Video Sequences
Umakanthan Sabanadesan
B.Sc Eng (Hons, 1st Class)
PhD Thesis
Submitted in Fulfilmentof the Requirements
for the Degree of
Doctor of Philosophy
Queensland University of Technology
Speech, Audio, Image and Vision Research Laboratory
Science and Engineering Faculty
Action Recognition, Human Motion Analysis, Video Surveillance, Bag-of-features, SVM Classification, Local Spatio-temporal Features, Sparse-representation, LDA Sparse-representation, Multiple instance dictionary learning.
Human motion analysis is currently receiving increasing attention from computer vision researchers. This interest is motivated by applications over a wide spec-trum of topics. For example, segmenting the parts of the human body in an image, tracking the movement of joints over an image sequence, and recovering the underlying 3D body structure are particularly useful for analysis of athletic performance, as well as medical diagnostics. The capability to automatically monitor human activities using computers in security-sensitive areas such as air-ports, border crossings, and building lobbies is of great interest to the police and military. With the development of digital libraries, the ability to automati-cally interpret video sequences will save tremendous human e↵ort in sorting and retrieving images or video sequences using content-based queries. Other applica-tions include building man-machine user interfaces and video conferencing.
The research trend in the field of action recognition has recently led to more robust techniques, which to some extent are applicable for action recognition in complex scenes. Action recognition in complex scenes is an extremely difficult task due to challenges such as background clutter, camera motion, occlusions and illumination variations. To address these challenges, several methods, like tree-based template matching, tensor canonical correlation, prototype based ac-tion matching, incremental discriminant analysis of canonical correlaac-tion, latent pose estimation and a generalised Hough transform were proposed. Most of these
methods are very complex and require preprocessing, like segmentation, tree data structure building, target tracking, background subtraction or the fitting of a hu-man body model. On the other hand, recently, spatio-temporal features have gained popularity because of their state-of-the-art performance with reduced or even no preprocessing. These methods apply interest point detectors and lo-cal descriptors to characterize and encode the video data, and thereby perform action classification. In this PhD program, local feature based action representa-tion, recognition and classification algorithms are explored due to their superior state-of-the art performance under complex environmental settings with lower preprocessing, compared to other approaches.
Even though local featubased methods have been researched by several re-searchers for more than a decade, these systems still have several limitations and far-from-real time implementations. The performance of local-feature based systems depends on three major areas: (1) Accurate Representation of video sequences as a set of feature vectors (Feature Extraction), (2) Reducing the di-mensionality of the feature points to create compact representation of the video (Feature Representation), (3) Train the classifier to classify new video sequences (Classification). This thesis has investigated the above three major areas of a local feature-based action-recognition pipeline and has proposed several improvements to the overall system accuracy.
In order to address the shortcomings of the action recognition pipeline, first base-line system using the bag of visual words with SVM framework has been imple-mented. Several state-of-the-art spatio-temporal features, such as HOG, HOF and HOG3D features, have been extracted and tested against popular bench-mark datasets. A comprehensive evaluation of state-of-the-art descriptors has been undertaken with a wide range of code book sizes.
represen-tation method, semi-binary features based on BRISK (Binary Robust Invariant Scalable Keypoints) descriptor, has been proposed. Because of the binary nature of this feature it provides compact representation while maximizing the overall classification performance on several benchmark datasets.
In order to provide efficient and compact feature representation, several popular machine learning techniques have been explored and three new representation techniques have been incorporated based on class-specific dictionaries. It has been found that class-specific dictionaries consistently perform well and three new machine learning techniques, such as Multiple instance dictionary learning, Class-specific simplex LDA (css-LDA) and class-specific sparse codes, have been incorporated to the action recognition domain. These representation methods have improved the overall performance of popular local feature descriptors.
Finally, to address the classification phase of the action recognition pipeline, a binary-tree SVM has been proposed. The proposed binary-tree SVM achieves comparable state-of-the-art performance with a significantly reduced computa-tional complexity and can be easily scalable to large datasets.
Though the techniques proposed in this thesis achieve promising results compared to the state-of-the-art, further research e↵ort is required to achieve comparable performance in more challenging environments that are encountered in practice. The limitations of the proposed techniques are discussed, together with possible future extensions.
Abstract i
List of Tables xii
List of Figures xv
Acronyms & Abbreviations xxi
Certification of Thesis xxv
Acknowledgments xxvii
Chapter 1 Introduction 1
1.1 Research Motivation . . . 3
1.2 Research Objective and Scope . . . 6
1.4 Original Contributions . . . 10
1.5 Publications . . . 13
Chapter 2 Literature Review 15 2.1 Introduction . . . 15
2.2 Human model-based methods . . . 16
2.3 Holistic methods . . . 17
2.3.1 Shape mask and silhouette based methods . . . 17
2.3.2 Optical flow and shape-based methods . . . 20
2.4 Local feature methods . . . 23
2.4.1 Feature detectors . . . 24
2.4.2 Feature descriptors . . . 26
2.4.3 Feature Trajectories . . . 28
2.4.4 Voting based action localization . . . 29
2.4.5 Summary . . . 30
2.5 Datasets . . . 31
2.5.1 KTH Actions Dataset . . . 31
2.5.3 Hollywood Actions Dataset . . . 34
2.5.4 UCF sports actions Dataset . . . 36
2.5.5 Youtube Actions Dataset . . . 38
2.6 Chapter summary . . . 39
Chapter 3 Comprehensive Evaluation of Local Feature Descriptors 41 3.1 Human Action Recognition Framework . . . 43
3.1.1 Feature detectors . . . 43
3.1.2 Feature Descriptors . . . 45
3.1.3 Bag of features representation . . . 48
3.1.4 Classification Techniques . . . 48
3.2 Experimental results . . . 50
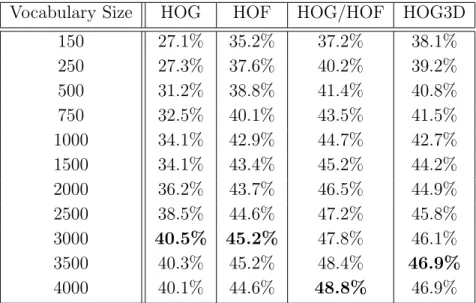
3.2.1 Evaluation of the impact of di↵erent code book sizes . . . 51
3.2.2 Evaluation of feature encoding methods . . . 58
3.2.3 Evaluation of di↵erent kernel methods . . . 63
3.3 Chapter summary . . . 68
Chapter 4 Semi-Binary Based Video Features for Activity
4.1 Introduction . . . 71
4.1.1 The Problem & Motivation . . . 72
4.1.2 Overview of proposed approach . . . 72
4.2 Related work . . . 74
4.3 Proposed method . . . 76
4.3.1 Interest Point Detection . . . 76
4.3.2 Motion Estimation . . . 77
4.3.3 Appearance Modelling . . . 80
4.3.4 Motion Modelling . . . 80
4.4 Experimental Results and Discussion . . . 81
4.4.1 KTH Dataset . . . 81
4.4.2 Hollywood2 . . . 84
4.4.3 Computational complexity . . . 87
4.5 Summary . . . 89
Chapter 5 Multiple Instance Dictionary Learning for Activity Rep-resentation 91 5.1 Introduction . . . 91
5.3 Related work . . . 97
5.4 Proposed method . . . 98
5.4.1 Feature Extraction . . . 98
5.4.2 Multiple Instance Dictionary Learning . . . 99
5.4.3 M3IC Approach . . . 100
5.4.4 MMDL Approach . . . 102
5.4.5 LLC Feature Encoding . . . 103
5.4.6 Spatio-Temporal Pooling . . . 104
5.5 Experiments and Results . . . 105
5.5.1 KTH . . . 106
5.5.2 Hollywood2 . . . 108
5.6 Summary . . . 109
Chapter 6 LDA Based Local Feature Representation 111 6.1 Introduction . . . 111
6.1.1 Motivation & Proposed Approach . . . 112
6.2 LDA variations and Applications . . . 115
6.3.1 Inference and parameter Estimation . . . 120
6.4 Proposed Feature Representation Framework . . . 121
6.4.1 Feature extraction . . . 122
6.4.2 Latent Dirichlet Allocation for videos . . . 122
6.4.3 Supervised LDA (SLDA) and MedLDA Approach . . . 124
6.4.4 css-LDA Approach . . . 126 6.5 Experimental setup . . . 127 6.6 Experimental Results . . . 129 6.6.1 Hollywood2 Dataset . . . 129 6.6.2 UCF50 Dataset . . . 130 6.6.3 KTH Dataset . . . 131 6.7 Chapter summary . . . 132
Chapter 7 Representing activities using class-specific sparse codes135 7.1 Introduction . . . 135
7.2 Dictionary Learning and Sparse Representation . . . 139
7.2.1 Shared dictionary Approach . . . 140
7.2.3 Appearance & Motion specific Dictionary Learning . . . . 142
7.3 Experiments and Results . . . 143
7.3.1 KTH Dataset . . . 145
7.3.2 UCF Sports Dataset . . . 146
7.4 Summary . . . 147
Chapter 8 Binary-Tree SVM for Representing Activities 149 8.1 Introduction . . . 149
8.2 Video representation . . . 151
8.2.1 Feature extraction . . . 152
8.2.2 Feature encoding . . . 152
8.3 Binary Tree Construction with GMM . . . 153
8.3.1 SVM classification . . . 154
8.4 Experimental results . . . 155
8.5 Conclusion . . . 157
Chapter 9 Conclusions and Future Directions 159 9.1 Introduction . . . 159
9.3 Future work . . . 163
3.1 Average Accuracy for di↵erent descriptor/codebook combination onKTH Dataset . . . 54
3.2 Average Accuracy for di↵erent descriptor/codebook combination onWeizmann Dataset . . . 55
3.3 Average Precision(AP) per action class for the Hollywood2
dataset compared against the baseline [97] . . . 56
3.4 Mean Average Precision(mAP) for di↵erent descriptor/codebook combination onHollywood2 Dataset . . . 56
4.1 Comparison of recognition accuracy on the KTH Dataset using di↵erent approaches. Approaches used in [69], [94], [48] are not fallen into spatio-temporal descriptors. . . 82
4.2 Comparison of recognition accuracy on theHollywood2 Dataset using di↵erent approaches. Approaches used in [94], [48] are not fallen into spatio-temporal descriptors. . . 85
4.3 Performance comparison between the popular HOG+HOF and BRISK+MBH descriptor with the Harris3D and the BRISK key-points. Average accuracy is reported on the KTH dataset and mean average precision is reported on the Hollywood2 Dataset. . 86
4.4 Time spent on di↵erent stages of our proposed feature detection and description method against the STIP method. Processing time is calculated on randomly selected 100 samples from each datasets without parallel processing. . . 88
4.5 Algorithmic complexity of our proposed method against the STIP method during feature detection and description. Spatial size of the cuboid is assumed to ben⇥n and temporal size is k. . . 88 4.6 Computational complexity comparison of STIP and BRISK+MBH
descriptor on Hollywood2. . . 89
5.1 Comparison of recognition accuracy on the KTH Dataset using di↵erent approaches. Di↵erent feature descriptors were used in [118] and [69]. . . 106
5.2 Comparison of mean Average Precision (mAP) on the Holly-wood2 Dataset using di↵erent approaches. Di↵erent feature de-scriptors were used in [94], [48] . . . 107
6.1 Mean Average Precision (mAP) on theHollywood2 Dataset us-ing the four di↵erent experimental setups . . . 130
6.2 Average Accuracy on theUCF50Dataset using the four di↵erent experimental setups . . . 130
6.3 Average Accuracy on the KTH Dataset using the four di↵erent experimental setups . . . 131
7.1 Average Accuracy on the KTH Dataset using the four di↵erent experimental setups . . . 145
7.2 Average Accuracy on the UCF-Sports Dataset using the four di↵erent experimental setups . . . 146
8.1 The clustering results for constructing the Binary Tree (see Figure 8.1). The error represents the percentage of misclassified feature vectors in each node. The root node consists of all activities, the
L11node consists of{Driving car, fighting, getting out of car,
kiss-ing, running}, L12 consists of {Answer the phone, eating, hand
shake, hugging, sitting down, sitting up, standing up} and so on. . 155 8.2 Average Precision(AP) per action class for the Hollywood2
1.1 The Spatio-temporal Action recognition framework. . . 7
2.1 motion history images (MHI) and motion energy images (MEI) [12]. This can be viewed as a weighted projection of a 3-D XYT volume into 2-D XY Dimension . . . 18
2.2 Space-time volumes for action recognition based on silhouette in-formation [9] . . . 18
2.3 Motion Context descriptor for the actions hand waving and jog-ging: motion images are computed over groups of images; the Mo-tion Context descriptor is computed over consistent regions of mo-tion [115] . . . 20
2.4 Motion descriptor using optical flow: (a) Original image, (b) Op-tical flow, (c)Separating the x and y components of opOp-tical flow vectors, (d) Half-wave rectification and smoothing of each compo-nent [21] . . . 21
2.5 Spatio-temporal interest points from the motion of the legs of a walking person; (left) 3D plot of a leg pattern and the detected lo-cal interest points; (right) interest points overlaid on single frames
in the original sequence [43] . . . 25
2.6 Feature trajectories by detecting and tracking spatial interest points. Trajectories are quantized to a library of trajections which are used for action classification [61] . . . 28
2.7 Sample Frames from the KTHHuman actions dataset [86]. Box-ing (first column), handclappBox-ing (second column), handwavBox-ing (third column), jogging (fourth column), running (fifth column), walking (sixth column) . . . 32
2.8 Sample frames from the Weizmann actions dataset [9] . . . 33
2.9 Sample frames from the Hollywood2 action dataset [60] . . . 35
2.10 Sample frames from UCF sports action datasets [81] . . . 37
2.11 Sample frames from the YouTube action dataset [51] . . . 38
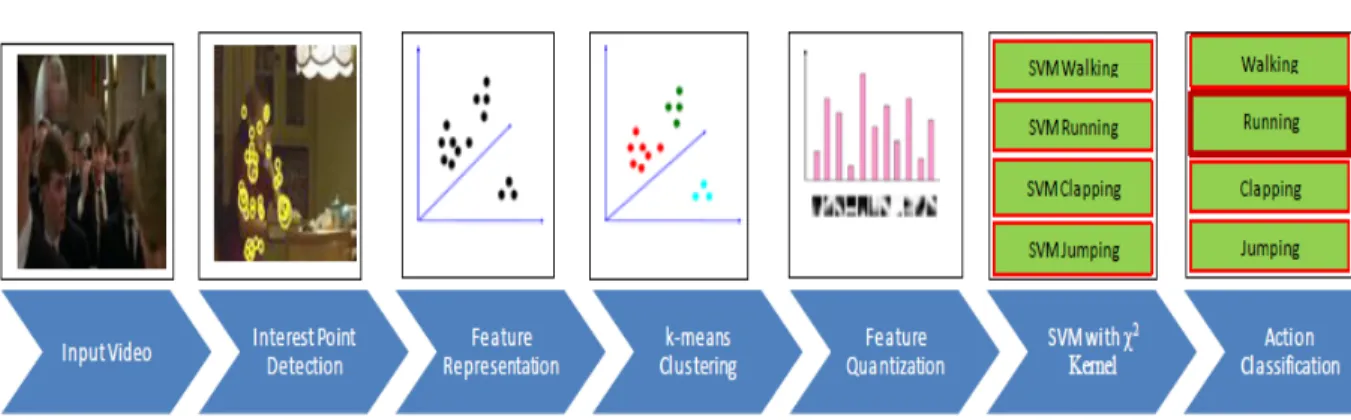
3.1 Flowchart of the Bag-of-feature based algorithm. . . 42
3.2 Spatio-Temporal Feature Descriptor . . . 46
3.3 Max-margin hyperplane derived from the training of two class SVM [88] . . . 49
3.4 Precision-Recall plots for di↵erent HOG/HOF codebook sizes on the Hollywood2 actions dataset . . . 57
3.5 Average classification accuracy of di↵erent encoding methods ap-plied on KTH and Weizmann Datasets with HOG/HOF descriptor.
(b) KTH Dataset,(b) Weizmann Dataset. . . 62
3.6 Mean Average Precision (mAP) obtained on Hollywood2 dataset with HOG/HOF descriptor and di↵erent encoding methods. . . . 63
3.7 Demonstration of a kernel mapping from a input to an non-linear feature space [99]. . . 64
3.8 Classification Accuracy of di↵erent kernels for di↵erent descriptors
with KTH Dataset (a) HOG Descriptor, (b) HOF Descriptor, (c)
HOG/HOF Descriptor and (d) HOG3D Descriptor. . . 66
3.9 Classification Accuracy of di↵erent kernels for di↵erent descriptors
with Weizmann Dataset(a)HOG Descriptor,(b)HOF Descriptor,
(c) HOG/HOF Descriptor and (d) HOG3D Descriptor. . . 67
3.10 Classification Accuracy of di↵erent kernels for di↵erent descriptors
with Hollywood2 Dataset (a) HOG Descriptor, (b) HOF
Descrip-tor,(c) HOG/HOF Descriptor and (d) HOG3D Descriptor. . . . 68
4.1 Proposed Framework for local feature extraction, which consists of key point detection, motion estimation followed by appearance and motion description. . . 73
4.2 Brisk Interest point detector [49]; a keypoint is detected by ana-lyzing the saliency scores inci and the layers above and below. . . 77
4.3 Key points detected by BRISK detector on sample frames from
KTH dataset are shown in the first row. The second row shows the candidate key points for description and the last row shows the eliminated points due to insignificant motion. Sample actions are Hand clapping (first column), Boxing (second column), Waiving (third column) . . . 78
4.4 Sample Frames from Hollywood2 human actions dataset are shown in the first row, key points detected by BRISK are shown in the second row. The third row shows the candidate key points for description and the final row shows the eliminated points due to insignificant motion. Sample actions are Eat (first column), Run (second column), Kiss (third column), Getoutcar(fourth column) and Answerphone (fifth column) . . . 79
4.5 The comparison between the classification performance and di↵ er-ent temporal window sizes (W) in KTH and Hollywood2 Datasets. 82
4.6 The recognition accuracy of three descriptors BRISK, MBH, BRISK+MBH with BRISK key point detector in KTH dataset. . 83
4.7 The confusion matrix of the KTH dataset with BRISK detector and BRISK+MBH descriptor, the temporal window size is set to
W = 5. . . 84
4.8 Recognition accuracy for di↵erent classes on the KTH dataset: Figure (left) shows the performance with three di↵erent descrip-tors BRISK, MBH and BRISK+MBH, Figure (right) shows the performance of the BRISK detector with BRISK+MBH descriptor against Harris3D detector with HOG+HOF descriptor . . . 85
4.9 The confusion matrix of the Hollywood2 dataset with BRISK de-tector and BRISK+MBH descriptor, the temporal window size is set toW = 7. . . 86
5.1 Schematic diagram of the popular bag-of-feature representation (Left) and our proposed feature representation (Right) in the con-text of activity recognition. . . 95
5.2 Illustration of mi-SVM to separate the instances in positive bags. A video (bag) is represented as a collection of features (instances), the bag is labelled positive if at least one of the instances (red) in the bag is positive and the bag is regarded negative if all instances (blue) are negative. mi-SVM aims to find the positive instances in the positive bags by maximizing the margin between positive and negative instances (the black ellipse denotes instances identified as positive by mi-SVM). Then, k-means is used to cluster the positive instances. . . 96
5.3 Average classification accuracy of di↵erent feature representation methods applied on KTH Datasets with Dense HOG/HOF de-scriptor. . . 107
5.4 Performance comparison of several Multiple instance learning (MIL) techniques against the k-means clustering approach with varying codebook sizes in Hollywood2 dataset. . . 108
6.1 (Left) Graphical representation of LDA. (Right) Graphical model representation of the variational distribution used to approximate the posterior in LDA. [11] . . . 117
6.2 Graphical model representation and plate representation . . . 118
6.3 Graphical representation of LDA Models. (a) unsupervised LDA Model (b) MedLDA Model (c) css-LDA Model . . . 123
6.4 Figure (left) shows the mean Average Precision (mAP) of Hol-lywood2 under 4 di↵erent experimental settings with varying number of topics, Figure (right) shows the average accuracy of
UCF50 dataset with di↵erent number of topics under 4 di↵erent experimental settings . . . 128
7.1 Confusion matrices for theKTHdataset with di↵erent sparse rep-resentations. (a) Class-specific sparse dictionary and (b) Appear-ance & Motion specific sparse dictionary. . . 145
7.2 Confusion matrices for theUCFdataset with di↵erent sparse rep-resentations. (a) using Class-specific sparse dictionary and (b) Appearance & Motion specific sparse dictionary. . . 146
8.1 Binary tree structure for support vector machine classification in the Hollywood2 dataset. . . 153
Average Precision AP
Bag Of Features BoF
Bag-of-Visual-Words BOVW
Binary Robust Invariant Scalable Keypoints BRISK Binary Robust Independent Elementary Features BRIEF
Class Specific Simplex LDA CSS-LDA
Expectation Maximization EM
Extended SURF ESURF
Features from Accelerated Segment Test FAST
Fisher Discriminant Analysis FDA
Fast Retina Keypoint FREAK
Gaussian Mixture Models GMM
Hidden Markov Models HMM
Histograms of Optical Flow HOF
Histograms of Oriented Gradients HOG
K-Nearest Neighbour KNN
Latent Dirichlet Allocation LDA
Locality Constrained Linear Coding LLC
Markov Chain Monte Carlo MCMC
Max Margin Dictionary Learning MMDL
Max Margin Multiple Instance Clustering M3IC
Max-margin Multiple instance clustering M3IC
Max-margin Multiple Instance Dictionary Learning MMDL Maximum Entropy Discrimination LDA MEDLDA
Mean Average Precision mAP
Motion Boundary Histogram MBH
Motion Energy Images MEI
Motion History Images MHI
Multiple Instance Clustering MIC
Multiple Instance Learning MIL
Multiple Instance Learning MIL
Multiple instance learning MIL
Multiple Instance SVM mi-SVM
Multiple Instance Multi Label Learning MIML
Oriented fast and Rotated BRIEF ORB Principal component analysis PCA Probabilistic Latent Semantic Analysis PLSA Probabilistic Latent Semantic Indexing PLSI
Radial Basis Function RBF
Scale Invariant Feature Transformation SIFT Single Instance Multi Label SIML Single Instance Single Label SISL Single Instance Single Label Learning SISL
Sparse Coding SC
Sparse coding Spatial Pyramid Matching ScSPM Sparse Representation-based Classification SRC
Spatial Pyramid Matching SPM
Spatio Temporal Interest Points STIP Supervised Latent Dirichlet Allocation LDA
Supervised LDA sLDA
Support Vector Machine SVM
I would firstly like to thank my principal supervisor, Professor Clinton Fookes, for his consistent research guidelines, discussions and support throughout this program. I would also like to express my deep gratitude to my associate supervi-sor, Professor Sridha Sridharan, for assisting me throughout the PhD application process, giving me the PhD opportunity, financial support for the past several years and guidance throughout this program.
I also extend my gratitude to associate supervisor, Dr Simon Denman. Dr Simon has provided a lot of suggestions, discussions, guidelines and technical support. He also made a lot of contributions to improving the conference papers and thesis contents, as well as setting the HPC and software development platform. This PhD program is partly supported by CSIRO and I want to extent my gratitude to Dr Tim Wark, for his supervision, guidance and support.
I would also like to thank everyone in the Speech, Audio, Image and Video Tech-nology (SAIVT) laboratory for their friendship and assistance. I would also like to acknowledge the assistance given by QUT administrative sta↵ in the progress of my thesis. Professional Editor, Ms Diane Kolomeitz (Editorial Services), pro-vided copy editing and proofreading services, according to the guidelines laid out in the University-endorsed national policy guidelines, for the editing of research theses.
Finally, I would also like to thank my family for their support throughout my PhD journey.
Umakanthan Sabanadesan
Queensland University of Technology 2016
Introduction
Human activity recognition is an important area of computer vision research to-day. The goal of human activity recognition is to automatically analyse ongoing activities from an unknown video (i.e. a sequence of image frames). In a simple case where a video is segmented to contain only one execution of a human activ-ity, the objective of the system is to correctly classify the video into its activity category. In a more general case, the continuous recognition of human activi-ties must be performed by detecting starting and ending times of all occurring activities from an input video.
The ability to recognise complex human activities from videos enables the con-struction of several important applications. Automated surveillance systems in public places like airports and subway stations require detection of abnormal and suspicious activities, as opposed to normal activities. For instance, an airport surveillance system must be able to automatically recognize suspicious activi-ties like “a person leaving a bag” or “a person placing his/her bag in a trash bin”. Recognition of human activities also enables the real-time monitoring of patients, children, and elderly persons. The construction of gesture-based human
computer interfaces and vision-based intelligent environments becomes possible with an activity recognition system as well.
There are various types of human activities. Depending on their complexity, they can be conceptually categorized into four di↵erent levels: gestures, actions, interactions, and group activities [3]. Gestures are elementary movements of a persons body part, and are the atomic components describing the meaningful motion of a person. “Stretching an arm” and “raising a leg” are good examples of gestures. Actions are single-person activities that may be composed of multiple gestures organized temporally, such as “walking”, “waving”, and “punching”. Interactions are human activities that involve two or more persons and/or objects. For example, “two persons fighting” is an interaction between two humans and “a person stealing a suitcase from another” is a human-object interaction involving two humans and one object. Finally, group activities are the activities performed by conceptual groups composed of multiple persons and/or objects: “A group of persons marching,” “a group having a meeting,” and “two groups fighting” are typical examples. In this research, the main focus is given to improve the recognition accuracy of single human activities from real-time video sequences.
Nowadays, more and more people record their daily activities using digital cam-eras, and this brings the enrichment of video content on the internet, and also causes the problems of categorizing the existing video, and classifying new videos according to the action classes present. Categorizing these videos is a time-consuming task if it is done manually, and recognizing certain actions from scenes of interest in real movies is impossible to accomplish through manual e↵ort. For these reasons, the area of human action recognition has attracted considerable attention. Existing approaches aimed at solving this problem have focused on a pattern recognition system, which is trained using feature descriptors extracted from the training videos, and enables the computer to identify the actions in
new videos automatically. The objective of this thesis is to present several novel approaches in feature extraction, representation and classification to improve the popular, widely used, local feature-based action-recognition system (Bag-of-visual words with SVM Framework).
1.1
Research Motivation
The development of computer vision has encouraged the occurrence of di↵erent novel recognition methods in both 2D images and 3D video sequences. Although it is still challenging to recognize a specific object from a dataset of images due to viewpoint change, illumination, partial occlusions, and intra-class di↵erence and so forth, many successful methods have been proposed. But for the video recognition problem, the current methods still need improvement, especially for realistic movies which have wide variations in people’s posture and clothes, dy-namic background, and partial occlusions. Intuitively, a straightforward way is comparing an unknown video with the training samples by computing correla-tion between the whole videos. This approach makes good use of geometrical consistency, but it is not feasible when dealing with camera motions, zooming, intra-class di↵erences and non-stationary backgrounds.
In fact, action recognition has become one of the hottest research areas in com-puter vision and impressive progress has been made in this direction. However, progress is primarily limited to a controlled experimental environment, which may lead to difficulties when we move to recognising and analysing actions in more realistic scenarios. To understand the possible difficulties, let us first examine some assumptions which have been made in traditional action recognition (i.e. controlled environment):
1. Preprocessing Assumption: For a computer vision problem, choosing appropriate visual features and representation is the first step to solving the problem. In most cases, the feature extraction requires some preprocessing steps. In action recognition, this preprocessing step can be the detection and tracking of body parts or a moving person, or the segmentation of the region of interest. However, if these preprocessing steps fail, the methods based on them will breakdown.
2. Data Assumption: Most action recognition systems are based on sta-tistical machine learning methods, which learn a classifier from a set of training data. In the usual case, sufficient labelled training data is assumed to be available. However, when the labelled training data is insufficient or unavailable or the data can only be obtained from more complex settings, say, from an ambiguously annotated dataset, the system structure of the training process will need to be changed accordingly.
3. Model Assumption: To mathematically model an action, we often make the assumption that an action can be viewed as an equivalent simplified vision/machine learning problem. For example, if an action is represented by a set of silhouettes, an underlying assumption is that an action can be characterized by the temporal evolution of 2D shapes. If we model an action by a bag of local features, we assume that an action can be characterized by the orderless local spatial temporal patterns. Of course, the assumption does not always hold in many applications.
In practical action recognition problems, one or more aforementioned assumptions will not hold. Let us consider the following examples: when we try to classify action in the presence of a dynamic background, the foreground segmentation or reliable bounding box detection and tracking is often not available; when we try to retrieve an action in video, to detect an unusual action, or to discover action
categories from a set of videos, the assumption that sufficient labelled training data is available does not hold. Most daily actions are more complex than simple body movements e.g. boxing, hand waving. The interaction between object, environment and many other cues is often as important as the motion patterns. So the common assumption that action is equivalent to body movement is not enough for modelling more complex actions.
To conquer these deficiencies, a lot of researchers focus on part-based approaches for which only the ‘interesting’ parts of the video are analyzed, rather than the whole video. These ‘parts’ can be trajectories or flow vectors of corners, profiles generated from silhouettes and spatial temporal interest points. Although part based approaches are promising they are still su↵ered due to background clutter and motion which prevents from accurate detection and tracking of interesting parts. Meanwhile recently proposed local feature based approaches extract inter-esting points based on the motion information present in the videos, which makes them more robust to background motion, clutter, viewpoint changes compared to other approaches. Moreover, this research is particularly interested in the case when an action is represented by a set of local spatial-temporal features due to following reasons:
1. As will be seen in the literature review, this representation is more robust to pose and view variance.
2. This representation can impose a relaxed requirement on the bounding box detection and tracking (and can even work without it).
3. It is more flexible to model the local interactions between multiple features by using a local spatial-temporal feature-based representation.
still the recognition rate is constrained due to the inefficient and unreliable de-scription and classification methods. The aim of this PhD research program is to address three major shortfalls such as lack of spatio-temporal relationship, scalability and computational complexity by proposing several novel and e↵ ec-tive description and classification methods. The contributions made in this thesis will make the application of local feature based methods to be more scalable and computationally e↵ective.
1.2
Research Objective and Scope
This thesis considers recognizing simple human activities from video sequences recorded under di↵erent environmental conditions varying from a fixed, clean background to complex, cluttered and moving backgrounds. A wide range of human activities have been investigated in this research from single person ac-tivities such as running, walking, jogging etc. to complex activities such as fight with person, get out of car, hugging etc.
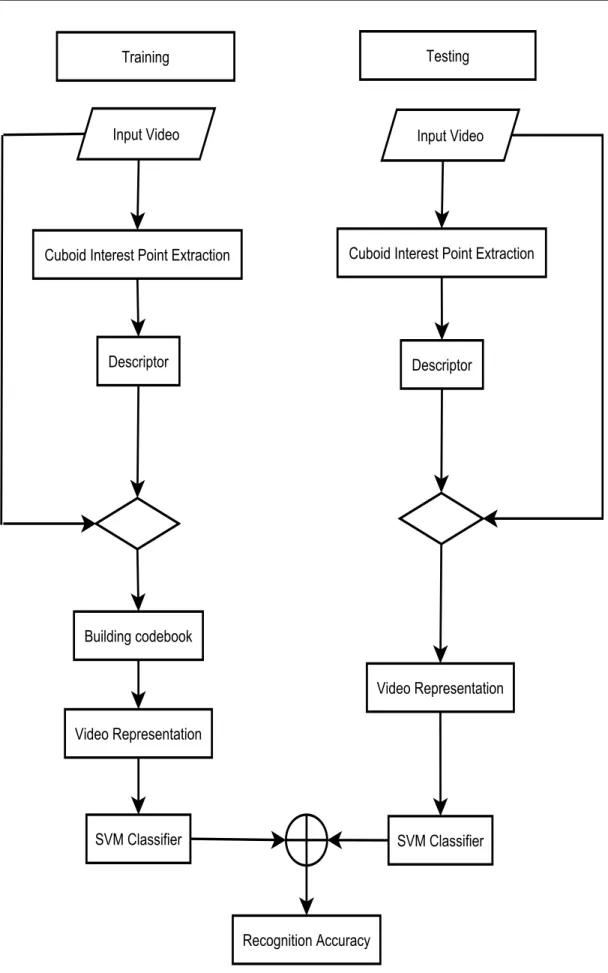
A number of methods have been proposed over the past 30 years in action recog-nition research. Earlier approaches were focused on the appearance, and heavily related to the entire silhouette extraction and modelling the action as a sequence of changes over time using Hidden Markov Models (HMM). More recent research has focused primarily on model-free approaches such as bag-of-words. The de-tails of these methods are described in Chapter 2. A local spatio-temporal based action recognition system typically consists of the fundamental tasks as shown in Figure 1.1.
In this thesis, due to its simplicity and superior performance, a local feature based action recognition system is incorporated as a baseline and several novel feature
Figure 1.1: The Spatio-temporal Action recognition framework.
extraction, representation and classification techniques have been proposed to improve the overall performance. The proposed approaches are primarily evalu-ated with datasets specifically designed for human action recognition. In order to provide a fair comparison, the proposed methods have been investigated with popular features and datasets, in order to enable the easy benchmarking of the proposed techniques with past and future developments. Even though these tech-niques have been developed primarily for human action recognition, they are not limited to this domain and can be extended to other video- based computer vision applications as well. This thesis has used several challenging, publicly available datasets designed for human action recognition, which are still very challenging in the field and highlight the ample ongoing room for improvement.
1.3
Thesis structure
The remaining chapters of the thesis are organized as follows:
• Chapter 2provides an overall review of the literature. In this chapter, 30 years of evolution of human action recognition is briefly presented. This section provides an introduction to di↵erent approaches, di↵erent features
extraction, representation and classification techniques used by researchers over the last three decades. In addition, a comprehensive review of popu-lar, challenging datasets and their evaluation metrics is also presented. A detailed review of a popular, local feature-based action recognition system is also presented, which is the main focus of this thesis and justification for the selection also presented.
• Chapter 3 presents a detailed overview of Bag-of-feature based action recognition systems and their development over time with a comprehen-sive evaluation of how di↵erent stages in the pipeline a↵ect performance. Popular local feature detectors and descriptors are presented with di↵erent classification schemes. In addition, parameters are optimized for di↵erent datasets in such a way as to improve the performance significantly with the existing features. This chapter will provide guidance to researchers to make decisions regarding di↵erent encoding approaches, codebook sizes, kernel matrices and spatio-temporal pyramids.
• Chapter 4 introduces a new binary detector/descriptor, BRISK, to effi -ciently represent the video. In this chapter, the binary BRISK detector is extended into video domain to detect interest points followed by a new algorithm to select potential spatio-temporal points based on their signif-icance. Then BRISK + MBH (Motion Boundary Histogram) descriptor is used to encode the detected key points. This proposed feature detec-tor and descripdetec-tor combination is not only efficient but also demonstrates comparative performance in benchmark datasets.
• Chapter 5 presents another spatio-temporal feature representation based on Multiple Instance Learning (MIL) techniques. MIL has gained pop-ularity amongst machine learning researchers and in this chapter several MIL techniques such as ‘miSVM + kmeans’, Max-margin Multiple instance Dictionary learning (MMDL) and Max-margin Multiple instance
cluster-ing (M3IC) are introduced to create e↵ective feature representation.
Ex-perimental results are presented to demonstrate the e↵ectiveness of this representation.
• Chapter 6 presents a new feature representation technique based on Su-pervised Latent Dirichlet Allocation (LDA) techniques such as S-LDA and MedLDA. Also this chapter presents another efficient LDA technique, css-LDA, where topics are discovered class-by-class basic rather than a single topic simplex for the entire dataset. It is shown from the experiments that this representation is far more efficient than original unsupervised LDA and Bag-of-feature representation. A detailed evaluation is also presented with di↵erent LDA approaches in this chapter.
• Chapter 7 investigates several sparse representation techniques and pro-poses a novel appearance and motion specific dictionary to encode features as a sparse coefficient vector. This separate motion and appearance dictio-nary significantly improves the performance compared to a single sparse-dictionary build for the entire dataset.
• Chapter 8addresses the classification problem by proposing a binary tree SVM to address the shortcomings of multi-class SVMs in activity recogni-tion. This chapter also presents a new method of constructing a binary tree using Gaussian Mixture Models (GMM), where activities are repeatedly allocated to sub-nodes until every newly created node contains only one activity. Then, for each internal node a separate SVM is learned to classify activities. This approach reduces the training time and increases the speed of testing compared to popular the ’one-against-the-rest’ multi-class SVM classifier.
• Chapter 9 summarizes and concludes the thesis, highlights the achieve-ments, addresses the limitations, and points to future research directions.
1.4
Original Contributions
This thesis has contributed several advances to the field of local feature-based activity recognition, by addressing several challenges. The popular, state-of-the art local feature based activity recognition system was built and the following novel techniques have been proposed to improve the overall performance of the system. The framework of the Bag-of-feature based SVM classification system is detailed in Chapter 3.
1. A comprehensive evaluation on several popular local feature detectors and descriptors is carried out with three challenging datasets. In this eval-uation, several encoding techniques, codebook sizes and di↵erent kernel learning techniques have been investigated and optimized techniques have been proposed. This provides a guide for researchers to choose appropriate techniques based on the complexity of the dataset.
2. A novel semi-supervised binary feature is introduced to efficiently represent videos for the purpose of activity classification. In this proposed framework, first, the BRISK feature detector is applied on a frame-by-frame basis to detect interest points, then the detected key points are compared against consecutive frames for significant motion. Amongst the detected points, only the points with significant motion are retained. Then the retained key points are encoded with the BRISK descriptor in the spatial domain and Motion Boundary Histogram in the temporal domain. This descriptor is not only lightweight but also has lower memory requirements because of the binary nature of the BRISK descriptor, allowing the possibility of applications using hand-held devices or for other resource-constrained and real-time applications.
in a local feature-based action recognition system to efficiently represent videos. MedLDA extends LDA to learn discriminative topics by employing a max-margin technique within the probabilistic framework. On the other hand, css-LDA introduces the supervision at the feature level and enables class specific topic simplexes and class-specific topic distributions to capture much richer intra-class information, which provides more discrimination to the representation compared to a single set of topics for the entire data set.
4. A novel feature representation technique based on Multiple Instance Learn-ing (MIL) is proposed for the local feature-based action recognition frame-work. In this proposed approach, the k-means clustering is replaced with three MIL based feature representation techniques such as ‘mi-SVM + k-means’, M3IC and MMDL. The proposed three representations provide
highly discriminative feature representation compared to bag-of-features and significantly improve the classification accuracy. Unlike the k-means approach where k-means is applied in the entire feature set, in ‘mi-SVM + k-means’ approach the k-means is applied only on the positive features identified by SVM. In addition, dictionaries are built on a class-by-class basis in ‘mi-SVM + k-means’ and MMDL approaches as opposed to a sin-gle shared dictionary across the dataset. In the M3IC approach, the MIL
technique is used during code-book generation.
5. A new sparse representation based on class-specific appearance and motion over-complete dictionary is proposed to encode video features for discrim-inative classification. In this approach, separate dictionaries are built for appearance and motion vectors and then a block-structured dictionary is constructed to encode features as a sparse linear combination of a block-structured dictionary. This approach is shown to be e↵ective, compared to shared and class-specific dictionaries. In addition, separate appearance and motion dictionaries explore di↵erent statistical characteristics captured by
appearance and motion features. It is also shown that as we go further into detail designing the sparse dictionary, the discriminative ability increases.
6. A Binary-Tree SVM is proposed to boost the speed of the classification stage in the local feature-based action recognition pipeline mentioned earlier. In this approach, training samples are assigned to the root node of the tree and a GMM is used to separate the training samples into two clusters, and the activities belonging to each cluster are assigned to the left and right sub-nodes respectively. In the training phase, it requires onlyN 1 SVMs to be trained for an N class problem; the amount of time required for training also reduces as the tree is traversed downwards as the number of classes (and amount of data) at each node is reduced. When performing classification, the proposed approach requires only log2N SVMs to predict
1.5
Publications
Listed below are the peer-reviewed publications resulted from this research pro-gramme.
Peer-reviewed international conferences
1. Umakanthan Sabanadesan, Denman Simon, Fookes Clinton B., & Srid-haran Sridha. Class specific sparse codes for representing activities
In Proceedings of the 2015 International Conference on Image Processing (ICIP), IEEE, Quebec, Canada.
2. Umakanthan Sabanadesan, Denman Simon, Fookes Clinton B., & Srid-haran SridhaSupervised Latent Dirichlet Allocation models for Ef-ficient Activity Representation. In Proceedings of the 2014 Interna-tional Conference on Digital Image Computing: Techniques and Applica-tions (DICTA), IEEE, Wollongong, Australia.
3. Umakanthan Sabanadesan, Denman Simon, Fookes Clinton B., & Srid-haran SridhaMultiple instance dictionary learning for activity rep-resentation. In Nilsson, Mikael (Ed.) Proceedings of the 22nd Interna-tional Conference on Pattern Recognition (ICPR 2014), IEEE, Stockholm, Sweden.
4. Umakanthan Sabanadesan, Denman Simon, Fookes Clinton B., & Srid-haran Sridha Activity recognition using binary tree SVM. In Pro-ceedings of the 2014 IEEE Workshop on Statistical Signal Processing (SSP), IEEE, Gold Coast, Australia, pp. 248-251.
5. Umakanthan Sabanadesan, Denman Simon, Fookes Clinton B., & Srid-haran Sridha Semi-binary based video features for activity
repre-sentation. In Proceedings of the 2013 International Conference on Digital Image Computing: Techniques and Applications (DICTA), IEEE, Wrest Point, Hobart, TAS, pp. 178-184.
6. Umakanthan Sabanadesan, Denman Simon, Sridharan Sridha, Fookes Clinton B., & Wark Tim Spatio temporal feature evaluation for ac-tion recogniac-tion. In Proceedings of The 2012 International Conference on Digital Image Computing Techniques and Applications (DICTA 12), IEEE, Fremantle, Western Australia, pp. 1-8.
Literature Review
2.1
Introduction
This section reviews the state-of-the-art methods for action recognition in real-istic, uncontrolled video data. To this end, we structure the existing works into three categories:
• Human model-based methods (Section 2.2) employ a full 3D (or 2D) model of human body parts, and action recognition is done using informa-tion on body part posiinforma-tioning as well as movements.
• Holistic methods (Section 2.3) use knowledge about the localization of humans in video and consequently learn an action model that captures characteristic, global body movements without any notion of body parts.
• Local feature methods (Section 2.4.1) are entirely based on descriptors of local regions in a video; no prior knowledge about human positioning nor any of its limbs/body parts is given.
Surveys on generic action and activity recognition, as well as motion analysis and body tracking, include Aggarwal et al. [3], Weinland et al. [101], Poppe et al.
[74], Moeslundet al. [68], Moeslund and Granum [67], Gavrila [27] and Aggarwal and Cai [2]. Furthermore, Hu et al. [35] present a survey for video surveillance, and Turaga et al. [90] review the state-of-the-art for high level activity analysis. Most relevant in our context are the surveys by Aggarwal et al. [3], Weinland
et al. [101] and Poppe et al. [74], which focus on the recognition of actions
and action primitives, which are closely related to this research in human action recognition.
2.2
Human model-based methods
Human model-based methods recognize actions by employing information such as body part positions and movements. A significant amount of research is devoted to action recognition using trajectories of joint positions, body parts, or landmark points on the human body, with or without a prior model of human kinematics, e.g., [Ali et al. [5], Parameswaran and Chellappa [71], Yilmaz and Shah [109]].
The localization of body parts in movies has been investigated by Ramanan et al. [76] and Ferrariet al. [24]. However, the detection of body parts is a difficult problem in itself, and existing approaches, especially for the case of realistic and less constrained video data, remain limited in their applicability. Some recent approaches that are able to provide more robust results [1], use strong prior knowledge by assuming particular motion patterns in order to improve tracking of body parts. However, this also limits their application to action recognition.
2.3
Holistic methods
Holistic methods do not require the localization of body parts. Instead, global body structure and dynamics are used to represent human actions. Polana and Nelson [73] referred to this approach as “getting your man without finding his body part”. The key idea is that, given a region of interest centred on the human body, global dynamics are discriminative enough to characterize human actions. Compared to approaches that explicitly use a kinematic model or information about body parts, holistic representations are much simpler, since they only model global motion and appearance information. Therefore their computation is, in general, more efficient as well as robust. This aspect is especially important for realistic videos in which background clutter, camera ego-motion and occlusion render the localization of body parts particularly difficult.
In general, holistic approaches can be divided into two categories.
• The first category employs shape masks or silhouette information, stemming from background subtraction or di↵erence images, to represent actions.
• The second category is mainly based on shape and optical flow information.
2.3.1
Shape mask and silhouette based methods
Several approaches for action recognition use human shape masks and silhouette information to represent the human body and its dynamics.
Bobick and Davis [12] use shape masks from di↵erence images to detect human actions. As action representation, the authors employ so-called motion energy images (MEI) and motion history images (MHI), as illustrated in Figure 2.1.
Figure 2.1: motion history images (MHI) and motion energy images (MEI) [12]. This can be viewed as a weighted projection of a 3-D XYT volume into 2-D XY Dimension
Figure 2.2: Space-time volumes for action recognition based on silhouette infor-mation [9]
More precisely, MEIs are binary masks that indicate regions of motion, and MHIs weight these regions according to the point in time when they occurred (the more recent, the higher the weight). This approach is the first to introduce the idea of temporal templates for action recognition.
Sullivan and Carlsson [89] detect tennis forehand strokes by matching a set of hand-drawn key postures, together with annotated body joint positions, to edge information in a video sequence. Positions of joints are then tracked between the key frames using silhouette information of the tennis player. This approach allows the positions of body parts to be inferred, which can be applied to animation.
An action model, based on space-time shapes from silhouette information, is introduced by Blank et al. [9]and Gorelick et al. [28]. Silhouette information is computed using background subtraction. Figure 2.2 illustrates some examples of
space-time shapes. The authors use the Poisson equation to extract features such as local saliency, action dynamics, shape structure and orientation. Sequences of 10 frames length are then described by a high-dimensional feature vector. During classification, these sequences are matched in a sliding window fashion to space-time shapes in test sequences.
Another work that uses space-time shapes of humans, is proposed by Yilmaz and Shah [110]. Spatio-temporal shapes are obtained from contour information using background subtraction, similar to Blank et al. [9]. For a robust representation, actions are then represented by sets of characteristic points (such as saddle, val-ley, ridge, peak, pit points) on the surface of the shape. In order to recognize actions, the authors propose to match spatio-temporal shapes by computing a homography using point-to-point correspondences.
Weinland and Boyer [100] introduce an orderless representation for action recog-nition using a set of silhouette exemplars. Action sequences are represented as vectors of minimum distance between silhouettes in the set of exemplars and in the sequence. Final classification is done using Bayes classifier with Gaussians to model action classes. In addition to silhouette information, the authors also employ the Chamfer distance measure to match silhouette exemplars directly to edge information in test sequences.
Foreground shape masks based on motion information in chunks of video data are employed by Zhang et al. [115], as shown in Figure 2.3 . A Motion Con-text descriptor is computed over consistent regions of motion by using a polar grid. Each cell in the grid is described with a histogram over quantized SIFT [53] features. The final descriptor for a sequence is a sum over all chunk descrip-tors. For classification, support vector machines (SVM) and di↵erent models for probabilistic latent semantic analysis (PLSA) are employed.
Figure 2.3: Motion Context descriptor for the actions hand waving and jogging: motion images are computed over groups of images; the Motion Context descrip-tor is computed over consistent regions of motion [115]
Silhouettes are also a popular representation for surveillance applications [35]. Since cameras are in general static, background subtraction techniques can be employed to compute silhouette information. In order to cope with more chal-lenging video data and camera motion, Ramasso et al. [77] employ a human tracker and camera motion estimation to compute shape information.
Another way to match space-time shape models to cluttered image data with heterogeneous background is demonstrated by Ke et al. [38]. The authors over segment video sequences using colour information. Volumetric and optical flow features are then matched to action templates in the form of space-time shapes.
Silhouettes provide strong cues for action recognition. Nevertheless, they are difficult to compute in the presence of clutter and camera motion. Furthermore, they only describe the outer contours of a person and thus lack discriminative power for actions that include self-occlusions.
2.3.2
Optical flow and shape-based methods
Human-centric approaches based on optical flow and generic shape information form another sub-class of holistic methods. As one of the first works in this direc-tion, Polana and Nelson [73] proposed a human tracking framework along with an action representation using spatio-temporal grids of optical flow magnitudes. The action descriptor is computed for periodic motion patterns. By matching against
Figure 2.4: Motion descriptor using optical flow: (a) Original image, (b) Optical flow, (c)Separating the x and y components of optical flow vectors, (d) Half-wave rectification and smoothing of each component [21]
reference motion templates of known periodic actions (e.g., walking, running, swimming) the final action can be determined.
In another approach purely based on optical flow, Efros et al. [21] track soccer players in videos and compute a descriptor on the stabilized tracks using blurred optical flow. Their descriptor separates x and y flow as well as positive and negative components into four di↵erent channels, as shown in Figure 2.4. For classification, a test sequence is frame-wise aligned to a database of stored, an-notated actions. Further experiments include tennis and ballet sequences as well as synthetic experiments.
The same human-centric representation based on optical flow and human tracks for action recognition is employed by Fathi and Mori [22]. As a classification framework, the authors use a two-layered AdaBoost variant. In the first step, intermediate features are learned by selecting discriminative pixel flow values in small spatio-temporal blocks. The final classifier is then learned from all previ-ously aggregated intermediate features.
Rodriguez et al. [81] propose an approach using flow features in a template matching framework. Spatio-temporal regularity flow information is used as the feature. Regularity flow shows improvement over optical flow since it globally minimizes the overall sum of gradients in the sequence. Rodriguez et al. [81] learns cuboid templates by aligning training samples via correlation. For
classifi-cation, test sequences are correlated with the learned template via a generalized Fourier transform that allows for vectorial values. Results are demonstrated on the KTH dataset, for facial expressions, as well as on custom movie and sports actions.
To localize humans performing actions such as sit down, stand up, grab cup and close laptop, Ke et al. [37] use a forward feature selection framework and learn a classifier based on optical flow features. Spatio-temporal Haar features on optical flow components are efficiently computed using an integral video structure. During learning, a discriminative set of features are greedily chosen to optimally classify actions which are represented as spatio-temporal cuboidal regions. For classification, the authors perform a sliding window approach and classify each position as containing a particular action or not.
A method purely based on shape information is presented by Lu and Little [54]. In their experiments, Lu and Little track soccer or ice-hockey players and represent each frame by a descriptor using histograms of oriented gradients. They then employ principal component analysis (PCA) to reduce dimensionality. An HMM with a few states models actions such as running/skating left, right etc.
Hybrid representations combine optical flow with appearance information. Schindler and van Gool [85] use optical flow information and Gabor filter re-sponses in a human-centric framework. For each frame, both types of information are weighted and concatenated. PCA over all pixel values is applied to learn the most discriminative feature information. Majority voting yields a final class label for a full sequence in multi-class experiments. Evaluations are carried out on the KTH and Weizmann dataset.
Human centric approaches require a method for localizing humans, therefore they rely intrinsically on the quality of human detections. To cope with imperfect
localizations from weakly labelled training data and an automatic human tracker,
Hu et al. [34] introduce an approach based on multiple instance learning. In
the neighbourhood around an annotated action or a human detection, a bag of possible action localization hypotheses is generated. An initial classifier is learned on all positive and negative instances. Iteratively, instances in bags are relabelled using the previously learned classifier and the classifier is retrained on the new data. Huet al. [34] apply a simulated annealing strategy to ensure convergence. Feature types that are used are histograms of oriented gradients, foreground segmentation, and motion history images [12]. Results are presented on simple actions in crowded sequences as well as in more challenging data recorded in a shopping mall.
Even though holistic approaches have been shown to be suitable for action recog-nition in more realistic video data, certain points are important to note. Holis-tic representations are in general not invariant to camera view direction. This needs to be accounted for, either by learning di↵erent models for particular views (frontal, lateral, rear), or by providing a sufficiently large amount of training data. Additionally, humans can appear at di↵erent scales (distant view, close-up view) such that certain parts of the body might not be visible in the image. However, human localizations reduce the computational complexity of detecting actions in time substantially.
2.4
Local feature methods
Local image and video features have been successfully used in many action recog-nition applications such as object recogrecog-nition, scene recogrecog-nition and activity recognition. Local space-time features capture characteristic shape and motion information for a local region in video. They provide a relatively independent
representation of events with respect to their spatio-temporal shifts and scales as well as background clutter and multiple motions in the scene. These features are usually extracted directly from video and therefore avoid possible dependencies on other tasks such as motion segmentation and human detection.
In the following, we first discuss existing space-time feature detectors and feature descriptors. Methods based on feature trajectories are presented separately, since their conception di↵ers from space-time point detectors. Finally, methods for localizing actions in videos are discussed.
2.4.1
Feature detectors
Feature detectors usually select characteristic spatio-temporal locations and scales in videos by maximizing specific saliency functions. Laptev [43] proposed a feature detector based on a spatio-temporal extension of the Harris cornerness criterion [31]. The cornerness criterion is based on the eigenvalues of a spatio-temporal second-moment matrix at each video point. Local maxima indicate points of interest. The authors note the importance of using separate spatial and temporal scale values since spatial and temporal extent of events are, in general, independent. Results of detecting Harris interest points in an outdoor image sequence of a person walking is illustrated in Figure 2.5.
Dollar et al. [19] argue that in certain cases, true spatio-temporal corner points (according to the Harris criterion) are relatively rare, while enough characteristic motion is still present in other regions. Therefore, they design their interest point detector to yield denser coverage in videos. Their method employs spatial Gaussian kernels and temporal Gabor filters. As with Harris 3D, local maxima give final interesting positions.
Figure 2.5: Spatio-temporal interest points from the motion of the legs of a walking person; (left) 3D plot of a leg pattern and the detected local interest points; (right) interest points overlaid on single frames in the original sequence [43]
A space-time extension of a salient region detector using entropy, is introduced by Oikonomopoulos et al. [70]. Entropy is computed in a cylindrical neighbourhood around a given space-time position for the temporal derivative of a video sequence. To obtain a sparse representation and more stable interest points, local maxima are thresholded and clustered.
The Hessian3D detector is proposed by Willemset al. [103] as a spatio-temporal extension of the Hessian saliency measure applied for blob detection in images [8]. The authors aim at a rather dense, scale-invariant, and computationally efficient interest point detector. Their detector measures saliency using the determinant of the 3D Hessian matrix. An integral video structure allows a speed up of compu-tations by approximating derivatives with box-filter operations. A non-maximum suppression algorithm selects joint extrema over space, time and di↵erent scales.
Most feature detectors determine the saliency of a point with respect to its local neighbourhood. Wong and Cipolla [104] suggest determining salient features by considering global information. For this, video sequences are represented as a dynamic texture with a latent representation and a dynamic generation model. This not only allows motion to be synthesised, but also allows the identification of important regions in motion. The dynamic model is approximated as a linear transformation. A sub-space representation is computed via non-negative matrix factorization.
2.4.2
Feature descriptors
Feature descriptors capture shape and motion information in a local neighbour-hood surrounding interest points. Among the first works on local descriptors for videos, Laptev and Lindeberg [44] develop and compare di↵erent descriptor types: single- and multi-scale higher-order derivatives (local jets), histograms of
optical flow, and histograms of spatio-temporal gradients. Histograms for opti-cal flow and gradient components are computed for each cell of a M⇥M⇥M grid layout describing the local neighbourhood of an interest point. A di↵erent variant describes the surrounding of a given position by applying PCA to concate-nated optical flow or gradient components of each pixel. The resulting descriptor uses the dimensions with the most significant eigenvalues. In their experiments, Laptev and Lindeberg [44] report best results for descriptors based on histograms of optical flow and spatio-temporal gradients.
In a similar work, Dollar et al. [19] evaluates di↵erent local space-time descrip-tors based on brightness, gradient, and optical flow information. They investigate di↵erent descriptor variants: simple concatenation of pixel values, a grid of local histograms, and a single global histogram. Finally, PCA reduces the dimensional-ity of each descriptor variant. Overall, concatenated gradient information yields the best performance.
Histograms of oriented spatial gradients (HOG) and Histograms of optical flow (HOF) descriptors are introduced by Laptev et al. [45]. To characterize local motion and appearance, the authors combine HOG and HOF in a late fusion approach. The histograms are accumulated in the space-time neighbourhood of detected interest points. Each local region is subdivided into a N⇥N⇥N grid of cells; for each cell, 4-bin HOG histogram and a 5-bin HOF histogram are computed. The normalized cell histograms are concatenated into the final HOG and HOF descriptors.
An extension of the SIFT descriptor [53] to 3D was proposed by Scovanner et al. [87]. For a set of randomly sampled positions, spatio-temporal gradients are computed in the local neighbourhood of each position. Each pixel in the neigh-bourhood is weighted by a Gaussian centred on the given position and votes into an M⇥M⇥M grid of histograms of oriented gradients. For orientation
quan-Figure 2.6: Feature trajectories by detecting and tracking spatial interest points. Trajectories are quantized to a library of trajections which are used for action classification [61]
tization, the authors represent gradients in spherical coordinates ,'; that are divided into an 8⇥4 histogram. To be rotation-invariant, the axis corresponding to =' = 0 is aligned with the dominant orientation of the local neighbourhood.
Willems et al. [103] propose the extended SURF (ESURF) descriptor, which extends the image SURF descriptor [7] to videos. Like in previous approaches, the authors divide 3D patches into a grid of local M⇥M⇥M histograms. Each cell is represented by a vector of weighted sums of uniformly sampled responses of Haar-wavelets along the three axes.
2.4.3
Feature Trajectories
Feature trajectories are based on spatial interest points tracked in time-as opposed to spatio-temporal interest points. Trajectory shapes encode information about local motion patterns and can thus be directly used as a local feature. Messing
et al. [64] represent feature trajectories of varying length as sequences of
log-polar quantized velocities. Activities are modelled using a generative mixture of Markov chain models.
In a di↵erent approach, Matikainen et al. [61] employ feature trajectories of a fixed length in a bag-of-features framework for action classification, as shown in Figure 2.6. Trajectories of a video are clustered together, and for each cluster centre, an affine transformation matrix is computed. In addition to displacement vectors, the final trajectory descriptor contains elements of the affine transforma-tion matrix for its assigned cluster centre.
2.4.4
Voting based action localization
Combined with a voting scheme, local features can also be employed to spatially and temporally localize actions in videos. For instance, Niebleset al. [69] perform a latent topic discovery and model the posterior probability of each quantized feature for a given action class. In order to localize actions, features are spatially clustered in each frame using k-means.
Mikolajczyk and Hirofumi [66] propose a voting approach to localize objects that perform a particular action. The authors use a forest of tree classifiers for fast feature quantization. The GLOH image descriptor [65], together with its dom-inant motion orientation, is used as local descriptor type. Features in motion cast initial hypotheses for position and scale of objects performing an action. Maxima in the voting space indicate detections, and static features refine their initial localization. For the final pose estimation, the object’s global orientation is computed from the orientation of voting features.
In order to localize actions in YouTube video sequences, Liu et al. [51] propose an approach based on pruning local features. First, spatio-temporal features are detected and their mean position over a range of neighbouring frames is computed. Features that are too far away from the center position are pruned. Second, static features are computed over all frames. By applying the Page Rank
algorithm over a graph for feature matches in a video sequence, the authors are able to identify discriminative features. For this, similar background features are assumed to be less frequently visible than foreground features. Finally, static and motion features are combined with an AdaBoost classifier. Action localization is carried out with a temporal sliding window over spatio-temporal candidate regions, defined by the centre and the second moments of motion as well as static features.
Willems et al. [102] model actions as space-time cubes. They localize drinking actions in movies by casting localization hypotheses for the strongest visual code-book entries of an action. Weak hypotheses are pruned, and a non-linear 2 SVM
evaluates the BoF representations of remaining ones. Local maxima in the voting space indicated the final action positions.
A related approach by Yuan et al. [112] employs the branch-and-bounds algo-rithm to localize actions in video sequences. Actions are, again, represented as cuboid volumes. The volumes themselves are scored based on mutual information and a Gaussian kernel for density estimation. For a more efficient density esti-mation, the authors introduce an approximated nearest neighbour search based on local sensitive hashing. Experimental results are shown for the KTH and the CMU actions dataset.
2.4.5
Summary
A key advantage of local features-based approaches is their flexibility with respect to the type of video data. They can be applied to videos for which the localization of humans or their body parts is not feasible. More recent works demonstrate their successful application to real world video data, such as Hollywood movies and YouTube video sequences (Laptevet al. [45], Mikolajczyk and Hirofumi [66],
![Figure 2.5: Spatio-temporal interest points from the motion of the legs of a walking person; (left) 3D plot of a leg pattern and the detected local interest points; (right) interest points overlaid on single frames in the original sequence [43]](https://thumb-us.123doks.com/thumbv2/123dok_us/1453455.2694509/58.918.233.721.450.742/figure-spatio-temporal-walking-detected-overlaid-original-sequence.webp)
![Figure 2.7: Sample Frames from the KTH Human actions dataset [86]. Box- Box-ing (first column), handclappBox-ing (second column), handwavBox-ing (third column), jogging (fourth column), running (fifth column), walking (sixth column)](https://thumb-us.123doks.com/thumbv2/123dok_us/1453455.2694509/65.918.108.727.174.563/figure-sample-frames-actions-dataset-handclappbox-handwavbox-jogging.webp)
![Figure 2.8: Sample frames from the Weizmann actions dataset [9]](https://thumb-us.123doks.com/thumbv2/123dok_us/1453455.2694509/66.918.241.724.437.806/figure-sample-frames-weizmann-actions-dataset.webp)
![Figure 2.9: Sample frames from the Hollywood2 action dataset [60]](https://thumb-us.123doks.com/thumbv2/123dok_us/1453455.2694509/68.918.243.726.387.858/figure-sample-frames-hollywood-action-dataset.webp)
![Figure 2.10: Sample frames from UCF sports action datasets [81]](https://thumb-us.123doks.com/thumbv2/123dok_us/1453455.2694509/70.918.240.726.437.810/figure-sample-frames-from-ucf-sports-action-datasets.webp)
![Figure 2.11: Sample frames from the YouTube action dataset [51]](https://thumb-us.123doks.com/thumbv2/123dok_us/1453455.2694509/71.918.172.663.174.646/figure-sample-frames-youtube-action-dataset.webp)
![Figure 3.3: Max-margin hyperplane derived from the training of two class SVM [88]](https://thumb-us.123doks.com/thumbv2/123dok_us/1453455.2694509/82.918.345.622.507.807/figure-max-margin-hyperplane-derived-training-class-svm.webp)