夽This work was supported by the National Science Council of Taiwan under grant no. NSC86-2213-E-001-023.
*Corresponding author. Present address: Applied Research Laboratory, Telecommunication Laboratories, 12, Lane 551, Min-Tsu Road Sec. 5, Yang-Mei, Taoyuan, Taiwan 326, ROC. Tel.:#886-3-4244186; fax:#886-3-4244167.
E-mail address:[email protected] (C.-C. Han).
}
Fast face detection via morphology-based pre-processing
夽
Chin-Chuan Han
*
, Hong-Yuan Mark Liao , Gwo-Jong Yu
, Liang-Hua Chen
Institute of Information Science, Academia Sinica, Nankang, Taipei, Taiwan
Institute of Computer Science and Information Engineering, National Central University, Chung-Li, Taiwan
Department of Computer Science and Information Engineering, Fu Jen University, Taiwan
Received 5 November 1998
Abstract
An e$cient face detection algorithm which can detect multiple faces oriented in any directions in a cluttered environment is proposed. In this paper, a morphology-based technique is "rst devised to perform eye-analogue segmentation. Next, the previously located eye-analogue segments are used as guides to search for potential face regions. Then, each of these potential face images is normalized to a standard size and fed into a trained backpropagation neural network for identi"cation. In this detection system, the morphology-based eye-analogue segmentation process is able to reduce the background part of a cluttered image by up to 95%. This process signi"cantly speeds up the subsequent face detection procedure because only 5}10% of the regions of the original image remain for further processing. Experiments demonstrate that an approximately 94% success rate is reached, and that the relative false detection rate is very low. 2000 Published by Elsevier Science Ltd on behalf of Pattern Recognition Society.
Keywords:Face detection; Backpropagation neural network; Morphological opening/closing operation
1. Introduction
Human face detection and recognition have long been a di$cult research topic. In the last two decades, re-searchers have devoted much e!ort to these two prob-lems and have obtained some satisfactory results. Some of these previous e!orts were focused on face recognition [1}3]. Turk and Pentland [3] have successfully em-ployed the eigenface approach to recognize a human face. However, an accurate and e$cient method for human face detection is still lacking. Govindaraju et al. [4,5] presented a system which could locate human faces in photographs of newspapers, but the approximate size
and expected number of faces must be known in advance. Sirohey [6] utilized an elliptical structure to segment human heads from cluttered images. Yang and Huang [7] utilized a three-level hierarchical knowledge-based method to locate human faces in complex backgrounds. Sung and Poggio [8}10] applied two distance metrics to measure the distance between the input image and the cluster center. Twelve clusters including six face and six non-face clusters were trained using a modi"edk-mean clustering technique. A feature vector consisting of 12 values was input into a multi-layer perceptron network for the veri"cation task. Pentland et al. [11}16] applied principal component analysis (PCA) to describe face pat-terns with lower dimensional features. They designed a distance function calleddistance from feature space(d+s) as a metric to evaluate the di!erence between the input face image and the reconstructed face image. The system can be considered a special case of Sung and Poggio's system.
Face detection can also be achieved by detecting geo-metrical relationships among facial components such as the nose, eyes, and mouth. Juell and Marsh [17] proposed a hierarchical neural network to detect human 0031-3203/00/$20.00 2000 Published by Elsevier Science Ltd on behalf of Pattern Recognition Society.
faces in gray scale images. An edge enhancing pre-proces-sor and four backpropagation neural networks arranged in a hierarchical structure were devised to"nd multiple faces in a scene. Leung et al. [18}20] combined a set of local feature detectors via a statistical model to"nd facial components for face locating. Their approach was invari-ant with respect to translation, rotation, and scale. In addition, they could also handle partial occlusion of faces. Instead of the gray scale images, Sobottka and Pitas [21], and Chen et al. [22}25] located the poses of human faces and facial features from color images. In Ref. [21], the oval shape of a face could be approximated by an ellipse in Hue-Saturation-Value (HSV) color space. Chen et al. [22}25] proposed a skin color distribution function on perceptually uniform color space to detect a face-like region. The skin color regions in color images were modeled as several 2-D patterns and veri"ed with a built face model by using a fuzzy pattern matching approach.
Most of the above-mentioned systems limit themselves to dealing with human faces in frontal view. That is, the orientation problem, which is a potential trouble in this type of system, was not seriously considered. Further-more, some previous approaches slid a small window (20;20) over all the portions of an image at various scales. This brute force search is, no doubt, a time-consuming procedure. Jeng et al. [26] used a geometrical face model to solve the above-mentioned problem. In their method, the geometrical face template was used to precisely locate faces in a cluttered image. The average execution time used in locating a face using a Sparc-20 machine was less than 5 s. However, the major draw-backs of their approach are: (1) the size of a face must be larger than 80;80 and (2) the accuracy of using a geo-metrical face model may be signi"cantly in#uenced by changes of the lighting conditions.
In this paper, an e$cient face detection system is proposed. The proposed system consists of three main steps. In the"rst step, a morphology-based technique is devised to perform eye-analogue segmentation. Mor-phological operations are applied to locate eye-analogue pixels in the original image. Then, a labeling process is executed to generate eye-analogue segments. In the sec-ond step, the previously located eye-analogue segments are used as guides to search for potential face regions. A face region is temporarily marked if a possible geometri-cal combination of eyes, nose, eyebrows, and mouth exists. Of course, this step is a relatively loose process because we do not intend to miss any candidate faces. Therefore, this step may result in numerous face candi-dates, including both true faces and false ones. The last step of the proposed system is to perform face veri" ca-tion. Face veri"cation here includes identifying faces and locating their corresponding poses. In this step, every face candidate obtained from the previous step is nor-malized to a 20;20 image. Then, each of these
nor-malized potential face images is fed into a trained back-propagation neural network for identi"cation. Among the identi"ed true faces, it is possible that a face is simultaneously covered by multiple windows which are partially overlapped and oriented in various directions. Under the circumstances, the correct pose of the face is located by optimizing a cost function. The proposed face detection technique may locate multiple faces oriented in any direction. Furthermore, the morphology-based eye-analogue segmentation process is able to reduce the background part of a cluttered image by up to 95%. This process signi"cantly speeds up the subsequent face detec-tion procedure because only 5}10% of the regions of the original image remain for further processing. In the ex-periments, we used 122 cluttered images which contained a total of 130 faces to test the e!ectiveness of the pro-posed method. 122 faces (approximately 94%) were suc-cessfully located, and the false detection rate was very low. On average, our algorithm required 20 s to"nish the detection task on a 512;340 test image. Therefore, the proposed approach is indeed an e$cient technique for face detection.
The rest of this paper is organized as follows. The extraction of eye-analogue regions using morphological operations is described in Section 2. In Section 3, eye-pairs and normalized images are generated based on some geometric rules. A neural network-based veri"er and ad+sfunction are presented in Section 4 to verify the face region. Some experimental results to show the valid-ity of our detection system are given in Section 5. Finally, concluding remarks are given in Section 6.
2. Eye-analogue segmentation
As mentioned in Refs. [26,27], the eyebrows, eyes, nostrils and mouth always look darker than the rest of the face. Among these facial features, the degree of dark-ness of the eyebrows is dependent on the density or color, and that of the nostrils depends on how they are oc-cluded. As to the shape of a mouth, it frequently varies in appearance and size due to facial expressions. In com-parison with the above-mentioned unstable facial fea-tures, the eyes can be considered a salient and relatively stable feature of faces. Therefore, in this section we pro-pose a morphology-based method to locate the eye-analogue segments as the"rst step of our system. The eye-analogue pixels in a cluttered image are segmented "rst. Then, the small segments of the eye-analogue regions are grouped together using conditional mor-phological dilation operations and labeled using a tradi-tional labeling process.
In 1993, Chow and Li [27] employed a morphological opening residueoperation to extract the intensity valleys as potential eye-analogue pixels via a 5;5 circle struc-turing element. In our approach, we apply morphological
closing and clipped di!erent operations to "nd the candidate eye-analogue pixels. Let X be the original image andXM be the image with scaleo. A horizontal structuring element S
F with size 1;7 and a vertical
structuring elementS
T with size 7;1 are, respectively,
operated on X and X. It is known that [27] eye-analogue pixels are located in intensity valleys whose sizes are smaller than a preset value. Therefore, by mixing closing (z), clipped di!erent ( ), thresholding (T), and OR (R) into di!erent operations, the eye-analogue pixels in an image can be located. The set of operations which is able to identify eye-analogue pixels is expressed as fol-lows: E "¹ (X (XzSF)), E "¹ (X (XzSF)), E "¹ (X (XzST)), E "¹ (X (XzST)), E"E RERERE, (1) where the superscript, 2, ofE
andEis used to enlarge them to twice the original size.¹
,¹ ,¹
, and¹ are four threshold functions whose values are the aver-age values of the imaver-agesE
,E,E, andE, respectively. As mentioned in the previous paragraph, the eye-analogue pixels are located in the intensity valleys. How-ever, when the scene is complex, some pixels of this kind may not be eye-analogue pixels. For instance, text char-acters on a notice board, frames of windows, edges among a set of text books, etc., are frequently segmented as eye-analogue pixels via the operations in Eq. (1). Basic-ally, these pixels can be considered as noise in facial images. Therefore, we apply the conditional morphologi-cal dilation operation at this stage to remove these unwanted pixels from the background. Then, a con-ventional labeling process is performed to locate the eye-analogue segments. The eye-analogue detection algorithm is described in detail below.
Eye-analogue detection algorithm:
Step 1: Perform a labeling process on imageE, and compute a set of geometrical data from each segment including the lengths of the major and minor axes, the orientation, the center point, and the minimal bounding rectangle.
Step 2: If the length of the major axis of segmentiis larger than 0.6N(whereNis the width of the smallest face regions which we can detect), terminate the conditional dilation operation for segmenti, and eliminate segment ifrom imageE. Otherwise, go to the next step.
Step 3: Perform a conditional dilation operation on every segment i using the structuring element
SE"+1
VW"(x,y)3Z,, where
1. if segmentiis a horizontal segment, i.e., the orienta-tion of segment i is located at [!p/8 to p/8], the structuring element SE is assigned as +1
\, 1
, 1,;
2. if segmentiis a left slant segment, i.e., the orientation of segmentiis located at (!p/8 to!3p/8], choose the element+1
\, 1, 1\, 1\,1,as the structuring elementSE;
3. if segmentiis a right slant segment, i.e., the orientation of segmentiis located at (p/8 to 3p/8], the structuring elementSEis de"ned as+1
\\, 1, 1, 1\, 1
,;
4. if segmentiis a vertical segment, i.e., the orientation of segmentiis located at (!3p/8 to!4p/8] or (3p/8 to 4p/8], choose the element+1
\, 1, 1,as the structuring elementSE.
Step 4: Repeat steps 1}3 forN/5 times. Here,N/5 is an approximately estimated value of the nearest distance between two eyes in the smallest detected face regions.
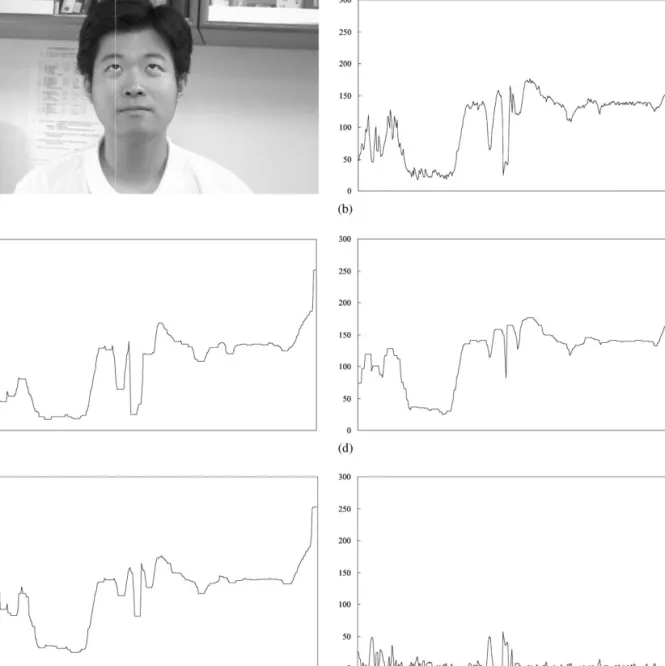
An example demonstrating the eye-analogue segmen-tation process is shown in Figs. 1 and 2. Fig. 1(a) is a gray scale image. The pro"le signals of the dashed line in Fig. 1(a) are shown in Fig. 1(b). After the erosion, dila-tion, and closing operations, the resultant signals are displayed in Figs. 1(c), (d), and (e), respectively. Finally, the signals obtained by executing the clipped di!erent operation between the original signal (Fig. 1(a)) and the closing signal (Fig. 1(e)) are depicted in Fig. 1(f ). In sum, after performing the operations shown in Eq. (1), the potential eye-analogue regions of Fig. 1(a) are shown in Fig. 2(a). After performing the conditional dilation and a labeling process on the potential eye-analogue seg-ments in Fig. 2(a), the located eye-analogue segseg-ments with bounding rectangles are those shown in Fig. 2(b). One thing to be noted is that the text characters in the notice board (Fig. 2(a)) merged together to form fewer segments. The main advantage of the two above-men-tioned processes is that those non-eye-analogue segments whose sizes are small are combined. These processes reduce the number of potential eye-analogue segments.
3. Finding potential eye-pairs from eye-analogue segments
As stated in Section 2, the eyes are considered the primary features in a face image. After performing the segmentation process, each eye-analogue segment can be considered a candidate of one of the eyes. In this section, we propose four matching rules to guide the merging of potential eye-analogue segments into pairs. Then, based on these potential eye pairs, the potential poses of the face regions are determined.
Fig. 1. The morphological operation process. (a) The original image, (b) the pro"le signals of the dash line in (a), (c) the signals after performing the erosion operation, (d) the signals after performing the dilation operation, (e) the signals after performing the closing operation, and (f) the signals after performing the closing and clipped di!erent operations.
Suppose that there are Meye-analogue segments in image E; at most M potential combinations of face regions are generated via the matched eye pairs. In order to reduce the execution time, the geometrical constraint on a real eye pair is introduced to screen out some impossible pairs. In Ref. [17], Juell and Marsh used a 19;11 window to"nd the location of the eyes. They assumed that the ratio between the width and the height of an eye is roughly about 2. In what follows, a set of rules
is proposed to merge those previously desired eye-ana-logue segments into potential eye pairs.
Matching rules
(a) The length ratio between the major and the minor axes of segment i must be smaller than 10.Here, the threshold value of the length ratio is set to 10 and should be larger than 2 to tolerate segmentation errors.
Fig. 2. The eye-analogue segmentation results. (a) The eye-analogue pixels and segments after the closing and clipped di!erent operations, (b) the eye-analogue segments after the conditional dilation and labeling processes.
(b) The distance between the center points of two eye-analogue segments must be larger than0.6N. Here, the value 0.6 is a rough estimate of the ratio between the distance between the two pupils of eyes and the width of a face, andNis the shortest width of a face. This value can be derived from the training samples. (c) Each eye must be located by extending a small range from the other eyeas shown in Fig. 3(a). Since two eyes can be located using their base line, they will be oriented co-linearly even if the face is rotated. (d) The area of segment i should be larger than0.01N2
pixels. Generally, the area of an eye pair in compari-son with the whole face region is about 0.1. Here, the threshold value 0.01 is smaller than 0.1. for the toleration of segmentation error.
Once the potential eye pairs are determined, their corresponding face regions can be easily extracted and each of these faces will be normalized into the 20;20 standard size. As shown in Fig. 3(b), (x
G,yG) and (xH,yH)
are two center points of segment i andj, respectively. (x
,y), (x,y), (x,y), and (x,y) are four corner points of a normalized face region. Let x
G#x H"A, x G!x H"B, andy G!y
H"C. The coordinates of the four corner points can be calculated as follows:
x " 1 2A! c c B# c c C, y "1 2A! c c C!c c B, x "1 2A# c c B#c c C, y " 1 2A# c c C! c c B, x " 1 2A! c c B# c c C, y " 1 2A! c c C! c c B, x "1 2A# c c B#c c C, y "1 2A# c c C!c c B, (2) wherec
is the average distance between the two pupils of the eyes, andc
is one half of the width of a face region. Furthermore, c
and c are, respectively, the distances from the base line of the two eyes to the top and bottom boundaries of a face region (see Fig. 3(b).) From the training samples used in the experiments,c
,c,c, and c
are, respectively, 12.5, 10, 4, and 16 in a normalized 20;20 face image. Based on these geometrical relations, a face region can be easily rotated and normalized. In Fig. 3(c), the potential eye pairs which satisfy the match-ing rules are linked via solid line segments. Accordmatch-ing to Eq. (2), the potential face regions which cover the poten-tial eye pairs in Fig. 3(c) have been extracted and nor-malized to the 20;20 standard size. These normalized potential face regions are shown in Fig. 3(d).
4. Face veri5cation
In the previous section, we have selected a set of potential face regions in an image. These potential face regions are allowed to have di!erent sizes and orienta-tions. However, after the normalization process, all po-tential faces are normalized to a"xed size, i.e., 20;20, and rotated into frontal position. In this section, we
Fig. 3. The extraction of face region. (a) The matching rule (c), (b) the geometrical relationship of face region, (c) the potential eye pairs of Fig. 1(c), (d) the potential face regions.
propose a coarse-to-"ne face veri"cation process to lo-cate the real positions of faces in an image. In coarse veri"cation, a trained backpropagation neural network [28] is applied to decide whether a potential region contains a face. Before the neural network is applied to execute coarse veri"cation, a preprocessing step which is similar to the work of Sung and Poggio [8], and Rowley et al. [28] has to be performed"rst. The preprocessing step consists of masking, illumination gradient correc-tion, and histogram equalization. The trained back-propagation net is then applied to "lter out those non-face regions. If the neural network outputs a positive response, the potential region may contain a face. Other-wise, this region will be eliminated from the potential candidate face list. Basically, this step can"lter out part of the non-face regions and we thus call it coarse
veri-"cation. In the"ne veri"cation process, we apply a cost function, d+s, proposed by Moghaddam and Pentland [14,15] to perform "nal selection. In what follows, the detailed procedure, from coarse to"ne, will be described. To train the neural networks, a technique similar to the one reported in Ref. [28] is adopted. A set of 11 200 face images generated from 700 face samples are collected as the positive samples by randomly, slightly rotating (up to 103), scaling (90}110%), translating (up to half a pixel), and mirroring. As mentioned by Rowley et al. [28], it is di$cult to characterize the prototype of non-face images because of the huge size of non-face images. Therefore, the network training task on non-face images is basically a di$cult one. Sung and Poggio's work [8] conformed this point. They collected 4000 positive (face) samples and 47 500 negative (non-face) samples to train their
network. It is obvious that the latter is much larger than the former. For reducing the number of non-face training samples, Rowley et al. [28] used the bootstrap algorithm to train the network. In their experiment, 16 000 positive and only 8000 negative face samples were used. For the non-face training samples, they repeated a bootstrap algorithm to collect the wanted data from 146 212 178 subimages that were available from all loca-tions and scales in the training scenery images. Therefore, it requires signi"cant computation time spent on train-ing. Here, we modify their bootstrap algorithm as fol-lows:
1. Create an initial set of non-face images by generating 1000 images with random intensities. Apply the pre-processing steps to each of these images. Initially, the network's weights are randomly initialized. Train a neural network to produce an output of 1 for the face samples and!1 for the non-face samples.
2. Run the system on 20 scenery images which contain no faces. Collect the subimages that the network in-correctly identi"es as faces. Select 250 of these sub-images as non-face samples.
3. Apply the preprocessing steps to the collected face and non-face samples. Then, retrain the network to obtain a new version of the face veri"er.
The major di!erence between our training process and Rowley's is the non-face sample collection process. In our system, 5000 non-face images are directly collected from 20 scenery images as negative samples. Therefore, only one training phase is needed in our scheme. This is the major di!erence between Rowley's approach and ours. In the recall process, if the trained neural network outputs a positive response, it means that there exists a face in the region being checked. If a negative response is received, the region being checked is considered a non-face region. In terms of performance, our neural network may not be as good as that of Rowley's. However, the coarse veri" ca-tion process using neural networks can"lter out a signi" -cant number of non-face regions. Although some of the non-face regions are retained due to the loose constraints used in the coarse veri"cation process, they can be de-leted in the"ne veri"cation process. Further, some over-lapping candidate faces are retained simultaneously and, therefore, require further checking. In the"ne veri"cation process, an evaluation function proposed by Moghad-dam and Pentland [14,15] is applied to eliminate the above-mentioned overlapping detections as well as those previously retained non-face regions. The evaluation function is called the residual reconstruction error, which is de"ned as follows: e" , G+> y G"""x!x ""!+ G y G, (3)
whereNis the size of an imagexwhich is to be checked, andMis the number of principal components used to reconstruct the original images. Since thed+svalue de-notes the di!erence between the input image and the reconstructed image via PCA, one has to choose the region with positive response and the local smallestd+s value as a face region. Once a face region is con"rmed, the last step is to eliminate those regions that overlap with the chosen face region.
5. Experimental results and discussion
A set of experimental results will be used to show the e!ectiveness and e$ciency of the proposed system. 122 test images containing totally 130 faces were used to test the validity of our system. All the test images were of size 512;339. In these test images, all the human faces were oriented in various directions and positioned arbitrarily in cluttered backgrounds. In this research, the minimum size of a face which could be detected was 50;50.
Fig. 4(a)}(j) show 10 test images which have correct detection results. The bounding rectangle that bounds a face region is used to justify whether the detection is correct or not. Among the successful cases, Fig. 4(b) demonstrates that the proposed method could detect faces with facial expressions. The case shown in Fig. 4(c) shows that the illumination problem could also be solved by our approach. One thing worth noticing is that the test image shown in Fig. 4(f ) contains two faces with a nearly 1803 di!erence; it is obvious that our system worked perfectly in dealing with this kind of problem. For an overall evaluation, 122 faces were detec-ted successfully out of the total of 130 faces. Therefore, the success rate for detecting face was roughly about 94%. On the other hand, the proposed system also detec-ted a total of 25 false faces from the cluttered back-grounds of the test images. Fig. 5 shows unsuccessful detection including false faces (the left bounding rec-tangle of Fig. 5(a)), missed faces (the right-hand side face of Fig. 5(b)), and inclined detected faces (the right bound-ing rectangle of Fig. 5(a)). There are three possible causes of the mis-detection problem. First, the size of a face to be detected has to be larger than 50;50. If the size of a face region was smaller than 50;50 as shown in Fig. 5(a), the system failed to detect it. The second cause of mis-detec-tion is missing eye pairs. If a potential eye pair which corresponds to a true face was not found, it was imposs-ible to further locate the exact pose of this face. Fortunately, the above-mentioned situation did not happen very often. In our experiments, only the mis-detection of the face in the right-hand side of Fig. 5(b) occurred for this reason. There is another reason for the mis-detection problem. As shown in Fig. 5(c), a partially occluded face was mis-detected. In the future, we shall extend the capability of the system to deal with partially
Fig. 4. Testing examples. occluded faces as well as to handle faces with sizes
small-er than 50;50.
As to the execution time problem, the time required to locate the precise locations of the faces in the test image set was dependent upon the size and complexity of the images. For example, a 512;340 image shown in Fig. 4(e) required less than 18 s for location of the correct face position using a Sparc 20 SUN workstation. For the
case shown in Fig. 4(f ), the execution time under the same environment was about 23 s.
6. Concluding remarks
In this paper, we have proposed an e$cient face detec-tion algorithm to"nd multiple faces in cluttered images.
Fig. 4. (Continued.)
In the"rst stage, morphological operations and a label-ing process are performed to obtain the eye-analogue segments. Based on some matching rules and the geo-metrical relationship of the parts of a face, eye-analogue segments are grouped into pairs and used to locate
po-tential face regions. Finally, the popo-tential face regions are veri"ed via a trained neural network, and true faces are determined by optimizing a distance function. Since the morphology-based eye-analogue segmentation pro-cess can e$ciently locate potential eye-analogue regions,
Fig. 5. The mis-detected examples.
the subsequent processing has to deal only with 5}10% of the area of the original image. Therefore, the execution time is much less than that of most existing systems. Furthermore, the proposed system can detect faces in arbitrary orientations and scales as long as the images are larger than 50;50.
7. Summary
An e$cient face detection algorithm which can detect multiple faces in a cluttered environment is proposed. The proposed system consists of three main steps. In the "rst step, a morphology-based technique is devised to perform eye-analogue segmentation. In a gray image, the eyebrows, eyes, nostrils and mouth always look darker than the rest of a face. Among these facial features, the eyes can be considered a salient and relatively stable feature than the other facial organs. Morphological op-erations are applied to locate eye-analogue pixels in the original image. Then, a labeling process is executed to generate the eye-analogue segments. In the second step, the previously located eye-analogue segments are used as
guides to search for potential face regions. Suppose that there areMeye-analogue segments in imageE; at most Mpotential combinations of face regions are generated via the matched eye pairs. In order to reduce the execu-tion time, the geometrical constraint on a real eye pair is introduced to screen out some impossible pairs. Once the potential eye pairs are determined, their corresponding face regions can be easily extracted. The last step of the proposed system is to perform face veri"cation. In this step, every face candidate obtained from the previous step is normalized to a standard size. Then, each of these normalized potential face images is fed into a trained backpropagation neural network for identi"cation. After all the true faces are identi"ed, their corresponding poses are located based on guidance obtained by optimizing a cost function. The proposed face detection technique can locate multiple faces oriented in any directions. Fur-thermore, the morphology-based eye-analogue segmen-tation process is able to reduce the background part of a cluttered image by up to 95%. This process signi" -cantly speeds up the subsequent face detection procedure because only 5}10% of the regions of the original image remain for further processing. Experiments demonstrate
that approximately 94% success rate is reached, and that the relative false detection rate is very low.
References
[1] M.A. Shackleton, W.J. Welsh, Classi"cation of facial fea-tures for recognition, Proceedings of Computer Vision and Pattern Recognition, Lahaina, Maui, Hawaii, June 1991, pp. 573}579.
[2] R. Brunelli, T. Poggio, Face recognition: features versus templates, IEEE Trans. Pattern Anal. Mach. Intell. 15 (10) (1993) 1042}1052.
[3] M. Turk, A. Pentland, Eigenfaces for recognition, J. Cogni-tive Neurosci. 3 (1) (1991) 71}86.
[4] V. Govindaraju, D.B. Sher, R.K. Srihari, Locating human face in newspaper photographs, Proceedings of Computer Vision and Pattern Recognition, San Diego, CA, June 1989.
[5] V. Govindaraju, S.N. Srihari, D.B. Sher, A computational model for face location, Proceedings of Computer Vision and Pattern Recognition, 1990, pp. 718}721.
[6] S.A. Sirohey, Human face segmentation and identi"cation, Master's Thesis, University of Maryland, 1993.
[7] G. Yang, T.S. Huang, Human face detection in a complex background, Pattern Recognition 27 (1) (1994) 53}63. [8] K.K. Sung, T. Poggio, Example-based learning for
view-based human face detection, Technical Report, Arti"cial Intelligence Laboratory, Massachusetts Institute of Tech-nology, December 1994.
[9] K.K. Sung, Learning and example selection for object and pattern detection, Ph.D. Thesis, MIT, 1996. anonymous ftp from publications.ai.mit.edu.
[10] K.K. Sung, T. Poggio, Example-based learning for view-based human face detection, IEEE Trans. Pattern Anal. Mach. Intell. 20 (1998) 39}51.
[11] A. Pentland, B. Moghaddam, T. Starner, View-based and modular eigenspaces for face recognition, IEEE Confer-ence on Computer Vision and Pattern Recognition, Seattle, WA, June 1994, pp. 84}91.
[12] B. Moghaddam, A. Pentland, Face recognition using view-based and modular eigenspaces, Proceedings of Automatic Systems for the Identi"cation and Inspection of Humans, SPIE, July 1994.
[13] B. Moghaddam, A. Pentland, Probabilistic visual learning for object detection, Proceedings of the"fth International Conference on Computer Vision, Cambridge, MA, June 1995, pp. 786}793.
[14] B. Moghaddam, A. Pentland, An automatic system for model-based coding of faces, Proceedings of IEEE
Data Compression Conference, Snowbird, Utah, March 1995.
[15] B. Moghaddam, A. Pentland, A subspace method for maximum likelihood target detection, Proceedings of IEEE International Conference on Image Processing, Washington DC, October 1995.
[16] T. Darrel, B. Moghaddam, A.P. Pentland, Active face tracking and pose estimation in an interactive room, Pro-ceedings of Computer Vision and Pattern Recognition, San Francisco, CA, June 1996, pp. 67}72.
[17] P. Juell, R. Marsh, A hierarchical neural network for human face detection, Pattern Recognition 29 (5) (1996) 781}787.
[18] T.K. Leung, M.C. Burl, P. Perona, Finding faces in clus-tered scenes using random labeled graph matching, Pro-ceedings of Computer Vision and Pattern Recognition, Cambridge, MA, June 1995, pp. 637}644.
[19] M.C. Burl, T.K. Leung, P. Perona, Face localization via shape statistics, Proceedings of Internal Workshop on Automatic Face and Gesture Recognition, 1995. [20] M.C. Burl, P. Perona, Recognition of planar object classes,
Proceedings of Computer Vision and Pattern Recognition, San Francisco, CA, June 1996, pp. 223}230.
[21] K. Sobottka, I. Pitas, Extraction of facial regions and features using color and shape information, Proceedings of 13th International Conference on Pattern Recognition, Vienna, Austria, August 1996, pp. 421}425.
[22] Q. Chen, H. Wu, M. Yachida, Face detection by fuzzy pattern matching, Proceedings of Computer Vision and Pattern Recognition, Cambridge, MA, June 1995, pp. 591}595.
[23] S. Chen, M. Haralick, Recursive erosion, dilation, opening, and closing transforms, IEEE Trans. Image Process. 4 (1995) 335}345.
[24] H. Wu, Q. Chen, M. Yachida, A fuzzy-theory-based face detector, Proceedings of the 13th International Conference on Pattern Recognition, Vienna, Austria, August 1996, pp. 406}410.
[25] H. Wu, Q. Chen, M. Yachida, Facial feature extraction and face recognition, Proceedings of the 13th International Conference on Pattern Recognition, Vienna, Austria, Au-gust 1996, pp. 484}488.
[26] S.H. Jeng, H.Y.M. Liao, C.C. Han, M.Y. Chern, Y.T. Liu, Facial feature detection using geometrical face model: an e$cient approach, Pattern Recognition 31 (1998) 273}282. [27] G. Chow, X. Li, Towards a system for automatic facial feature detection, Pattern Recognition 26 (12) (1993) 1739}1755.
[28] H.A. Rowley, S. Baluja, T. Kanade, Neural network-based face detection, IEEE Trans. Pattern Anal. Mach. Intell. 20 (1998) 23}38.
About the Author*CHIN-CHUAN HAN received the B.S. degree in Computer Engineering from National Chiao-Tung University in 1989, and an M.S. and a Ph.D. degree in Computer Science and Electronic Engineering from National Central University in 1991 and 1994, respectively. From 1995 to 1998, he was a Postdoctoral Fellow in the Institute of Information Science, Academia Sinica, Taipei, Taiwan. He is currently an Assistant Research Fellow in the Applied Research Lab., Telecommunication Laboratories, Chunghwa Telecom Co. His research interests are in the areas of 2D image analysis, computer vision, and pattern recognition.
About the Author*HONG-YUAN MARK LIAO received a B.S. degree in Physics from National Tsing-Hua University in 1981, and an M.S. and a Ph.D. degree in Electrical Engineering from Northwestern University in 1985 and 1990, respectively. He is currently
a Research Fellow in the Institute of Information Science, Academia Sinica, Taipei, Taiwan. He is also a member of the IEEE Computer Society and the International Neural Network Society (INNS). His current research interest includes neural networks, computer vision, fuzzy logic, and image analysis.
About the Author*GWO-JONG YU was born in Keelung, Taiwan in 1967. He received the B.S. Degree in Information Computer Engineering from the Chung-Yuan Christian University, Chung-Li, Taiwan in 1989. He is currently working toward the Ph.D. Degree in Computer Science. His research interests include face recognition, statistical pattern recognition and neural networks.
About the Author*LIANG-HUA CHEN received the B.S. degree in Information Engineering from National Taiwan University, Taipei, Taiwan, ROC, in 1983, the M.S. degree in Computer Science from Columbia University, New York, NY, in 1988, and the Ph.D. degree in computer science from Northwestern University, Evanston, IL, in 1992. He is currently an Associate Professor in the Department of Computer Science and Information Engineering, Fu Jen University, Taipei. His research interests include computer vision and pattern recognition.