Statistical Lip-Appearance Models Trained
Automatically Using Audio Information
Philippe Daubias
Laboratoire d’Informatique de l’Universit´e du Maine (LIUM), Institut d’Informatique Claude Chappe, F-72085 Le Mans Cedex 9, France
Laboratoire d’Informatique Graphique Image et Mod´elisation (LIGIM), Bˆatiment 710, 8, bd Niels Bohr, F-69622 Villeurbanne Cedex, France
Email: [email protected]
Paul Del ´eglise
Laboratoire d’Informatique de l’Universit´e du Maine (LIUM), Institut d’Informatique Claude Chappe, F-72085 Le Mans Cedex 9, France
Email: [email protected]
Received 1 November 2001 and in revised form 19 June 2002
We aim at modeling the appearance of the lower face region to assist visual feature extraction for audio-visual speech processing applications. In this paper, we present a neural network based statistical appearance model of the lips which classifies pixels as belonging to thelips,skin, orinner mouthclasses. This model requires labeled examples to be trained, and we propose to label images automatically by employing a lip-shape model and a red-hue energy function. To improve the performance of lip-tracking, we propose to usebluemarked-up image sequences of the same subject uttering the identical sentences asnaturalnonmarked-up ones. The easily extracted lip shapes fromblueimages are then mapped to thenaturalones using acoustic information. The lip-shape estimates obtained simplify lip-tracking on thenaturalimages, as they reduce the parameter space dimensionality in the red-hue energy minimization, thus yielding better contour shape and location estimates. We applied the proposed method to a small audio-visual database of three subjects, achieving errors in pixel classification around 6%, compared to 3% for hand-placed contours and 20% for filtered red-hue.
Keywords and phrases:lip-appearance model, lip-shape model, automatic lip-region labeling, artificial neural networks, dynamic time warping, audio-visual corpora.
1. INTRODUCTION
Today, automatic speech recognition (ASR) works well for several applications, but performance depends highly on the specificity of the task, and on the type and level of surround-ing noise. To strengthen ASR systems against noise, one may, for example, use multiband systems [1], higher level (linguis-tic) information [2], or visual information which is comple-mentary to the audio information. Since McGurk’s experi-ments [3] which have proven the importance of visual in-formation in human speech perception, visual modality has been successfully used for improving performance and ro-bustness of ASR [4, 5, 6, 7, 8, 9], speaker recognition [10, 11], and other speech applications [12]. Using visual information in unconstrained conditions requires having accurate visual feature extraction, regardless of the visual features used:
(i) pixel-based (data-driven) features:images are fed di-rectly into a speech recognition system [4, 5, 8, 13], after applying a few transformations or normalizations
to the images (fixed-size ROI (region of interest) crop-ping, histogram normalization, for example);
(ii) model-based features:a model is located on images, and parameters to be used for ASR are deduced form the location and shape of the model.
performance is lower, a model of the lips allows easier com-parison with other results on audio-visual speech (in pro-duction for instance). Most research of the model-based cat-egory has only focussed on lip shape. Lip-shape models are often a priori parametric models: a set of parabolic curves [18, 19, 20], elliptic or portions of elliptic curves [19, 21], or geometric templates (polygons) [22]. Rev´eret and Benoˆıt [23], and Basu et al. [24], use a 3D parametric shape model of the lips. The shape model might also be an a posteri-ori geometrical template (polygon), with its shape and de-formations learned statistically from corpora [7, 11]. Fi-nally, Dupont and Luettin [25], and Matthews et al. [26] also use a lip grey-level appearance model learned from a corpus.
We are also interested in modeling the appearance, but of the whole lower face region. Contrary to other existing approaches relying on red-hue [14, 27, 28, 29], we aim at modeling appearance statistically using feed-forward artifi-cial neural networks (ANNs) also known as multiple layer perceptrons (MLPs). We present here an MLP-based statis-tical appearance model of the lips which classifies pixels as belonging to thelips,skin, orinner mouthclasses. Such an ANN requires labeled examples to be trained and these may only be found on natural images. Therefore, training this model requires a precise labeling of such images. One way to obtain examples is to hand-label images, but annotating lips is a hard and time-consuming task for humans. More-over, using such a statistical appearance model on a large database would quickly make the labeling task become in-tractable, as shown in [8]: the necessary labeling phase must be partially or fully automated. In this paper, we propose to achieve this, avoiding labor-intensive hand labeling, by employing automatic lip contour tracking based on a lip-shape model and a red-hue energy function. The lip-lip-shape model is a polygon, which represents outer and inner lip contours of a subject, and whose shape and deformations are learned statistically. The energy function uses hue in-formation and a filtering function to be more robust. As nevertheless contour tracking lacks robustness, to improve its performance, we propose to useblueimage sequences of the same subject uttering the identical sentences as natural
ones. We then use the acoustic channel of both sequences to perform a dynamic time warping alignment. The easily extracted lip shapes from blue images are then mapped to the corresponding natural ones using the audio alignment of the two sequences. The obtained lip-shape estimates sim-plify lip-tracking on the naturalimages, as they reduce the parameter space dimensionality in the red-hue energy mini-mization, thus yielding better contour shape and location es-timates. Such lip contours can then be used to automatically label image blocks as belonging to one of the three classes of interest.
In Section 2, we describe the statistical appearance model of the lower face we intend to use. Then, in Section 4 we ex-plain how to train it automatically using a statistical lip-shape model (described in Section 3) and how to use acoustic infor-mation to obtain a more accurate automatic labeling. Finally, detailed results are presented in Section 5.
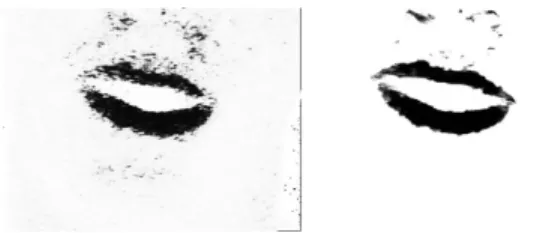
Figure 1: A samplenaturalimage from the corpus: color image (left) and filtered red-hue image (right).
2. LIP APPEARANCE MODELING
We intend to model the lower face appearance to assist vi-sual feature extraction. More precisely, we aim at classifying image pixels as belonging to the three classes of interest of this region: skin,lips, andinner mouth. In this section, we first briefly summarize existing approaches, and then pro-pose how to model appearance statistically and how to train such a statistical model.
2.1. Literature approaches
Work towards automatic lip segmentation in natural condi-tions was reported by Coianiz et al. [27], Li´evin and Luthon [14], Zhang et al. [29], and Wojdel and Rothkrantz [28]. They all make use of hue information, either filtering it with a parabolic filter [27, 28], or combining it with edge [29] or movement information [14]. Although reported results are always good, the extension to other corpora recorded in dif-ferent conditions does not seem obvious. We tested the color transformation proposed by [27, 28, 29], but the results ob-tained were not as good as expected. The images obob-tained were similar to the one on the right of Figure 1, for which cor-rect lip classification only reaches 80.5%, according to manu-ally labeled contours, whereas non-lip classification is 98.1%. Contrary to others, Li´evin uses a logarithmic color transfor-mation to compute hue. This is justified by the low quality of the camera used and the noisy images produced by it. We have also tested this color transformation on our corpus, but the results were not any better. Wojdel [28] also proposes to use a very simple ANN instead of hue. Training is done us-ing a closed mouth image roughly hand-labeled by the user: pixels inside a rectangular area are labeled as lips and the rest as non-lips, and we will discuss this type of model in more detail in the next subsection.
A crucial issue is the portability to different skin colors (for different ethnicities), and red-hue based models may not always be accurate in such contexts. We believe that it is pos-sible to obtain more accurate models relying only on appear-ance and that the best way to achieve this, is to build, like other researchers [25, 26], an a posteriori statistically learned appearance model of the lips. In the following subsections, we present more precisely the appearance model we wish to build and how to train it.
2.2. Statistical modeling of lip appearance
contour point), we use global appearance similarly to [30], by applying a single classifier to each image pixel. We consider three classes of interest, and we train the classifier to assign image points into thelips,skin, orinner mouth(teeth, dark area, and tongue) classes. We tried both Gaussian mixture model (GMM) and neural network (NN) classifiers, obtain-ing very similar results. For example, correct classification is around 87.5% for a mixture of 4 Gaussians per class and 87.2% for a neural network with 10 hidden units.
We have also varied the image block size for classifica-tion, and results improved with increased block size, from 87.2% for 1×1 pixel blocks (as used by Wojdel [28]) to 98% for 5×5 pixel blocks. Classification results obtained using NNs are somewhat superior to GMMs, when image blocks are used, for example, 2 mixtures per class lead to a 94% recognition accuracy, compared to an NN classifier with 6 hidden units which achieves 96.5% accuracy. Similarly, a 10-mixture per class GMM reaches 97.4%, whereas a 30-hidden unit NN achieves 98.1% recognition and is less computation-ally expensive to use. There is a certain trade-offbetween the size of blocks and the number of training samples, and with regard to the size of our images, we chose to use 5×5 color blocks.
Our chosen appearance model is a three-layer feed-forward ANN. Its entry layer contains 75 units (one for each red, green, and blue value of each 5×5 block pixel), whereas its output consists of three units, one for each class of inter-est. The three output values of the network correspond to the probability of the image block to belong to thelips,skin, or
inner mouthclasses. Between the 75 input and the 3 output units, there exists one layer of hidden units. We have evalu-ated two different network architectures, one having 10 hid-den units, and one having 15. Both networks are fully con-nected and are trained using back propagation (supervised learning).
2.3. Training of the lip appearance model
To train the neural networks, labeled 5×5 color blocks are required (blocks for which it is known whether they belong to the skin,lips, or inner mouthclasses). As a lip contour, once located in an image, indicates the frontier between skin and lips (outer lip contour), and between lips and the in-side of the mouth (inner lip contour), it is possible to use an image with its corresponding contour to automatically label the blocks. To obtain these contours, manual labeling may be considered on small data sets, but would become in-tractable on large databases, as shown in [8]. We assume that automatic labeling is possible, we will explain how it can be achieved later.
For the supervised network training, we will work on a region about 15 pixels wider than the lips on all sides, and centered around them, because this is the region where most of the confusion lies. This region will be scanned pixel by pixel, and for each pixel, we will consider the 5×5 pixel color image block centered around this position. For training, we will take only homogenous blocks into account (blocks for which all pixels belong to the same class). We will pseudo-randomly select 45 000 blocks (15 000 per subject) of each
class and train the networks with them (1000 iterations). In Section 5, the networks obtained will be referred to as auto-10 and auto-15, where the number auto-10, or 15, corresponds to the number of hidden layer units. We will also train the two neural networks with “certified” blocks. These blocks will be a subset of the previous ones, less subject to mislabeling. As automatic location is less certain than manual location, to obtain this subset, we will reject all blocks that are near the lip contours representing the boundaries between the 3 dif-ferent classes. In Section 5, these networks will be referred to as cert-10 and cert-15.
In Section 3, we will discuss how to automatically extract lip boundaries onblueimages, however the algorithm per-forms poorly onnaturalimages. The blue color has high con-trast against flesh tones, but without cosmetic assistance, hue information does not allow to separate lips from skin effi -ciently (see Figure 1), and red-hue alone cannot be used to reliably estimate lip shape. To achieve accurate lip shape and location estimation onnaturalimages, we propose to com-bine red-hue with a lip-shape model. The design and training of this shape model will be described in Section 3.
3. LIP SHAPE MODELING
To build a statistical shape model, the most natural way is to hand-label images, as done in [7, 26]. But, even with the help of a specialized tool we designed for it, it is a hard and time-consuming task, especially when building a precise model with numerous points. Time is an important issue consid-ering that the larger the corpus, the better the model is. To build an accurate shape model, an automatic procedure is necessary.
3.1. Lip-contour extraction in “blue” images
To automatically build the shape model, we usebluevideo se-quences. The blue color of the lipstick corresponds approx-imately to 220 degrees on the color circle and was chosen to make shape extraction of the lips easier: as blue does not exist in the skin, colored lips present high contrast against the rest, with respect to hue information. Due to variation in lighting recording conditions, on some images, the teeth reflect the blue color from the lips, thus appearing blue. To discriminate the blue lips from the blue teeth, we use satu-ration information, which corresponds roughly to the purity of the color (the quantity of white added in it). Lips and teeth have high and low saturation values, respectively, and we use a combination of saturation and hue.
Figure2: A sample image from the corpus: original image (left), blue-hue image (center), and the contour extracted (right).
considered as the left lip corner. Similarly, the center of grav-ity of all pixels below the mean grey-level value on the right most column is considered as the right lip corner.
Based upon these lip corners, we extract the outer lip contour by considering the interval between the two lip cor-ners. To get annpoint contour, wherenis an even integer greater than 2 (n >2), we cut this interval (n−2)/2 times and take as contour points the highest and lowest blue-hue points. We then detect whether the lips are open or closed (if there is a non-null inner lip contour). When appropriate, we extract the inner lip corners position and the inner lip con-tour in the same way. An example of concon-tour extraction on a
blueimage can be seen in Figure 2. 3.2. Shape model building
The shape model of the lips is a 44-vertex polygon. More precisely, a 24-vertex polygon describes the outer-lip contour and a 20-vertex polygon describes the inner lip contour. For each picture, we extracted these 44 points, as described in Section 3.1. We then normalized all shapes for position, rota-tion, and scaling. From the 1190 shapes available in our cor-pus, we kept only those with a non-null inner contour (618). We then calculated the mean shape c of all contours and subtracted it from all the normalized contours, thus obtain-ing 88-dimensional contour vectors. Finally, we performed a principal component analysis (PCA) on these vectors as in [7]. As a result, any shape of lipscfound in the corpus can be expressed as
c=c+V·p, (1)
wherec is the mean shape of the lips,V = (v1,v2, . . . ,v88) is the matrix for the column eigenvectors, and p =
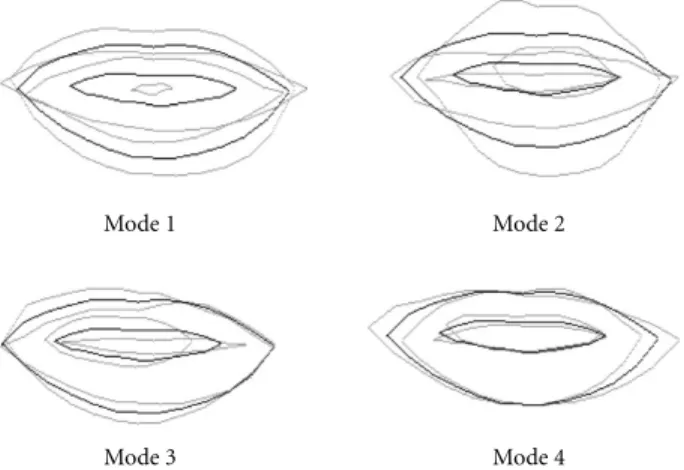
(p1, p2, . . . , p88) is a column vector of dimension 88 con-taining the weights of each eigenvector to obtain the desired shape. The first coefficients of this vector account for most of the variation, and the projection of the original shape on the first few axes gives a good approximation of the contour. As a result, it is possible to use only the first few eigenvectors to approximate lip shapes. Here, the first 4 vectors represented about 94% of lip deformations, and are shown in Figure 3. Any shape of lipsccan be approximated by
c≈c+p1v1+p2v2+p3v3+p4v4. (2)
3.3. Shape model evaluation
To evaluate the lip-shape model, we filled the polygons cor-responding to lip contours (examples of filled shapes can be
Mode 1 Mode 2
Mode 3 Mode 4
Figure3: From the first to the fourth mode of deformation: mean shape in solid lines and maximum observed deviation on both sides of the mean (in grey).
Figure4: Examples of good (upper row) and bad (lower row) ap-proximations of lip shape for the three subjects considered (2 males and one female (center)) using the first four eigenvectors.
seen in Figure 4) and measured the percentage of overlap be-tween the original and the projected contour areas. Overlap can be defined as the number of intersection pixels divided by the number of union pixels of the two areas, that is,
overlap =original contour ∩ projected contour
original contour ∪ projected contour. (3)
Table1: Overlap between real lip shapes and projected shapes for different numbers of eigenvectors used (percentages, %).
Number of vectors 1 2 3 4 5 6 7 PCA variance % 60.1 84.7 92.0 94.0 95.3 96.6 97.5 Worst case 37.4 54.7 55.2 60.6 60.9 62.2 80.4 Mean 75.7 84.1 86.7 87.7 89.2 90.9 92.4 Best case 90.9 93.8 95.2 96.2 96.3 97.1 97.7
Figure 4 shows the overlap between extracted normalized contours and their projection on the first four PCA axes, for three corpus subjects. The extracted contours are filled in dark grey, whereas the projected ones are filled in light grey. Points appearing black are intersection pixels. This fig-ure gives the opportunity to see that the quality of shape ap-proximation varies a lot, but also that a 4-parameter model may adapt to the specific lip shape of different subjects. Such a 4-parameter model is suitable for lip location as will be shown in Section 4.
4. LIP CONTOUR LOCATION ONNATURALIMAGES
In Section 3, we have shown how to automatically build a lip-shape model. We will now use it for lip location onnatural
images using first a joint lip-shape and location estimation scheme and then a more efficient cascade lip-shape estima-tion and locaestima-tion scheme, made possible through the use of complementary acoustic information.
4.1. Joint lip-shape and location estimation
Locating the subject’s lips in an image with our shape model can be accomplished by applying the right deformation to the mean shapecand then placing the obtained shape at the right position. We must search a 4-dimensional space for lip contour position (x, y), scaling (r), and rotation (θ), as well as a 4-dimensional space (p1, p2, p3, p4) for lip shape (see (2)). The best fit of the shape model on the image is obtained by minimizing the f function which measures the distance from a red-centered (about 0 degree on the color circle) hue image (img) to a model image (mod), computed with each set of parameters (x, y, r, θ, p1, p2, p3, p4) where size is the number of pixels in the image (width ×
height), modi and imgi represent the model and red-hue, respectively for eachipixel and will be detailed next. To re-inforce red-hue’s discrimination, we use the following robust function, proposed by Odobez [31] in the energy criterion
imgi= 1
π ∗arctan 0.4π∗
huei−huet+1 2, (5)
where hueiis the hue value and imgithe output filtered hue
value for each pixel. The transition hue value was set to huet=4 degrees. Model image mod is computed as follows: the mean shapecis deformed intocwith (2), then it is scaled and rotated according torandθ. The center of gravity of the obtained contour is translated from (0,0) to (x, y), and this latter contour is drawn, then filled (as in Figure 4) on the mod image. The modivalues from each pixeliof this image are
0 between outer and inner lip contour,
1 elsewhere.
(6)
We tested lip location on natural images using filtered red-hue, and the downhill simplex method (DSM) [32] as a minimization procedure, but the results were poor. Com-paring the contours obtained by this method to the refer-ence hand-labeled ones, the overlap was only about 69.0% on average with a minimum overlap of 31.5%. When looking only at the shapes (not at location), the overlap was on aver-age about 72.2%, with a minimum of 34.2%. By a visual in-spection, we noticed that the worst cases were obtained with wrong shapes: the DSM method searches all dimensions si-multaneously to find the minimum. It may happen that a wrong and badly placed shape has so little energy that it at-tracts the simplex into a local minimum.
These poor results do not mean that our shape model is inappropriate, but rather indicate that appearance based on hue information, which we implicitly used in energy mini-mization, is not sufficient. The dominant skin color of the corpus subjects is rather similar to the dominant lip color, thus red-hue images are very noisy (see Figure 1). As a conse-quence, there are numerous local minima at which the min-imization procedure may stop. To locate lips with our shape model more reliably in unconstrained conditions, a more accurate lip-appearance model like the statistical one pre-sented in Section 2.2 would be necessary. However, to build this appearance model, we need accurate lip location on nat-ural images and must improve location in any other way. For this, we propose to estimate lip shape before locating it on the image, instead of trying to jointly estimate shape and location. How this can be achieved will be explained next.
4.2. Cascade lip shape and location estimation using acoustic information
As jointly using a lip-shape model and a red-hue appear-ance function fails, we must add more constraints for loca-tion to work accurately. We propose to divide lip localoca-tion on
natural images into two subtasks: estimating lip shape and then locating this shape on the image. For that purpose, we have recorded our subjects uttering twice the same sentences: once with blue lipstick and once without, and propose to use acoustic information to align the naturalsequences on the
blueones. This should allow to use the lip shapes extracted onblueimages to deduce the presumable shape of the lips on
4.2.1 Use of acoustic information for lip shape estimation
To train the lip-appearance model described in Section 2.2, we need to precisely locate lip boundaries onnaturalimages, but want to avoid labor intensive contour hand-labeling. However, our shape model does not work well enough to lo-cate lips on naturalimages accurately. To improve lip con-tour estimation, we propose to take advantage of speech bi-modality: by consideringblueandnaturalimages of the same person uttering identical sounds, we can reliably obtain lip shape information from theblueimages, and use this to sim-plify the energy minimization problem (4). We propose to find such image correspondence using dynamic time warp-ing (DTW) on the audio channels of the two sequences. Note that on the literature, the visual channel is mostly used to bring complementary cues when acoustic information is un-reliable or missing [12]. By contrast, here we propose to use acoustic information to simplify a visual problem.
DTW is efficient for small vocabulary, isolated word, sin-gle speaker automatic speech recognition [33]. It computes the distance from a test word to all words in the vocabu-lary (qreference words). More precisely, the acoustic signal corresponding to any word is parameterized into acoustic vectors, in this paper, 6 or 12 mel-frequency cepstral coeffi -cients (MFCCs), plus energy. The distances between the vec-tors from the test word and the ones from eachqreference word are computed. This produces n×mk cost matrices,
nbeing the number of acoustic vectors associated with the test word, andmkthe number of vectors associated with the kth reference word (1 ≤ k ≤ q). The lowest cost path be-tween vector pairs (1; 1) and (n;mk) is computed to obtain the distance from the test word to the kth reference word (some constraints are also applied on the path). The low-est cost path computation is repeatedqtimes for each refer-ence word, and the lowest overall distance corresponds to the recognized word. Usually, only this result is used, but DTW brings richer information: the lowest cost path indicates how to best align the vectors from the test and the reference words. In our case, we use DTW to align the acoustic features of a test sentence, corresponding to anaturalimage sequence, to the acoustic features of a reference sentence, correspond-ing to ablueimage sequence. The sentences are pronounced as continuous speech and can be seen as two utterances of the same word, both corresponding to an identical phonem-ical content uttered by the same subject in very similar condi-tions. The alignment (path) produced using DTW gives, for any acoustic vector from the test sentence, the correspond-ing acoustic vector in the reference sentence. Uscorrespond-ing this as-sociation and the synchronicity between acoustic and visual signals, it is possible to deduce to which reference (blue) im-ages (and contours) corresponds a test (natural) image. Due to the different audio and video frame rates (here, 100, or 200 Hz vs. 25 Hz, respectively), a few (4, or 8) acoustic vectors will correspond to one test image. These acoustic vectors will correspond to a similar number of reference sentence acous-tic vectors, which may map to different reference images. Therefore, one test image might be associated with several
different contours. Thus, computing which contour corre-sponds to the test image is not straightforward. We studied three different ways to choose the contour in [34], using ei-ther the first, the last, or an interpolation between all possi-ble contours, and the best results were obtained by the latter method.
Two utterances of the same sentence will not always lead to identical lip shapes, especially considering large corpora with different subjects. Nevertheless, this was true to a high degree for any given subject on the corpus used, and the DTW alignment method worked well even with differences in speaking rate. We do not believe that this method can easily be extended to align any speaker with any other, but more experiments should be carried, to see if classes of speak-ers can be found. Anyway, if only appearance modeling is intended, just a few representative subjects (with different skin colors and facial hair) are needed to build a speaker-independent model, and cross-speaker use of DTW align-ment is not necessary.
4.2.2 Lip contour location estimation
Knowing the presumable lip shape corresponding to a pic-ture facilitates the automatic lip extraction process notice-ably. We just have to locate a shape on an image instead of estimating a shape before placing it, as it was required in Section 4.1. This reduces the risk of wrong location due to wrong shape, and can be done by minimizing the en-ergy function of Section 4.1. The minimization is now over a 4-dimensional space (x, y, r, θ) instead of the original 8-dimensional one (x, y, r, θ, p1, p2, p3, p4), and is therefore more robust. Once again, we use filtered red hue (as [14, 27, 28, 29]) in the energy function calculation. In fact, we calculate for each color image the corresponding filtered red hue (mod) image (see the right part of Figure 1) with (5) and locate the lip shapes on the latter images. We tried two different types of minimization for locating the lips using:
(i) coordinate pair minimization: combinatory explo-ration of scale (r) and rotation (θ) and, for each value of these parameters, energy function calculation at ev-ery possible position (x, y);
(ii) DSM: minimization of all parameters (x, y, r, θ) by a downhill simplex method [32], initialized at the center of image with a scaling factor of one, and no rotation.
For each case, we kept the best contour found according to the energy function.
5. DATABASE AND EXPERIMENTS
In this section, we first describe the corpus used to statis-tically train and test both parts of the lip model, and then the evaluation principles that we propose to follow. Subse-quently, we present our experimental results.
5.1. The audio-visual database
Table2: Characteristics from the subset of our corpus.
Task Phonetically balanced sentences in French Image contents Mouth area and base of nose
Subjects 3
Utterances 8 per subject (4blue, 4natural) Frames 2400 images
Mouth size Approximately 200×100 pixels Lighting Ambient sun light
sentences, we had to build our own audio-visual database. In total, we recorded nine subjects (8 males, 1 female), seven of whom were recorded wearing blue lipstick (6 males, 1 fe-male) to allow training and testing of different shape models, and six with no make-up (5 males, 1 female) for training and testing different appearance models. Videos were captured uncompressed at a resolution of 384×288 pixels in 24 bit RGB color, at a frame rate of 25 noninterleaved images per second. For video acquisition, a PAL analog camcorder was used, connected to a SUN ULTRA2 workstation with an ana-log card for digitization. Audio was recorded using a stan-dard SUN microphone at a sample rate of 16 kHz with 16 bit samples.
In our experiments, we mainly used three subjects (2 males, 1 female) from the corpus. A brief description of the corresponding corpus subset is shown in Table 2. The sub-jects were recorded twice on four phonetically balanced sen-tences in French [35]: first with blue lipstick (as, for exam-ple, in [10]), and then without any make-up. These 24 utter-ances were recorded in natural sun light conditions, which resulted in shadows on some images under the subject’s nose and mouth. We have filmed the subjects, placing the lips near the center of the picture at the beginning of the acquisition, but some subjects moved either before or during recording. The camera-subject distance was variable (about one meter), and so was the zooming factor.
5.2. The evaluation paradigm
Usually, in automatic speech recognition, only global evalu-ations which consist of measuring the recognition rate at the system’s output are made. Although we have recently pub-lished this type of evaluation for our models elsewhere [36], a more detailed evaluation of each step is necessary. Before we report our lip contour estimation results and lip appear-ance model accuracy on the audio-visual database, we briefly discuss the evaluation paradigm for our algorithms.
5.2.1 Lip contour evaluation
We chose to hand-label a subset of thenaturalimages from the corpus, and to use them as a reference for all evaluations. We will compare the automatically extracted contours with the hand-labeled ones, using two metrics:
(i) the average distance (in pixels) between each point from the test contour and the corresponding point in the reference (hand-labeled) contour;
(ii) the percentage of filled shape overlap (see (3)).
5.2.2 Appearance model evaluation
To evaluate the neural network based appearance models, we also use the hand-labeled contours. We want to see if our au-tomatic labeling method allows to build appearance models of the mouth area comparable to manually obtained ones. More precisely, we compare the classification results of the two neural networks described in Section 2.2 after training, as well as of reference networks trained with blocks obtained using hand-labeled contours.
To build these reference models, we need a labeled sub-set of the corpus: for each of the three subjects considered, we hand-placed the contour on a tenth of thenatural im-ages (40 out of 400). To compare all models, we use the same images in all cases, and as acoustic alignment is pos-sible only when there is speech, we do not use many closed lips images. The 120 remaining images produce 1.71 million
skin blocks, 0.72 millionlip blocks, and 0.11 millioninner mouth blocks. As in Section 2.3, we retain 45 000 pseudo-randomly chosen blocks of each class to train the networks. The whole set, including the blocks used for training (ap-proximatively 2.5 million blocks), is used for testing all the networks. In Section 5.3.3, the reference networks obtained will be referred to as ref-10 and ref-15.
Finally, we normalized (in position, rotation, and scal-ing) the hand-labeled contours and used our two energy minimization algorithms (Section 4.2.2) to replace them on their original images. These re-located contours give the op-portunity to extract a new set of blocks to train the neural networks. As the contours are the reference ones, they should be 100% accurate in shape and only location may be inaccu-rate. This allows to see to what extent location and shape esti-mation are responsible for performance loss of the automat-ically obtained models over the reference ones. The trained models will be referred to as loc-10 and loc-15 in the results section.
5.3. Experimental results
We first present quality of lip-shape estimation results, ob-tained using DTW for alignment, followed by location re-sults of these shapes onnaturalimages. Finally, we describe classification results obtained with the two neural networks (10 and 15 hidden layer units) trained with four different sets of image blocks (hand-labeled blocks (ref), automati-cally labeled ones (auto), “certified” ones (cert), and relo-cated hand-labeled ones, (loc)).
5.3.1 Lip-shape estimation
Table3: Distance to the reference of the shapes obtained using DTW.
Acoustic features Distance (pixels) Overlap (%)
Rate MFCCs Worst Mean Best Worst Mean Best
100 12 17.06 6.67 1.81 45.63 77.90 90.01
100 6 17.06 6.57 1.77 45.63 77.77 91.67
200 12 18.60 6.66 1.89 44.87 77.94 91.85
200 6 17.06 6.57 1.93 45.63 77.96 91.01
Table4: Location results by coordinate pair minimization, DSM, and best of both.
Minimization Distance (pixels) Overlap (%)
Algorithm Worst Mean Best Worst Mean Best
Coord. pair min. 19.46 7.07 2.93 59.58 77.98 89.73
DSM 23.86 7.41 3.24 60.23 77.72 86.94
Best of both 23.86 7.39 2.93 60.23 77.96 89.73
percentage of overlap between the lip contours are depicted (see also Section 4.2.1).
One may notice that results are very similar, whatever the type of coefficients used, and that they are approximately 78% for overlap and 6.6 pixels for average distance between the two contours. A number of facts influence these results. First, hand labeling of contours is not perfectly accurate, and the shapes may differ even if the alignment is right, as the reference shape is hand-labeled and the estimated shapes are interpolated from automatically extracted shapes. In addi-tion, one of the database subjects painted a little more than his lips with the blue lipstick. As a result, the automatically extracted lip shapes differ in shape from the manually la-beled ones. Not using this speaker, results become slightly higher than 80% for overlap and reach an average 6 pixels for distance. Finally, we used relatively high resolution im-ages compared to other existing corpora. A 6 pixel average error must be compared to the 200 pixel average width of the lips.
5.3.2 Quality of location
Table 4 shows the results obtained after energy minimiza-tion using the methods described in Secminimiza-tion 4.2.2 (coordi-nate pair minimization, DSM, and best of both, according to the energy criterion used). Notice that the distance results degrade compared to Table 3. Several factors may help ex-plaining this phenomenon: first of all, note that even a one degree variation in rotation alone yields an important er-ror in the results for the distance in pixels between the con-tours. Also remember that, as explained in the previous sub-section, the shapes themselves may differ, which has conse-quences on both measures. However, contour overlap results remain good, and are almost identical to those of Table 3, which demonstrates that location estimation is successful. As a comparison, the use of our minimization procedures for lo-cating contours extracted on blue-hue images (see Figure 2),
Table5: Correct classification rates (%) with each neural network.
Network Skin Inner mouth Lips Global
ref-10 96.91 97.86 98.48 97.40 loc-10 95.16 98.25 97.62 96.00 auto-10 93.68 98.31 93.52 93.84 cert-10 93.53 97.19 95.65 94.30 ref-15 97.61 97.77 98.19 97.78 loc-15 95.56 97.81 98.49 96.49 auto-15 95.39 97.17 91.07 94.24 cert-15 94.94 97.75 94.30 94.88
and normalized back on their source image, yielded results about 3 pixels in distance and 86% in overlap for coordinate pair minimization and 4.3 pixels and 82%, respectively for DSM.
5.3.3 Appearance model accuracy
In our work, the main objective is to build an appearance model of the lips, not to evaluate the quality of location of a contour on an image. Nevertheless, the quality ofalignment,
lip shape, andlocation estimation may also be evaluated by comparing the classification results obtained with the diff er-ent ANNs. Classification results are shown in Table 5. They were calculated on a WTA (winner takes it all) basis, which means that for each block entered, the output unit having the highest value was selected as output of the network. These results were computed on a test set of available hand-labeled image blocks in which all classes are not equally represented (67.3% skin, 28.4% lips, and 4.3% inner mouth). The re-sult for all blocks is presented in the Global column. The
Figure5: Filtered (with (5)) red-hue image (left) and output of the neural network cert-10 (right).
The correct classification rates obtained are very high (always well over 90%), whatever the ANN used. Table 5 shows a global improvement of classification using “certi-fied” blocks for the training phase. The results obtained with the loc-10 and loc-15 networks seem to indicate that the dif-ference between the redif-ference models (ref-10 and ref-15) and the models built using “certified” blocks (10 and cert-15) is half due to errors in location (Section 4.2.2) and half due to errors of lip-shape estimation. Finally, one can notice that the networks having 15 units in the hidden layer yield slightly higher global results than the ones with 10 units in the hidden layer.
6. SUMMARY AND DISCUSSION
In this paper, we have shown how to build statistical shape and appearance models of the lips without hand-labeling. The only drawback of the proposed method is the need for some of the subjects to utter at least part of the training cor-pus twice (once with a blue lip-enhancer). The shape model is easy to extend to more subjects, but may also be adapted to a specific recognition task (see [36]). The automatic appear-ance model is rather similar to the one obtained on the same corpus by manually labeling images and it is a lot more effi -cient than filtered red-hue. The shape and appearance mod-els presented here were used in a parallel and sequential way (appearance, then shape) to compare the efficiency of both approaches for audio-visual ASR in [36].
An important advantage of a statistical model like MLP over a red-hue function, is its adaptation capability: it should be adaptable to all subjects after training. To build a general speaker-independent appearance model, one should intro-duce in the training corpus subjects with different skin colors and/or facial hair (beard or moustaches), leaving the adapta-tion work to the ANN. Important attenadapta-tion should then be paid to the architecture of the network, to study more pre-cisely its impact on the adaptation capability.
ANN models can also adapt to previously unencountered data, and they may be used to extract visual speech infor-mation on speakers not present in the training corpus. We tested the three subject model described here on a fourth subject (the one studied in [36]), and the preliminary results are rather satisfying, although not entirely: ref-10 reaches 81.9% of correctlipclassification, with only 63.2% for global classification. When looking more precisely at the confu-sion matrix, it appears that this is due to the fact that the
inner-mouth class becomes highly confusable withlipsand
skin. For cert-10, results are 75.0% forlipsand only 58.1% globally, for the same reason. Somewhat surprisingly, net-works with 10 hidden units were adapting better to this sub-ject than those with 15 hidden units. However, even if perfor-mance is a little lower, the networks still model appearance better than filtered red-hue: considering lip versus non-lip classification, red-hue reaches only 55.6% with the same set-tings as in Section 2, on the manually labeled images of this subject. More experiments on appearance modeling will be carried in the near future to study cross-speaker adaptation of the models.
Another important issue we have discovered with sta-tistical lip appearance modeling is that pixel information is rather less discriminant than image blocks, and this should be taken into consideration by other researchers in the field. Combining a statistical model like ours with spatial (Zhang [29]) or temporal (Li´evin [14]) gradient information should yield a fairly robust appearance model of the lips.
Finally, the use of blue lipstick is not mandatory in our method, as it is not very convenient for speakers and can cause imperfections to the extracted shapes. If one has a very reliable lip-contour extraction system using another intru-sive method, it can be used instead. One may, for example, record the first set of sentences with an intrusive device such as a head-mounted camera, or with very intensive frontal lighting to avoid shadows, and then record the second rep-etition under more realistic conditions.
ACKNOWLEDGMENTS
The authors would like to thank the EURASIP Journal on Applied Signal Processing reviewers and the editor in charge of the Joint Audio-Visual Speech Processing special issue for their helpful comments in improving this paper.
REFERENCES
[1] A. Morris, A. Hagen, H. Glotin, and H. Bourlard, “Multi-stream adaptive evidence combination for noise robust ASR,” Speech Communication Journal, vol. 34, no. 1-2, pp. 25–40, 2001.
[2] I. Zitouni, K. Sma¨ıli, and J.-P. Haton, “Beyond the con-ventional statistical language models: the variable-length se-quences approach,” inProc. 6th International Conference on Spoken Language Processing (ICSLP), vol. 3, pp. 962–965, Bei-jing, China, October 2000.
[3] H. McGurk and J. McDonald, “Hearing lips and seeing voices,”Nature, vol. 264, pp. 746–748, December 1976. [4] C. Bregler, H. Hild, S. Manke, and A. Waibel, “Improving
connected letter recognition by lipreading,” in Proc. IEEE Int. Conf. Acoustics, Speech, Signal Processing, vol. 1, pp. 557– 560, Minneapolis, Minn, USA, April 1993.
[5] P. Duchnowski, M. Hunke, D. B¨usching, U. Meier, and A. Waibel, “Toward movement-invariant automatic lip-reading and speech recognition,” in Proc. IEEE Int. Conf. Acoustics, Speech, Signal Processing, vol. 1, pp. 109–112, De-troit, Mich, USA, May 1995.
European Conference on Computer Vision (ECCV), vol. 2, pp. 376–387, Cambridge, UK, April 1996.
[7] J. Luettin, N. A. Thacker, and S. W. Beet, “Active shape mod-els for visual speech feature extraction,” in Speechreading by Humans and Machines: Models, Systems, and Applications, D. G. Stork and M. E. Hennecke, Eds., vol. 150 ofNATO Ad-vanced Science Institutes, pp. 383–390, Springer-Verlag, New York, NY, USA, 1996.
[8] C. Neti, G. Potamianos, J. Luettin, et al., “Audio-visual speech recognition,” Tech. Rep. Workshop 2000, Center for Lan-guage and Speech Processing (CLSP), Johns Hopkins Univer-sity, Baltimore, Md, USA, October 2000.
[9] A. Rogozan and P. Del´eglise, “Adaptive fusion of acoustic and visual sources for automatic speech recognition,”Speech Com-munication Journal, vol. 26, no. 1-2, pp. 149–161, 1998. [10] R. Auckenthaler, J. Brand, J. S. D. Mason, F. Deravi, and C. C.
Chibelushi, “Lip signatures for automatic person recogni-tion,” inProc. 2nd International Conference on Audio- and Video-Based Biometric Person Authentification (AVBPA), pp. 142–147, Washington, DC, USA, March 1999.
[11] P. Jourlin, J. Luettin, D. Genoud, and H. Wassner, “Acoustic-labial speaker verification,” inProc. 1st International Confer-ence on Audio- and Video-Based Biometric Person Authentifi-cation (AVBPA), J. Big¨un, G. Chollet, and G. Borgefors, Eds., pp. 319–326, Springer-Verlag, Crans-Montana, Switzerland, March 1997.
[12] L. Girin, L. Varin, G. Feng, and J.-L. Schwartz, “A signal pro-cessing system for having the sound “pop-out” in noise thanks to the image of the speaker’s lips: New advances using multi-layer perceptrons,” inProc. 5th International Conference on Spoken Language Processing (ICSLP), vol. 4, pp. 1451–1454, Sydney, Australia, December 1998.
[13] U. Meier, R. Stiefelhagen, J. Yang, and A. Waibel, “Towards unrestricted lip reading,” inProc. 2nd International Conference on Multimodal Interfaces (ICMI), Hong Kong, 1999.
[14] M. Li´evin and F. Luthon, “Unsupervised lip segmentation under natural conditions,” inProc. IEEE Int. Conf. Acous-tics, Speech, Signal Processing (ICASSP), vol. 6, pp. 3065–3068, Phoenix, Ariz, USA, March 1999.
[15] C. Benoˆıt, T. Guiard-Marigny, B. Le Goff, and A. Adjoudani, “Which components of the face do humans and machines best speechread?,” inSpeechreading by Humans and Machines: Models, Systems, and Applications, D. G. Stork and M. E. Hen-necke, Eds., vol. 150 ofNATO Advanced Science Institutes, pp. 315–328, Springer-Verlag, New York, NY, USA, 1996. [16] C. Benoˆıt, “On the production and perception of audio-visual
speech by man and machine,” inMultimedia Communications and Video Coding, Y. Wang, S. Panwar, S.-P. Kim, and H. L. Bertoni, Eds., Plenum, New York, NY, USA, October 1995. [17] G. Potamianos, H. P. Graf, and E. Cosatto, “An image
transform approach for HMM based automatic lipreading,” in Proc. IEEE International Conference on Image Processing (ICIP), vol. 3, pp. 173–177, Chicago, Ill, USA, October 1998. [18] M. E. Hennecke, K. V. Prasad, and D. G. Stork, “Using
de-formable templates to infer visual speech dynamics,” in28th Annual Asilomar Conference on Signals, Systems, and Comput-ers, Pacific Grove, Calif, USA, November 1994.
[19] S. Horbelt and J.-L. Dugelay, “Active contours for lipreading: combining snakes with templates,” in15th GRETSI Sympo-sium Signal and Image Processing, pp. 717–720, Juan-les-Pins, France, September 1995.
[20] R. Kober, J. Schiffers, and K. Schmidt, “Model-based versus knowledge-guided representation of non-rigid objects: A case study,” inProc. IEEE International Conference on Image Pro-cessing, vol. 1, pp. 973–977, IEEE Computer Society Press, Los Alamitos, Calif, USA, 1994.
[21] B. Leroy, I. L. Herlin, and L. D. Cohen, “Face identification by deformation measure,” inProc. IEEE International Conference on Pattern Recognition (ICPR), vol. 3, pp. 633–637, Vienna, Austria, August 1996.
[22] K. F. Lai, C. W. Ngo, and S. Chan, “Tracking of deformable contours by synthesis and match,” inProc. IEEE International Conference on Pattern Recognition (ICPR), vol. 1, pp. 657–661, Vienna, Austria, August 1996.
[23] L. Rev´eret and C. Benoˆıt, “A new 3D lip model for analysis and synthesis of lip motion in speech production,” inProc. Auditory-Visual Speech Processing (AVSP), pp. 207–212, Terri-gal, Australia, December 1998.
[24] S. Basu, N. Oliver, and A. Pentland, “3D modeling and track-ing of human lip motion,” inProc. IEEE International Confer-ence on Computer Vision (ICCV), pp. 337–343, Bombay, India, January 1998.
[25] S. Dupont and J. Luettin, “Audio-visual speech modeling for continuous speech recognition,”IEEE Trans. Multimedia, vol. 2, no. 3, pp. 141–151, 2000.
[26] I. Matthews, T. Cootes, S. Cox, R. Harvey, and J. A. Bang-ham, “Lipreading using shape, shading and scale,” inProc. Auditory-Visual Speech Processing (AVSP), pp. 73–78, Terrigal, Australia, December 1998.
[27] T. Coianiz, L. Torresani, and B. Caprile, “2D deformable mod-els for visual speech analysis,” inSpeechreading by Humans and Machines: Models, Systems, and Applications, D. G. Stork and M. E. Hennecke, Eds., vol. 150 ofNATO Advanced Science Institutes, pp. 391–398, Springer-Verlag, New York, NY, USA, 1996.
[28] J. C. Wojdel and L. J. M. Rothkrantz, “Using aerial and geometric features in automatic lip-reading,” in Proc. 7th European Conference on Speech Communication and Technol-ogy (Eurospeech), vol. 4, pp. 2463–2466, Aalborg, Denmark, September 2001.
[29] X. Zhang, C. C. Broun, R. M. Mersereau, and M. Clements, “Automatic speechreading with applications to human-computer interfaces,”EURASIP Journal on Applied Signal Pro-cessing, vol. 2002, no. 11, pp. 1228–1247, 2002.
[30] R. Kaucic and A. Blake, “Accurate, real-time, unadorned lip tracking,” inProc. IEEE International Conference on Com-puter Vision (ICCV), pp. 370–375, Bombay, India, January 1998.
[31] J.-M. Odobez, Estimation, d´etection et segmentation du mou-vement: une approche robuste et Markovienne, Ph.D. thesis, Universit´e de Rennes I, December 1994.
[32] J. A. Nelder and R. Mead, “A simplex method for function minimization,”Computing Journal, vol. 7, no. 4, pp. 308–313, 1965.
[33] H. Sakoe and S. Chiba, “Dynamic programming algo-rithm optimization for spoken word recognition,” IEEE Trans. Acoustics, Speech, and Signal Processing, vol. 26, no. 1, pp. 43–49, 1978.
[34] P. Daubias, “Utilisation de l’information acoustique pour aligner deux s´equences de parole audiovisuelle,” inProc. 4th Rencontres Jeunes Chercheurs en Parole, pp. 74–77, Mons, Bel-gium, September 2001.
[35] R. Descout, J.-F. S´erignat, O. Cervantes, and R. Carr´e, “BD-SONS: Une base de donn´es des sons du franc¸ais,” inProc. 12th International Congress on Acoustics (ICA), Toronto, Canada, 1986.
Philippe Daubias was born in Le Mans (France) in 1972. He completed his Mas-ter’s thesis in computer science in Universit´e du Maine, France in 1996. He is now fin-ishing his Ph.D. on visual feature extraction for audio-visual automatic speech recogni-tion. His research interests include multi-media processing and statistical modeling.
Paul Del´eglisereceived his Ph.D. in com-puter science from the Pierre & Marie Curie University (Paris VI, France) in 1983 and his Doctorat D’´etat in 1991. He worked in the Signal Laboratory of the ´Ecole Na-tionale Sup´erieure des T´el´ecommunications (ENST) on automatic speech recognition from 1985 to 1992. Since October 1992, he is full professor at Universit´e du Maine