks, we can observe that our model BiDRL steadily outperforms the strong baseline MT-PV. It proves the efficacy of our bilingual embedding constraints.
For most of the nine tasks including DE-DVD, DE-MUSIC, FR-DE-DVD, FR-MUSIC and JP-MUSIC, the performance of BiDRL increases with the growth of the vector size at the begin-ning and remains stable afterwards. For the rest tasks, our model responds less sensitively to the change of the vector size and the prediction accu-racy keeps steady. However, the results of MT-PV show no regular patterns with the change of the vector size which makes it hard to choose a satis-fying parameter value.
The parameter K is empirically chosen as 10 because we find that its value has little influence to our model when it is chosen between 10 and 50. Selecting a smallKwill help to accelerate the training procedure.
4.6 Analysis of the Sentiment Information
The traditional paragraph vector model only mod-els the semantic relatedness between texts via the word co-occurrence statistics. In this study, we propose to learn the bilingual representation uti-lizing the sentiment information. Firstly, we in-troduce a classification hyperplane to separate the embedding of texts with different polarities, i.e the loss functionL2. Secondly, we consider the texts
Figure 3: Influence of vector size for the nine cross-lingual sentiment classification tasks
results of our model without using these sentiment information.
Model MT-PV BiDRL-L2 BiDRL-L4 BiDRL
Accuracy 77.23 79.51 80.43 81.34 Table 3: Influence of the sentiment information. We only show the mean accuracy of the nine tasks due to space limit.
MT-PV can be regarded as BiDRL without all the sentiment information. It achieves lower re-sults than the other three methods. We can also observe that removingL2orL4both decreases the
accuracy. It proves that the sentiment information helps BiDRL to achieve better results.
5 Conclusion and Future Work
In this study, we propose a bilingual documen-t represendocumen-tadocumen-tion learning medocumen-thod for cross-lingual sentiment classification. Different from previ-ous studies which only get bilingual word embed-dings, we directly learn the vector representation for documents in different languages. We propose three strategies to achieve a consistent embedding space for the source and target languages. Both
sentiment and semantic correlations are exploited in our algorithm while previous works only use the semantic relatedness between parallel docu-ments. Our model is evaluated on a benchmarking dataset which contains three different target lan-guages and three different domains. Several state-of-the-art methods including several bilingual rep-resentation learning models are used for compar-ison. Our algorithm outperforms all the baseline methods on all the nine tasks in the experiment.
Our future work will focus on extending the bilingual document representation model into the multilingual scenario. We will try to learn a single embedding space for a source language and mul-tiple target languages simultaneously. In addition, we will also explore the possibility of using more complex neural network models such as convolu-tional neural network and recurrent neural network to build bilingual document representation system.
Acknowledgments
Pro-gram (863 ProPro-gram) of China (2015AA015403, 2014AA015102) and IBM Global Faculty Award Program. We thank the anonymous reviewers for their helpful comments. Xiaojun Wan is the corre-sponding author.
References
AR Balamurali. 2012. Cross-lingual sentiment analy-sis for indian languages using linked wordnets. In Proceedings of 2012 International Conference on Computational Linguistics (COLING), pages 73–82. Carmen Banea, Rada Mihalcea, and Janyce Wiebe. 2010. Multilingual subjectivity: Are more
lan-guages better? In Proceedings of the 23rd
in-ternational conference on computational linguistic-s, pages 28–36. Association for Computational Lin-guistics.
Avrim Blum and Tom Mitchell. 1998. Combining
la-beled and unlala-beled data with co-training. In
Pro-ceedings of the eleventh annual conference on Com-putational learning theory, pages 92–100. ACM. Johan Bollen, Huina Mao, and Xiaojun Zeng. 2011.
Twitter mood predicts the stock market. Journal of
Computational Science, 2(1):1–8.
Sarath Chandar A P, Stanislas Lauly, Hugo Larochelle, Mitesh Khapra, Balaraman Ravindran, Vikas C. Raykar, and Amrita Saha. 2014. An autoencoder approach to learning bilingual word representations. InAdvances in Neural Information Processing Sys-tems, pages 1853–1861.
Michael Gamon. 2004. Sentiment classification on customer feedback data: noisy data, large feature
vectors, and the role of linguistic analysis. In
Pro-ceedings of the 20th international conference on Computational Linguistics, page 841. Association for Computational Linguistics.
Stephan Gouws, Yoshua Bengio, and Greg Corrado. 2015. Bilbowa: Fast bilingual distributed
represen-tations without word alignments. In Proceedings
of The 32nd International Conference on Machine Learning, pages 748–756.
Karl Moritz Hermann and Phil Blunsom. 2015. Multi-lingual models for compositional distributed
seman-tics. In Proceedings of 52rd Annual Meeting of
the Association for Computational Linguistic, pages 58–68.
Alexandre Klementiev, Ivan Titov, and Binod Bhat-tarai. 2012. Inducing crosslingual distributed
rep-resentations of words. InProceedings of
COLING-2012, pages 1459–1474.
Quoc Le and Tomas Mikolov. 2014. Distributed
repre-sentations of sentences and documents. In
Proceed-ings of the 31st International Conference on Ma-chine Learning (ICML-14), pages 1188–1196.
Bing Liu. 2012. Sentiment analysis and opinion min-ing. Synthesis lectures on human language tech-nologies, 5(1):1–167.
Bin Lu, Chenhao Tan, Claire Cardie, and Benjamin K. Tsou. 2011. Joint bilingual sentiment
classifica-tion with unlabeled parallel corpora. In
Proceed-ings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1, pages 320–330. Association for Computational Linguistics.
Thang Luong, Hieu Pham, and Christopher D. Man-ning. 2015. Bilingual word representations with
monolingual quality in mind. InProceedings of the
1st Workshop on Vector Space Modeling for Natural Language Processing, pages 151–159.
Xinfan Meng, Furu Wei, Xiaohua Liu, Ming Zhou, Ge Xu, and Houfeng Wang. 2012. Cross-lingual
mixture model for sentiment classification. In
Pro-ceedings of the 50th Annual Meeting of the Associ-ation for ComputAssoci-ational Linguistics: Long Papers-Volume 1, pages 572–581. Association for Compu-tational Linguistics.
Rada Mihalcea, Carmen Banea, and Janyce Wiebe. 2007. Learning multilingual subjective language
vi-a cross-linguvi-al projections. InProceedings of
ACL-2007, pages 976–983.
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S. Cor-rado, and Jeff Dean. 2013. Distributed representa-tions of words and phrases and their
compositional-ity. InAdvances in neural information processing
systems, pages 3111–3119.
Bo Pang, Lillian Lee, and Shivakumar Vaithyanathan. 2002. Thumbs up?: sentiment classification using
machine learning techniques. InProceedings of the
ACL-02 conference on Empirical methods in natural language processing-Volume 10, pages 79–86. As-sociation for Computational Linguistics.
Hieu Pham, Minh-Thang Luong, and Christopher D. Manning. 2015. Learning distributed
representa-tions for multilingual text sequences. In
Proceed-ings of NAACL-HLT, pages 88–94.
Peter Prettenhofer and Benno Stein. 2010. Cross-language text classification using structural
corre-spondence learning. InProceedings of the 48th
An-nual Meeting of the Association for Computational Linguistics, pages 1118–1127. Association for Com-putational Linguistics.
Jie Tang, Yuan Zhang, Jimeng Sun, Jinghai Rao, Wen-jing Yu, Yiran Chen, and Alvis Cheuk M. Fong. 2012. Quantitative study of individual emotional
s-tates in social networks.Affective Computing, IEEE
Transactions on, 3(2):132–144.
Andranik Tumasjan, Timm Oliver Sprenger, Philipp G. Sandner, and Isabell M. Welpe. 2010. Predicting elections with twitter: What 140 characters reveal
Xiaojun Wan. 2009. Co-training for cross-lingual
sen-timent classification. In Proceedings of the Joint
Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natu-ral Language Processing of the AFNLP: Volume 1-Volume 1, pages 235–243. Association for Compu-tational Linguistics.
Min Xiao and Yuhong Guo. 2013. Semi-supervised representation learning for cross-lingual text
clas-sification. InProceedings of EMNLP-2013, pages
1465–1475. Association for Computational Linguis-tics.
Min Xiao and Yuhong Guo. 2014. Semi-supervised matrix completion for cross-lingual text
classifica-tion. In Twenty-Eighth AAAI Conference on
Artifi-cial Intelligence, pages 1607–1614.
Huiwei Zhou, Long Chen, Fulin Shi, and Degen Huang. 2015. Learning bilingual sentiment word embeddings for cross-language sentiment
classifi-cation. In Proceedings of the 53rd Annual
Meet-ing of the Association for Computational LMeet-inguis- Linguis-tics, pages 433–440. Association for Computational Linguistics.