ISSN : 2394-2231
www.ijctjournal.org
Page 139
BPA: Bigdata Parallelism Algorithm for Distributed Machine Learning
Prajakta Ugile, Dr. S. B. Chaudhari
Savitribai Phule University of Pune,
Department of Computer Engineering JSPM, Hadapsar, Pune.
[email protected]
---
************************
---
Abstract:
Machine learning (ML) and applied math techniques are key to transforming huge information into unjust knowledge. In spite of the trendy importance of knowledge, the complexness of existing ML algorithms is usually overwhelming many users don't understand the trade-off and challenges of parameterizing what's a lot of, selecting between different learning procedures. Hide there more; existing elastic frameworks that facilitate machine learning are frequently not hospitable specialists with- out a solid foundation in spread frameworks and low-level Natives. To handle this draw back, this work organized vast info correspondence recursive commonplace for Distributed Machine Learning info correspondence is practiced once each processor plays out associate indistinguishable trip on numerous bits of disseminated knowledge. Exploitation distributed frameworks that parcel the huge info crosswise over machines and license every machine to see and refresh all ML demonstrate parameters. This system is believed as stupendous info correspondence. It offers the most effective truth with less execution time. Trial result demonstrates the organized BPA recursive principle applies machine learning calculations to vast info quickly. Also, it diminishes machine learning time and can expand machine learning speed
.
Keywords
—Big data, Machine Learning, Distributed system, Parallelism Algorithm.
---
************************
---
I.
INTRODUCTION
Machine Learning base system have a tendency to aim to form machine learning accessible to a broad audience of users and applicable to varied data corpora, starting from little to terribly massive knowledge sets. To achieve this goal, we offer here a style for MLbase along the lines of an info system, with four major foci. Mobile sensors, social media services, genomic sequencing, and natural philosophy are among a mess of applications that have generated Associate in nursing explosion of plentiful knowledge. Data is no longer requiring to only some of educational researchers or large web corporations. Instead of this, even among statistical machine learning, Associate in Nursing understanding of computational techniques for algorithmic rule choice and application is only getting down to seem. The complexness of existing algorithmic programs is overwhelming to layperson
system containing billions of parameters. Despite the actual fact that there exist suggests that and speculations to assist theory methodologies like subsampling information or utilizing very little models, there's a basic demand for sound and powerful circulated ML approaches for shoppers WHO can't be all around served by such straightforward routes. With the advancements in sensory, digital storage, and Internet communication technologies, conventional ML research and development which excel in algorithm. Several long periods of video transferred to video-sharing destinations every minute†, or petabytes of internet primarily based life on billion or a lot of
shopper social networks‡. The ascent of huge data is
in addition being joined by an increasing longing for higher-dimensional associated more and more unpredictable ML models with billions to trillions of parameters, therefore on facilitate the frequently increasing elaboration of knowledge, or to accumulate still higher prescient exactitude (e.g., for higher shopper administration and healthful analysis) what's a lot of, bolster more and more shrewd errands (e.g., driverless vehicles what's a lot of, linguistics understanding of video information)
Preparing such huge ML models over such huge info is past the capability and calculation capacities of a solitary machine. This hole has roused a developing assortment recently work on distributed metric capacity unit, wherever metric capacity unit programs are executed crosswise over analysis bunches, server farms, and cloud suppliers with tens to thousands of machines. Given P machines of one machine, one would expect associate virtually P-overlap hurrying within the time taken by a distributed metric capacity unit program to end, within the sense of accomplishing a scientifically identical or equivalent declare that delivered by a solitary machine; nonetheless, the discovered hurrying oft falls way at a lower place this imprint. For example, even current best in school executions of subject models (a well-known technique for content examination) can't accomplish two hurrying with four machines, on account of scientific error within the usage (as appeared in referee.), whereas profound learning on Map Reduce-like frameworks, as an example, Spark presently can't appear to accomplish five hurrying with ten machines [11]. Comprehending this versatility challenge is during this manner a motivating objective of taken
over metric capacity unit explore, so on diminish the capital and operational expense of running huge metric capacity unit applications. To unravel this draw back, this work projected huge information similarity formula for Distributed Machine Learning. This model is sometimes shared among all procedure nodes. A procedure node computes native update on its information set in each iteration thus submits the native update to the parameter server that updates the model parameters; the parameter server distributes the new international model parameters to each procedure node. Victimization distributed systems that partition the big information across machines and allow each machine to browse and update all model parameters.
II.
RELATED WORK
The core of MLbase is its optimizer that transforms a declarative metric capacity unit task into a sophisticated learning set up. Throughout this method, the optimizer tries to and a thought that quickly returns a first quality answer to the user, permitting MLbase to boost the result iteratively within the background. Moreover, MLbase is meant to be absolutely distributed, and it offers a run-time able to exploit the characteristics of machine learning algorithms. We are presently within the method of building the complete system. We tend to reported results showing the potential of the optimizer additionally because the performance blessings of algorithm-specific execution methods [1].
We give a programmable framework for dynamic huge Model-parallelism that provides the subsequent benefits: (i) quantifiability and economical memory utilization, permitting larger models to be run with extra machines; (ii) the flexibility to invoke dynamic schedules that cut back model parameter dependencies across staff, resulting in lower parallelization error and therefore quicker, correct convergence. A vital direction for future analysis would be to scale back the communication costs of exploitation STRADS. We have a tendency to conjointly wish to explore the employment of STRADS for alternative common ML applications, like support vector machines and logistical regression [2].
machine learning algorithms. We have a tendency to show that it's potential to style algorithms well suited to the present framework; during this case, AN asynchronous block proximal gradient methodology to resolve general non-convex and non-smooth issues, with obvious convergence. This algorithm could be a good match to the relaxations obtainable within the parameter server framework: governable desynchronization via task dependencies and user-definable filters to scale back digital communication volumes. We showed experiments for many difficult tasks on real datasets up to zero.6PB size with tons billions samples and options to demonstrate its potency. We have a tendency to believe that this third-generation parameter server is a vital and helpful building block for scalable machine learning [3].
MXNet may be a machine learning library combining symbolic expression with tensor computation to maximize potency and suppleness. It's light-weight and embeds in multiple host languages, and can be run during a distributed setting. Experimental results are encouraging. Whereas we tend to still explore new style selections, we tend to believe it will already profit the relevant analysis community. The methodology not just makes the information synchronization works consistent with calculation, and furthermore incredibly simplifies the execution. The preparation module usually utilized optimization calculations, for example, stochastic gradient descent [4].
An in depth summary of wildcat, including a dynamic compiler from PTX to Multi-core x86 CPUs. Through the study of wildcat victimization many micro benchmarks and full applications, on-chip memory pressure, context-switch overhead, and variable CTA execution time were identified as elementary problems that impact performance once compiling extremely parallel programs to systems with few hardware resources. Within the future, these problems can need to be addressed as systems still migrate towards many-core architectures, and developers obtain programming models that can scale to them. A model for the interpretation of unequivocally parallel bulk synchronous applications to a multi-threaded execution model [5].
The parameter server provides Associate in Nursing
easy-to-use shared interface for read/write access to Associate in Nursing mil model’s values (parameters and variables), and the SSP model permits distributed employees to browse older, stale versions of these values from a neighborhood cache, rather than waiting to urge them from a central storage. This considerably will increase the proportion of your time employees’ pay computing, as hostile waiting. We offer a facet impact of rightness beneath SSP, more as data-based outcomes exhibiting that the SSP display accomplishes speedier equation combination on various entirely distinctive mil problems, contrasted with utterly synchronous and way-out plans [6].
This paper studied 2 fashionable asynchronous parallel implementations for SG on pc cluster and shared memory system severally. 2 algorithms (ASYSG-CON and ASYSG-INCON) are used to describe 2 implementations. Associate degree straight line sub linear convergence rate is evidenced for both algorithms on nonconvex sleek improvement. This rate is according to the results of SG for lenticular improvement. The linear quickening is evidenced to realizable once the quantity of employees is delimited by
√
𝐾, that improves the sooner analysis of ASYSG-CON for lenticular improvement. The proposed ASYSG-INCON calculation gives a progressively exact depiction to lock free usage on shared memory framework [7].We gave associate degree increased illustration of the factorization downside that is amenable to distributed computation and we delineated 2 algorithms for optimizing the resulting objective perform. Our contributions are the following: we offer associate degree efficient rule for vertex partitioning the graph and demonstrate that it's vital. We tend to describe automatic task layout at runtime and show that it's efficient in apply. Asynchronous improvement is very beneficial for scalable inference, providing associate degree order of magnitude acceleration. We tend to perform factoring on one in every of the most important natural user graphs presently obtainable [8].
asynchronous random gradient descent. We have a tendency to divide the educational rate by the typical staleness of gradients, leading to quicker convergence and lower check error. The 1-softsync protocol (in that the parameter server accumulates gradients before change the weights) minimizes gradient staleness and achieves the lowest runtime for a given check error. We have a tendency to found that to take care of model accuracy, it's necessary to cut back the mini-batch size because the variety of learners is magnified. This means AN upper limit on the amount of correspondence that may be exploited for a given model, and consequently a requirement for algorithms that permit coaching over larger batch sizes [9].
We emphasize that for any specific downside, it's doubtless that another methodology can perform higher than ADMM, or that some variation on ADMM can considerably improve performance. However, a simple formula derived from basic ADMM can typically supply performance that is a minimum of equivalent to terribly specialized algorithm, and in most cases, the easy ADMM formula will be economical enough to be helpful. In an exceedingly few cases, ADMM-based strategies actually end up to be progressive even within the serial regime. Moreover, ADMM has the benefit of being very simple to implement, and it maps onto many customary distributed programming models reasonably well. ADMM was developed over a generation agony, with its roots stretching far ahead of the web, distributed and cloud computing systems, huge high-dimensional datasets, and also the associated large-scale applied math issues. Despite this, it seems to be suited to the fashionable regime, and has the necessary advantage of being quite general in its scope and pertinence [10].
III.
PROPOSED ALGORITHM
A. Description of the Proposed Algorithm:
1.
Load big data:
In this module, user load market basket big data set. This dataset contains too many transactions. Each transaction contains many items. The user wants to extract frequent item sets using big data parallelism algorithm. The user needs to extract frequent item sets victimization hugeknowledge similarity rule. After that dataset is send for partitioning.
2.
Partitioning:
In this module, the user split big data into n blocks. Using whole big data, we cannot apply machine learning algorithm directly. It takes more time for machine learning. So partition is necessary to handle big data in machine learning. Partitioned blocks send to different machine learning. Data is equally divided & then send it to the Distributed machine learning.Fig.1 Proposed System
3.
Distributed Machine Learning:
In this module, transmit each blocks to each machine for apply machine learning. In this structure, same tasks are performed on various parallel figuring processors on the dispersed information sub set. It centers around dispersing the information crosswise over various hubs, which work on the information in parallel. Here, we use frequent item set mining for machine learning. So each machine applies frequent item set mining and extracts all frequent itemset. This Bigdata similarity rule applies machine learning algorithms to huge knowledge with efficiency. It conjointly provides the very best accuracy with less execution time. Here, we tend to use frequent item set mining for machine learning. We tend to begin with the frequent itemset mining, that works by putting off most massive sets as hopefuls by taking a primary at smaller sets and perceiving that.frequent itemset mining and get the list of most frequent products. Also provide recommendation to the consumer by calculating their support count.
I. PSEUDOCODE
Big-data Parallelism Algorithm (BPA)
Step 1: Initialize
Step 2: Load Big-dataset
Step 3: Split Big-data into n blocks.
Step 4: Each block to each Computational node.
Step 5: Forward the data to each machine.
Step 6: Apply Machine Learning to build classifier
Step 7: Thenapply Frequent Itemset mining.
Step 8: The most frequent patterns generated.
Step 9: Forward that patterns to Parameter Server.
Step 10: Now take testing dataset
Step 11: Again Apply Frequent itemset mining.
Step 12: Combine all Machine Learning Results.
Step 13: End.
II. SIMULATIONRESULTS
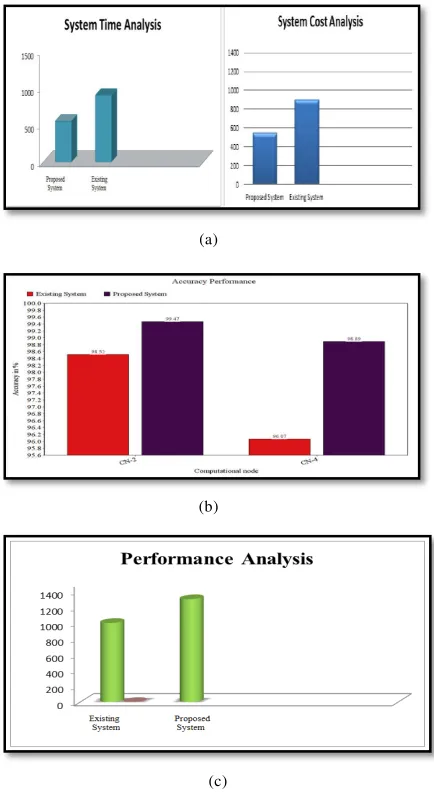
Tremendous Data is an articulation used to mean a massive volume of dual sorted out and unstructured data that is so significant it is difficult to process using customary database and programming procedures. In this module, client load advertise container data set. This dataset contains such a huge number of occurrences. Existing framework primary commitment is to demonstrate that for smooth stochastic issues, the deferrals are asymptotically insignificant and they can accomplish request ideal union outcomes. The model make the forecast for training occasions, the mistake is determined and moreover model is refreshed to decrease blunder for next prediction. It is infeasible when the preparation information estimate is immense. Subsequently in proposed framework we utilized frequent itemset. It chooses the best frequent example P to separate the information into two sets: one containing P and the other not. Training the circulated model with BPA can diminish the correspondence and synchronization costs and improve the business rate
of the strategy hubs and also the effectiveness of computation.
(a)
(b)
(c)
Fig. 2 Total system Performance analysis
better than existing system.
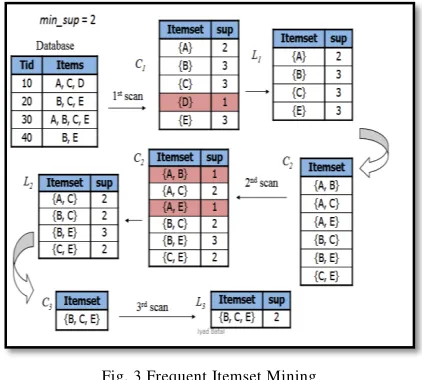
FREQUENT ITEMSET MINING:-
The assignment of finding every frequent set is very challenging. The hunt space is exponential in the quantity of things happening in the database and the focused on databases will in general be enormous, containing quantities of exchanges. Both these qualities try to look for the most productive methods to unravel this assignment. For the totally various things, their support counts are extraordinary. Rehash the strategy on every subset until a stopping condition is fulfilled. Visit itemset mining designs is in like manner when we considered number of things and from that compute their help check. At long last got the pattern, which is progressively valuable for proposal.
Fig. 3 Frequent Itemset Mining
III.CONCLUSIONANDFUTUREWORK
BPA can reduce the communication and synchronization cost. This dataset contains too many transactions. Each dealing contains many things. Due to the size, it takes longer for work model. To accommodate this disadvantage, the planned algorithm split huge info and distributes it into many procedure nodes. This algorithm applies in each procedure node and provides work results to parameter server. Moreover, parameter server applies another cn for collected Results from procedure nodes. Practice circulated frameworks that parcel the monstrous data crosswise over machines and enable each machine to peruse and
refresh every single model parameter. Coaching the distributed model with BPA can reduce the communication and synchronization costs and improve the employment rate of the procedure nodes and additionally the efficiency of calculation. For fully completely different item their support counts are different & come-at-able patterns together. Improve the utilization rate and the efficiency of calculation. Improves the performance of the distributed ML algorithm.
REFERENCES
[1] Tim Kraska, Ameet Talwalkar John Duchi, MLbase: A Distributed Machine-learning System, publication in the proceedings of CIDR, January 6-9, 2013.
[2] Seunghak Lee, Jin Kyu Kim, Xun Zheng, Qirong Ho, Garth A. Gibson and Eric P. Xing, On Model Parallelization and Scheduling Strategies for Distributed Machine Learning, Advances in Neural Information Processing Systems NIPS 2014.
[3] Mu Li, David G. Andersen, Alexander Smola and Kai Yu, Communication Efficient Distributed Machine Learning with the Parameter Server, Conference on Neural Information Processing Systems - Volume 1, December 08 - 13, 2014. [4] Tianqi Chen, Mu Li, Yutian Li, Min Lin, Naiyan
Wang and Minjie Wang, MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems ,volume 1512.01274, Dec 2015.
[5] Gregory Diamos, Andrew Kerr and Sudhakar Yalamanchili, Ocelot: A Dynamic Optimization Framework for Bulk-Synchronous Applications in Heterogeneous Systems, IEEE PACT10, Sept 1115, 2010.
[6] Qirong Ho, James Cipar, Henggang Cui, Jin Kyu Kim and Seunghak Lee, More Effective Distributed ML via a Stale Synchronous Parallel Parameter Server, Neural Information Processing Systems - Volume 1, December 2013.
[8] Ahmed, N. Shervashidze, S. Narayanamurthy, V. Josifovski, and A. J. Smola, Distributed large-scale natural graph factorization, in International Conference on World Wide Web, ser. International Conference on World Wide Web. Rio de Janeiro: ACM, 2013, pp. 3748.
[9] Stephen Boyd, Neal Parikh, Eric Chu, Borja Peleato and Jonathan Eckstein, Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers, in Machine Learning, January 2011.
[10]Suyog Gupta, Wei Zhang and Fei Wang, Model Accuracy and Runtime Tradeoff in Distributed Deep Learning: A Systematic Study, IEEE International Conference on Data Mining, Dec 2016.