PHARMACEUTICAL AND TECHNICAL SCIENCE
ISSN (O) :- 2349-3585IMPROVING MEMORY HIERARCHY FOR
IRREGULAR APPLICATIONS
__________________________________________________________________________________________
A.V.SAI PRASAD
1, P.MOUNIKA
2, B.LAKSHMI GAYATHRI
3, Mr.A.RAJA
41,2,3
UG Students,4Assistant professor,
Department of Electronics and Communication Engineering, Saveetha School of Engineering,Chennai(602105),India
ABSTRACT: The hole between CPU speed and memory speed in present day com-puter frameworks is augmenting as new ages of
equipment are presented. Circle blocking and prefetching changes help connect this hole for customary applications; be that as it
may, these procedures aren't as viable for sporadic applications. This paper investi-doors utilizing information and calculation
reordering to improve memory progression usage for unpredictable applications on frameworks with staggered memory chains of
command. We assess the effect of information and calculation reordering utilizing space-filling bends and introduction multi-Ievel
hindering as another calculation reordering strat-egy for unpredictable applications. In tests that applied explicit mixes of
information and calculation reorderings to two sporadic projects, by and large execution time dropped by a factor of two for one
program and a factor of four for the second.
I.INTRODUCTION
The hole between CPU speed and memory speed is increas-ing quickly as new ages of PC frameworks are presented. Staggered memory chains of importance are the standard architec-turalconfiguration used to connect this memory get to bottleneck. As the hole between CPU speed and memory speed extends, frameworks are being developed with more profound orders. Accomplishing high perfor-mance on such frameworks requires fitting the reference conduct of uses to more readily coordinate the qualities of a machine's memory hierarchy.The execution of universally useful microchips keeps on expanding at a quick pace. Over the most recent 15 years, execution has improved at a pace of generally 1.6 times each year with about portion of this addition ascribed to procedures for misusing guidance level parallelism and memory area [1]. In spite of these advances, a few looming bottlenecks take steps to slow the pace at which future execution upgrades can be realized.Arguably the single greatest potential bottleneck for some applications later on will be high memory inactivity and the absence of sufficient
memory transfer speed. In spite of the fact that advances, for example, non-blocking reserves [2] and equipment and programming based prefetching [3, 4] can diminish dormancy at times, the fundamental structure of the memory chain of importance whereupon these methodologies are actualized
may at last farthest point their viability.
II.LITERATURE SURVEY
1.Sequoia Design
The chief develop of the Sequoia programming model is an errand: a symptom free capacity with call-by-esteem result parameter passing semantics. Assignments accommodate the statement of:
• Explicit Communication and Locality. Correspondence of
information through the memory chain of importance is communicated by passing contentions to assignments. Calling assignments is the main methods for depicting information development in Sequoia.
• Isolation and Parallelism. Assignments work completely
inside their own private location space and have no instrument to speak with different undertakings by some other means than calling subtasks and coming back to a parent task. Errand detachment encourages versatile simultaneous programming.
• Algorithmic Variants. Sequoia enables the software
engineer to give different executions of an errand and to determine which usage to utilize dependent on the setting in which the undertaking is called.
• Parameterization. Undertakings are communicated in a
of an objective machine. This assortment of properties permits programs composed utilizing assignments to be compact crosswise over machines without sacrificing the capacity to
tune for execution.
2.Cache and TLB Circuit Structures
In this segment, we depict the circuit structures of the traditional and configurable reserves and TLBs that we
consider. We additionally depict two distinct methodologies for utilizing configurable reserves as swaps for ordinary
on-chip store chains of importance.
2.1 Configurable Cache Organization
The store and TLB structures (both regular and configurable)
that we model pursue that portrayed by Mc-Farland in his postulation [5]. McFarland built up a definite planning model for both the store and TLB that adjusts both execution and vitality contemplations in subarrayparceling, and which incorporates the impacts of innovation scaling. We start with a regular 2MB information reserve that is sorted out both for quick access time and vitality efficiency. As is appeared in
Figure 1, the store is organized as two 1MB interleaved banks1 so as to give sufficient memory data transmission to
the four-way issue dynamic superscalar processor that we mimic. So as to lessen get to time and vitality utilization, each 1MB bank is additionally separated into two 512KB SRAM structures one of which is chosen on each bank get to. We make various modifications to this fundamental structure to furnish configurability with little effect on get to time, vitality
dispersal, and utilitarian thickness.
2.2 Configurable Cache Organization
The store and TLB structures (both regular and configurable) that we model pursue that portrayed by Mc-Farland in his postulation [6]. McFarland built up a definite planning model for both the store and TLB that adjusts both execution and vitality contemplations in subarrayparceling, and which incorporates the impacts of innovation scaling. We start with a regular 2MB information reserve that is sorted out both for quick access time and vitality efficiency. As is appeared in
Figure 1, the store is organized as two 1MB interleaved banks1 so as to give sufficient memory data transmission to
the four-way issue dynamic superscalar processor that we mimic. So as to lessen get to time and vitality utilization, each
1MB bank is additionally separated into two 512KB SRAM structures one of which is chosen on each bank get to. We make various modifications to this fundamental structure to furnish configurability with little effect on get to time, vitality
dispersal, and utilitarian thickness.
2.3Uniform Memory Hierarchy Analysis
UMH examination refines conventional strategies for calculation investigation by including the expense of information development all through the memory order. Thecommunication proficiency of a program is a proportion estimating the part of UMH running time during which M0 is dynamic[7]. A calculation that can be actualized by a program whose correspondence proficiency is nonzero in the cutoff is said to becommunication-proficient. The correspondence proficiency of a program relies upon the parameters of the UMH model, in particular on the exchange cost work. Athreshold work isolates those exchange cost capacities for which a calculation is correspondence productive from those that are excessively exorbitant. Edge capacities for framework transpose, standard grid augmentation, and Fast Fourier Transform calculations are built up by displaying correspondence proficient projects at the limit and demonstrating that progressively costly move cost capacities are excessively exorbitant. A parallel PC can be displayed as a tree of memory modules with calculation happening at the leaves. Edge capacities are built up for increase ofN×N frameworks utilizing something like N2 processors in a tree with steady stretching element.
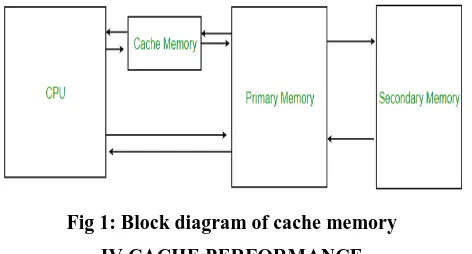
III.CACHE MEMORY
distinctive autonomous reserves in a CPU, which store guidelines and information.
Fig 1: Block diagram of cache memory
IV.CACHE PERFORMANCE
At the point when the processor needs to peruse or compose an area in primary memory, it first checks for a relating section in the cache. On the off chance that the processor finds that the memory area is in the store, a cache hit has happened and information is perused from cache.On the off chance that the processor doesn't discover the memory area in the store, a reserve miss has happened[10]. For a store miss, the cache assigns another passage and duplicates in information from primary memory, at that point the solicitation is satisfied from the substance of the cache. The presentation of store memory is every now and again estimated regarding an amount called Hit proportion.
Hit proportion
Hit proportion = hit/(hit + miss) = no. of hits
We can improve Cache execution utilizing higher reserve square size, higher associativity, diminish miss rate, lessen miss punishment, and decrease Reduce an opportunity to hit in the store.
V.CACHE MAPPING:
There are three unique kinds of mapping utilized with the end goal of reserve memory which are as per the following: Direct mapping, Associative mapping, and Set-Associative mapping. These are clarified beneath.
1.Direct Mapping
The least difficult procedure, known as immediate mapping, maps each square of primary memory into just a single conceivable store line. or on the other hand In Direct mapping, assigne every memory square to a particular line in the store[11]. In the event that a line is recently taken up by a memory square when another square should be stacked, the
old square is destroyed. A location space is part into two sections file field and a label field. The reserve is utilized to store the label field while the rest is put away in the primary memory. Direct mapping's exhibition is legitimately corresponding to the Hit proportion.
2.Associative Mapping
In this sort of mapping, the affiliated memory is utilized to store substance and addresses of the memory word. Any square can go into any line of the store. This implies the word id bits are utilized to recognize which word in the square is required, however the tag turns into the entirety of the rest of the bits. This empowers the position of any word at wherever in the store memory. It is viewed as the quickest and the most adaptable mapping structure.
3.Set-cooperative Mapping
This type of mapping is an improved type of direct mapping where the downsides of direct mapping are expelled. Set cooperative tends to the issue of conceivable whipping in the immediate mapping technique. It does this by saying that as opposed to having precisely one line that a square can guide to in the reserve, we will assemble a couple of lines making a set[12]. At that point a square in memory can guide to any of the lines of a particular set..Set-affiliated mapping permits that each word that is available in the store can have at least two words in the fundamental memory for a similar list address. Set acquainted reserve mapping consolidates the best of immediate and cooperative store mapping procedures.
VI. CACHE FUNCTIONALITY AND ORGANISATION
In a cutting edge microchip a few stores are found. They change in size and usefulness, yet in addition their inner association is commonly extraordinary over the stores. This area talks about the most significant caches, just as some mainstream store associations.
1.Instruction Cache
2.Data Cache
An information store is a quick cradle that contains the application information. Before the processor can work on the information, it must be stacked from memory into the information cache4. The component required is then stacked from the reserve line into a register and the guidance utilizing this worth can work on it. The resultant estimation of the guidance is additionally put away in a register. The register substance are then put away again into the information store. In the end the reserve line that this component is a piece of is replicated once more into the principle memory.
3.TLB Cache
Deciphering a virtual page address to a legitimate physical location is somewhat exorbitant. The TLB is a reserve to store these deciphered locations. Every section in the TLB maps to a whole virtual memory page. The CPU can just work on information and guidelines that are mapped into the TLB. On the off chance that this mapping is absent, the framework needs to re-make it, which is a generally expensive activity. The bigger a page, the more successful limit the TLB has. On the off chance that an application doesn't utilize the TLB expanding the size of the page can be valuable for execution, taking into account a greater piece of the location space to be mapped into the TLB.A few chip, including UltraSPARC, execute two TLBs. One for pages containing directions (I-TLB) and one for information pages (D-(I-TLB).
VII.FUTURE WORK
Future work incorporates researching the utilization of compiler support for applications where an interim based plan can't catch the stage changes (varying working sets) in an application. Compiler backing would be beneficial both to
choose fitting adjustment indicates just as anticipate an application's working set sizes. At long last, upgrades at the circuit and microarchitectural levels will be sought after that better offset configuration flexibility with get to time and
vitality utilization.
VIII.CONCLUSION
We have depicted a novel configurable store and TLB as an
option in contrast to customary reserve progressive systems. Repeater inclusion is utilized to empower dynamic reserve and TLB configuration, with an association that takes into
consideration dynamic speed/size tradeoffs while constraining the effect of speed changes to inside the memory chain of importance. Our configuration the board calculation can powerfully look at the tradeoff between an application's hit and miss prejudice utilizing CPI as a definitive measurement to decide proper store estimate and speed. At 0.1 smaller scale m innovations, our outcomes show a normal 16% decrease in CPI in examination with the best regular L1-L2 structure of practically identical complete size, with the benefit similarly inferable all things considered to the configurable reserve and TLB. Moreover, vitality mindful upgrades to the calculation exchange off an increasingly unassuming exhibition improvement for a significant decrease in vitality. Anticipating
to 0.04micro m advances and a 3-level reserve chain of command, we show improved execution with a normal 45% decrease in memory progression vitality when contrasted with an ordinary plan. This last outcome shows that on the grounds that our configurable methodology significantly improves memory chain of command efficiency, it can fill in as a halfway answer for the significant control dispersal challenges
confronting future processor engineers.
REFERENCES
[1] J. Hennessy. Back to the future: Time to return to some long standing problems in computer systems? Federated Computer Conference, May 1999.
[2]K.Farkas and N. Jouppi.Complexity/performance tradeoffs with non-blocking loads.Proceedings of the 21st International Symposium on Computer Architecture, pages 211– 222, April 1994.
[3] N. Jouppi. Improving direct-mapped cache performance by the addition of a small fully-associative cache and prefetch buffers. Proceedings of the 17th International Symposium on Computer Architecture, pages 364–373, May 1990.
[4] T. Mowry, M. Lam, and A. Gupta.Design and evaluation of a compiler algorithm for prefetching.Proceedings of ASPLOS-V, pages 62–73, October 1992.
[5] G. McFarland. CMOS Technology Scaling and Its Impact on Cache Delay. PhD thesis, Stanford University, June 1997. [6] R. Kessler. The Alpha 21264 microprocessor. IEEE Micro, 19(2):24–36, March/April 1999.
2.0.Technical Report TR-97-1342, University of WisconsinMadison, June 1997.
[8] W. Dally and J. Poulton. Digital System Engineering.Cambridge University Press, Cambridge, UK, 1998.
[9]K.Farkas and N. Jouppi.Complexity/performance tradeoffs with non-blocking loads.Proceedings of the 21st International Symposium on Computer Architecture, pages 211– 222, April 1994.