Mining Of Web Information Utilizing Spatial Web Mining
1Ch.S.K.V.R.Naidu,2T.Y.Ramakrushna1,2Assoc.Professor In CSE,
Indo American Institutions Technical Campus
Sankaram Village,Batlapudi Post,Anakapalli,Visakhapatnam District, Andhra Pradesh-531001
1[email protected],2[email protected] Abstract:
In this paper we ponder and exhibit truths about how to extricate the helpful data on the web furthermore give the shallow learning and examinations about data mining. Web mining is the utilization of data mining procedures to concentrate learning from web data, including web records, hyperlinks between reports, use logs of sites, and so on. This paper depicts the present, past and eventual fate of web mining. These days the World Wide Web has getting to be a standout amongst the most thorough data assets. It likely, if not generally, covers the data requirement for any client. Those distinctions make it testing to completely utilize Web data in a successful and proficient way. Web mining is the utilization of data mining methods to concentrate learning from web data including web reports, hyperlinks, log use of site and so forth. In this paper we extricate data from web utilizing spatial data mining. Spatial data mining is the procedure of attempting to discover examples in geographic data. Spatial data mining is the utilization of data mining systems. Spatial data mining takes after along the same capacities in data mining, with the end target to discover examples in topography. In this paper we give a presentation of spatial data mining and also web. At that point we concentrate on how data is separated from web utilizing some preprocessing methods or a few stages. It depicts a technique to separate helpful data from a site page utilizing spatial data mining. We are extricating hyperlinks and email from single and various sites that is the reason it is utilizing spatial data mining on the grounds that as a part of spatial mining data is removed from distinctive areas. Distinctive sites will have diverse web servers implies distinctive areas. This technique incorporates some preprocessing undertakings to concentrate data. That removed data will be learning.
Keyword: - Web Mining, Data mining, Mining
Categories, process of spatial web mining, Mining Text databases, data recovery.
I. Introduction
Data mining, a branch of software engineering and counterfeit consciousness, is the procedure of extricating examples from data. Data mining is seen
as an undeniably imperative apparatus by cutting edge business to change data into business knowledge giving an educational point of preference. It is right now utilized as a part of an extensive variety of profiling practices, for example, advertising, observation, extortion recognition, and logical revelation. The related terms data digging, data angling and data snooping allude to the utilization of data mining strategies to test bits of the bigger populace data set that are (or might be) too little for solid factual derivations to be made about the legitimacy of any examples found. These strategies can, notwithstanding, be utilized as a part of the production of new theories to test against the bigger data populaces. By and large, data mining (now and again called data or learning revelation) is the procedure of examining data from alternate points of view and compressing it into helpful data - data that can be utilized to build income, cuts costs, or both. Data mining programming is one of various logical instruments for investigating data. It permits clients to break down data from various measurements or points, order it, and condense the connections distinguished. Actually, data mining is the procedure of discovering connections or designs among many fields in vast social databases.
A. Spatial data mining
with the end goal to discover examples in topography. It has become out of the field of data mining, which at first centered around finding designs in literary and numerical electronic data. Spatial data mining is viewed as a more confused test than customary mining due to the troubles connected with breaking down items with solid presences in space and time. Spatial data mining is the utilization of data mining strategies to spatial data. Spatial data mining takes after along the same capacities in data mining, with the end goal to discover examples in topography. data mining and Geographic Data Systems have existed as two separate advancements, each with its own particular strategies, customs and ways to deal with representation and data examination. Likewise with standard data mining, spatial data mining is utilized principally as a part of the universe of promoting and retail. It is a method for settling on choices about where to open what sort of store. It can illuminate these choices by preparing prior data about what elements spur purchasers to go to one place and not another.
B. Spatial Data
Otherwise called geospatial data or geographic data it is the data or data that distinguishes the geographic area of elements and limits on Earth, for example, common or developed elements, seas, and then some. Spatial data is normally put away as directions and topology, and is data that can be mapped. Spatial data is regularly gotten to, controlled or dissected through Geographic Data Systems . Spatial data is about data that has a few measurements. It is some of the time alluded to as spatial data. It incorporates both geospatial data and structospatial data.
C. Process of Spatial Mining
1. Input Spatial Data: It is the data to the spatial mining process.
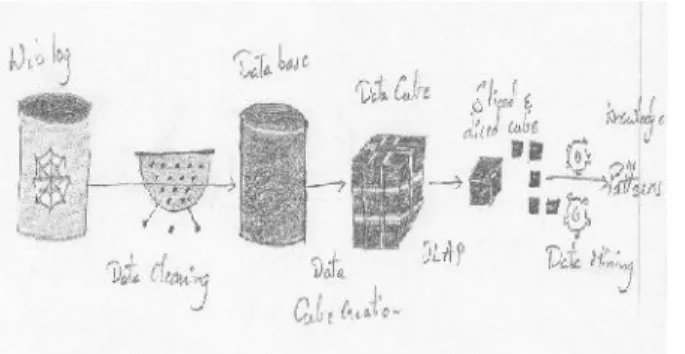
2. Character Library: Feature extraction and Feature database foundation. Spatial datum is the object of data mining. Since the current databases, data distribution centers, OLAP and data mining advances can not be utilized to handle spatial datum, it is
important to change over non-organizing spatial datum into organizing social table or extensional table firstly, keeping in mind the end goal to exploit such innovations. Store the components removed out and the first pixel esteem in the element data base, which is one wellspring of data mining case set. 3. Data Warehouse: This meaning of the data distribution center spotlights on data stockpiling. The fundamental wellspring of the data is cleaned, changed, classified and made accessible for use by directors and different business experts for data mining, online explanatory preparing, statistical surveying and choice backing. Be that as it may, the way to recover and examine data, to remove, change and stack data, and to deal with the data lexicon are likewise viewed as key parts of an data warehousing framework. Numerous references to data warehousing utilize this more extensive connection. In this way, an extended definition for data warehousing incorporates business insight devices, devices to extricate, change and stack data into the store, and instruments to oversee and recover metadata.
4. Data Extraction: Data extraction is the demonstration or procedure of recovering (paired) data out of (generally unstructured or inadequately organized) data hotspots for further data handling or data stockpiling (data movement). The import into the transitional extricating framework is along these lines ordinarily taken after by data change and perhaps the expansion of metadata before fare to another stage in the data work process.
5. Establishing and Training Model: Data mining model is a theoretical data structure, made, filled and gave question by data mining calculation. Through the info and yield strings of indicated data mining model and the utilization of mining calculation, data mining calculation can set up a vacant data mining model structure; and through embeddings the preparation set into data mining show, the preparation of the model is executed.
for further examination and estimate by utilizing learning.
7. Knowledge: All the valuable data toward the end will be data.
D. Web mining
These days, the World Wide Web has getting to be a standout amongst the most far reaching data assets. It most likely, if not generally, covers the data requirement for any client. Be that as it may, the Web shows numerous radical contrasts to customary data holders, for example, databases, in pattern, volume, point soundness. Those distinctions make it testing to completely utilize Web data in a compelling and proficient way. Web digging is ideal for this need indeed, Web mining can be considered as the uses of the general data mining systems to the Web. In any case, the characteristic properties of the Web make us need to tailor and develop the customary techniques significantly. Firstly, despite the fact that Web contains tremendous volume of data, it is dispersed on the web. Before mining, we have to accumulate the Web report together. Furthermore, Web pages are semi-organized, all together for simple preparing, records ought to be removed and spoke to into some configuration. Thirdly, Web data has a tendency to be of assorted qualities in me
II. Web Mining
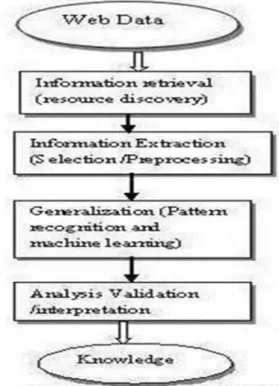
Web Mining depends on information disclosure from web. It is concentrate the information structure speaks to properly. Web min g is similar to a chart and all pages are hub and each associate with hyperlinks. Web mining is valuable to remove the data, picture, content, sound, video, reports and mixed media. By utilizing web mining effectively remove all elements and data about mixed media before this web mining hard to concentrate data in legitimate route from web. We seek the any theme from web hard to get exact subject data however Now's day it is anything but difficult to get the correct data about any things. Web using so as to mine depends on information mining system information mining strategy find the shrouded information in web log. Along these lines, web mining, however thought to be a specific utilization of information mining, warrants a different field of exploration. In view of the aforementioned four subtasks from above figure, web mining can be seen as the utilization of information mining systems to consequently recover, remove and assess data for learning revelation from web reports and benefits. Here, assessment incorporates both "speculation" and "examination.
Web Mining Categories:
Web mining can be sorted into three region of interest in light of which part of the web to mine: a) Web Content Mining
b) Web Structure Mining c) Web Usage Mining
a) Web Content Mining
Web mining is fundamentally extricate the data on the web. Which process is happen to get to the data on the web. It is web content mining. Numerous pages are interested in access the data on the web. These pages are substance of web. Seeking the data and open inquiry pages is likewise substance of web. Last exact result is characterized the outcome pages content mining.
Fig: Web Mining Processing b) Web Structure Mining
We can characterize web structure mining as far as diagram. The site pages are speaking to as hubs and Hyperlinks speak to as edges. Fundamentally it's demonstrated the relationship between client and web. The thought process of web structure mining is producing organized rundowns about data on website pages/networks. It is demonstrated the connection one site page to another website page.
c) Web Usage Mining
the use designs from online application. It is method to anticipate client conduct when it is communicate with the web.
Web utilization mining is classes in three
stages:-Preprocessing-According to customer, server and intermediary server it is first way to deal with recovers the crude information from web assets and handled the information .it is consequently changed the first crude information.
Design Discovery-According the information preprocessing found the learning and actualizes the systems to find the learning like as machine learning and information mining techniques are done at this stage.
Design Analysis-design examination is the procedure after example disclosure. Its check the example is right on the web and how to actualize on web to separate the data on your web look/remove learning from the web.
Fig: Web Mining Structure Web mining subtasks 1. Resource finding
2. Task of recovering planned web documentation 3. Information choice and pre process
4. Automatic choice and preprocessing particular from recovering different assets
5. Generalization
6. Automatic revelation of examples in sites 7. Analysis
8. Validation and translation of mined examples
III. Mining Text databases
Content databases:
Extensive gathering of reports from different sources: news articles, research papers, books computerized libraries, email messages &web pages, library database, and so forth. Information put away is generally semi organized. Customary data recovery systems get to be lacking for the inexorably endless measures of content information.
IV. Data recovery
A field created in parallel with database frameworks. Data is sorted out into reports; Information recovery comprises of a Typical IR frameworks and Online library indexes and record administration frameworks. Data recovery v/s database frameworks Some DB issues are not present in IR, e.g. upgrade exchange administration, complex articles. Some IR issues are not tended to well in DBMS.
Data recovery issue:
Finding significant archive in light of client info, for example, watchwords or sample reports.
Sample: Unstructured archives, rough hunt utilizing watchwords and significance.
Accuracy the rate of recovered archives that are actually pertinent to the question
Accuracy
Review the rate of reports that are important to the inquiry and were, truth be told recovered
Accuracy =
Console based recovery:
A report is spoken to by a string. Which can be recognized by an arrangement of catchphrases .Queries might utilize articulation of watchwords. E.g. auto and repair shop, tea or espresso. DBMS however not Oracle Queries and recovery ought to consider equivalent words, e.g. repair and support Technique
Make a term recurrence lattice, recurrence network SVD development; register the particular esteemed disintegration of freq-framework by part it into 3 grids, U,S,V
Vector recognizable proof: For every archive d supplant its unique record vector by another barring the disposed of terms.
File creation: store the arrangement of all vector ordered by one of various systems other content recovery indexing procedures Invested file
Keeps up two hash : or B+-tree ordered.
Report _table : an arrangement of archive records <doc id, postings _list>
Term_ table an arrangement of report term records <term, posting _ list>
Advantage: simple to actualize
Detriment: Do not handle well synonymy and polysemi, and posting records could be too long. Signature document:
Partner a mark with every record .A mark is a representation of a requested rundown of terms that depict the report. Request is gotten by recurrence investigation, stemming and stop records.
V. WEB SEARCH ENGINE
A web index is a product framework that is intended to scan for data on the World Wide Web. The indexed lists are for the most part displayed in a line of results frequently alluded to as web crawler results pages (SERPs). The data might be a blend of pages, pictures, and different sorts of records. Some web search tools additionally mine information accessible in databases or open indexes. Not at all like web catalogs, which are kept up just by human editors, have web crawlers likewise kept up real-time data by running a calculation on a web crawler.
VI. Web Search-Google
Google is a standout amongst the most mainstream and broadly utilized internet searchers. It gives clients access to data from more than 2 billion website pages that it has listed on its server. The quality and briskness of the inquiry office makes it the best web index. Prior web indexes focused on web content alone to give back the pertinent pages to an inquiry. Google was the first to present the significance of the connection structure in mining data from the web. Page Rank, which measures the significance of a page, is the hidden innovation in all Google look items, and utilizes auxiliary data of the web diagram to return top notch results. The Google toolbar is another administration gave by Google that looks to make seek less providing so as to demand and useful extra elements, for example, highlighting the inquiry words on the returned pages. The full form of the toolbar, if introduced, additionally sends the snap stream data of the client to Google. The utilization measurements in this way got are utilized by Google to improve the nature of its outcomes. Google additionally gives propelled look abilities to pursuit pictures and find pages that have been overhauled inside of a particular date range. Based on top of Netscape's Open Directory venture, Google's web index gives a quick and simple approach to seek inside of a specific point or related subjects.
VII. Page Rank Algorithm
Page Rank is a numeric worth that speaks to the significance of a page present on the web. At the point when one page connections to another page, it is adequately making a choice for the other page. More votes infers more significance. Significance of the page that is making the choice decides the significance of the vote. Google figures a page's
significance from the votes cast for it. Significance of every vote is considered when a's Page Rank is computed. Page Rank is Google's method for choosing a page's significance. Page Rank Notation is "PR" The first Page Rank calculation which was depicted by Larry Page and Sergey Brin is given by PR(A)=(1-d + d (PR(T1)/C(T1) + ... + PR(Tn)/C(Tn)) Where, PR(A)–Page Rank of page A PR(Ti)–Page Rank of pages Ti which connection to page A C(Ti) - number of outbound connections on page Ti d - Damping element which can be set somewhere around 0 and 1 A straightforward method for speaking to the equation is, (d=0.85) Page Rank (PR) = 0.15 + 0.85 * (an offer of the Page Rank of each page that connections to it) The measure of Page Rank that a page needs to vote will be its own particular worth * 0.85. This worth is shared just as among every one of the pages that it connections to. Page with PR4 and 5 outbound connections > Page with PR8 and 100 outbound connections. The counts don't work in the event that they are performed just once. Precise qualities are gotten through much emphasis. Assume we have 2 pages, An and B, which connection to one another and neither have some other connections of any sort. Page Rank of A relies on upon Page Rank estimation of B and Page Rank of B relies on upon Page Rank estimation of A. We can't work out A's Page Rank until we know B's Page Rank, and we can't work out B's Page Rank until we know A's Page Rank. In any case, performing more emphasess can bring the qualities to such a stage where the Page Rank qualities don't change. Along these lines more emphasess are vital while ascertaining Page Ranks.
TEXT BASED ALGORITHMS
The content based calculation comprise of numerous methods for drawing nearer information through mining. The accompanying are couple of methods for methodologies
1. A vision-based page segmentation algorithm 2. Discovering calculated relations from content 3. Spectral voice change for content to discourse blend
4. A new benchmark gathering for content arrangement research
5. Ontology learning for content 6. Word sence disambiguation
VIII. CONCLUSION
depends on some preprocessing ventures in information mining. The strategy identification.
REFERENCES
[1] He yue-shun ding qiu technique research on data mining based on semi structured data source. Journal of hurbin institute of technology.
[2] Raymond Kosala, Hendrik Blockeel, Web Mining Research: A Survey, ACM SIGKDD Explorations Newsletter, June 2000, Volume 2 Issue 1.
[3] Jidong Wang, Zheng Chen, Li Tao, Wei-Ying
Ma, Liu Wenyin, Ranking User’s Relevance to a Topic through Link Analysis on Web Logs, WIDM’
02, November 2002.
[4] Han, J., Kamber, M. Kamber. Data mining: concepts and techniques. Morgan Kaufmann Publishers, 2000.
[5] Wang Jicheng, Huang Yuan, Wu Gangshan, Zhang Fuyan. Web mining: knowledge discovery on the Web. Systems, Man, and Cybernetics, 1999. [6] Cooley, R.; Mobasher, B.; Srivastava, J.; Web mining: information and pattern discovery on the World Wide Web. Tools with Artificial Intelligence, 1997. Proceedings., Ninth IEEE International Conference. Page(s):558–567 - 3-8 Nov. 1997. [7] L. Getoor, Link Mining: A New Data Mining Challenge. SIGKDD Explorations, vol. 4, issue 2, 2003.
[8] O. Etzioni. The world wide web: Quagmire or gold mine. Communications of the ACM, 39(11):65-68, 2007.
[9]www.google.com