3222 IJSTR©2019
www.ijstr.org
Development Of Speech Recognition System:
Using Combination Of Vector Quantization And
Linde-Buzo-Gray Algorithm
Sakshi Dua, Amit kamraAbstract: In this research work of automatic speech recognition (ASR), not ordinary speech but recorded form of Gurubani recitation by different speakers has been taken as input speech signals. The speech was in continuous mode with normal speed and fast speed while uttering the sentences. Speech was encapsulated with different kinds of noises (background noises and parallel noise of musical instruments) which was challenging task to be eliminated and performing optimal recognition rate. Vector Quantization and Linde Buze Gray (LBG) algorithm has been used for the recognition of speech sentences. The implementation focuses on speech to text process by performing recognition of recited hymns (Continuous input speech) as existing models are working for recognizing ordinary and continuous speech/interview speech. The paper is a research paper that focuses on recognizing sentences of uttered speech (recited Gurubani Hymns) as a continuous mode of speech. The main objective was to recognize tonal sentences (recited hymns-Japji sahib Ji with different Raags). LBG algorithm with MFCC feature extraction has been used that yielded 92.6% accuracy and 13.89% as word error rate.
Index Terms :- ASR, Feature extraction, Gurubani Hymns, LBG, MFCC, Segmentation, Vector Quanitizatio
————————————————————
1I
NTRODUCTIONBroad range of speech recognition models on various languages for different speech modes has been implemented by various researchers. Automatic Speech Recognition is a technique of representing modulating function where speech signals are converted and presented into set of speech words with the aid of algorithm. This is possible by establishing communication between computers and human beings. The vocabulary involved in speech recognition systems for set of words/sentences has been reached to thousand of words i.e. continuous mode of speech. Two variations are available in ASR. Speech recognition where recognition is performed on the basis of feature selected from input speech. Speaker Identification, identification of individual speaker takes place. Nowadays, this process is employed in Biometric recognition method that establishes interface of user with computer or machine. The basic technique behind this entire structure is to develop efficient and skilled algorithm by which input speech signal can be fed into computer. Feature extraction and Classification perform significant role in such systems. HMM and VQ are two traditional approaches to perform the task of recognition. Still, these techniques in conjunction with other techniques resulted hybrid techniques and yielding good accuracy rate of recognition. The significance of accuracy remained important factor due to the presence of different additional noises in input speech signals. These noises are inseparable part of input speech signals and reduction of such noise is highly considerable factor before the commencement of speech recognition process.
Figure. 1 Basic Structure of Speech Recognition system [2]
3223 IJSTR©2019
www.ijstr.org
Analysis (MEL), and Relative Spectra Filtering of Log Domain Coefficients (RASTA).
1. STATEMENT OF PROBLEM
In this work, speech-to-text process has been implemented. In place of ordinary speech, recitation of Gurubani hymns in the recorded form and in continuous mode of speech signals have been considered. 26 Different speakers (21 Females and 5 Males) were involved in designing the database for process. Due to lack of available database of Japji Sahib (Gurubani Sahib Ji) sentences recited by different speakers, database has to design. This database contains 38 sentences of Japji Sahib recited by 26 different speakers. Sampling rate of speech signals was 44100 Hz. Shure SV100 microphone has been used with NCH Suite software for recording. Background noises (hiss. Hum, rumble and babble noise) were present while recording along with parallel noise of instrumental music which was playing along with the recitation. This kind of noise elimination is one of the challenging task in this research work. Moreover, recitation of speech signals (sentences) was tonal that was also crucial part to be eliminated for good recognition rate.
2.
L
ITERATURER
EVIEWExisting literature review on recognition processes revealed work has been carried out on multiple languages and very large scale vocabulary. Thousand of words have been involved in speech recognition process. This work is different in itself, because not ordinary speech has been used. Recorded form of recitation by different speakers is used in this work. Literature review on continuous speech and LBG algorithm is collected and presented. Amanpreet Kaur and Tarandeep Singh (2010) worked for Punjabi speech recognition in which automatic segments have been made into syllable like units. Wiqas Ghai and Navdeep Singh (2013) worked for recognize continuous speech in Punjabi language by using Tri-Phone based acousting modeling and HTK 3.4.1 speech engine. The system has performed 82.18% and 94.32% level of accuracy for sentence and word level. Yogesh Kumar and Navdeep Singh (2016) worked for developing automatic spontaneous speech system for Punjabi language. Prior to this, no work for spontaneous speech was carried out. They have used sphinx toolkit and java programming for this spontaneous speech recognition system for live Punjabi interview. The system has yielded 98.6% and 98.8% for Punjabi sentences and Punjabi words respectively. Vedant Dhandhania and Jens Kofod Hansen et. al. (2012) presented Speaker Independent speech system for isolated Hindi digits. HMM has been used for training process and MFCC for feature extraction was used. System revealed 75% accuracy rate for 500 utterances. Aggarwal and Dave (2011) worked for Hindi Speech Recognition System by using Gaussian mixture and iterative procedures. HMM and MFCC along with extended MFCC has been used to carry out the procedure. System has revealed 82% accuracy for recognizing 400 whole words. Kumar and Aggarwal (2011) developed Speech Recognition System for Hindi by using HMM and its toolkit HTK. The system used 30 words of Hindi language and yielded 94.63%. Saini and Kaur et. al. (2013) has developed Hindi automatic Speech Recognition System using HMM and HTK. It was word recognition system that worked with 113 Hindi words and resulted with 96.61% and
95.49% accuracy level. Shyuu and Wang have worked for Mandarin and Japanese speech recognition system. It was syllables based research using HMM. Results were found as 86.5% and 93.5% accuracy rate for Chinese and Japanese words respectively. Nacereddine (2014) contributed for Arabic Automatic Speech Recognition by using two different approaches namely, Statistical Method and Copula based Tool. The overall accuracy for system was 93.09% - 95.34%. ABC () worked for Lithuanian Speech Recognition where system was able to recognize Lithuanian words and digits 0-9 where DTW and LPC techniques have been used. The system showed 0.83% error rate for speaker dependent mode and 1.94% error rate for speaker independent mode.
3.
M
ETHODOLOGY3.1 Overview
System is trained and tested by using same speakers against recited sentences of Gurubani hymns (Japji Sahib Ji). 26 different speakers recited 38 sentences of Japji Sahib Ji. 21 females and 5 male speakers were involved in this recognition process. Though, Vector Quantization is one of the well known traditional approach for recognition, it was proved suitable approach in implementing this speech recognition process. Linde-Buze-Gray algorithm has been used in this work. For extracting the features MFCC technique was used and manual segmentation has been done on input speech sentences recited by different speakers. Coding has been on MATLAB 9.2.
TABLE 1.DETAILS OF SPEAKERS
Number of Speakers (Training)
Male Speakers
Female
Speakers Age
26 5 21 >18 and
<60
TABLE 2.RECORDING DETAILS
Microphone
used Type
Background
Noises Parallel Noise
Shure SV100
Multi-Purpose Microphone
hum, rumble, crackle, babble and motor noise
Harmonium, and Tabla
3224 IJSTR©2019
www.ijstr.org
Figure 2. Block Diagram of MFCC process
Window is used to minimize the discontinuity of speech signal wrapping the beginning and ending of each frame to zero. Fast Fourier Transform converts the each frame to frequency domain from time domain. Mel Scale Filter is used to filter the signal by suing band-pass filter. In this work, MFCC has been used which has generated infinite features due to tonal and large number of sentences.
3.2 Vector Quantization (VQ) and Linde-Buze-Gray (LBG) algorithm
In this research work, Vector Quantization technique has been used. This technique is beneficial in data reduction. It generates optimal codebooks. The testing is evaluated by all the codebooks and system chooses the word whose codebook is with least distance measure. Codebooks are having no explicit time information and codebooks are not ordered, they are tend to come from anywhere from the training set of words. Dipmoy Gupta and Radha Mounima C. et al. (2012) have worked with this combination of VQ and LBG for text-dependent speaker identification system.
Figure 3. Block Diagram of Vector Quantizer (Makhoul 1985)
Vector Quantization is a quantization process of data in contiguous blocks known as vectors. Quantization is the process where infinite scalar/vector quantities are mapped to finite ones. Quantization has remarkable role in signal processing and image processing. VQ has expanded its wings due to introduction of algorithms like LBG algorithm. VQ uses several techniques- Split Vector Quantization (SVQ), Multistage Vector Quantization (MSVQ), Split-Multistage Vector Quantization (S-MSVQ). The performance of these stages relies upon the efficient generated codebooks which are generated by training set of speech signals. Computational complexity and memory requirement is usually decreased while decreasing the number of bits for generated codebooks. In this work, codebooks have been
generated in VQ by using LBG algorithm which is an iterative algorithm in itself. In VQ, finite number of regions is generated in that particular space. Each region is known as cluster and its center is known as code word. These code words are grouped together to form codebook. Here, training sequence of speech signals are taken as inputs. These training bits are the set of LSF vectors which are obtained from different speakers of different ages. LBG has performed its functionality as follows-The training sequence from the set of input speech samples have been recorded under noisy conditions along with parallel noise of Music with speech (recitation).
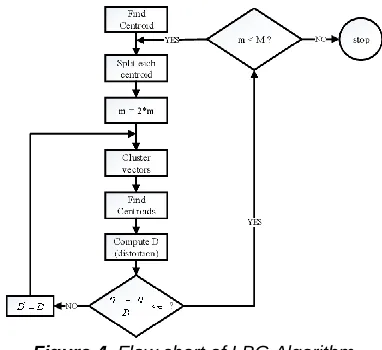
S= {xi Є Rd| where i=1 to n}
Centroids are then found. Centroids are the initial codebook values usually obtained from set of training patterns.
The obtained Centroids are then splitted to make relevant set of codeword
The difference between training sequence and codeword is generated and referred as D. Start obtaining new Centroids and replace old ones. The above procedure is repeated until desired numbers of codeword(s) are not found. To guarantee the convergence maximum number of iterations is required to be performed. At first, acoustic features (vectors) are extracted from input speech signals and yielded training vectors. Then the complex and important task is performed i.e., building VQ codebook by using prior discovered training vectors. Then, LBG algorithm was used for clustering the set of training vectors namely, L into set of codebook vectors namely M. It works as-Designing the Centroid of entire set of training vectors i.e., designing of 1-vector codebook. Then, double the size of codebook and splitting the every codebook to current size of codebook. Search for nearest-neighbor codeword against each training vector in current codebook is taken place. Search and match take place on the basis of similarity measurement or closest codebook. These vectors are then assigned to relative cell (closest codeword). Updations of codeword is occurred in each cell by using Centroids of training vectors. Iterative procedure is repeated until average distance is decreased below the values of preset threshold values and M, the size of codebook is not designed.
Figure 4. Flow chart of LBG Algorithm
3225 IJSTR©2019
www.ijstr.org
Here, Speech recognition system works by using LBG algorithm and VQ. Recorded sentences of Japji Sahib Ji spoken (recited) by different speakers have been recognized. Speech samples from 21 Female speakers and 5 Male speakers have been recorded. 1000 sentences were trained in this research. Samples with noise and parallel noise of music along with spoken sentences have been recorded. During training each word is segmented manually. The flow chart for developed system can be depicted as-
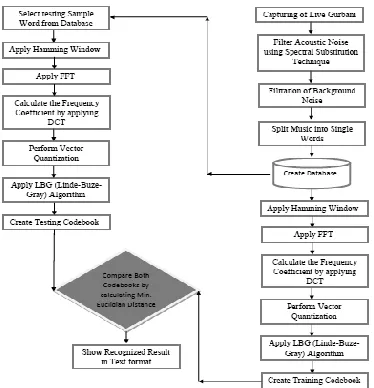
Figure 5. Flow Chart for developed speech recognition
system for Gurubani Hymns
3.4 Interpretation of Flow Chart
The step wise working flow of recognition system can be described as-
Training: capturing of recorded sentences of Japji Sahib Ji as continuous speech. Applying Filter: Acoustic Noise by using Spectarl Substitution Technique that makes use of FFT (Fast Fourier Transform) that allows to generate the spectrograms and sequences the frames for short-spectral speech and yields 2-Dimensional series S(ω, ti). These spectral values are derived and computed from the original speech signal i.e. x(t) from time window ∆t of input speech spectrums.
Filteration: Filteration of different background noises and parallel noise of music in few speech samples.
a) Creation of database as per the requirement. 26 different speakers were involved in process. Training and testing was done for similar speakers.
b) Windowing: Applying hamming window with L-frames
c) Calculating frequency coefficients by applying Discrete Cosine Transformation.
d) LBG and VQ worked by designing code set in MATLAB.
e) Training codebook is generated which is tested against testing codebook. The matching is performed by using Euclidean Distance Method.
Figure 6. Segmentation of words in sentence while training
4.
R
ESULTS ANDD
ISCUSSION12 different experiments have been made and results of them have been showed in following table. Testing results showed 92.6% accuracy with same speakers with same sentences and 64.30% accuracy with same speakers but with different speakers.
TABLE 3.EXPERIMENTAL EVALUATION
Exp. No.
Same Speakers, Different Sentences
(Testing)
Same Speakers Same Sentences (Testing)
Recog.
Rate WER
Recog.
Rate WER
Exp 1 84.87 11.57 91.33 10.67
Exp 2 74.42 10.75 93.56 11.88
Exp 3 75.02 13.88 92.90 11.09
Exp 4 74.45 11.97 94.06 10.98
Exp 5 75.28 12.05 92.55 9.55
Exp 6 84.78 9.95 91.34 12.45
Exp 7 85.67 10.89 91.09 13.22
Exp 8 84.32 11.99 90.01 10.12
Exp 9 65.09 12.45 93.89 9.43
Exp 10 74.06 13.77 94.66 10.99
Exp 11 85.11 14.55 92.44 11.89
Exp 12 74.78 12.99 93.76 10.67
Average
Results 64.30 30.08 92.6 13.89
5.
C
ONCLUSIONThe work is demonstrating the advancement in field of speech recognition by taking speech as recited hymns as continuous mode. 38 sentences were spoken by one speaker twice. The speech corpus was designed due to unavailability of built-in database for required speech. The speech has not been spoken (recited) in an ordinary way, it was tonal in nature and parallel noise of music was complex to be suppressed. This made recognition process tedious and segmentation of words made it possible to separate the words from music. Further, work can be carried out on live recitation.
6.
C
OMPETINGI
NTERESTThe authors are declaring that they have no competing interests.
3226 IJSTR©2019
www.ijstr.org
Speech Recognition or Automatic Speech Recognition (Speech-Text) is a process that recognizes the uttered speech by creating an interaction between human and machine. Our work aims to recognize the tonal sentences spoken in tonal voice facilitate the devotees to get all the recitations in Gurudwara Sahib Ji. This work is also beneficial for the old age and physical disable persons sitting outside the premises of Gurudwara Sahib Ji. Though our work aims to develop database for Japji Sahib Ji (Gurubani Hymn) and its scope can be extended by developing a database for many other hymns also. This can be viewed as extending the research work towards better human computer interaction.
A
CKNOWDGEMENTI would like to thank Amit Kamra for valuable and useful suggestions. Continuous support from his side is acknowledged.
R
EFERENCES[1] Haridas, A.V. & Marimuthu, R. & Sivakumar, V. G. ―A critical review and analysis on techniques of speech recognition: The road ahead‖, International Journal of Kniowledge-Based and Intelligent Engineering Systems‖, 22(1):39-57 · March 2018
[2] Dipmoy Gupta, Radha Mounima C. Navya Manjunath, Manoj PB ― Isolated Word Speech Recognition Using Vector Quantization (VQ)‖, International Journal of Advanced Research in Computer Science and Software Engineering, Volume 2, Issue 5, May 2012 ISSN: 2277 128X [3] Saksamudre, S. K. & Shrishrimal, P.P. & Deshmukh,
R. R. ―A Review on Different Approaches for Speech Recognition System‖, International Journal of Computer Applications (0975 – 8887) Volume 115 – No. 22, April 2015
[4] Dua, M & Aggarwal, R. & Kadyan, V. & Dua, S. ―Punjabi Automatic Speech Recognition Using HTK‖, IJCSI International Journal of Computer Science Issues, Vol. 9, Issue 4, No 1, July 2012 ISSN (Online): 1694-0814
[5] Hermansky, H. ―Speech recognition from spectral dynamics‖, Sadhan ¯ a¯ Vol. 36, Part 5, October 2011, pp. 729–744 © Indian Academy of Sciences [6] Marcus, S. & Iliasa, M. F. & Vatau, D. ― New
Interpolation Tools for Digital Signal Processing‖, IEEE, The International Conference on Information and Digital Technologies, 2016
[7] Raj B. & Parikh, V. N. & Stern, R. M. ―The Effects Of Background Music On Speech Recognition Accuracy‖, IEEE 1997
[8] M. Unser, "Splines: A perfect fit for signal and image processing," IEEE Signal Processing Magazine, vol. 16, no. 6, pp. 22-38, 1999.
[9] Gopalakrishnanetal, P. S. ―Suppressing background music from corrupted data of the ARPA Hub4 task‖, proceedings of ARPA speech recognition workshop. Pages 81-84, February, 1996.
[10]F. Jelinek, ―Continuous speech recognition by statistical methods‖, Proceedings of the IEEE, 64(4):532–556, Apr. 1976
[11]S. Levinson, ―Structural methods in automatic speech recognition‖. Proceedings of the IEEE, 73(11):1625–1650, Nov.
[12]Boruah S., Basishtha S., ―A Study on HMM based Speech Recognition System‖ IEEE, 2013
[13]Ghai W., Singh N., ―Continuous Speech Recognition for Punjabi Language‖, International Journal of Computer Applications (0975 – 8887) Volume 72– No.14, May 2013
[14]Mishra et. al., ―Study of robust extraction techniques for speech recognition system‖, IEEE, 2015
![Figure. 1 Basic Structure of Speech Recognition system [2]](https://thumb-us.123doks.com/thumbv2/123dok_us/8620359.1410067/1.612.324.559.298.507/figure-basic-structure-speech-recognition.webp)