Author for correspondence:
Department of ECE, Nandha Engineering College (Autonomous), Erode-52.
Volume-7 Issue-1
International Journal of Intellectual Advancements
and Research in Engineering Computations
Improve localizing salient body motion in multi-person scenes using fuzzy
with morphological segmentation algorithm
RameshKumar J
1,Poomukilan V
2, Murugan J
21
Professor, Department of ECE, Nandha Engineering College (Autonomous), Erode-52.
2UG Students Department of ECE, Nandha Engineering College (Autonomous), Erode-52.
ABSTRACT
In this paper analyzed the potential of using CNNs to localize salient body movement in scenes with multiple people because such scenes are typical for vision applications in real environments. In this paper investigated a scenario that extended a typical one-person lab experiment to contain several people. One of those people performed a dynamic body gesture while the others were passive observers and only performed subtle movements. The task of the CNN was to detect and localize the person performing a ge sture from an image sequence and ignore non-gesture movements. To train our network with a large data variety, to introduce an approach to combine Kinect recordings of one person into artificial scenes with multiple people, yielding a large diversity of scene configurations in our dataset. We performed experiments using these sequences and show that the proposed model is able to localize the salient body motion of gesture set. In addition a new way for detection and tracking of human full-body and body-parts with color (intensity) patch morphological segmentation and adaptive thresholding for security surveillance cameras. An adaptive threshold scheme has been developed for dealing with body size changes, illumination condition changes, and cross camera parameter changes. Tests with the PETS 2017 and 2018 datasets show that we can obtain high probability of detection and low probability of false alarm for full-body. Test results indicate that our human full -body detection method can considerably out-perform the current state -of-the - art methods in both detection performance and computational complexity
INTRODUCTION
Body motion tracking and action recognition are study fields that are nowadays being researched in depth, due to their high interest in many applications. Many methods have been proposed whose complexity can significantly depend on the way the scene is acquired. Apart from the techniques that use markers attached to the human body, tracking operations are carried out mainly in two ways, from 2D information or 3D information On the one hand, 2D body tracking is presented as the classic solution; a region of interest is detected within a 2D image and processed. Because of the use of silhouettes, this method suffers from occlusions [1, 2]. On the other hand, advanced
body tracking and pose estimation is currently being carried out by means of 3D cameras, such as binocular and Time-of-Flight (ToF) cameras. Within the ToF field, different techniques are utilized; the most commonly used are he extraction of features from depth images and the processing of a stick figure model (or skeleton) using depth information (Figure 1.1) According to [3] the use of 3D information results advantageous over the pure image-based methods. The collected data is more robust to variability issues including vantage point, scale, and illumination changes. Additionally, extracting local spatial features fro m skeleton sequences provides remarkable advantages: the way an action is recognized by
Copyrights © International Journal of Intellectual Advancements and Research in Engineering Computations, www.ijiarec.com
humans can be conveniently represented this way, since the effect of personal features is reduced,
isolating the action from the user who performed.
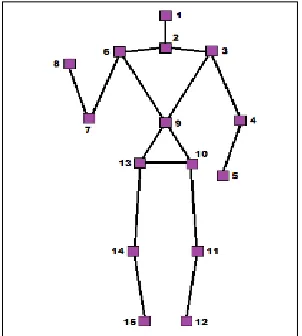
Fig. 1.1Fifteen-joints skeleton model
This derives in problems such as an increase in computational complexity and makes more difficult the extraction of key features of the action. Current methodologies use four stages to solve this: feature extraction, feature refinement to improve their discriminative capability (such as dimension reduction or feature election), pattern construction and classification. Then, by studying the temporal dynamics of the body performing the movement, we can decode significant information to discriminate actions. To that extent, a system able to track arts of the
human body for the whole duration of the action is needed.
However, many action recognition approaches do not utilize 3D information obtained from consumer depth cameras to support their system. The existence of state -of- the-art technology offering positions of the human body in all three dimensions calls for the emergence of methodologies that use it to track this information for a variety of purposes such as action recognition. In addition to this, an algorithm that is accurate and computationally efficient is needed.
RELATED WORK
It have combined the HOG features and the local binary pattern (LBP) features for improved performance. Lately Liao [14] has introduced the local ternary patterns (LTP) as an extension to the LBP. More recently in [3], Zweng and Kapel have evaluated a new algorithm for pedestrian detection using a relational feature model (RFM) in combination with histogram similarity functions. Relational features compute the similarity between histograms of the HOG descriptor describe a comparative study for tracking multiple persons using cameras with overlapping views. The evaluated methods consist of two batch mode trackers (and one recursive tracker, which integrate appearance cues and temporal information differently. This paper also added our own
Copyrights © International Journal of Intellectual Advancements and Research in Engineering Computations, www.ijiarec.com
Various methods have been proposed recently for such a multi-person tracking setting using overlapping cameras, but few quantitative comparisons have been made. In order to improve visibility regarding performance characteristics, this paper present an experimental comparison among representative state-of-the-art methods. This paper is selected one recursive method and two batch methods for this comparison. Furthermore, this made some performance improving adaptations to. The trackers were combined with the static background estimation method from and the adaptive background estimation method.
[2] Presents an extensive three year study on economically annotating video with crowd sourced marketplaces. Our public framework has annotated thousands of real world videos, including massive data sets unprecedented for their size, complexity, and cost. To accomplish this, we designed a state-of-the-art video annotation user intermotion and demonstrate that, despite common intuition, many contemporary intermotions are sub-optimal. This paper present several user studies that evaluate different aspects of our system and demonstrate that minimizing the cognitive load of the user is crucial when designing an annotation platform. This paper then deploy this intermotion on Amazon Mechanical Turk and discover expert and talented workers who are capable of annotating difficult videos with dense and closely cropped labels. We argue that video annotation requires specialized skill; most workers are poor annotators, mandating robust quality control protocols. This paper [5] presents the traditional crowd sourced micro-tasks which are not suitable for video annotation and instead demonstrate that deploying time-consuming macro-tasks on MTurk is effective. Finally, it also show that by extracting pixel-based features from manually labeled key frames, this paper is able to leverage more sophisticated interpolation strategies to maximize performance given a fixed budget. This paper [6] show the results of three years of experiments and experience in annotating massive videos unprecedented for their size and complexity, with some data sets consisting of millions of frames, costing tens of thousands of dollars, and requiring up to a year of continuous work to annotate. This
extensive study has resulted in our release of VTIC (Video Annotation Tool from Irvine, California), an open platform for monetized, high quality, crowd source video labeling.
Introduce a novel multi-view annotation tool for generating 3D ground truth data of the real location of people in the scene. The proposed tool allows the user to accurately select the ground occupancy of people by aligning an oriented rectangle on the ground plane. In addition, the height of the people can also be adjusted. In order to achieve precise ground truth data the user is aided by the video frames of multiple synchronized and calibrated cameras [3]. Finally, the 3D annotation data can be easily converted to 2D image positions using the available calibration matrices.
One key advantage of the proposed technique is that different methods can be compared against each other, whether they estimate the real world ground position of people or the 2D position on the camera images. Therefore, this paper defined two different error metrics, which quantitatively evaluate the estimated positions. This paper [9] used the proposed tool to annotate two publicly available datasets, and evaluated the metrics on two state of the art algorithms
Describe a visual tracking evaluation is sporting an abundance of performance measures, which are used by various authors, and largely suffers from lack of consensus about which measures should be preferred. This is hampering the cross-paper tracker comparison and faster advancement of the field. In this paper [13] provide an overview of the popular measures and performance visualizations and their critical theoretical and experimental analysis. We show that several measures are equivalent from the point of information they provide for tracker comparison and, crucially, that some are more brittle than the others. Based on our analysis we narrow down the set of potential measures to only two complementary ones that can be intuitively interpreted and visualized, thus pushing towards homogenization of the tracker evaluation methodology.
Copyrights © International Journal of Intellectual Advancements and Research in Engineering Computations, www.ijiarec.com
by adding cameras. By adopting such a multi-camera approach, multiple sensors cooperate for overall scene understanding. However, new issues arise such as data association and data fusion. This work addresses the issue of evaluating the performance of a multi camera tracking algorithm based on Rao-Black wellized Monte Carlo data association (RBMCDA) on real data. For this purpose, a new metric based on three performance indexes is developed.
METHODOLOGY
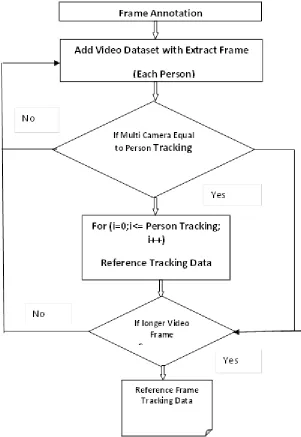
In this section the human motion that is to be found out in the video should be noticed previously into the database that should be saved in the database. For storing that the camera should be added for taking the snaps of the human in particular position or the place where the camera located. The previously added camera details are also view in the grid view control that is done in this module. The different electrical consumables that is in the camera are also noticed in this module to locate the human image taken in clear manner this process is been called. Without having searching image pattern image in the video is not possible to found the occurrence of the motion in the video that user needs to found.
Add Pattern and Select Snapshot
In this module human motion is chosen and then it is been added to the database for that the specific area of the human motion is selected and stored as the pattern. With that selected pattern image the searching is carried out. For the selection of the snapshot that is taken in the camera will be noticed. The date and time the snap are taken is stored in the database.
The view is also provided for the pattern that is already stored that details are stored in the database and will be generated as the view using the grid view control. The selected pattern is done using the command click the specific camera is chosen and with that camera id the snap is been waited [5-9]. View is generated using the grid view control and the snapshots stored will be shown in this grid view.
Split into Frames
This module the video or the image is applied into frames and then each image is split into frames and stored to the database for the future reference. For that process command click is used to split the image into frames is been done in this module. For doing this picture box control is used and explore control is to explore the split image to the user.
Annotation
In this section the movie id and the frame id is been selected using the machine learning algorithm the previously added movie and the split frames are stored in this annotation module. The selected details are stored to the database. This module also has view that is designed using the grid view control. The added annotation is also having in this module [11, 12, 13].
This also includes the annotation titles that are video added for the annotation and the frames they split for the annotation are shown in this module. This view is created using the grid view controls. This module also includes the separate view for displaying the person character name and the movie id are shown in this module.
CNN AND FUZZY MEANS
CLUSTERING OF BODY MOTION
Copyrights © International Journal of Intellectual Advancements and Research in Engineering Computations, www.ijiarec.com
the Panel control with different color pixels. Then to display the cluster information, Tooltip option is
implemented in this module.
Fig 3.1. CNN and Fuzzy Clustering Model
Visual tracking has been studied for years, which has resulted in a rich and abundant scientific literature, summarized well in recent surveys Existing multi-view trackers are usually evaluated on relatively simple content such as people walking or standing without the presence of furniture and for practical reasons on short sequences, For real-life applications there is a considerable risk that existing solutions are over-tuned to specific datasets.
Copyrights © International Journal of Intellectual Advancements and Research in Engineering Computations, www.ijiarec.com
datasets (with overlapping views) which have been used to evaluate trackers.
Most of these datasets were manually annotated using tools like VIPER. This available ground truth is very useful, but it does not always represent the desired experimental conditions for
new research, which may require different camera resolutions or frame rates, different numbers or types of cameras with different viewpoints, different environmental conditions, etc. What is needed are more efficient procedures to generate annotations, or a substitute for it, in new datasets.
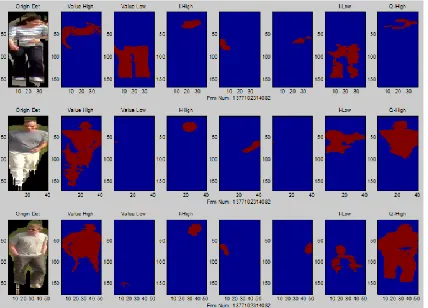
Fig 3.2 Human Body Segmentation
In this figure 3.2 describe the CNN and Fuzzy Segmentation process. Generation of references for evaluation is of vital importance for assessing and improving the performance of detectors and trackers. Comprehensive ground truth databases are mostly created using labour-intensive manual annotation of videos, which usually restricts the
database to short sequences one approach is to rely on crowd-sourcing, as has been done for detailed annotation of persons in single images and for delineating bounding boxes in videos. However, even this approach is still labour intensive and requires considerable training and validation to ensure quality of the results.
Copyrights © International Journal of Intellectual Advancements and Research in Engineering Computations, www.ijiarec.com
Fig 3.3 Filtering Analysis
Fig 3.4 Detection Human Action
Procedure for semiautomatic annotation of people tracking in long multi-camera sequences, and provide a new annotated video database where a person performs different activities involving different poses. The methodology aims to produce
reference tracking data with minimal human effort and with an estimation of precision under given values of desired position accuracy, i.e. the fraction of the resulting annotations with a positional error larger than a specified threshold.
Copyrights © International Journal of Intellectual Advancements and Research in Engineering Computations, www.ijiarec.com
Fig 3.5 Detection Multi Human Body Action
With a given amount of human effort, our proposed approach allows producing reference data for much longer video sequences than is currently possible. This allows (future) trackers to be evaluated on a much richer test data set, encompassing a wider variety of environmental conditions, with more diverse camera setups, scenes and person appearances
CONCLUSION
A new way for detection and tracking of human full-body and body-parts (head, torso, arms, and legs) using color and intensity patch segmentation. With the help of morphological connecting and cutting image processing, the fusion of various individual sub-patch segmentations is used for full-body detection, while the individual V, I, and Q segmentations are used for body-parts detection.
An adaptive thresholding scheme has been developed for dealing with body size changes, illumination condition changes, and cross camera parameter changes. Preliminary tests show that we can obtain high probability of detection (Pd) and low probability of false alarm (Pfa) for both full-body and full-body-parts (human heads). Furthermore, the detected body-parts allow us to extract important local constellation features for human walking gait estimation, human pose estimation for potential abnormal behavior and accidental event detection, as well as for human face recognition improvements with super-resolution techniques. The algorithms are highly parallelizable since the various V, Y, S, I, and Q images can be processed independently without needing interactions between each other. Therefore, current state of-the-art GPU and FPGA techniques should be able to speed the execution time up to real-time.
REFERENCES
[1]. A. Yilmaz, O. Javed, and M. Shah, “Object tracking: A survey,” ACM Comput. Surv., 38(4), 2016, 13. [2]. H. Yang, L. Shao, F. Zheng, L. Wang, and Z. Song, “Recent advances and trends in visual tracking: A
review,” Neurocomputing, 74(18), 2017, 3823–3831.
[3]. X. Li, W. Hu, C. Shen, Z. Zhang, A. Dick, and A. Van Den Hengel, “A survey of appearance models in visual object tracking,” ACM Trans. Intell. Syst. Technol., 4(4), 2013, 58.
[4]. M. Liem and D. Gavrila, “A comparative study on multi-person tracking using overlapping cameras,” in Proc. 9th Int. Comput. Vis. Syst., 2013, 203–212.
[5]. Amazon. Amazon Mechanical Turk, accessed [Online]. Available: http://www.mturk.com, 2016.
[6]. C. Vondrick, D. Patterson, and D. Ramanan, “Efficiently scaling up crowdsourced video annotation,” Int. J. Comput. Vis., 101(1), 2013, 184–204.
Copyrights © International Journal of Intellectual Advancements and Research in Engineering Computations, www.ijiarec.com
[8]. A. Sorokin and D. Forsyth, “Utility data annotation with Amazon mechanical turk,” in Proc. CVPRW, 2018, 1–8.
[9]. A. Utasi and C. Benedek, “A multi-view annotation tool for people detection evaluation,” in Proc. VIGTA, 2012, 1–6.
[10].G. Miller et al., “MediaDiver: Viewing and annotating multi-view video,” in Proc. 30th Conf. Human Factors Comput. Syst. Extended Abstracts, 2013, 1141–1146.
[11].B. Zhong, H. Yao, S. Chen, R. Ji, T.-J. Chin, and H. Wang, “Visual tracking via weakly supervised learning from multiple imperfect oracles,” Pattern Recognit., 47(3), 2014, 1395–1410.
[12].A. T. Nghiem, F. Bremond, M. Thonnat, and V. Valentin, “ETISEO, performance evaluation for video surveillance systems,” in Proc. AVSS, 2007, 476–481.
[13].PETS. Pets2001 Dataset, accessed [Online]. Available: http://www.cvg.reading.ac.uk/pets2001/pets2001-dataset.html, 2016.