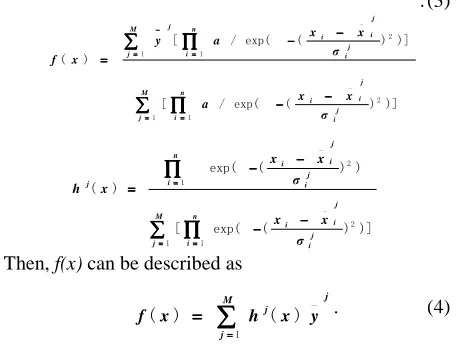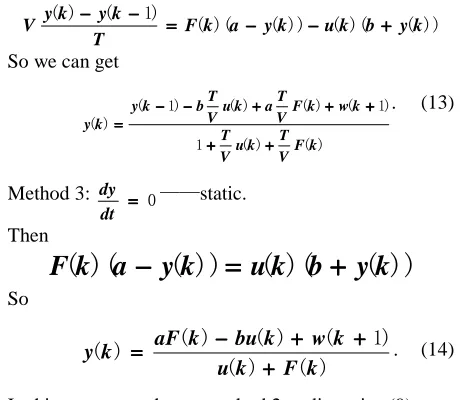A Research on the pH Neutralization Process
Based on the T-S Fuzzy Model
Xiaohui Chen
*College of Computer and Information Technology, China Three Gorges University, Yichang, China Email: [email protected]
Jinpeng Chen
College of Computer and Information Technology, China Three Gorges University, Yichang, China
Bangjun Lei
Institute of Intelligent Vision and Image Information, China Three Gorges University, Yichang, China
Abstract—Inherent pH process nonlinearity and
time-varying characteristics impose a highly challenging control problem. To meet the requirement of precise identification of parameters in pH neutralization process, this paper
concerns the modeling and identification of pH
neutralization process. In consideration of the approximate three sections linear characteristic of titration curve in the pH neutralization process, the T-S fuzzy model is adopted as the model of pH neutralization process. Considering the gradient parameters in pH neutralization process, the parameters of the model are identified with the methods of recursive least square algorithm (RLS) and recursive least square with fading factor algorithm (RLS-RFF). The simulation results indicate the effectiveness of the modeling method and the identification methods, and the RLS-RFF algorithm has better identification accuracy and adaptive ability than the RLS algorithm in the reaction process of gradient parameters.
Index Terms—T-S fuzzy model, fuzzy identification, pH
neutralization process, least square method
I. INTRODUCTION
In chemistry, pH is a measure of the acidity or basicity of an aqueous solution [1]. It is defined as a negative decimal logarithm of the hydrogen ion activity in a solution.
) 1 ( log ) (
log10 ++++ ==== 10 ++++
−−−− ====
H H
pH . (1)
Where H+ is the activity of hydrogen ions in units of mol/L(molar concentration).
The pH process control has been widely used in
medicine, biology, chemical, light industry, food science, wastewater treatment, environmental protection and many other applications. Improving the identification accuracy (The identification is of high precision or well meets the required precision) is helpful to the effective control, and has a profound effect on improving the quality and output of the products, as well as the safety of production equipment and the environmental protection.
Because of the serious nonlinearity, time-varying, and time delay in the pH neutralization process, the identification and control of the pH neutralization process have been one of the most difficult problems in relative fields [2]. Thus the research of the identification and control in pH neutralization process is very important.
Extensive researches in the identification of pH neutralization process have been done by many relative experts in recent years. Mcavoyt T J proposes the mathematical model of pH neutralization process [3]. More complicated and more all-purpose pH neutralization models have been further proposed [4], which laid a research foundation for the identification and control of the pH neutralization process. Bhat N V proposes a back-propagation net to model the system [5]. Nie J H adopts a simplified fuzzy model as an approximate reasoner to deduce the model output on the basis of the identified rule-base [6]. A support vector machine method based on structure risk minimization principle and a stronger generalization ability of network has been proposed to construct the identification model of pH neutralization process [7]. Wiener model has been widely used to the study of pH neutralization process [8]-[9]. Tao Liu establishes an identification model using BP neural network [10]. Min Han proposes a new type of neural network—universal learning to identify the reaction process. The approach of neutral network applied to pH neutralization process has the shortage that it is difficult to control the complexity of the network, and the Wiener model applied to pH neutralization is also complicated, what’s more, the phenomenon of over-fitting is likely to appear; The T-S fuzzy model takes linear equation as the consequent part [12], and it is Manuscript received May 1, 2011; revised June 1, 2011; accepted
July 1, 2011.
This research was supported by the National Natural Science Foundation of China (Grant No.60972162).
This research was supported by the Research and Development Project of Science and Technology of Yichang (Grant No.A2011-302-14).
0 5 10 15 20 25 30 35 40 45 2
3 4 5 6 7 8 9 10 11
T
h
e
p
H
v
a
lu
e
The flow of acid-base
Figure 1. The titration curve in the pH neutralization process. possible to deal with nonlinear problems by using the theory of linear system. The universal approximation of T-S fuzzy model for the nonlinear system [13] provides the theory basis to identify the nonlinear system by using T-S fuzzy model.
In this paper, we analyze the characteristic of the titration curve in the pH neutralization process, which is very similar to the three sections linear line linked. We further propose the modeling and identification methods for the pH neutralization process. The consequent part of T-S fuzzy model is a linear equation, and it is feasible to take T-S fuzzy model as the model of pH neutralization process [14]. The parameters of the T-S fuzzy model are identified with the methods of recursive least square algorithm (RLS) and recursive least square with fading factor algorithm (RLS-RFF) in the reaction process of gradient parameters. The effectiveness of the modeling method and the identification methods is proved by MatLab simulation.
II. IDENTIFY THE MODEL PARAMETERS BY LEAST SQUARE
A. Establishment of the Model of pH neutralization process
Based on the Fig.1, it is clear that the titration curve of pH neutralization process is nonlinear. Further, having analyzed the characteristic of the titration curve, and we can find that the titration curve is very similar to the three sections linear line linked.
The T-S fuzzy model is an essential nonlinear model, and it uses linear equations to express the partial rules of the partial region in nonlinear system. Based on the partial linearization, it can approach a nonlinear system infinitely via the fuzzy inference. It has the characteristics of simple structure and strong approach ability.
Since the pH neutralization process has the characteristic of three sections linear line linked.The consequent part of T-S fuzzy model is a linear equation, so it is feasible to take the T-S fuzzy model as the model of pH neutralization process. Once the model of pH neutralization process is established, we can identify the model parameters to control the pH neutralization process.
Identification of T-S model is divided into premise part identification and consequent part identification. Based on the expert experience, we can select two or three
points as the fuzzy central points, and set the fuzzy radius. In order to achieve better real-time control, we select two points, so it can establish two fuzzy rules, and the premise parameters arexijand j
i
σ , j=1, 2.
Aiming at the pH neutralization process, let F(t) be the acid flow rate, and u(t) be the alkali flow rate, then the input of the pH neutralization process x equals F(t)-u(t).
In this paper, Gaussian function is introduced, and it is shown as (2)
) ) (
exp( )
( 2
j i
j i i i
j i
σ
x x x
A ==== −−−− −−−−
.
(2)
The fuzzy logic system consists of average fuzzy eliminator, Gaussian membership functions, inference principle. The single-valued fuzzy generator has the following form:
∑ ∑∑ ∑ ∏∏∏∏
∑ ∑ ∑ ∑ ∏∏∏∏
==== ==== ==== ====
−−−−
−−−− −−−−
−−−− −−−− ====
M j
n i
j i
j i i M
j n
i ij
j i i j
σ
x x a
σ
x x a
y
x f
1 1
2 _
1 1
2 _
)] ) (
exp( / [
)] ) (
exp( / [ )
(
. (3)
∑
∑∑
∑ ∏∏∏∏
∏ ∏∏ ∏
==== ==== ====
−−−− −−−−
−−−− −−−− ====
M j
n i
j i
j i i
j i
j i i n
i j
σ
x x
σ
x x
x h
1 1
2 _
2 _
1
)] ) (
exp( [
) ) (
exp( )
(
Then, f(x) can be described as
j M
j j
y x h x
f
_
1
) ( )
(
∑
∑
∑
∑
====
==== . (4)
T-S model is adopted in (4), and then the fuzzy logic system has the following form, as shown in (5).
Aiming at the representative model of pH neutralization process, and based on the fuzzy rules, then
T j
j j
j
θ
W x p p h x
f
Y ==== ==== ∑∑∑∑ ×××× ++++ ==== ••••
====
)] (
[ )
( 0 1
2
1
. (5)
) , , , (
) , , , (
2 1 2 0 1 1 1 0
2 2 1 1
P P P P
θ
x h h x h h W
==== ====
The parameter
Y
and other parameters in (5) are in a linear relationship, andW
is known as a basis function, so the independent consequent parameterθ needs to be identified. Fuzzy systems are suitable to describe the dynamic characteristics of nonlinear system. The consequent part of T-S model is a linear expression, so it is suitable for control design [15], and the linear parameter estimation methods can be adopted. In this paper, the conventional RLS algorithm and RLS-RFF algorithm are used to identify the model parameters. B. Model Identification Based on conventional RLSdetermine the number of the rules, this paper aims at proving the effectiveness of the proposed method. So this paper mainly identifies the consequent part, and the premise part of the fuzzy model is simulated by the gauss membership function.
The Conventional RLS algorithm can realize the online identification, and the core ideas of Conventional RLS algorithm can be described as follows:
When the new observed data are obtained, they can be used to revise the last estimate, and the new estimate can be recursively obtained.
The conventional RLS can be concluded as follows:
γ
θ
θ
(
k
+
1
)
=
(
k
)
+
Whereγ
is the correction term.The parameter identification is taken under the conventional RLS algorithm and indicators identification of minimal significance. Object model is represented by (5), according to the principle of RLS [16], we can get the least squares estimate
k
θ of parameter vector θ
k T k k
T k
k
W
W
W
Y
θ
====
(
)
−−−−1 . (6)The input variable of the system is represented by
x
k, and the output variable of the system is represented byY
k, andW
kis the vector of observed data. The least square value of the k times of the observation is represented byθk, of which the subscript k indicates the k times.The conventional RLS algorithm can be concluded as follows:
−−−− ==== ++++
====
−−−− ++++
====
++++ ++++ ++++
++++ ++++
++++ ++++
++++ ++++
++++ ++++
k T k k k
k k T k
k k k
k T k k
k k k
S W F I S
W S W
W S F
θ W Y
F θ θ
] [
1
] [
1 1 1
1 1
1 1
1 1
1 1
. (7)
1 ++++
k
θ
is the vector parameter to be identified ,F
k++++1isthe gain vector,
S
k++++1is the covariance matrix. Recursiveinitial value θ0equals any value; S0 equals α2I ; α is
the allowable maximum of the computer.
In (7), we calculate the
F
k++++1first, and theS
k++++1second, then we can get the value ofθ
k++++1. So the consequent parameterθ
k++++1 can be identified.Supposing the object output is y, identification output is yn, and then identification error e equals y-yn,
identification indicator ====
∑
∑
∑
∑
2e
J . When the
identification accuracy meets the requirement, the operation comes to an end.
The identification steps are shown as follows:
Step1: We set recursive initial value θ0 and S0 .
Recursive initial value θ0equals any value. SSSS0 equals α2I,
in which α is the maximum value according to the computer.
Step2: The new observed data ++++1 k
Y and
x
k++++1 are obtained through sampling, and form the observed data vector Wk.Calculate the current parameter estimates as (7) shows.Step3: The number of sampling adds one, and then turns to the Step2 to continue. Until the identification accuracy meets the requirement, the operation comes to an end.
C. Model Identification Based on RLS-RFF
The conventional RLS algorithm can achieve good results on the condition of constant parameters. Actually the pH neutralization process is a time-varying dynamic process, and the consequent parameters p0 and p1 are
changing during the reaction. As the latest observed data can reflect the current characteristics of the objects, the conventional RLS algorithm cannot timely reflect the reaction process of gradient parameters. With the growth of data, the "data saturation" phenomenon will have an effect on the accuracy of the RLS algorithm, and new data have been inundated by a number of old data. For the identification of gradual variation of parameters, it is impossible to identify the varying parameters, and the identification accuracy of the unknown parameters cannot accomplish the desired result.
In order to overcome the "data saturation" and weaken the influence of historical observed data to the unknown parameters estimation, the RLS-RFF algorithm is adopted.
The core ideas of Conventional RLS can be described as follows:
In order to reduce the information of the old data, it assigns the weight to the old data, so the old data as well as new data can be considered to estimate the parameters.
When the new observed data are obtained, all previous data will be multiplied by a weighted factor ρ(0 <ρ <1), which is called the weighted factor. After selecting the weighted factor ρ, the RLS-RFF algorithm can be concluded as follows:
−−−− ====
++++ ====
−−−− ++++
====
++++ ++++ ++++
++++ ++++
++++ ++++
++++ ++++ ++++ ++++
k T k k k
k k T k
k k k
k T k k k k k
S W F I
ρ
S
W S W
ρ
W S F
θ
W Y F
θ θ
] [
1
] [
1 1 2
1
1 1 2
1 1
1 1 1
1 . (8)
1
++++
k
θ is the vector parameter to be identified, Fk++++1is the gain vector, ++++1
k
W is the the vector of observed data,
S
k++++1 is the covariance matrix. Recursive initialvalue θ0 equals any value; S0 equals α2I , α is the
allowable maximum of the computer.
Take ρ2 as µ (0 <µ <1), forgetting factor 0 <µ≤ 1, and
µ usually take value from 0.9 to 0.99.
overcome "data saturation" phenomenon effectively by choosing the right forgetting factor.
In (8), we calculate the
F
k++++1 first, and theS
k++++1second, then we can get the value of
θ
k++++1 . So the consequent parameterθ
k++++1 can be identified.The identification steps are showing as follows: Step1: We set recursive initial value θ0 and SSSS0.
Recursive initial value θ0 equals any value, SSSS0 equals
I
2
α , in which α is the maximum value according to the computer.
Step2: The new observed data ++++1 k
Y and
x
k++++1 are obtained through sampling, and form the observed data vectorW
k. Calculate the current parameter estimates as (8) shows.Step3: The number of sampling adds one, and then turns to the Step2 to continue. Until the identification accuracy meets the requirement, the operation comes to an end.
III. MECHANISM OF PH NEUTRALIZATION PROCESS The representative model of the pH is described as follows [4]: −−−− ==== ++++ −−−− −−−− ==== −−−− w t pH t pH K t y t y b t u t y a t F dt dy V ) ( ) ( 10 10 ) ( )) ( )( ( )) ( )(
( . (9)
Where
Kw: water equilibrium constant, 10-14.
V: reactor volume, L. F (t): the acid flow rate, L/min. u (t): the alkali flow rate, L/min.
a: the concentration of acid, mol/L. b: the concentration of alkali, mol/L.
y(t): the distance from the neutral point, [H+] - [OH-]. A. The methods of discretization
In order to facilitate the MatLab simulation, we discretize the (9), and the methods of discretization are described as follows:
Method 1: T k y k y dt
dy ==== ( ++++1)−−−− ( ). (10)
Take (10) into (9), then
)) ( )( ( )) ( )( ( ) ( ) 1 ( k y b k u k y a k F T k y k y
V ++++ −−−− ==== −−−− −−−− ++++
So we can get
) 1 ( ) ( ) ( ) ( ) ( ) ( 1 ) 1
( + =− − − + Fk+wk+ V aT k u V bT k y k u V T k F V T k
y . (11)
Method 2: T k y k y dt
dy ( ) −−−− ( −−−− 1)
==== . (12)
Then )) ( )( ( )) ( )( ( ) 1 ( ) ( k y b k u k y a k F T k y k y
V −−−− −−−− ==== −−−− −−−− ++++
So we can get
) ( ) ( 1 ) 1 ( ) ( ) ( ) 1 ( ) ( k F V T k u V T k w k F V T a k u V T b k y k y ++++ ++++ ++++ ++++ ++++ −−−− −−−− ====
. (13)
Method 3: ==== 0 dt dy ——static. Then
))
(
)(
(
))
(
)(
(
k
a
y
k
u
k
b
y
k
F
−−−−
====
++++
So ) ( ) ( ) 1 ( ) ( ) ( ) ( k F k u k w k bu k aF k y ++++ ++++ ++++ −−−−
==== . (14)
In this paper, we choose method 2 to discretize (9). Where
T: sampling time, min w: system noise signal B. pH value of solving
The pH value formula is described as follows:
w w K K t y t y t pH 2 ) 4 ) ( ( ) ( lg ) ( 2 / 1 2 ++++ ++++ −−−−
==== . (15)
Where
Kw: water equilibrium constant, 10-14.
y(t): the distance from the neutral point, [H+] - [OH-].
IV.SIMULATION
Input the control signal UUUU ====22221(1(1(1(1++++sin(2πt/f))and choose the model of (13) and (15).
The parameters of simulation: f = 200, a = 0.001mol/L, V = 2L, T = 1 min, F(t) = 0.1125L/min. Initial b0 of b
equals 0.001mol/L and increase slowly by
▽b=0.16/400*b0.
The premise part of the fuzzy model is simulated by the gauss curve.
Where
The fuzzy center x1 =7, x2 =30; the fuzzy radius σ1= 5,
2
σ =5.
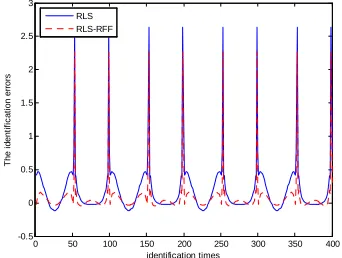
The error curve is shown in Fig.2 and the titration curve is shown in Fig.3. The error of the two proposed algorithms is shown in TABLE I.
Where the forgetting factor µ equals 0.99
The Clustering method is adopted to identify the same objections [4]. 400 times calculations are adopted.
Where
Step = 0.5; t0 = 0; tN = 200.
TABLE I.
THE ERROR OF THE TWO PROPOSED METHODS
Approach RLS RLS-RFF
0 50 100 150 200 250 300 350 400 -0.5
0 0.5 1 1.5 2 2.5 3
T
h
e
i
d
e
n
ti
fi
c
a
ti
o
n
e
rr
o
rs
identification times RLS
RLS-RFF
Figure 2. The errors comparison between the RLS and RLS-RFF.
0 5 10 15 20 25 30 35 40 45 2
3 4 5 6 7 8 9 10 11
The flow of acid-base
T
h
e
p
H
v
a
lu
e
original RLS RLS-RFF
Figure 3. The comparison of the pH titration curve among the original, RLS and RLS-RFF.
Based on the TABLE I, it is clear that the RLS-RFF algorithm has better identification accuracy than the RLS algorithm.
Based on the Fig. 3, we can conclude that the titration curve of pH neutralization process in the RLS-RFF algorithm has better adaptive ability than the conventional RLS algorithm in the reaction process of gradient parameters.
Actually the forgetting factor µ can be taken from 0.9 to 0.99. In order to achieve more intuitionistic comparison, we have also compared the error of RLS-RFF algorithm by introducing different forgetting factor µ
from 0.9 to 0.99. The error comparison of different forgetting factor is shown in TABLE II.
Based on the TABLE II, It is clear that the error of the RLS-RFF algorithm decreases with the decrease of the forgetting factor at the beginning, and then it increases with the decrease of the forgetting factor. So the forgetting factor µ is an important parameter for the identification of RLS-RFF algorithm. The forgetting factor close to one can achieve better identification accuracy, and selecting the right forgetting factor is beneficial to the effective identification and control of the pH neutralization process.
V.CONCLUSIONS
This paper analyzes the characteristics of pH neutralization process. On this basis, the model of pH neutralization process is constructed by the T-S fuzzy model, and the parameters of T-S fuzzy model are identified with the methods of RLS algorithm and RLS-RFF algorithm. In consideration of the variation of parameters during reaction process, we have compared the real-time identification accuracy and adaptive ability between the conventional RLS algorithm and RLS-RFF algorithm. The simulation results indicate that the use of T-S fuzzy model to construct the model of pH neutralization process is feasible, and RLS-RFF algorithm has better identification accuracy and adaptive ability than the RLS algorithm in the reaction process of gradient parameters. To meet the requirement of precise identification in the reaction process of gradient parameters, it is important to select the right forgetting factor. This paper mainly identifies the consequent part of the T-S fuzzy model. For future study, we will do more researches on the premise part identification as well as the consequent part identification to improve the identification accuracy.
ACKNOWLEDGMENT
This paper was supported by the National Natural Science Foundation of China (Grant No.60972162) and the Research and Development Project of Science and Technology of Yichang (Grant No.A2011-302-14).
REFERENCES
[1] Bates, Roger Gordon, Determination of pH: theory and practice, in press, 1973.
[2] Shuxin Du, “Set range intelligent controller for pH neutralization of industrial waste water,” Chinese Journal of Scientific Instrument. J. 25 (2):202-204, 2004.
[3] Mcavoyt T J, Hsu E, Lowenthal S, “Dynamics of pH in controlled stirred tank reactor,” Ind Eng Chem Process Des. J. 11(1):68-70, 1972.
[4] Goodwith G C and Sin K S, Adaptive filtering prediction and control. Prenticehall, Inc. NJ : Englewood Cliffs , in press,1984.
[5] Bhat N V, Minderman P A, Jr Macvoy T,et al, “Modeling chemical process systems via neural Computation,” IEEE Control Systems Magazine. J. 10(3):24-30, 1990.
[6] Nie J H, Loh A P, Hang C C, “ Modeling pH neutralization processes using fuzzy neural approaches,” Fuzzy Sets and Syst. J. 78(1):5-22 ,1996.
TABLE II.
THE ERROR COMPARISON OF DIFFERENT FORGETTING FACTOR
Forgetting factor
µ
The error of the RLS-RFF algorithm
0.99 0.0166
9.98 0.0150
0.97 0.0149
0.96 0.0157
0.95 0.0169
0.94 0.0183
0.93 0.0204
0.92 0.0247
0.91 0.0350
[7] Juanjuan Cheng, Yonghong Tan, and Bo Gao, “Identification of pH neutralization process based on support vector machine,” Journal of Lanzhou University of Technology. J. Vol.35 No.2, 2009.
[8] Gomez J C, Jutan A, Baeyens E, “Wiener model identification and predictive control of a pH neutralization process,” IEEE Proc-Control Theory App. J. 151(3):329-338, 2004.
[9] Qingchao Wang, Jianzhong Zhang, “Wiener model identification and nonlinear model predictive control of a pH neutralization process based on Laguerre filters and least squares support vector machines,” Journal of Zhejiang University-Science C (Computers & Electronics).J, 12(1):25-35,2011.
[10]Tao Liu, Zezhi Chen, Yuxiang Zhou, “Application of artificial neutral network for pH neutralization system identification,” Computers and Applied Chemistry. J. 23(12):1280- 1282, 2006.
[11]Min Han, Xiaomeng Jia, “Identification of neutralization control process based on universal learning network,” Journal of Dalian University of Technology. J. 43(1):119-123, 2003.
[12]Takagi T, Sugeno M, “Fuzzy identification of systems and its application to modeling and control,” IEEE SYST, Man, Cybern, SMC-15(1), 1985.
[13]Lixin Wang, Adaptive fuzzy system and control, in Press, 1995.
[14]Xiaohui Chen, “Identification Method of pH characteristic Based on T-S model,” the Proceedings of the 23rd Chinese Control Conference, in press,980-983 ,2004.
[15]Xiaohui Chen, Qianyi Han, “Application of Fuzzy Control to Production of Urea-Formaldehyde Resin Adhesive (UF),” Journal of China Three Gorges University (Natural Sciences).J. , 24(4):314- 316 ,2002.
[16]Chengzhi Yang, System Identification and Adaptive Control, in Press, 2003.
Xiaohui Chen was born in Sichuan
China in 1967. He received his master’s degree from Huazhong University of Science and Technology (HUST) , Wuhan, China, in 1996, He is currently an associate professor in the college of computer and information technology, China Three Gorges University. His research interests include wireless sensor networks, data mining, and intelligent control.
Jinpeng Chen was born in Hubei China
in 1986. He received his bachelor's degree from Huazhong University of Science and Technology (HUST), Wuhan, China, in 2010, he is seeking for his master’s degree in the college of computer and information technology of China Three Gorges University now. His research interests include wireless sensor networks, intelligent control, and embedded system.
Bangjun Lei was born in 1973. he got