DEVELOPING A GROUP REGISTERING SYSTEM
USING APACHE SPARK TO ENHANCE SUBSTANTIAL
SCALE POINT INFORMATION SYSTEM TO MITIGATE
SECURITY THREATS IN CLOUD COMPUTING
Abhijeet Manohar
Student, Delhi Public School, RK Puram, New Delhi
ABSTRACT
Point cloud information assumes an exceptional job in different geospatial applications as it passes on abundant data which can be utilized for various kinds of investigation. The semantic research, which is an essential one of them, means to name focuses as multiple classes. In machine language, the issue is called arrangement. Likewise, handling point information is ending up increasingly difficult because of the developing information volume. In this paper, we address point information characterization in a significant information setting. The famous group registering system Apache Spark is utilized through the trials, and the promising outcomes recommend an extraordinary capability of Apache Spark for substantial scale point information preparing.
1.
INTRODUCTION
Point cloud information is progressively helpful to get because of the fast improvement of remote detecting advances, for example, UAV-based photogrammetry (Pix4D, 2014), indoor portable mapping (Viametris, 2014), and minimal effort buyer RGB-D sensor Microsoft, 2014). These emerging techniques and frameworks give an assortment of possible means for getting scenes with shifting scales, and an extensive volume of information can be created day by day. For instance, the AHN2 LIDAR informational index (AHN, 2014) covering the entire Netherlands is about half terabyte. Be that as it may, established information handling approaches are by and large performed on a single machine, they end up being not appropriate in light of the constrained processing and capacity limit. Accordingly, it is pivotal to make sense of an answer which can process such gigantic information proficiently.
gigantic point cloud information preparing utilizing distributed computing innovations, particularly Apache Spark.
Filling this hole, we present our work on one of the essential point cloud handling errands in the geospatial space - point cloud characterization. While an impressive assemblage of work exists on point cloud grouping, for substantial datasets, the size of information itself turns into a test. In this paper, we address the grouping issue in a significant information setting by applying distributed computing on expansive point mists. Promising trial results are additionally given to show the likelihood to use distributed computing in substantial scale geospatial applications.
Whatever is left of this paper is sorted out as pursues. The strategy for tree crown grouping is diagrammed in Section 2. The calculation is displayed in detail in Section 3 and also the implementation by methods for Apache Spark. In Section 4, the trial results are dissected and talked about. This remainder work is covered up in Section 5.
2. OVERVIEW
Point arrangement is a typical machine learning issue, solidly, connecting each point with a mark. The learning method in this paper is propelled by (Weinmann et al., 2014) which plans to decipher point mists semantically, while our work has practical experience in demonstrating whether a point has a place with a tree crown. Like (Weinmann et al., 2014), our work applies machine figuring out how to accomplish the ordered outcomes. The classifier is prepared to utilize irregular backwoods (Breiman, 2001) which is a vast number of choice trees. Point highlights for machine learning are processed dependent on the strategy proposed in (Demantke' et al., 2011). Seven distinct highlights (Weinmann et al., 2014) are utilized in our grouping issue, separately encoding linearity, planarity, disseminating, Omni fluctuation, anisotropy, Eigen entropy, and change of bend.
An essential contrast between our work and the ones up to made reference to is that monstrous parallelism in our usage is acknowledged utilizing distributed computing. This supplies our technique with remarkable adaptability. The whole test is led on a bunch propelled in Amazon EC2 benefit (Amazon, 2015). The general population accessible benchmark (Vallet et al., 2015) for public point cloud examination is additionally used to show the productivity and the power of our technique.
3 TREE CROWN CLASSIFICATION
In this segment, a tree crown arrangement technique is proposed. First, the calculation utilizing a machine learning procedure is displayed. The usage dependent on Apache Spark is examined in detail thereafter.
3.1 Algorithm
3.1.1 Feature calculation
Highlights assume a genuinely critical job in machine learning issues. Highlights with high calibre can rearrange learning models to translate the models all the more effective and upgrade calculation execution as for both the speed and the precision. In our concern, we plan to proficiently separate tree crown focuses and different focuses on methods for highlights. Targets in the area of a tree crown direct incline toward being scattered consistently along all beams from the essential issue, which demonstrates homogeneous dissemination. Then again, different focuses, by and large, uncover either the idea of 2D planes, for example, building aspects or the concept of 1D lines, for example, light posts. In such situation, Eigen estimations of covariance framework of focuses are reasonable measures to portray the dimensional data, which is thoroughly examined in (Demantke' et al., 2011). Solidly, seven 3D highlights dependent on Eigen esteems are utilized through our order technique has appeared in Table 1.
Table 1: 3D features of points
3.1.2 Random forest
Given an info point cloud with figured highlights depicted in Table 1 and right names, a classifier is prepared to utilize irregular woodland. When the classifier is created, the forecast procedure can be led on info information with highlight data. Arbitrary backwoods (Breiman, 2001) is a generally connected learning strategy which can be utilized for both characterization and relapse issues. An irregular backwoods is a mix of a few choice trees (Bishop, 2006) which play out the expectation by crossing the tree structure. Over-fitting frequently happens inside choice trees because of hard esteem split of each tree hub (Bishop, 2006), which is a noteworthy impediment. As a troupe of choice trees, arbitrary woodland defeats such issue by the goodness of weighted votes from different choice trees. Also, irregular backwoods additionally expressly performs include choice as every choice tree is made utilizing distinctive arbitrary highlights. In this way, great highlights can be chosen from an assortment of information includes with the goal that the forecast exactness can be enhanced substantially.
3.2 Implementation
3.2.1 Parallel Computing in Cloud
We use Apache Spark to satisfy the parallelization of our strategy in the cloud. Apache Spark is a fast and universally useful bunch processing library. Like Hadoop (White, 2009), it bolsters the outstanding MapReduce (Dean and Ghemawat, 2008) worldview. Furthermore, it presents the robust appropriated dataset (RDD) which can be held on in memory. This component can drastically upgrade the execution of Apache Spark over Hadoop particularly for applications with iterative tasks. It has turned into the most prominent bunch registering framework for large-scale information preparing in the business. In Apache Spark, a few helpful inherent modules are accessible including Spark SQL for SQL and organized information handling and MLib for machine learning. The usage of irregular timberland exists in the module MLib too.
In contrast to Hadoop, Apache Spark offers APIs in Java, Scala, Python and R. For point cloud information handling, the Python API is more advantageous, because of a lot of existing Python bundles for digital processing and less exertion to make a Python official for C++ libraries. This quality enables us to reuse existing libraries in Apache Spark applications effectively. Accordingly, the Python API of Apache Spark is utilized, and the whole code for our technique is composed in Python too.
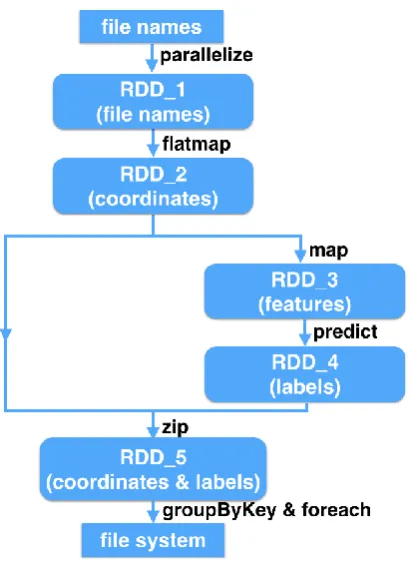
Figure 1: The directed acyclic graph (DAG) in our implementationusing Apache Spark
As showed in Figure 1, the main RDD 1 is instated from a rundown of record name strings through the activity parallelize. RDD 1 is apportioned and is disseminated over bunch hubs. Point cloud information is stacked as RDD 2 by applying flat map on RDD 1. RDD 2 can be viewed as a rundown of point components, and every part is a 3D vector speaking to the point organize. Highlights for taking in are processed from RDD 2 and spared as RDD 3, and after that anticipated outcomes are created by applying a pre-prepared model on RDD 3. The arrangement results are yielded into document framework by performing groupByKey and foreach on RDD 5 which is a blend of RDD 2 and RDD 4.
3.2.2 Visualization
Figure 2: The user interface of potree.
4. EXPERIMENTAL RESULTS
5. CONCLUSION
In this paper, a tree crown characterization technique is proposed and executed in the cloud stage. Apache Spark is received to satisfy the parallel registering. The exploratory outcomes show its promising execution for large-scale point cloud information handling.
REFERENCES
AHN, 2014. AHN2, http://www.ahn.nl/pagina/open-data.html.
Amazon, 2015. Amazon EC2, http://aws.amazon.com/ec2/.
Bishop, C. M., 2006. Pattern Recognition and Machine Learning(Information Science and Statistics). Springer-Verlag New York,Inc., Secaucus, NJ, USA.
Breiman, L., 2001. Random forests. Machine Learning 45(1),pp. 5–32.
Dean, J. and Ghemawat, S., 2008. MapReduce: Simplified dataprocessing on large clusters. Commun. ACM 51(1), pp. 107–113.
Demantk´e, J., Mallet, C., David, N. and Vallet, B., 2011. Dimensionalitybased scale selection in 3d lidar point clouds. TheInternational Archives of the Photogrammetry, Remote Sensingand Spatial Information Sciences 38(Part 5), pp. W12.
Microsoft, 2014. Kinect, https://www.microsoft.com/en-us/kinectforwindows/.
Pix4D, 2014. Pix4Dmapper, https://pix4d.com/products/.
Potree, 2015. Potree, https://github.com/potree/potree.
Vallet, B., Brdif, M., Serna, A., Marcotegui, B. and Paparoditis,N., 2015. Terramobilita/iqmulus urban point cloud analysisbenchmark. Computers & Graphics.Viametris, 2014. ViametrisiMMS,
http://viametris.info/iMMS/EN/.
Weinmann, M., Jutzi, B. and Mallet, C., 2014. Semantic 3dscene interpretation: a framework combining optimal neighborhoodsize selection with relevant features. ISPRS Annals of thePhotogrammetry, Remote Sensing and Spatial Information Sciences,Volume II-3.
White, T., 2009. Hadoop: The Definitive Guide. 1st edn, O’ReillyMedia, Inc.