Faculty of Computer ScienceInstitute of Systems Architecture
Diploma Thesis
DEVELOPMENT OF A AUTONOMOUS
BUILD AND DISTRIBUTION SYSTEM
FOR SOFTWARE WITH HYBRID
DEVELOPMENT MODELS
Tino Breddin
Mat.-Nr.: 326234
Supervised by:
Prof. Dr. Alexander Schill, Dipl. Inf. Josef Spillner
ABSTRACT
The Open-Source Software business model has helped Open-Source Software (OSS) to gain acceptance within the software industry as viable software which can handle mission critical tasks. This model has also introduced a new way to develop Open-Source Software. Instead of being entirely developed by a open community of developers, a company supports and leads the development primarily. MoreoverOSSprojects in general benefit from the increasing interest, with more developers helping such projects. The distributed nature ofOSSdevelopment teams requires new ways to manage projects in order to achieve good productivity. Concepts like Continuous Integration provide such methods, focusing on improving information sharing and instant feedback on changes within a development process. Continuous build systems are a central part of any infrastructure which implements Continuous Integration methods and as such holds an important role to improve software quality.
Good software quality includes robustness in regard to the deployment environment of any given software. Better quality is perceived by users if they don’t run into problems when setting up and using the software. Modern continuous build systems don’t help development teams as much as desirable in such cases. Old concepts which build the foundation of such systems prohibit the enhancement of these to be of better use. Therefor the system which is developed in this thesis, named Swarm, is based on different concepts which are meant to support software development teams in a improved manner.
Swarm’s core is based upon the use of many so called production environments, as the environments in which software should be build and tested is called as part of Continuous Integration. To further integrate well with development processes based on Distributed Version Control Systems, the features of such systems are used to provide feedback for the various changes to a software project which are available through various communication channels. The prototypical implementation of the system presented in this thesis shows how software quality can be boosted further than existing continuous build systems can do. Moreover Swarm can be adapted to allow even more improvements which is reserved for future extensions.
Dedication
For my great-grandma, Gertrud. She will always be remembered as the kind women she was. For my wife, Marie-Kristin, who always finds ways to make me smile. For my family, thanks for the unconditional support throughout my studies.
CONFIRMATION
I confirm that I independently prepared the thesis and that I used only the references and auxiliary means indicated in the thesis.
Dresden, August 10th, 2010
CONTENTS
1 Introduction 13
1.1 Motivation . . . 13
1.2 Idea . . . 14
1.3 Structure of the Thesis . . . 14
1.4 Summary . . . 14 2 Background 15 2.1 Continuous Integration . . . 15 2.1.1 Concepts . . . 15 2.1.2 System: CruiseControl . . . 16 2.1.3 System: Hudson . . . 17 2.1.4 Summary . . . 17
2.2 Source Code Management . . . 17
2.2.1 History of Version Control . . . 17
2.2.2 Centralized Version Control . . . 18
2.2.3 Distributed Version Control . . . 18
2.2.4 Git . . . 19
2.2.5 Summary . . . 21
2.3 Collaborative Software Development . . . 21
2.3.1 Sourceforge . . . 21
2.3.2 Github . . . 21
2.3.3 Summary . . . 21
2.4 Erlang/OTP Project . . . 22
2.4.1 Language Characteristics . . . 22
2.4.2 Open Telecom Platform . . . 24
2.4.3 Development Process . . . 24
2.4.4 Summary . . . 24
2.5 Summary . . . 25
3 Swarm — A Distributed Build System 27 3.1 Requirements Analysis . . . 27
3.1.1 Continuous Integration . . . 27
3.1.2 Distributed Version Control Systems . . . 28
3.1.3 System Integration . . . 28
3.1.4 Summary . . . 29
3.2 System Principles . . . 29
3.2.1 Single Project Support . . . 30
3.2.2 Deferred Authentication . . . 31
3.2.3 Git SCM Support . . . 31
3.2.4 Summary . . . 32
3.3 System Design . . . 32
3.3.1 Architecture . . . 33
3.3.2 Subsystem: Platform Management . . . 33
3.3.3 Subsystem: VCS Interface . . . 39
3.3.4 Subsystem: Data Storage . . . 43
3.3.5 Subsystem: Job Processor . . . 49
3.3.6 Subsystem: Operation and Management . . . 52
3.3.8 Summary . . . 58 3.4 System Integration . . . 58 3.4.1 Event Hooks . . . 59 3.4.2 Hook Scripts . . . 59 3.4.3 Summary . . . 60 3.5 Workflows . . . 60
3.5.1 Latest Version Change . . . 60
3.5.2 Result Propagation . . . 61 3.5.3 New Change . . . 63 3.5.4 Summary . . . 63 3.6 Summary . . . 63 4 Evaluation 65 4.1 Component-based Development . . . 65 4.2 Usage of Erlang/OTP . . . 65 4.3 Test Run . . . 66 4.4 Test Deployment . . . 67 4.5 Summary . . . 67 5 Conclusion 69 5.1 Plugin Support . . . 69 5.2 Restful HTTP API . . . 69 5.3 Native VCS Support . . . 70 5.4 Inter-Instance Communication . . . 70 5.5 Summary . . . 71 List of Figures 72 List of Tables 74 Glossar 77 Acronyms 79 Bibliography 80 Contents 11
1
INTRODUCTION
The topic of this thesis is introduced in this chapter by giving a detailed explanation of the initial motivation in section 1.1. The following section 1.2 concisely summarizes the idea which builds the foundation for this work. Lastly the structure of this thesis is presented in section 1.3 and the foundations for this thesis are summarized in section 1.4.
1.1
MOTIVATION
In recent yearsOSShas emerged as a business opportunity which is now well known as the Open-Source Software business model. While some companies make their software available to the public to drive adoption others specialize on supporting already establishedOSSprojects. While it becomes easier for all participants to use Open-Source Software, this is not necessarily the case when it comes to driving the development forward. Often companies have well established internal development procedures which they don’t want to expose to the public. This makes it hard for external developers to contribute to a project. Furthermore in-house development driven by customer projects might not be integrated with theOSSversion of the software.
In parallel to the development of theOSSbusiness model, the development models being used have change as well. This led to the adoption of continuous build systems to improve software quality and feedback about changes throughout the complete development cycle of a software project. This class of software already provides tremendous benefits for any software project. Still, these build systems have been designed with other requirements in mind than modern
OSSprojects are presented with. Software is expected to support many operating systems and integrate with an ever-changing and divers set of third-party software.
If the gap between in-house development at companies and efforts ofOSSdevelopers could be bridged to connect the different workflows without ongoing manual effort, contributions would be much easier to integrate than it is the case at the moment. Such changes would enable the collaboration betweenOSSprojects and corporations in new ways when it comes to software development.
In addition the possibilities to more easily extend support for operating systems would add more benefits to the overall goal, to improve software quality which itself helpsOSSprojects to drive adoption.
1.2
IDEA
The concept of continuous build systems needs to be reconsidered based on the requirements of modernOSSprojects. The core functionality of build systems should be modified to provide the ability to build software on many different systems by default. Furthermore the outcome of builds should be easily sharable with other tools to enable the creation of sophisticated development processes. As a Proof of Concept (PoC) for these core functionalities a continuous build system should be developed which proves the aforementioned benefits while taking a simplistic approach in regard to other aspects of modern build systems.
1.3
STRUCTURE OF THE THESIS
Chapter 1 opens up this thesis by introducing the underlying motivation and general idea to solve the described problems. Subsequently relevant topics, such as Continuous Integration (CI) and Source Code Management (SCM), are explored in detail in chapter 2 to provide the
necessary background for further discussions. The system itself is developed in chapter 3. This includes the requirements analysis as well as the system design. The results are evaluated in chapter 4 in regard to the initial assumptions and gathered requirements. Finally this thesis concludes by discussing shortcomings and future improvements in chapter 5.
1.4
SUMMARY
OSSdevelopment has led to rapid changes both in software development practices and software business models. Unfortunately the available software development tools don’t allow
OSSprojects to fully exploit collaboration between all contributors and drive user adoption, as explained in further detail in section 1.1. Instead it is suggested in section 1.2 that a novel continuous build system should serve as a showcase of how new core functionalities can further enhance the software quality ofOSSprojects. Lastly section 1.3 describes the structure of this thesis.
2
BACKGROUND
The system which is developed in this thesis is based on the achievements made in different areas of software development to address the issues presented in the section 1.1. As the thesis’ title implies the developed system is a continuous build system, thus the theory behind Continuous Integration will be explained in section 2.1 and highlight the need for such systems. The various emerging Distributed Version Control System (Distributed VCS), e.g. Git [git] and Mercurial [mercurial], have changed the way developers share code and contribute toOSS
projects. Section 2.2 describes the history and basics of these systems briefly. The following section 2.3 gives examples for platforms which support collaborative software development withinOSSprojects. Subsequently the basics of Erlang, the programming language being used for the implementation of the system developed in this thesis, are explained in section 2.4. Section 2.5 summarizes the presented background while pointing out important aspects.
2.1
CONTINUOUS INTEGRATION
The term Continuous Integration was first defined by [Beck2000] as part of a set of Extreme Programming (XP) best practices. Building and testing a software product every time a
development task is completed was consideredCI. [Beck2000] arguments that this regular cycle would instantly show whether new changes break the software and could be addressed much earlier than in traditional development models such as theWaterfall Model[Royce1987]. This simple concept has evolved from a suggestedXP practice to a software development
methodology [Duvall2007] which is based on several practices of which the most important are briefly explained in the following sections.
2.1.1
Concepts
Build AutomationBuilding the current version of a software should be possible by executing a single command. The assumption is that the more steps a build process involves the more unlikely it becomes that developers actually build the software during development. This might not hold true for small projects but the more complexity and components are added to a software the more difficult the build process becomes. Keeping the simplicity of building software during the development is a crucial part of Continuous Integration.
Build Fast
During the development of software it is almost inevitable that the time which is needed to run a build increases. Building complex software can take several hours to finish which increases the time it takes until developer receives feedback by building. This leads to a state where nobody can tell whether recent changes have affected the system behavior or even broke the system entirely. To alleviate this situation one should focus on keeping the build process fast so that developers can actually build the software and test it after having applied changes. This can be achieved by creating components which are independent enough that it makes sense to build and test them individually after recent changes, while building and testing the whole system independently.
Progress Must Be Visible
Extreme Programming focuses on the interaction within a team instead of following strict processes. This creates a need for providing as much information as possible about the state of the development to any team member at any time. It should be visible how much work a team member was able to finish, which changes broke the system at which time by whom, how much attention has been put on individual components and whether a team member got stuck at a certain task. The goal is to keep all team members informed so that the most critical tasks can be tackled at any time.
Each Commit triggers Builds
A way to implement the principle described in the previous section 2.1.1 is to build the complete system every time a developer commits to the code base. In a software development team one measure for progress are committed changes, thus it is feasible to automatically provide feedback for any commit which is visible to all team members. It is essential that developers are relieved from the burden to start this process manually since this should be done behind the scenes.
Clone Production Environment
While developers tend to have a development environment which is specifically geared towards their personal needs, this too often isn’t the case for the build and test environments. To eliminate the risk of leaving issues undetected when running the developed system on the target platform, it is necessary to create a environment for the automatic builds and tests which resembles the target environment. This doesn’t only affect the chosen operating system but also the complete hardware and software stack of the target system. The better theCI
environment is modeled after the target environment the more confident can the development team be that they didn’t miss critical bugs before deploying the software.
2.1.2
System: CruiseControl
As one of the first successfulOSScontinuous build systems CruiseControl [cruisecontrol] has served as an example for many systems of that kind thereafter. Initially developed within ThoughtWorks the system has been published asOSSlater and found wide adoption. This is underlined by the subsequent offerings of commercial products by ThoughtWorks based on
CruiseControl to meet corporate user’s requirements. Technically CruiseControl is a traditional continuous build system which uses the server it is served from to run builds. Its flexible plugin architecture has helped to extend the base framework with various additional functionality which helped to spread adoption of the system even further. CruiseControl is still in active use and development with various spin-offs, written in other programming languages, being available.
2.1.3
System: Hudson
TheOSScontinuous build system Hudson [hudson] has become a very popular alternative to CruiseControl due to its extensiveSCMsupport and plugin architecture. Its development has been sponsored by Sun Microsystems thus attracting many users early on. Although it was initially being used as a continuous build system for Java projects, support for different projects has been added through the help of many additional plugins. The project keeps growing in popularity after receiving variousOSSawards lately. It is nevertheless based upon the very same principles as CruiseControl like using the local server for running builds.
2.1.4
Summary
Continuous Integration is comprised of various smaller concepts which are individually referred to as agile practices and as a whole help improving software development by sharing information. Notably the idea of making any progress visible to all members of a team as well as getting progress information as fast as possible support the idea ofCI. ManyOSScontinuous build systems have picked up these concepts and help shaping the software build process to fit such agile practices. TheOSSsystems CruiseControl and Hudson stand out because of their wide user adoption which is influenced by the versatility of both tools.
2.2
SOURCE CODE MANAGEMENT
When a team of software developers works on the same software it becomes increasingly important to be able to see who made which changes when. This need for organization led to the development of Version Control Systems (VCSs). Since version control is an integral part of any Continuous Integration environment it is necessary to highlight how version control started and how it has evolved until today. Section 2.2.1 covers the roots of Version Control Systems and details the important milestones in the development of the state-of-the-art systems. The class of Centralized Version Control Systems is covered in section 2.2.2. Furthermore
section 2.2.3 focuses on the recent developments in the area of Distributed Version Control Systems. Finally the takeaways of Source Code Management are presented in section 2.2.5.
2.2.1
History of Version Control
The development of special purpose systems for controlling source code became first publicly noticed through [Rochkind1975] and [Glasser1978] who introduced the concept of using aSCM
system and recent development in this area. [Tichy1982] showed the stages and culprits involved in working on such systems. The first widely usedOSS SCMcalled RevisionControl System (RCS), introduced by [Tichy1985], was an important milestone because it nourished the development of many different approaches in the area ofSCMas summarized by [Royce1987]. Further development has focused on Centralized Version Control Systems (Centralized VCSs) which are presented in detail in the following section 2.2.2. A recent conceptual change has been introduced by Distributed Version Control Systems, covered in section 2.2.3.
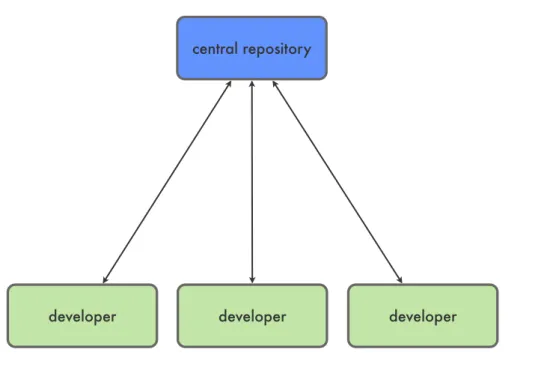
central repository
developer developer developer
Figure 2.1: A centralized version control workflow.
2.2.2
Centralized Version Control
The first group ofSCMsystems which received wide adoption were Centralized Version Control Systems. These systems rely on a central location to store all versioned data as well as version history. These locations are referred to as central repository. Figure 2.1 depicts a typical
Centralized VCSsetup with one central repository and several developers. These users can only checkout a single version of the data in the central repository. No further versioning information is kept within a developer’s copy of the data other than the version identifier itself. Thus all versioning knowledge is kept within the central repository. Furthermore developers are only allowed to push changes to the central repository. Those changes need to be based on the latest version of the data as well. This leads to a very inflexible process of working on the source code. However having this central authority can fit well into other parts of a software development process.
Concurrent Versions System (CVS) [cvs] is a notable implementation of such systems as it gained popularity after its initial release in 1990 and is still in active development. Further improvements are provided by theOSS Centralized VCSSubversion as described by [Pilato2004].
2.2.3
Distributed Version Control
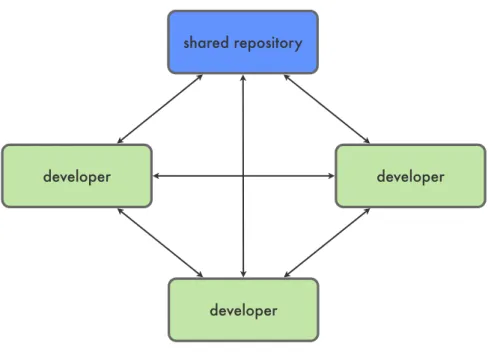
WhileCentralized VCSs employ a strict workflow based on a central repository the newer concept of Distributed Version Control Systems tries to support flexible workflows as much as possible by eliminating the need for central repositories. All copies of a repository are
considered full-fledged repositories themselves because all versioning metadata is kept within a copy as well. Therefor developers are given the freedom to share data more easily as shown in figure 2.2. This unconstrained flexibility allows teams to create workflows which are specifically tailored towards their needs by creating roles and logical contracts for repositories. Figure 2.3 presents a simple workflow which contains a single shared repository, which can only be
shared repository
developer developer
developer
Figure 2.2: A distributed version control setup.
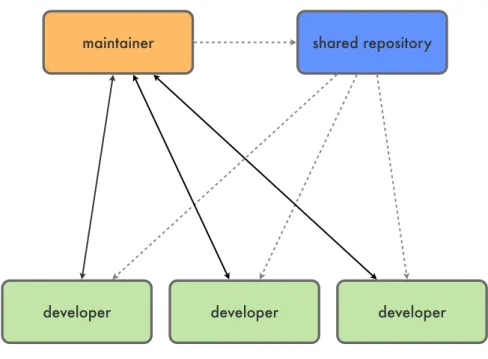
pushed to by a single maintainer. Developers can read from the shared repository and share data between each other. But ultimately final changes need to be send to the maintainer for inclusion in the team’s shared repository. This example shows how versatile Distributed Version Control Systems are in terms of workflow adaptation.
While there are manyDistributed VCSs available, especially two systems have established themselves as the state-of-the-art. Mercurial [mercurial] is a system implemented in Python which focuses on providing a easy user interface, thus there is always only one way to do a certain task. Another approach is taken by Git [git] which is implemented in C and often provides the developer many options to accomplish a certain task. In general both systems are very similar regarding their features and performance.
2.2.4
Git
Git has initially been developed by the Linux Kernel Development Team to support their complex requirements forSCM. Since then it has become very popular especially in theOSS
community. Git provides many ways to organize and change the source code one is controlling with it. But the system developed in this thesis only needs a small subset of the features available thus the important features and their usefulness are discussed in this section.
Branching
Creating branches of the source code is a essential tool to separate different development paths with the same base source code. The concept is that one can work on a separate branch for a set of features and once all changes have been committed, these would be added to the main branch again. Creating a new branch used to be a time consuming operation inCentralized VCSswhich often involves the locking of the main branch, thus blocking anybody from
committing changes.
shared repository
developer maintainer
developer developer
Figure 2.3: A development workflow employing a maintainer to approve changes to the shared repository.
Git performs branching operations very fast because it is able to operate locally instead of having to synchronize with a remote server. This allows for a more flexible usage of branches, such as having a separate branch for each known bug or feature which somebody is working on. Switching a branch is fast as well, so that one can change between so calledTopic Branches
easily if necessary, without mixing fixes for a bug or the implementation of a new feature. Developers are encouraged to use many branches instead of mostly working on the main branch.
Merging
When making extensive use of branches the actualmergingof changes in a branch with another branch is very important. Just as with branching themergeoperation itself is very fast which enables developers tomergeoften, to check that recent changes work well with the downstream of the project. Furthermore Git uses a multi-stagemergingalgorithm which is supposed to work very well without much manual interaction.
Rebasing
Therebaseoperation is used to align the changes in a branch to an upstream branch. It rolls back the local branch to the last commit it has in common with a upstream branch. Then it will apply the new changes from the upstream branch to the local branch. Finally the local changes will be re-applied on top of the upstream changes. If Git experiences merging problems the developer will have to manually merge the conflicts. The operation is supposed to be used to apply local changes on top of the upstream changes without actually merging them from the beginning. Therefor the upstream changes become the base for any local changes, thus one will rather edit the local changes than the ones from the upstream branch which are supposed to be working and well tested.
2.2.5
Summary
Source Code Management has become an integral part of any software development process over the last decades. In this section an overview has been given over the History of Version Control 2.2.1 beginning withRCSas the first widely usedOSSVersion Control System until the more recent systems, such as Mercurial, gained traction. The two dominant approaches for
SCM,Centralized VCSandDistributed VCS, mostly differ in how flexible the workflows are which they enforce as described in detail in sections 2.2.2 and 2.2.3. Git, a popularDistributed VCS, puts an emphasis on the speed of any operation it performs and is used for the system developed in this thesis.
2.3
COLLABORATIVE SOFTWARE DEVELOPMENT
Open-Source Software has led to the assembly of many teams which work in separate physical locations around the planet. Inevitably traditional software development tools which are used in corporations can’t provide sufficient support for such flexible teams. This has led to the development of new tools and platforms which help developers to collaborate on projects productively while being physically separated. Two popular web platforms for collaborative development are presented in sections 2.3.1 and 2.3.2. Lastly section 2.3.3 summarizes the benefit for development teams.
2.3.1
Sourceforge
As one of the first project hosting platforms SourceForge became a hub forOSSprojects. It started out in 1999 with source code hosting and added more advanced features ove time to become a full-fledged project hosting platform. These features include bug tracking, wikis, forums and mailing lists. The platform also expanded to offering commercial plans for closed projects, which essentially receive the same features.
2.3.2
Github
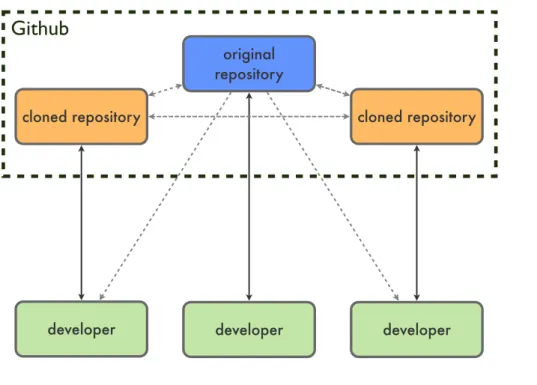
Many project hosting platforms provide various options for the different features which are available, while some niche platforms focus on one option for each feature instead. Github is one such niche platform which started as a source code hosting platform for Git repositories. Later it has become a viable platform for complete projects though, while still focusing on giving developers only one option for any feature such as code reviewing or wikis. The platform has found wide adoption especially because of its early support for Git hosting. The common workflow for code sharing on Github is depicted in figure 2.4. Any developer can create a clone of an existing public repository, which is then tied to his own Github account. This repository can be used to share code changes with others since it is publicly available. Other developers can then incorporate these changes into their own copies of the original repository.
2.3.3
Summary
Teams which are physically separated need not only a way to share information but also need to be able to setup processes which support their efforts. Because of the ubiquitous internet access especially web-based tools have been adopted for such purposes. Both SourceForge and Github, which were described in sections 2.3.1 and 2.3.2, are popular among the large set of such platforms because auf their good feature set.
original repository developer cloned repository developer developer cloned repository
Github
Figure 2.4: A common workflow for repositories hosted on Github.
2.4
ERLANG/OTP PROJECT
The Erlang/OTP project comprises the development of the programming language Erlang and a set of well supported applications referred to as Open Telecom Platform (OTP). The language itself was developed at the Ericsson CSLab from the 1980s until it was made available asOSSin 1998 [?]. The language and libraries are covered by the Erlang Public License [epl]. Since then Ericsson has continued driving the development of the language especially because it’s still used for internal product development. Erlang/OTP is already widely used for telecom and messaging applications while the adoption for systems which require easy scalability and fault-tolerance is increasing steadily over the last years.
This section introduces Erlang/OTP by giving a dense overview of the language in section 2.4.1 itself and its libraries in section 2.4.2. Section 2.4.3 focuses on the current development process which is used by the Erlang community. Finally section 2.4.4 summarizes the findings and shortly discussed the use of Erlang in this thesis.
2.4.1
Language Characteristics
Erlang is often referred to as aconcurrent functional programming language. It has several features which are meant to make programming concurrent applications easier. The most important of those are briefly described in this section in addition to some language basics.
Virtual Machine Erlang source files (.erl) are compiled to byte-code (.beam). This byte-code is
then interpreted at runtime by the Erlang Virtual Machine, called BEAM. This gives Erlang the advantage of good portability, since the compiled code is platform independent. The virtual machine itself is optimized for multi-core processors which improves its performance on modern hardware tremendously.
Lightweight Processes A fundamental language construct are processes. A process is some code which is executed sequentially. It has a very small memory footprint as well as fast creation and destruction performance. The Erlang Virtual Machine can manage millions of processes while only being memory bound. Processes can be executed in parallel making executing chunks of code in parallel very trivial. Listing 2.1 shows how a process can be started, which is calledspawningin Erlang terminology.
1 spawn( fun ( )−> e r l a n g : d i s p l a y ( h e l l o _ w o r l d ) end) .
Listing 2.1: Spawning a process which prints a message to stdio.
Message Passing Erlang processes don’t share any memory. Thus messages are being used
to send data between processes. Any process can send any type of data to any other process in the system. At a receiving process all incoming messages are being added to a receive queue from which the process can pull new messages. Therefor the language provides thereceive
keyword which makes a process block and pull the oldest message from the queue. Listing 2.2 shows how messages are send and received.
1% sending message t o myself ( the r u n n i n g process ) 2 s e l f( ) ! {d i s p l a y , h e l l o _ w o r l d}. 3 4% r e c e i v e t h a t s p e c i f i c message 5 r e c e i v e 6 {d i s p l a y , Msg} −> e r l a n g : d i s p l a y ( Msg ) 7 end.
Listing 2.2: Sending and receiving messages with one process.
Hot Code Swapping The virtual machine provides the ability to swap Erlang byte-code at
runtime, allowing systems to be upgraded without any downtime. Therefor two versions of any givenmoduleare kept in memory, the current versionVand the older versionV-1. If a new version of a module is loaded it becomes the current versionVwhile the former current version becomesV-1. All new processes will be using the current version of the module, whereas already running processes will continue to use the older version. Yet the running processes can choose to upgrade to the current version at any time, making it possible to upgrade whole systems without having to restart running processes.
Single Variable Assignment As mentioned earlier Erlang doesn’t have any shared memory.
This concept has been taken to the variable level by making variables immutable after being assigned a value. This allows for easier tracing of errors because the assignment of a value to a variable is explicit. However this concept can lead to messy code in practice if not used properly. Listing 2.3 shows how variables are assigned properly.
1% p r o p e r assignment o f a new v a r i a b l e 2 MyVar = 1 .
3
4% f a i l i n g assignment , because v a r i a b l e i s a l r e a d y a s s i g n e d
5 MyVar = MyVar + 2 . % r e t u r n s : ∗∗ e x c e p t i o n e r r o r : no match o f r i g h t hand s i d e v a l u e 3 6
7% p r o p e r assignment 8 MyVar2 = MyVar + 2 .
Listing 2.3: Correct variable assignment and common failures.
Distributed Erlang Message passing and lightweight processes give programmers a easy abstraction from multi-core processors allowing them to make use of all available resource without having to worry about multi-threading.Distributed Erlangprovides the same level of abstraction on a system level. A single running Erlang virtual machines is callednode. Erlang nodes can be connected in the sense that processes from each node can communicate through messages with each other. This makes it trivial to run any Erlang program on more than one Erlang node. The real advantage is that these nodes can reside on different physical machines, which allows programmers to run a distributed system on top of distributed Erlang.
2.4.2
Open Telecom Platform
Erlang is shipped with a set of applications which act as the standard library for the language. These applications are referred to asOTP, named after their initial development as part of telephony development projects. These applications are known to be well tested and in
production use for many critical systems, thus the Erlang/OTP team encourages users of Erlang to utilize theOTPas much as possible. The applications are constantly improved to ensure that they present a viable solution for common problems.
2.4.3
Development Process
After Erlang/OTP has been made available to the public as Open-Source Software in 1998, the Erlang/OTP team at Ericsson continued to manage the development of the language. New releases would be published on a regular basis, but the development wasn’t visible to the public. Furthermore the direction of development was largely based on customer’s needs. The
interaction with the Erlang community was mainly based on three mailing lists, one for bug reports, one for patches and one intended for general discussion.
EEPs In order to be able to get involved in the development of the language itself one would have had to write an Erlang Enhancement Proposal (EEP) [eep]. Those proposals were meant as a base for discussing important language changes before any work is done.
This process has worked well until 2008, when the Erlang community started to grow and it became apparent that Erlang/OTP would benefit from a better community involvement in the development process. In 2009 the Erlang/OTP team started to open up their development process by publishing the main development branch of Erlang/OTP on Github [erlangongithub]. Now developers are able to contribute changes to the development version by sending
standardized patches to the patches mailing-list. Those patches will then be reviewed and potentially added to the development branch. Thus the open source community is now more involved into the development which has led to an increased interest in Erlang/OTP, judging from the number of patches submitted to the mailing list.
2.4.4
Summary
Erlangis a mature programming language which is often used for programming highly concurrent applications. Together with its standard libraryOTP it allows developers to create scalable and fault-tolerant software with less effort than would be necessary with other programming languages such as C. Erlang is also a functional programming language which uses concepts such as pattern matching, no shared data and single-assignment variables to allow programmers to express difficult problems more easily. The language is Open-Source Software and available from its main source code repository on Github [erlangongithub].
2.5
SUMMARY
Continuous Integration is a software development methodology which emphasizes sharing of information within a project. The concepts behindCIand continuous build systems which actually implement these concepts were described in section 2.1. Section 2.2 presented the history and modern tools for Source Code Management which became increasingly important as software project became more ambitious and complex. It focused on Git as it is used within the system which is developed in this thesis. Subsequently the importance of project hosting platforms for collaborative software development were explained in section 2.3, giving Github as an example for such platforms. Lastly section 2.4 gives a short introduction to the programming language Erlang, which is used for the prototypical implementation of the system developed in this thesis. Its strength for concurrent programming are especially useful for the concurrent nature of the this system.
3
SWARM — A DISTRIBUTED
BUILD SYSTEM
Continuous build systems have been gaining popularity ever since Continuous Integration has been adopted by more and more software development teams. As a result those systems have matured to a point where there are many available systems which provide very similar
capabilities. The system which is proposed in this chapter takes a different approach in regard to some concepts which have been indicated in section 1.1. Section 3.1 creates the foundation for this proposal by specifying the high-level requirements for this system. Three important system principles are defined in section 3.2 before the system design is presented in elaborate detail in section 3.3. Subsequently the capabilities for integration with third-party systems is outlined in section 3.4 before some core workflows of the system are explained in section 3.5. Lastly this chapter is concluded by a summary of the proposed system in section 3.6.
3.1
REQUIREMENTS ANALYSIS
This section presents the requirements for Swarm. Section 3.1.1 outlines the requirements which are defined by existing continuous build systems and the concept of Continuous Integration. Furthermore the popularity of Distributed Version Control Systems requires some novel functionality as well which is explained in section 3.1.2. In addition section 3.1.3 describes ideas from general systems integration which relate to continuous build systems. To conclude all requirements are again summarized in section 3.1.4.
3.1.1
Continuous Integration
Continuous Integration as a development methodology already defines a set of requirements which continuous build systems need to adhere to. These can also be identified by looking at some core features of existing continuous build systems.
Project Repository Monitoring As part of a project which is setup within the continuous build
system the respective source code repository should be monitored automatically. This allows the continuous build system to notice when the latest version within the repository changes.
Build Latest Version Furthermore the continuous build system should build and test the latest version of the source code, once it changed. The delay between the time when the change was published and the start of the build should be as small as possible.
Make Results Publicly Available Continuous Integration stresses the fact that any
information about the state of the source code should be shared within a team. Thus the results of builds of a project need to be presented in a publicly readable form, once available. That means even results from ongoing builds should be presented.
Build in Production Environment The motivation of this thesis presented in section 1.1
states that builds need to be run on many systems to improve software quality rather than sticking to one particular environment. This requirement especially holds true forOSSprojects. Therefor a continuous build system needs to be able to build the source code on as many platforms as possible, which are distinct from the one it is running on.
This requirement also marks a conceptual change from existing continuous build systems, which focus on using the platform they are running on as the reference environment.
3.1.2
Distributed Version Control Systems
The paradigm change within Source Code Management systems has allowed development teams to customize their development workflow towards their needs. In addition developers are presented with many now effective methods to control their source code, such as branching. Continuous build systems need to adapt to this change to be able to keep up with the changing pace of development.
Build Topic Branches Globally shared repositories are not the first destination of changes
within custom development workflows anymore. Teams might decide to only submit verified changes to their central repository, while changes which still need to be verified are kept in the developers repositories, some other shared repository or within a code review system. Either way, part of the verification should be the building of changes as soon as developers have finished working on these. A continuous build system should build such changes whether they live in a repository as topic branches, are kept as patches in a code review system or send as an email to a mailing list. The same benefits of building the latest version of some source code apply to building potential changes to the latest version, which is the next step of Continuous Integration.
This requirement marks another conceptual change from existing continuous build systems, since these only take the latest version in a repository into account when looking for changes.
3.1.3
System Integration
A continuous build system is usually part of a larger combination of systems which support the development process of a team. Within this process each system has its dedicated purposes and brings distinct advantages. Just like other systems a continuous build system needs to be properly integrated into such an environment to fully exploit the advantages of Continuous Integration.
Share Results An important part of the integration is that results of builds for any change are shared with other systems within the build environment. This allows the setup of sophisticated processes which propagate the data to the correct communication channels. Thus a continuous build system should provide the foundation for sharing results with other communication channels.
Share Results with other System Instances OSSprojects are usually developed by many
participants which can be both individuals and corporations as observed in the motivation of this thesis in section 1.1. Thus the development might not be centralized and based on a single defined process. Instead the different parties might have separate processes and development environments, but are still working on the same project. In such cases receiving information about changes which have been made within another environment can be as important as changes from within the own environments. Thus a continuous build system should be able to share both changes and their results with other instances of the system.
This requirement defines another conceptual change from existing continuous build systems, because these have been regarded as stand-alone systems ever since. This sharing of information would truly federalize information between development environments.
3.1.4
Summary
In this section the following set of core functionalities has been defined which should be provided by a next generation continuous build system.
• Project Repository Monitoring
• Build Latest Version
• Make Results Publicly Available
• Build in Production Environment
• Build Topic Branches
• Share Results
• Share Results with other System Instances
They are influenced by the concepts behind Continuous Integration, Distributed Version Control Systems and system integration. Each of these requirements will be further discussed as part of the system design in section 3.3.
3.2
SYSTEM PRINCIPLES
This section explains the principles which the bespoke system follows in addition to implementing the requirements gathered in section 3.1. These principles allow the system design, which is covered in detail in section 3.3, to be very precise without focusing on extensibility where it isn’t needed.
The following principles will be presented in detail in the following sections.
• Single project support
• Deferred authentication
• Git-onlySCMsupport
A summary of the applied system principles is given in section 3.2.4.
3.2.1
Single Project Support
Popular continuous build systems often provide support for multiple projects at a time. This feature is required due to the nature of the usage of such systems and the groups of users. The monitored software tends to be project-related thus running for a specified amount of time during which the feedback from Continuous Integration is most important. After the project has finished the software might still be monitored but since no changes will be added the
continuous build system won’t add any benefit thereafter.
In the case of such time-delimited projects the administrative overhead should be kept to a minimum. Having one instance of a continuous build system being able to monitor many projects eliminates the need to setup an instance per project. This saves the system administrators time as well as resources since no additional hardware is needed.
Swarm is meant to be used by projects with different characteristics. Such projects should be ongoing rather than time-delimited. ManyOSSprojects don’t have a pre-defined set of
requirements which defines the scope of a project. Instead they are work-in-progress where new ideas and features are added continuously. Furthermore the targeted projects are generic platforms rather than specific instances of a software. Whereas in client projects the
deployment environment is well known and teams can work towards that environment,OSS
projects can’t assume how the environment into which the software is deployed looks like in all cases. ThusOSSprojects need to support as many combinations of hardware, operating system and software. This ensures that the software can be spread among as many user groups as possible.
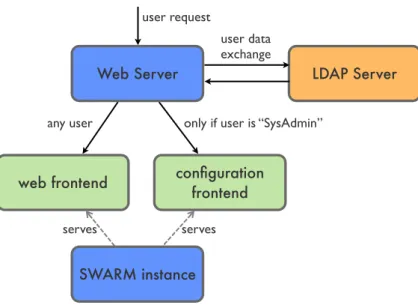
Based on these assumptions Swarm supports only one project per system instance. A administrator needs to setup an instance of Swarm per project which should be monitored. This design decision allows for a simple administration of an instance. Nevertheless The underlying architecture as explained in section 3.3.1 is not completely tied to this concept. If necessary it can be extended to support the monitoring of multiple projects, which would also require the adaptation of other components such as the Operation, Administration and Maintenance (OAM) subsystem presented in section 3.3.6.
SWARM instance
configuration frontend web frontend
Web Server LDAP Server
serves serves
user request
user data exchange
only if user is “SysAdmin” any user
Figure 3.1: A web server providing authentication through an LDAP service.
3.2.2
Deferred Authentication
Swarm is a continuous build system which acts autonomously after a administrator has setup the project correctly. Thus it doesn’t require a complex user management or flexible
authentication support because only few changes need to be made thereafter. To keep the system simple and focused on its core functionality it won’t attempt to provide any sort of authentication. Instead other means of security should be used to provide the right users access to the configuration frontend as well as giving all users access to the main web frontend. In this respect Swarm defers the authentication support to external systems which provide a mature and flexible security model already.
This limitation, which is considered to be a feature, will also allow Swarm to be deployed in internal networks with custom security measures already in place. Since Swarm doesn’t enforce any security model the employed security system simply needs to be made aware of a Swarm instance. All data available to the security system can be used as in any other case.
A simple scenario for deferred authentication is the usage of web servers and Lightweight Directory Access Protocol (LDAP) to limit the access of users to certain websites as illustrated in figure 3.1. Since the Swarm configuration frontend is available via a unique Uniform Resource Locator (URL), the web server can be configured to provide only system administrators access to that particularURLand allow all users to view all otherURLsserved by Swarm. This kind of configuration is a routine operation and often used to secure certainURLs.
3.2.3
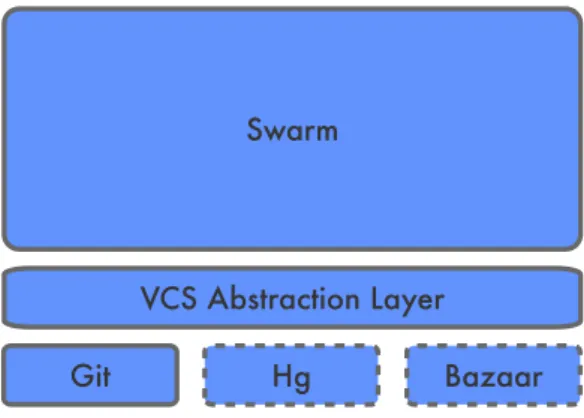
Git SCM Support
As described in section 2.2.3 variousOSSDistributed Version Control Systems are available and often provide the same core set of functionality. To emphasis simplicity Swarm will only
Swarm
VCS Abstraction Layer
Git Hg Bazaar
Figure 3.2: SCM support realized through abstraction layer over specific systems.
support the use of Git for monitored projects. This limitation, once again a feature, allows the system to leverage Git as much as possible.
Although only Git will be supported, the system will abstract from the underlyingSCMas shown in figure 3.2. This abstraction will provide as much extensibility as necessary to be able to support otherSCMsystems in the future.
3.2.4
Summary
The principles presented in this section do limit the system’s capabilities, but also allow the system design to focus on simplicity and core functionality.Deferred authenticationdelegates any authentication to third-party systems, whileGit SCM supportandsingle project supporthelp to focus the design on other areas of interest. Nevertheless these limitations can be ignored in the future if the system is supposed to provide the skipped functionality.
3.3
SYSTEM DESIGN
Thesystem designof Swarm is covered in broad detail in the following sections. Section 3.3.1 introduces the overall architecture which is based upon easily exchangeable components. Further each component is presented individually including its internal design as well as the Application Programming Interface (API) to other components and the prototypical
implementation. Section 3.3.2 covers theplatform managementsubsystem which manages the usage of external servers within Swarm. Subsequently the VCSinterface, which manages any source code repository access, is explained in section 3.3.3. All system data is stored and access to it managed by thedata storagesubsystem detailed in section 3.3.4. Further
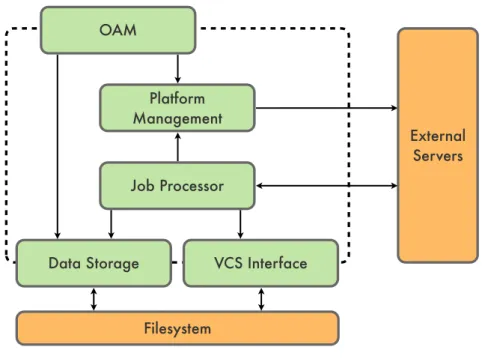
Data Storage VCS Interface Job Processor OAM Platform Management Filesystem External Servers
Figure 3.3: System architecture showing the component communication channels.
section 3.3.5 focuses on thejob processorwhich is the most active component in the system because of continuous management of running tasks. The user front-end and its foundation provided by theOAMsubsystem are described in section 3.3.6 followed by a description of the standard system configuration in section 3.3.7. The system design is finally summarized again in section 3.3.8.
3.3.1
Architecture
The goal of Swarm’s architecture is to use a component-based design to be able to use external components for generic tasks. Furthermore such a design allows the individual parts to be self-contained with few well-defined dependencies which need to be provided by other components. Figure 3.3 depicts the various components as well as external system which Swarm depends on. The arrows indicate directed communication channels. As an example, the
OAMcomponent, which is presented in detail in section 3.3.6, is only calling other components actively, not being called by them at any time. Thus all other component act independently from theOAMcomponent, which could very well be removed from the system if the functionality it provides is not needed anymore. Each component is individually described in the following sections. The few external dependencies of this architecture are the access to the filesystem to store data and source code repositories as well as external servers which can be used to run builds on them. Other than these dependencies Swarm is self-contained which adds to the flexibility of the system.
3.3.2
Subsystem: Platform Management
The need for multi-platform support has been described in detail in section 3.1. Such support is not a novel idea. Other continuous build systems, such as [hudson], allow users to add multiple platforms if the required plugins are installed. This approach works sufficiently but is far
from ideal since the computational model of the core build system is targeted towards the use of a single platform.
The objective of this subsystem is defined initially, followed by important terminology
definitions. Then theAPIfunctions are listed which are provided by this component. Further the component’s design is detailed, with a subsequent description of its implementation. Lastly the component’s role is summarized and concludes this section.
Objective
Theplatform managementsubsystem needs to provide access to multiple platforms for other system components. Furthermore this access should be available through aAPIwhich abstracts from the subsystem’s internal data model. State information about the platforms should be kept internally.
Definition – Platform
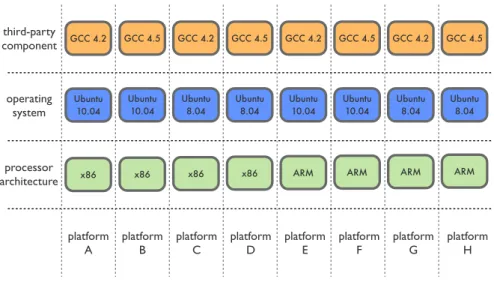
Aplatformis a combination of specific hardware, the operating system and the installed software. Often multi-platform support refers to supporting multiple processor architectures, which is not the case with this extended definition. The processor architecture is as much part of a platform as the respective version of an operating system or user libraries. This definition is required because software projects often rely on third-party components, and even specific versions of these. Figure 3.4 shows how two processor architectures, two versions of the same operating system and two versions of a specific library can be combined to eight platforms.
GCC 4.2 x86 Ubuntu 10.04 Ubuntu 10.04 Ubuntu 8.04 Ubuntu 8.04 Ubuntu 10.04 Ubuntu 10.04 Ubuntu 8.04 Ubuntu 8.04 GCC 4.5 GCC 4.2 GCC 4.5 GCC 4.2 GCC 4.5 GCC 4.2 GCC 4.5
x86 x86 x86 ARM ARM ARM ARM
third-party component operating system processor architecture platform
A platformB platformC platformD platformE platformF platformG platformH
Definition – Platform Provider
Platforms need to be available through some means of communication. A system which hosts platforms is called aplatform provider. Providers are used to get access to a platform via standard communication mechanisms such as Secure Shell (SSH).
The Host Machine The machine on which a continuous build system is running is referred to
as itshost. Most continuous build systems use the host machine to execute builds on it, thus it often closely resembles the expected production environment of the software which is
developed.
Dedicated Servers The simplest form of platform providers arededicated servers. Such
servers provide one particular platform, a combination of hardware and software. Both physical and virtual machines belong to this category, because the means of communication with the servers doesn’t change. Since the setup of dedicated servers is a common administrative task, these platform providers are mostly used by continuous build systems to improve multi-platform support.
Cloud Computing Platforms An abstraction over virtual servers is provided bycloud
computing platforms. Servers can be created and released within minutes, which makes such clouds ideal for rather dynamic computation needs. The platforms which are available on a cloud can be adapted within certain parameters. Often the chosen operating system needs to support certain virtualization functionality while any additional software can be arbitrarily chosen. This platform versatility makes cloud computing platforms very powerful platform providers. Despite these benefits other continuous build systems don’t make use of them yet.
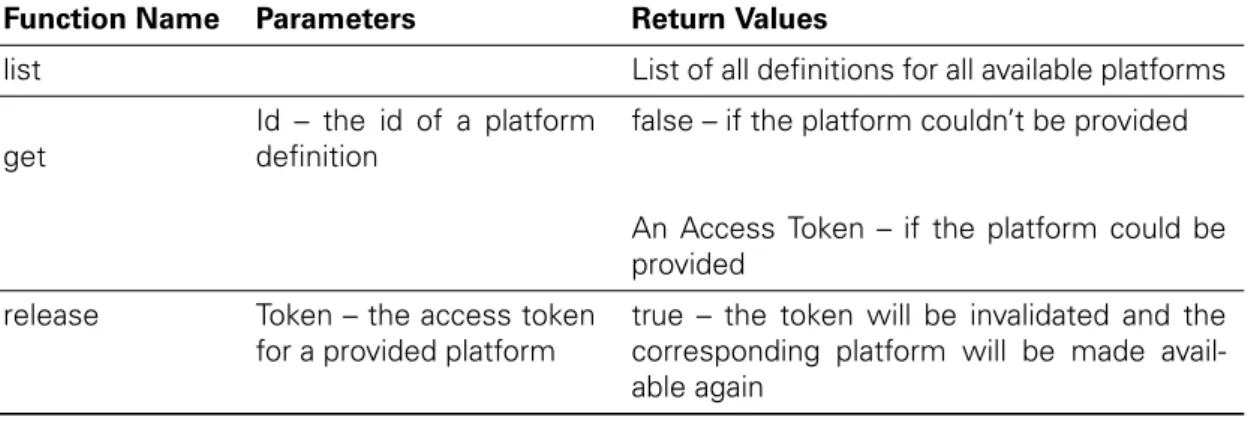
API
Other components should be allowed to get information about available platforms as well as access to such platforms through a simpleAPI. Thus only the few functions listed in table 3.1 need to be exposed externally.
Function Name Parameters Return Values
list List of all definitions for all available platforms
get
Id – the id of a platform definition
false – if the platform couldn’t be provided
An Access Token – if the platform could be provided
release Token – the access token for a provided platform
true – the token will be invalidated and the corresponding platform will be made avail-able again
Table 3.1: API functions of the platform management subsystem.
Design
While theAPIdescribed in section 3.3.2 is very simple, the underlying mechanism to manage the various platforms requires a lot of flexibility to be able to support a range of platform
providers. The design is based on two user contracts. These contracts are discussed next before the resulting component design is presented in detail.
Single User Policy The workflow of the component is based upon a simple yet important
contract.
A platform may only be used by one user at a time.
This policy simplifies the internal workflow since the component only needs to keep track on whether a platform is used or not. Furthermore the user of a platform can be sure that there will be no other users on a provided platform interfering with potentially sensible tasks.
User Reliability Because platforms are blocked if used by a user, it needs to be ensured that
they are released eventually. Therefor two assumptions need to be discussed before settling on a policy.
• Unreliable users
User programs which have blocked platforms can crash, experience data corruption and thus forget about the occupied platforms. In such cases the platform management would need to employ token timeouts to be able to release platforms dedicated to faulty clients. But such timeouts also add complexity to the component’sAPIas well as the clients interaction with the component. It would need to report back to the component periodically to signal that it is still running and using a platform.
• Reliable users
In contrast user programs can be regarded as reliable. It would be assumed that they employ their own measures to ensure that no data loss occurs and in case of failures the used platforms are either released or usage is continued once the program has recovered.
Both presented assumptions add complexity to user programs, either in the form of timeout prevention or failure recovery. But while the assumption that user programs are unreliable requires the platform management to keep track of token timeouts internally, reliable user programs allow for a simpler component design. No additional client communication would be enforced as well as the internal state would be simplified. Based on the discussed assumptions the following policy will shape the platform management’s design further.
User programs are considered to be reliable and must ensure that platforms are released eventually.
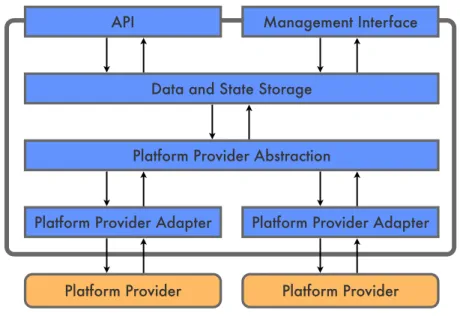
Platform Provider
API Management Interface
Data and State Storage
Platform Provider Abstraction
Platform Provider Adapter Platform Provider Adapter
Platform Provider
Figure 3.5: Architecture of the platform management subsystem.
Component Blocks The platform management component consists of the following set of
building blocks, which make up the component design in combination with the previously presented user contracts.
• API
• Management Interface
• Data and State Storage
• Platform Provider Abstraction
• Platform Provider Adapters
The connections between those building blocks are roughly depicted in figure 3.5.
API TheAPI, as mentioned in section 3.3.2, provides only a small set of functions. It is stateless and very simple. All state information is kept within the data and state storage, while theAPImasks access to this information to the outside.
Management Interface While theAPIprovides functions to access platforms, the
management interface allows user programs to add, update and remove platforms. The interface is stateless and only operates on the information kept in the data and state storage.
Data and State Storage All information which is available to user programs as well as all component state information needs to be stored persistently. In case of system failures or restarts, the platform information should be durable. Information about which platforms are in use needs to be consistent at all times. The data and state storage provides the required criteria for all internal data storage. Access is available for component-internal use only. This allows the overall component to be used as a black-box without outside dependencies.
Platform Provider Abstraction When user programs request access to a platform, the
component will try to provide a platform by using the respective platform provider. Although the set of platform providers is small initially, as discussed in section 3.3.2, it might expand in the future. Thus the platform provider support should be flexible enough to allow easy extension. Therefor the platform provider abstraction is an internal interface to specific platform provider adaptors. Based on the type of platform, the abstraction will call the corresponding adapter which will then perform the required work to enable access to a platform.
Platform Provider Adapters Support for a provider is given though platform provider adapters.
Such an adapter encapsulates the provider-specific knowledge for managing platforms. All specific information is kept inside the adapter which makes the process of adding a new adapter to the component as easy as adding the adapter code to the system. No further configuration or adaptation of other blocks of the component is necessary.
Implementation
Since the platform management doesn’t depend on other components, as dictated by the component design in section 3.3.2, its implementation is relatively simple compared to other system components. Figure 3.6 shows the supervision tree of the component which consists of the main application supervisor and a single worker process. The worker process is started once the component is initiated and handles all communication with the platform management component. Although the communication doesn’t require a dedicated process, this approach has been chosen to simplify access patterns to platforms. In case of multiple request for a single platform, the first user program’s request will be served. Since requests are handled sequentially the following requests will not be provided with access to the requested platform. Thus requests are served in First-In-First-Out (FIFO) order. One can be assured that there will never occur a race condition because of two user programs trying to get the same platform simultaneously.
API and Management Interface Both interfaces are provided by a single interface module.
This module implements the functions presented in the component design in section 3.3.2. All function calls are translated into messages and sent in a synchronous call to the worker process.
Worker Process Exclusive access to the component’s internal data and state is given to the
worker process. Both is kept persistently in two Disk-based Erlang Term Storage (DETS) tables, one for individual platform information and one for any additional platform provider data. The tables are stored on the local filesystem. Except from actions triggered byAPIcalls, the process doesn’t do any further work on the stored data.
PM Worker
PM Supervisor
Figure 3.6: Supervision tree of the platform management subsystem.
Platform Provider Adapters These adapters are implemented as separate modules which
provide the required interface functions. Thus the worker process will only look at a platforms provider type, and call the corresponding adapter’s interface function. Initially two adapters are available, an adapter fordedicated serversand an adapter for theAmazon EC2 Cloud. In order to be able to use the Amazon EC2 cloud adapter, the EC2APIaccess parameters need to be provided to the component, so that it will be able to use theAPI successfully.
Amazon EC2 Support The required support for theAmazon EC2adapter, as well as the
similarEucalyptus Cloudproject, is implemented as a separate interface component. The access logic could’ve been implemented as a module within the platform management component as well. Because other projects can benefit from such a library though, it has been implemented as its own component which can be embedded more easily. The component’sAPI
resembles the officialAmazon EC2 APIso that users will be able to use it easily without the need to study new interface functions.
Summary
Theplatform managementsubsystem provides a simpleAPIto manage platforms. The implementation provides access to individual servers as well asComputing Cloudssuch as
Amazon EC2. This allows user programs to use a vast number of platform combinations which wouldn’t be possible with dedicated servers alone.
3.3.3
Subsystem: VCS Interface
Many Version Control Systems are available and used byOSSprojects. Because continuous build systems need to be able to access source code repositories, support for such access
Version Control System API
Version Control System Abstraction
VCS Adapter
Version Control System
VCS Adapter
Figure 3.7: Architecture of the version control interface subsystem.
needs to be provided by this subsystem. The unifiedAPIof the component is outlined, followed by the subsystem design. The actual implementation is detailed thereafter. Finally the
component’s advantages are summarized to conclude this section.
Objective
TheVCS interface component provides access to various Version Control Systems through a single publicAPI. Further it should ensure that source code repositories are not corrupted by parallel access.
API
A user program should be presented with a unifiedAPIfor the various Version Control Systems which the component supports, the functions of which are defined in table 3.2. Although mostVCSsshare common functions, especiallyCentralized VCSsandDistributed VCSsas discussed in section 2.2, are built upon different paradigms which don’t easily lend themselves to a common set ofAPIfunctions. Thus the component’s publicAPIis a
combination of both, with some functions being not available if they are specific to anotherVCS.
Design
Since the version control interface component is independent from other system
components, its internal architecture is simplistic as well. Figure 3.7 illustrates the component’s design.
API The version control interface is not meant to hold copies of repository state information, since the underlyingVCS takes care of such repository management already. Thus the
component’sAPIis stateless, implying that user programs always need to refer to the source code repository on which certain action should be executed.
VCS Integration All Version Control Systems which are of interest for Swarm, as discussed in
section 2.2, are implemented in other programming languages than Erlang. Thus one can’t simply use them as libraries as done with other components. Instead the command-line front-ends of theseVCSswill be used for communication between Swarm and theVCS. This approach lacks the flexibility of a native interface, but also builds upon the strong foundations of those established systems.
VCS Abstraction Although Swarm will only provide support for theVCSGit initially, its internal
architecture should provide the flexibility to extendVCSsupport without changing the
architecture. Therefor the component abstracts from the actualVCSadapter which is used and calls an abstraction layer instead of accessing adapters directly. Adapters are expected to implement the abstraction’s interface functions which are supported by theVCS.
VCS Adapter Adapters are modules which provide support for particular Version Control
Systems. They are self-contained and modeled after theVCSabstractionAPI. State information about repositories should not be exposed to the outside. Support for a newVCScan be added by adding the respectiveVCSadapter to the version control interface component.
Implementation
Just as the platform management component the version control interface is implemented as a simple single worker process component. The process supervision tree is depicted in
figure 3.8, showing that the component supervisor manages only one worker process at all times. Once started the worker process will act as a queue to ensure thatAPIcalls which address the same repository won’t access it simultaneously. Although the use of a single worker process might slow down operations which address different repositories, these situation won’t occur often within Swarm, since it manages only a single project, which is also associated with a single repository. Thus mostAPIcalls to the version control interface will address the same repository.
API TheAPIis provided by a separate module which transforms all function calls to
synchronous calls to the worker process. The worker will call the respective function of theVCS
abstraction layer. WhichVCSadapter will be used is defined by an application configuration parameter.VCSadapters are modules which implement the abstractionAPIfunctions which are supported by the underlying Version Control System.
Git Adapter As defined in section 3.2 Swarm only supports Git from the beginning. The
respective adapter implements allAPIfunction so that a repository can be fully controlled through the version control interface subsystem.