Fast Automatic Smoothing for Generalized Additive Models
27
0
0
Full text
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
(10)
(11)
(12)
(13)
(14)
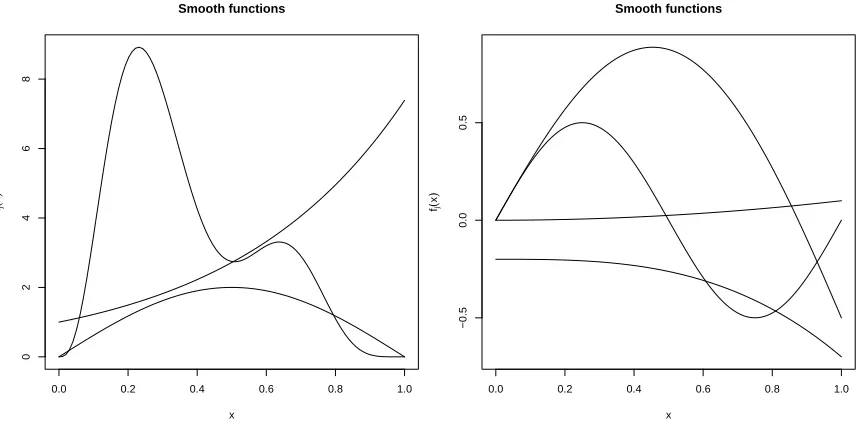
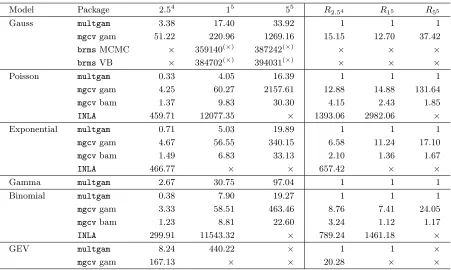
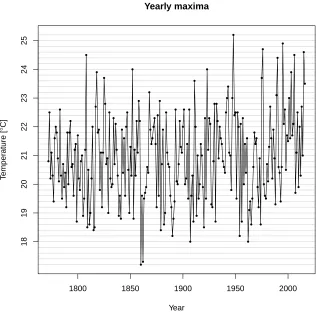
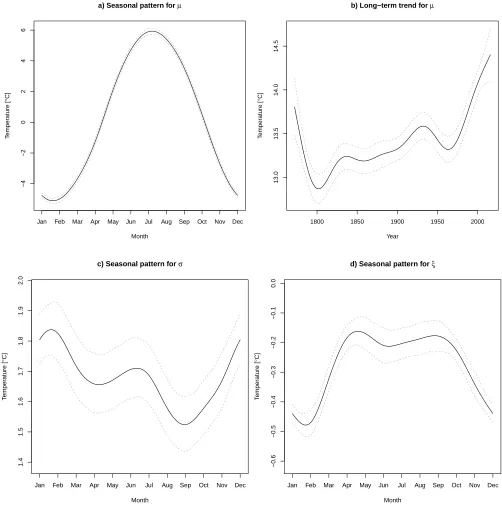
Figure

+3

Related documents
With cloud and managed security services, integrated technologies and a team of security experts, ethical hackers and researchers, Trustwave enables businesses to transform the
The above univariate analysis gives an interpretation of individual features and their individual relationships with the outcome. The SFS gives the best feature subset as explained
The PDQ-Endeca Connector Attribute Discovery configures the Endeca project directly from an Oracle DataLens Administration Server.. This component is implemented as a DSA
rapae number significantly decreased (compare with control) in treatments with Calypso and Decis (Table 2).. Efficiency of insecticides against caterpillars of small cabbage white
When you return to the Dashboard, you will see the hostname of the Domain Controller or other Windows machine that you installed the Connector on the 'System Settings > Sites
Firstly, this paper introduces the background and reasons of the financing difficulties of start-up enterprises in China's current economic situation and compares the
The PPP is procurement tool by which a public entity relies on the skills and performance of a private entity to implement a project.. The main difference with standards
