International Journal of Business and Information
Using Blog Content Depth and Breadth
To Access and Classify Blogs
Meichieh Chen
Department of Social Intelligence & Informatics Graduate School of Information Systems
University of Electro-Communications Japan
Toshizumi Ohta
Graduate School of Information Systems &
Social Informatics Research Station University of Electro-Communications
Japan
ABSTRACT
Blogs are attractive to readers and researchers because of their ability to express a variety of opinions and critiques on topics. In particular, the fast growth of such online context brings in a strong demand for developing blog-specific filtering systems in order to identify and monitor the knowledge flow in the blogosphere. Traditional measures, which simply adopt link-analysis algorithms, are inadequate when it comes to blogs because of their sparseness of links. In this paper, we propose a filtering system that is able to assess the associated content of blog entries by measuring topic concentration and topic variety in terms of content depth and breadth with the scalars of informativeness, completeness, topic count, inter-topic distance, and topic mergence. These employed measures have proved to be appropriate for helping users to judge blogs they prefer among search results. Our system is different from existing blog search engines, as it aims to provide better relevance and precision of the search.
Volume 5, Number 1, June 2010
1.
INTRODUCTION
A blog is a prominent social medium that provides support for the issues bloggers deem interesting and important. Along with the development of the Internet and the increase in the prevalence and convenience of Web-related activities, blogs spontaneously transfer individuals’ opinions, interests, and desires in this knowledge-sharing platform inside virtual communities. According to the State of the Blogosphere, April 2007, from Technorati Weblog, more than 70 million Weblogs are tracked, about 120,000 new Weblogs are created worldwide each day, and 1.5 million blogs are posted daily. In terms of blog posts by language, Japanese ranks first at 37%, followed by English at 36%, Chinese at 8%, and Italian at 3% [34].
Besides offering a great pastime for its readers, a blog is also a rich source of consumer-generated media for marketers by which database-driven relationship marketing or the enlargement of market shares could be approached. Because of the huge online context database, machine learning techniques such as retrieval, clustering, and indexing that work on ordinary Web documents are widely applied in the blogosphere. Blog searches, however, have different interests than normal Web searches, which track references to known entities and focus on certain concepts [24]. The following examples give an idea of which blogs are likely to be interesting or useful to blog readers.
For instance, readers who are interested in cuisine may prefer blogs that share recipes, recommend kitchen utensils, or introduce lifestyle ideas. Among those readers, some may also be interested in blogs that talk about children’s education. Based on the classification, we assume that the cuisine lovers are more interested in one specific group of blogs and seek deep content instances; the interest in children’s education would only prompt for searches as broad content instances. Hence, we propose two aspects of measurement – content depth and content breadth – as the assessment model of the quality of blog contextual information.
International Journal of Business and Information The remainder of the paper is organized as follows. Section 2 discusses related studies. Section 3 proposes the method for measuring the depth and breadth of contextual information by using the five criteria of quality blog identification. Section 4 presents our approach for estimating the content depth and breadth of blog search results and validating it by the results of human experiment. Section 5 presents our conclusions.
2.
RELATED STUDIES
Blogs are popular because of their ability to express opinions and to critique various topics. The concept of quality-driven information filtering in the context of a blog-based information system is relatively young and highly diverse. In this section, we divide relevant research into three parts. The first part discusses the problem of current blog assessment. The second reviews existing approaches of blog quality assessment. The third discusses content assessment.
2.1. Blog Assessment
As the massive amount of information accessible via the Internet grows exponentially, users have more difficulty pinpointing the information they really need. Researchers pay a lot of attention to information filtering and data mining techniques in order to resolve this problem ([9, 30, 20, 1, 15]). Following the most popular information retrieval (IR) models, beginning with Google’s PageRank [5] and Kleinberg’s HITS [16] algorithms, search engines rank document relevance to a query quantitatively in terms of query term frequency and position, and qualitatively via a recursive metric of the quality of incoming links [38]. For instance, Technorati, a famous blog-specific search engine, calculates a measure of blog authority as the number of incoming blog links over a six-month period [34]. Similarly, many other blog-specific search engines, such as Bloglines, Feedster, and BlogPulse, index and search the RSS/XML feeds of blogs, using the boolean search.
Volume 5, Number 1, June 2010 2.2. Quality Assessment
The definition of information quality that adopted Joseph Juran’s definition of quality is “fitness for use” of information [4, 39, 36, 27, 8, 17]. Information quality assessment measures the quality dimensions that are relevant to the information consumer and compares the assessment results with the information consumer’s quality requirements [4]. An information quality assessment metric is a procedure for measuring an information quality dimension. Assessment metrics rely on quality indicators and calculate an assessment score from these indicators using a scoring function. Assessment metrics are heuristics that are designed to fit a specific assessment situation [4, 29].
Blog entries have been treated as being associated with ideas about an information item. To define a quality blog and to clarify the specific use of blog information, many researchers have discussed the characteristics of blog content and the user behavior of blogging. Mishne notes that blogs exhibit differences in language (more informal), in structure (a dense micro-community topology, typed links such as blogrolls and trackbacks with distinct meanings) [24], and the importance of recency.
Mishne and de Rijke did an extensive query log analysis of blog user behavior in terms of queries and page views. Their research determined that most of the named-entity queries for blogs are requests to learn what is being said currently about that entity, whereas the more general queries are often attempts to find blogs or posts on a topic of interest [25]. Fujimura also differentiates three characteristics of blog content from the general Web. First, for the purpose of entertainment, blog content is, on average, more interesting. Second, blog content reflects the bloggers’ personality. Third, blog content contains more personal opinions or real experience of products or services [10]. Hence, the traditional methods of information retrieval, which are suited for identifying popular Web posts, are no longer enough for accessing blogs.
Many studies of complex algorithms, which combine various quality indicators, have been developed to suit the demands of blog users. Since blog information is often subjective or opinion-oriented, and perhaps most important, the data is people-centric [13], some studies have been conducted to identify the influential bloggers from the micro viewpoint, such as analyzing the blog threads for discovering the important bloggers [26]; or measuring the influence of the blogosphere, from the macro viewpoint, such as focusing the topic-centric view of the blogosphere [2]; detecting the blogs’ growing trends [11]; and tracking the propagation of discussion topics in the blogosphere [12].
International Journal of Business and Information assessment of the importance of a news event in addition to popularity. He has identified a set of source, message, and reception features to formulate a measure of blog author credibility. Some distinguishing features are full name, affiliation, unquoted content, and links to news sources [38]. Those summarized quality indicators are reported to be able to improve application on blog post retrieval [40]. But most of the indicators, especially those related to content analysis, are subjective and hard to identify.
Given that there are many features of the information quality of blogs being discussed, we define the term “quality blog” in this paper as blogs with great content worthy of being explored. This definition is close to Sriphaew’s concept of “cool blog” [35]. The cool blog scenario is different, however, from our work since we put more effort on directly and immediately analyzing the correlation of topics that appear in blogs, entry by entry. On the other hand, the cool blog model studies the topic consistency of influential bloggers’ historical archives. Along with the pre-condition of inlink calculation, good writings which are not created by tenured bloggers are not easily recognized.
2.3. Content Assessment
Content-based filtering (CBF) is one of the oldest methods for percolating data. Systems using this method analyze the content of a set of items together with the ratings provided by individual users to infer which non-rated items might be of interest for a specific user [15]. This method has severe problems. One major difficulty in designing CBF systems lies in the problem of formalizing human perception and preferences. The reason one user likes or dislikes a joke, or prefers one CD over another, is virtually impossible to formalize. Similarly, it is difficult to derive features that represent the difference between an average news article and one of high quality [3]. Another problem occurs when data about items or users are limited. Some types of data may not have easily extractable information for detecting similarities [6]. Even when information about items can be found, systems may lack data about user preferences, resulting in inadequate or incoherent recommendations [15].
Volume 5, Number 1, June 2010
Focusing on sentiment analysis, our work challenges the categorization of style-based features that involve audiences’ reading preference and the accuracy of information extraction. We adopt the latent semantic analysis (LSA) algorithms for automatically indexing blog content and detecting topics [22], which applies the singular value decomposition (SVD) method to project the document vectors into a lower dimensional sub-space, measures semantic similarity, reflects the major associative pattern in the indexing data, and ignores the less representative information. SVD determines the correlation between the occurrence of terms and documents in the term by document matrix, and hence evaluates the “real” association of terms and documents. Some pattern of the occurrence of some words provides evidence of the likely occurrence of other words. Hence, terms with similar meanings of the search query are emphasized and the synonymy problem is almost resolved. At the same time, the co-relational structure analysis on predicting the likely occurrence of other terms based on the pattern of the occurrence of the query tries to anticipate the searcher’s desired knowledge, and hence reduces the effects caused by the polysemous issue [7].
3.
THE PROPOSED QUALITY ASSESSMENT MODEL
Given the suggestion from previous studies that the analysis of blog textual resources should be more topic oriented [10, 13], in this paper we decompose a blog into topic units and analyze its combination to estimate the quality of that blog.
On the basis of empirical investigation, we conduct the major premise of assessing quality blog as content depth and breadth and a set of information quality indicators for blog content. We define that the depth measurement is in charge of the narrative style of topic concentration, and the breadth is for topic variety. Over and above that, Tseng’s [37] definition on a well-written blog helps us to construct the blog quality indicators in detail, For example, the concept of decent length contributes our indicator of informativeness; the concept of strong opinions and views relates to our definitions of completeness, inter-topic distance, and topic identification; and the concept of innovative tips infers our idea of topic mergence indicator. That is, we develop two dimensions factors for blog quality measurement – content depth and content breadth – by which our method analyzes blog content through five indicators: informativeness, completeness, topic count, inter-topic distance, and topic mergence.
International Journal of Business and Information Wikipedia contains many semantic relationships [32]. As some authors [21, 33] have pointed out, initiatives like the Wikipedia platform, which allow easy and collaborative information exchange, can be of great help in making the semantic Web successful. In addition, Wiki communities have proved to be successful in collaboratively producing, at low cost, vast information repositories and lowering the technical barriers [32].
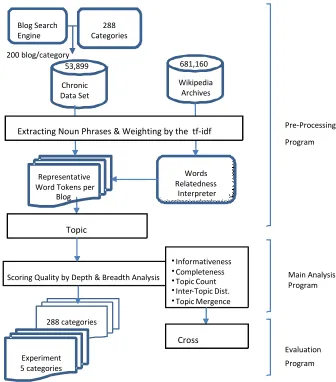
Figure 1. Analytical Framework of the Quality Assessment Model Pre-Processing
Program
Main Analysis Program Blog Search
Engine
200 blog/category
Chronic Data Set 53,899
288 Categories
Wikipedia Archives 681,160
Words Relatedness
Interpreter
Scoring Quality by Depth & Breadth Analysis
Evaluation Program •Informativeness
•Completeness •Topic Count •Inter-Topic Dist. •Topic Mergence Representative
Word Tokens per Blog
Extracting Noun Phrases & Weighting by the tf-idf
Topic
Clustering
Cross
Validation 288 categories
Volume 5, Number 1, June 2010
The LSA is used to identify topics given the relatedness scores of tokens inside each blog. After calculating the structural components of topic and word token, scores of indicators will be generated by the definitions of quality assessment components, informativeness, completeness, topic count, inter-topic distance, and topic mergence. Each of them must achieve admissible performance measures evaluated through cross-validation. Finally, the main analysis process enables the generated indicators to anticipate the classes of unseen contextual instances.
Based on statistical language processing, it is possible to treat a blog as a probabilistic mixture of topics where each topic is a probability distribution over words in a blog collection [14, 35]. The way we process analysis is to decompose a blog into topics and words, and study their structural composition in the blog. There are five quality criteria in the domains of content depth and breadth. Informativeness and completeness are in the domain of content depth; and topic count, inter-topic distance, and topic mergence are structured to content breadth. For all criteria except informativeness, we developed a topic model to estimate the composition and mixture of topics for each blog. We implemented the clustering algorithms for grouping representative tokens in a blog into at most three topic groups [35]. We define a unit of measurement nominated relatedness value, to evaluate the closeness of relationship between two different
terms, tj and tk, from the basis of 1,302,007 proper nouns, which have been
extracted from Wikipedia 681,160 articles by the tf-idf weight. The calculation of value is based on the degree of co-occurrence of two terms in the same
Wikipedia article.
3.1. Content Depth
Content depth is defined by the completeness of each topic and the number of meaningful terminologies used by the author. If writing has informative context or narrative completeness of each topic, we say the content of this writing is deep. For the different data properties, we define the informativeness and completeness as the indicators of contextual depth. All the indicators of content depth and content breadth are calculated on the basis of standard score:
The standard score is (1)
where X is a raw score to be standardized; is the mean of the population, and is the standard deviation of the population. Since the standardized informativeness and completeness indicators are independent of each other, the essentials of two indicators are additive. The operation also performs the best on the corresponding rate (see section 4.5) in the experiment. The content depth parameter is defined below, where i is the identification number of a blog entry.
International Journal of Business and Information Criterion 1. Informativeness (I):
We make an assumption that the more specific terminologies used in the text body, the more informative the blog is; and the more information could be transmitted to audiences. We applied the tf-idf weight to extract proper nouns from each blog entry. The extracted proper nouns are considered the representative word tokens of blog content. That is, we distinguished whether the writing is informative by retrieving the number of representative word tokens in a blog:
(3)
where is number of proper nouns ( t ) used in blog i.
Criterion 2. Completeness (C):
The completeness indicator tests the intra-topic closeness. We assume that if word tokens inside topic groups have a close relationship with each other, words are supportive to that topic argument. Semantic completeness of each topic is defined by the sum of relatedness values of word tokens inside each topic group. We assume that there are, at most, three topics in a blog entry based on our observation and the reference on another topic model that is used for analyzing blog content [35]. The function of completeness of a topic group is shown below. The completeness of a blog is the sum of all topic completeness scores within a blog.
Completeness of a Topic: (4)
Completeness of a Blog: (5)
where means the sequence of topic in a blog. i; .
3.2. Content Breadth
Volume 5, Number 1, June 2010
topics in a blog and their arrangement. The operation is also ascertained by the goodness of corresponding rate.
(6)
Criterion 3. Topic Count (TC):
Topic count indicator calculates the number of distinguishing topics in a blog. Each topic is considered as a composition of word tokens that are meaningfully connected. To formulate the benchmark, based on the observation of grouping results, we define that two terms with more than five time co-occurrences in Wikipedia corpus could be circulated into a topic group. The grouping process is shown below, by first defining A as a word token with the most topic coverage in a blog; in other words, with the greatest R value, A has the closest relation with other word tokens of blog. Those higher related word tokens, at least more than five times co-occurrence with word A in Wikipedia corpus, are aggregated as a topic group. Following the same logic, the rest of the word tokens are circulated into other topic groups.
(7)
where , , indicate topic 1, 2, 3; D is the ensemble of word tokens in blog i; is the number of word tokens in topic .
Criterion 4. Inter-Topic Distance ( ):
International Journal of Business and Information where
where ; (8)
Criterion 5. Topic Mergence ( )
Topic mergence is the indicator for tracking down the hidden idea that happened on the combination of two topics and could not be detected by the topic model from Criterion 3. For example, in a blog, two distinguishing topics – Korea and Food – are different from one merged topic (Korean food). It seems reasonable to suppose that if two terminologies are always used together, another idea that links these two terminologies occurs. That is what we call a hidden idea. Based on observations, most blog articles are not necessarily following the writing directories; for example, the narrative of one topic should be concentrated in one paragraph. Blog writing style is more innovative and is closer to human thinking. Applying the concept of moving variance, we tend to detect the overlapped part of topics.
where
(9)
where N is number of word tokens in blog i ; presents the group belonging of a word token ; V is variance.
4.
EXPERIMENTS
To study the effectiveness of our proposed blog quality assessment, we conducted experiments by exploiting different feature sets based on each criterion, and then investigated the experimental results.
4.1. Experiment Settings
To the best of our knowledge, there is no benchmark corpus for quality blog classification in terms of content depth and breadth, and the ranking technique of each blog search engine is impossible to be disclosed. For this study, we developed a crawling program to collect corpus limited to Yahoo’s blog search engine in Japanese on the Internet, since most commercial blog services prevent Web crawlers from visiting their blog sites.
Volume 5, Number 1, June 2010
business, recreation, sports, health, society, science, information, totally 288 categories as the inputted queries to identify 200 blog pages per category. In the data, there are 53,899 blog entries selected by time sequence, which is a random selection representing the whole blog population, from March 3, 2009, to March 5, 2009. The collected blog data covers time period that spans years.
4.2. Estimational Results
Given our assumptions of quality assessment in terms of content depth and breadth, the indicators informativeness and completeness are parts of construction for content depth; the indicators topic count, inter-topic distance, and topic mergence constitute content breadth. Through the main analysis program, the blog entries are transformed into numerical data and stored in regard to the unique blog identifiers, belonging key phrases, number of comment in years since the blog search engine was launched by Yahoo Japan, scores of informativeness, completeness, topic count, inter-topic distance, and topic mergence, total scores of content depth and breadth, Google Directory associated with topics in a blog entry, and post uniform resource locators (URLs).
4.3. Cross-Validation
To estimate the stability of each indicator, we applied 10-fold cross-validation. Each of the indicators must achieve admissible performance measure evaluated through cross validation. This process enables the generated predictors to anticipate the classes of unseen contextual instances. Samples were divided into 10 roughly equal-size parts. A model was constructed using nine parts and the remaining part was used to examine the predictability. This procedure was repeated ten times, with the combination of nine parts changed with each repetition. By summing up the squared errors of testing set from the fitted model of training set we obtain Mean Squared Error of Cross-Validation:
(10)
Then, cross-validation parameter is defined as
(11)
where - root mean square deviation of y from average value for the training
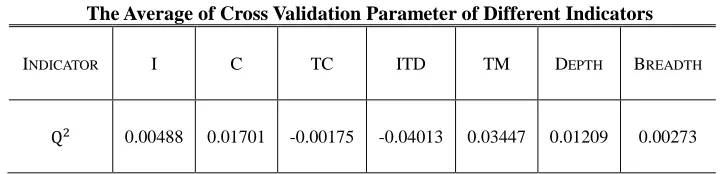
International Journal of Business and Information In other words, - parameter shows to what extent the factor model constructed is better than random selection. For our purpose of testing the stability of estimational scalars, a value of 0, or closing to 0, corresponds to a model with homogenous data distribution because of the performance of a stable indicator. All estimational scores were conducted in 10-fold cross-validation where 9 folds were used for training and the rest for testing. The average of cross-validation parameter of different indicators is shown in Table 1. The results demonstrate reasonable stability of indicators.
Table 1
The Average of Cross Validation Parameter of Different Indicators
INDICATOR I C TC ITD TM DEPTH BREADTH
0.00488 0.01701 -0.00175 -0.04013 0.03447 0.01209 0.00273
4.4. Experimental Procedure
To validate our quality criteria, we applied a human experiment to examine the estimated values of each indicator and to prove whether those indicators are qualified to be the reference index for quality blog ranking service. The experiment was led as an Internet survey from August 24, 2009, to September 4, 2009. The research subjects were 21 students from the University of Electro-Communications in Japan. From 288 categories, we selected data from 5 categories as experimental – Internet, computer, sports, games, and news. These categories were supposed to be well known to students majoring in IT engineering. The Internet survey included subjects’ background information, such as the frequency of Internet browsing and blog reading, age, gender, and student ID, and experimental contents. On each occasion, the Internet survey took around one hour. After selecting a category, students completed a set of 20 paired comparison tests, which included 40 blog contents randomly chosen from 200 blogs in that category domain. The paired comparison examined two blogs’ distinctness of content depth (informativeness and completeness) and content breadth (topic variety). Every student processed the experiment with at least two categories.
Volume 5, Number 1, June 2010 4.5. Experimental Results
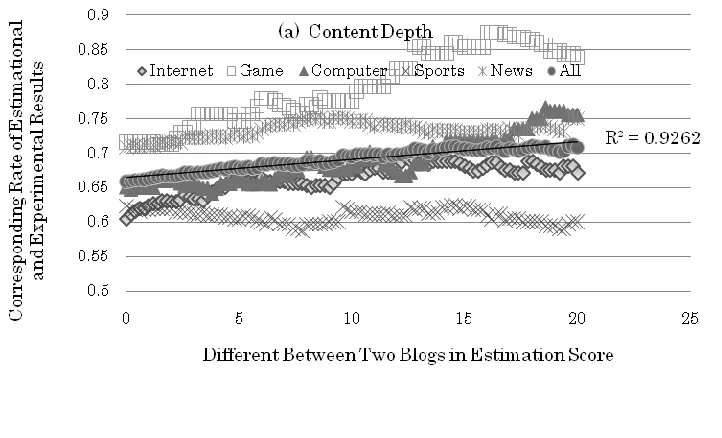
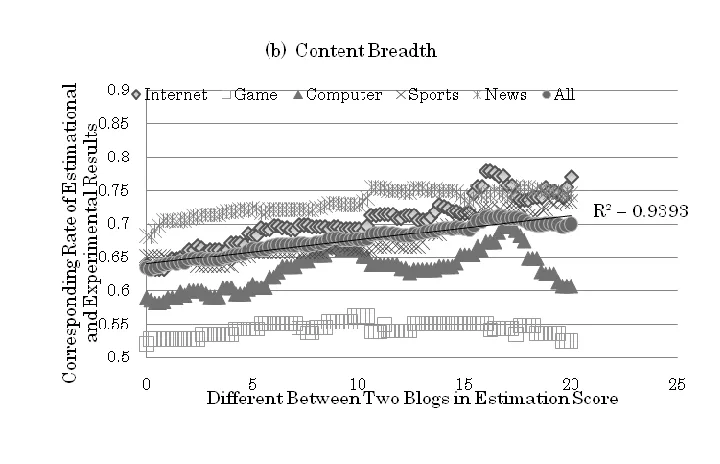
This experiment aimed to verify the applicability of created quality indicators by comparing the rank order of experimental results and the estimated results. The total 718 effective experimental results of blog content depth and breadth were restored in a one-to-one comparison format. We estimated and paired to compare these 718 blog contents by quality criteria of content depth and breadth. For our purpose of testing the validation of estimational scalar, a high corresponding rate showed a good match of experimental results and estimated results, which validated our criteria of quality indicators. The results are shown in Figure 2-a and 2-b. The horizontal axis demonstrates the difference between two blogs in estimation score, which tells the distinctiveness of the two blog contents assessed by our computational program. In general, the corresponding rate has positive correlation with the difference of estimation score on both quality measurements; still, the degree of positive correlation varies by category. The positive correlation (R2 = 0.9262 in Content Depth; R2 = 0.9393 in Content Breadth) implies that it is easier for people to distinguish a quality blog when two blogs are detected as being much different in content quality.
In sum, the high corresponding rate of overall quality measurements and categories in Figure 2-a and 2-b also indicates that the proposed method of measuring blog content depth and breadth is appropriate and that these two should help users judge which pages they choose among search results.
International Journal of Business and Information Figure 2-b. Corresponding Rate of Experiment Results
and Estimational Results in Content Breadth
4.6. Visualizing Analysis
The visualizing analysis aims to investigate the relationship and performance of two quality measurements in order to analyze blog content by implementing principle component analysis. We investigated the correlation between content breadth and content depth in the scale of overall blogosphere and the top 5% high-quality blog space.
As shown in Figure 3-a, 3-b, and 3-c, we found that content depth and content breadth have positive correlation (0.675) in the overall blogosphere. This finding means that general blog creators consider content depth and breadth in their compositions on balance. For high-quality blogs, however, content depth and content breadth do not show strong dependency with each other (correlation: -0.289). This fact indicates that, with fairly deep content, the distribution in content breadth is relatively broad.
Volume 5, Number 1, June 2010
(a) Overall Blogosphere
International Journal of Business and Information Figures 3-c. Relationship Between Content Depth and Content Breadth
5.
CONCLUSION AND FUTURE WORK
Motivated by the lack of literature to address the possible detection of valuable blogs with high-quality content, we conducted a thorough and comprehensive study that specifically investigates how coordination measures, such as content quality, can be applied to the blog ranking service when different quality elements are presented within the implementation of text mining technologies.
The paper presents results using semantic models for assessing blog contextual information, in terms of content depth and content breadth. To our knowledge, this is the first such study focusing on general blog entries, instead of specific groups of bloggers. For this study, we created a huge blog data corpus by all the topic domains to simulate the real blogosphere. A word-relatedness interpreter, which is a data-base of all terms co-occurrence on Wikipedia corpus, was successfully developed to measure semantic connectivity.
Volume 5, Number 1, June 2010
the completeness of each topic and the number of meaningful words used in the blog. Content breadth is estimated by topic count, inter-topic distance, and topic mergence. The experimental results suggest that the positive correlation between automatic evaluation and manual evaluation indicates that our proposed methods are effective in identifying quality blog by content depth and content breadth assessment. Our experiments on our data set of blogs demonstrate how our model can present the blogosphere in terms of topic variety and consistency with measurable quality indicators. Hence, it is useful to track popular topics and quality contentsin the blogosphere. We hope that this work will contribute to the growing need and application for search and mining blog contextual information.
We have addressed the problem of quality blog selection in the current blog- ranking mechanism and propose a new algorithm to detect quality blogs by the numerated quality assessment components with the dimensions of content depth and breadth. However, there are still many aspects of information quality that can be discussed. In future study, more detail discussions of the definition of quality indicators should be conducted. Potential applications of this stream of research may include automatically monitoring and identifying trends in blogs and predicting topic dynamics.
REFERENCES
[1] Adomavicius, G., and A. Tuzhilin. 2005. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions, IEEE Transactions on Knowledge and Data Engineering 17 (6), 734–749.
[2] Avesani, P.; M. Cova; C. Hayes; and P. Massa. 2005. Learning contextualised weblog topics, Proc. WWW’05 Workshop on the Weblogging Ecosystem: Aggregation, Analysis and Dynamics.
[3] Balabanovi, M., and Y. Shoham. 1997. Fab: content-based, collaborative recommendation. Commun. ACM 40, 3 (Mar.1997), 66-72.
[4] Bizer, C., and R. Cyganiak. 2009. Quality-driven information filtering using the WIQA policy framework, Web Semantics: Science, Service and Agents WWW’07 1-10.
[5] Brin, S.; L. Page; R. Motwami; and T. Winograd. 1999. The PageRank citation ranking: Bringing order to the Web. Stanford University Technical Report 1999-0120.
[6] Chee, S.; J. Han; and K. Wang. 2001. Rectree: An efficient collaborative filtering method, In 3rd Int. Conf. On Data Warehousing and Knowledge Discovery (DAWAK 2001), LNCS 2114, Munich, Germany, September 2001.Springer Verlag. [7] Chen, Y.; F.S. Tsai; and K.L. Chan. 2008. Machine learning techniques for business
blog search and mining, Expert Systems with Applications 35, 581–590.
International Journal of Business and Information [9] Faloutsos, C.; and W.D. Oard. 1995. A Survey of Information Retrieval and Filtering
Methods, UM Computer Science Department; CS-TR-3514.
[10] Fujimura, K.; H. Toda; T. Inoue; N. Hiroshima; R. Kataoka; and M. Sugizaki. 2006. BLOGRANGER – A Multi-faceted Blog Search Engine, Proc. WWW’06.
[11] Glance, N.S.; M. Hurst; and T. Tomokiyo. 2004. BlogPulse: Automated trend discovery for weblogs, Proc. WWW’04 Workshop on the Weblogging Ecosystem: Aggregation, Analysis, and Dynamics.
[12] Gruhl, D.; R. Guha; D. Liben-Nowell; and A. Tomkins. 2004. Information diffusion through blogspace. Proc.WWW’04 Workshop on the Weblogging Ecosystem: Aggregation, Analysis, and Dynamics.
[13] Hearst, M.; M. Hurst; and D. Dumais. 2008. What Should Blog Search Look Like? Proc. SSM’08.
[14] Hofmann, T. 1999. Probabilistic latent semantic indexing, Proc. SIGIR /ACM ’99. [15] Kayaap, M.; T. Özyer; and S.T. Özyer. 2009. A collaborative and content based
event recommendation system integrated with data collection scrapers and services at a social networking site, IEEE Advances in Social Network Analysis and Mining, 113-118.
[16] Kleinberg, J. 1999. Authoritative sources in a hyperlinked environment, Journal of the ACM 46.
[17] Knight, S.-A.; and J. Burn. 2005. Developing a framework for assessing information quality on the World Wide Web, Informing Science Journal 8,160–172.
[18] Kolari, P.; A. Java; and T. Finin. 2006. Characterizing the splogosphere. In 3rd Workshop on the Weblogging Ecosystem, WWW 2006.
[19] Koppel, M.; J. Schler; S. Argamon; and J.W. Pennebaker. 2006. Effects of age and gender on blogging, In AAAI Spring Symposium on Computational Approaches to Analyzing Weblogs.
[20] Kosala, R.; and H. Blockeel. 2000. Web mining research: A survey, SIGKDD Explor. Newsl. 2(1), 1-15.
[21] Kr¨otzsch, M.; D. Vrandecic; and M. V¨olkel. 2005. Wikipedia and the semantic Web – the missing links, Proc. WIKIMANIA’05.
[22] Kuhn, A.; S. Ducasse; and T. Girba. 2007. Semantic clustering: Identifying topics in source code, Information and Software Technology.
[23] Li, M.; and W.A. Chen. 2009. Synthetical approach for blog recommendation: Combining trust, social relation, and semantic analysis, Expert Systems with Applications 36(3), 6536-6547.
[24] Mishne, G.; and M. de Rijke. 2006. A study of blog search, Proc. ECIR’06.
[25] Mishne, G. 2006. Information access challenges in the blogspace, Proc. IIIA-2006 - International Workshop on Intelligent Information Access.
[26] Nakajima, S.; J. Tatemura; Y. Hino; Y. Hara; and K. Tanaka. 2005. Discovering important bloggers based on analyzing blog threads, Proc. WWW’ 05 Workshop on the Weblogging Ecosystem: Aggregation, Analysis and Ddynamics.
[27] Naumann, F. 2002. Quality-Driven Query Answering for Integrated Information Systems, Springer, Berlin/Heidelberg/New York.
Volume 5, Number 1, June 2010
[29] Pipino, L.; R. Wang; D. Kopcso; and W. Rybold. 2005. Developing Measurement Scales for Data-Quality Dimensions, New York: M.E. Sharpe.
[30] Raghavan, P. 1997. Information retrieval algorithms: A survey, SODA '97: Proc. SIAM/ACM’97, pp. 11-18.
[31] Rubin, L.; and E. Liddy. 2006. Assessing credibility of Weblogs. Proc. AAAI-06: CAAW.
[32] Ruiz-Casado, M.; E. Alfonseca; and P. Castells. 2006. From Wikipedia to semantic relationships: A semi-automated annotation approach, Proc. ESWC ’06.
[33] Schaffert, S.; A. Gruber; and R. Westenthaler. 2005. A semantic Wiki for collaborative knowledge formation, Proc. SEMANTICS’05.
[34] Sifry, S. 2007. State of the Blogosphere, http://www.sifry.com
[35] Sriphaew, K.; H. Takamura; and M. Okumura. 2008. Cool blog identification using topic based models, Proc. IEEE/WIC/ACM’08.
[36] Strong, D.; Y. Lee, Y.; and R. Wang. 1997. Data quality in context, Communications of the ACM 40 (5), 103–110.
[37] Tseng, B.; J. Tatemura; and Y. Wu. 2005. Tomographic clustering to visualize blog communities as mountain views, Proc. WWW’05.
[38] Ulicny, B.; and K. Baclawski. 2007. New metrics for newsblog credibility, Proc. ICWSM. Boulder, Colorado.
[39] Wang, R., and D. Strong. 1996. Beyond accuracy: What data quality means to data consumers, Journal of Management Information Systems 12(4), 5–33.
[40] Weerkamp, W., and M. Rijke. 2008. Credibility improves topical blog post retrieval, Proc. ACL’08: HLT, pp. 923-9.
ABOUT THE AUTHORS
Meichieh Chen, M.S., is a post-graduate student in the Department of Social Intelligence and Informatics in the Graduate School of Information Systems at the University of Electro-Communications, Japan. She is pursuing her doctoral thesis focusing on marketing prediction with analysis of blog content. Other research interests include relationship marketing and virtual communities, especially that based on the technology of dynamics network analysis.