Optimizing Mining Association Rules for
Artificial Immune System based
Classification
SAMEER DIXIT1, GAJENDRA SINGH CHANDEL2
1
Master of Engineering (student), 2 Assistant Professor Department of Computer Science and Engineering
Sri Satya Sai Institute of Science and Technology, Sehore, Bhopal, MP, India
Abstract- The primary function of a biological immune system is to protect the body from foreign molecules known as antigens. It has great pattern recognition capability that may be used to distinguish between foreign cells entering the body (non-self or antigen) and the body cells (self). Immune systems have many characteristics such as uniqueness, autonomous, recognition of foreigners, distributed detection, and noise tolerance . Inspired by biological immune systems, Artificial Immune Systems have emerged during the last decade. They are incited by many researchers to design and build immune-based models for a variety of applicationdomains. Artificial immune systems can be defined as a computational paradigm that is inspired by theoretical immunology, observed immune functions, principles and mechanisms. Association rule mining is one of the most important and well researched techniques of data mining. The goal of association rules is to extract interesting correlations, frequent patterns, associations or casual structures among sets of items in the transaction databases or other data repositories. Association rules are widely used in various areas such as inventory control, telecommunication networks, intelligent decision making, market analysis and risk management etc. Apriori is the most widely used algorithm for mining the association rules. Other popular association rule mining algorithms are frequent pattern (FP) growth, Eclat, dynamic itemset counting (DIC) etc. Associative classification uses association rule mining in the rule discovery process to predict the class labels of the data. This technique has shown great promise over many other classification techniques. Associative classification also integrates the process of rule discovery and classification to build the classifier for the purpose of prediction. The main problem with the associative classification approach is the discovery of high quality association rules in a very large space of candidate rules and incorporating these rules in the classification process. The rule search process is also computationally expensive for the small support threshold values which plays very important role in building an accurate classifier.The artificial immune system (AIS) uses powerful information capabilities of the immune system such as feature extraction, learning pattern recognition etc. The clonal selection algorithm of artificial immune system uses the population-based search model of evolutionary computation algorithms that have the capability of dealing with a complex search space. The clonal selection algorithm has good features for searching and optimization.
In this work, we studied and optimised an artificial immune system based classification system. We evaluated the performance of the AIS based classification system by computing accuracy at different clonal factors and varying number of generations. We used three standard datasets to compute the accuracy. Experimentally, we find that the system gives highest accuracy with clonal factor 0.4.
Keyword: Association rule mining algorithm, cloning process , support and confidence counting ,Weka Tool.
INTRODUCTION
databases or other data repositories. In this work we study a technique for associative classification using artificial immune system. But let us first discuss the basics of associative classification.
MATERIALS AND METHODS
A SYSTEM FOR AIS BASED CLASSIFICATION
Artificial immune system algorithms have good features for the problem search optimization. In this system we use clonal selection algorithm for AIS based classification.
System block diagram: Figure 1 shows the schematic diagram of our system. All the blocks of figure 1 are the steps performed in the system.
DATA PREPROCESSING
Data preprocessing is the initial step for any data mining task. Preprocessing is done to convert the data in a format which can be easily processed. In our work data was in the form of files containing transaction records. These files are referred to as datasets. A transaction in a dataset contains set of items called itemset. There are various representation schemes available for representing itemsets in a transactional dataset. The itemset in a dataset can be represented as a binary string with items present are encoded as binary 1 and items absent are encoded as binary 0. Consider the following example in table 1 containing 9 transactions from T100 to T900. The data before each transaction is considered as an itemset.Now the itemset were presented in binary representation with a matrix of 9 rows and 5 columns. The items present in a transaction are encoded as binary 1 and the items absent are encoded as binary 0.
INITIALIZE POPULATION
RULE SELECTION
The selection process eliminates rules with support values below the support threshold. After preprocessing the data we applied association rule mining algorithm (Apriori or FP growth) for finding frequent itemsets. If the minimum support threshold is 22% then table 1 shows the list of frequent itemsets based on support threshold and their corresponding confidence.
Table 1: list of frequent itemset based on support threshold
11 12 13 14 15 Support (%)
Confidence (%)
1 1 1 0 0 0 44 66.67 2 1 0 1 0 0 44 66.67 3 1 0 0 0 1 22 33.33 4 0 1 1 0 0 44 57.14 5 0 1 0 1 0 22 28.57 6 0 1 0 0 1 22 28.57 7 1 1 1 0 0 22 50 8 1 1 0 0 1 22 50
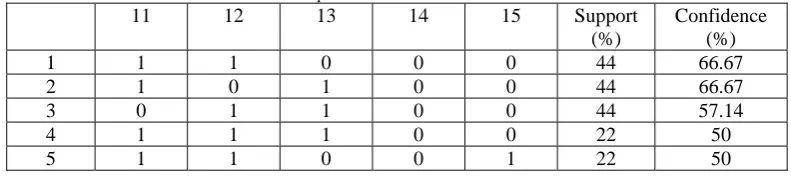
Now we select the rules whose confidence is equal to or greater than the minimum confidence threshold. If the minimum confidence threshold is 50% then table 2 shows the list of frequent itemsets based on confidence.
Table 2: list of frequent itemset based on confidence threshold
11 12 13 14 15 Support (%)
Confidence (%)
1 1 1 0 0 0 44 66.67 2 1 0 1 0 0 44 66.67 3 0 1 1 0 0 44 57.14 4 1 1 1 0 0 22 50 5 1 1 0 0 1 22 50
CLONING OF SELECTED RULE SET
The cloning process is carried out such that the clonal rate of a rule is directly proportional to the confidence (i.e., affinity) of the rule and the average value of clonal rate of every rule is equal to clonalRate given by the user. In particular, the clonal rate of a rule is calculated as follows. Let us denote clonal rate of a rule R as
cRate(R) and R1, R2, R3, …………, Rn are rules selected at a certain generation. As the clonal rate of a rule is
directly proportional to the confidence value, the clonal rate of Ri will be equal to its confidence value multiply
by a constant A
(1) As the average value of clonal rate of every rule is equal to clonalRate, we have
(2) or
(3)
Thus,
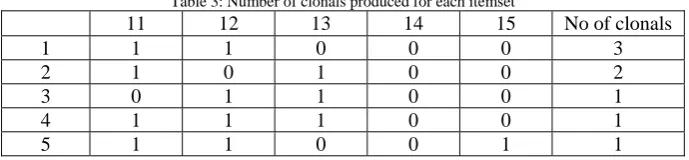
After finding the frequent item sets on the basis of support and confidence threshold, we perform cloning on the basis of clonal rate. Table 3 shows the number of clonals which has to be produced for each item sets [1].
Table 3: Number of clonals produced for each itemset
11 12 13 14 15 No of clonals
1 1 1 0 0 0 3
2 1 0 1 0 0 2
3 0 1 1 0 0 1
4 1 1 1 0 0 1
5 1 1 0 0 1 1
Thus the total no of clonals produced = 8
Table 4 shows the clonals produced for each item sets.
Table 4: Clonals produced for each itemset
1 2 3 4 5 11000 10100 01100 11100 11001 11000 10100
11000
AFFINITY MATURATION
In the clonal selection algorithm, the mutation rate of a cell is inversely proportional to the affinity of the cell. It gives the chance for each low affinity cell to “mutate” more in order to improve its affinity. In our proposed system, the mutation rate is equal to “one item” for every rule. That is, when a rule is mutated, the newly produced rules will differ from the parent rule only by one item. Table 5 shows the mutated clonals by single bit mutation.
Table 5: Mutated Clonals for each itemset
1 2 3 4 5 11000 10101 01101 10100 11101 11000 11100
11000
DIVERSITY INTRODUCTION
To maintain diversity, the clonal selection algorithm updates the population by replacing some existing cells with new ones. In our proposed system, instead of rule replacement, new rules are generated and added into every generation. After the first generations, new rules can be generated for system to help diversify the population. This is an important and effective step to help improve the quality of the mined association rules.
SUPPORT AND CONFIDENCE COUNTING
Now we again count the support and confidence of the mutated clonals. Formally, an association rule is an implication , where and are sets of items in a given dataset.
The supportof the rule is the percentage of transactions containing and with respect to the number of all transactions. While support is seen as usefulness or generalization, i.e., how often the rule is observed, confidence measures the “imply” relationship, i.e., how certain the rule is. In our work we use two association rule mining algorithms namely Apriori and FP growth for counting support and confidence. Table 6 shows the mutated clonals with their support and confidence.
Table 6: Mutated Clonals with their support and confidence
Mutated Clonals Support (%) Confidence (%)
11000 44 66.67 10101 11 25 11100 22 50 01101 11 25 10100 44 66.67 11101 22 50
POPULATION PRUNING
The population pruning process prunes those rules that have already been covered by the memory rules from the population of rules. After counting support and confidence pruning is done to remove the rules of lower affinity (confidence measure). Table 7 shows the pruned item set on the basis of support and confidence threshold.
Table 7: Pruned item sets with their support and confidence
Pruned Clonals Support (%) Confidence (%)
10101 11 25 01101 11 25
MEMORY SELECTION
The memory selection process adds high confidence rules into the memory pool. As the optimal (maximal) value of confidence threshold may vary depending on the dataset, there is no fixed value for the optimal
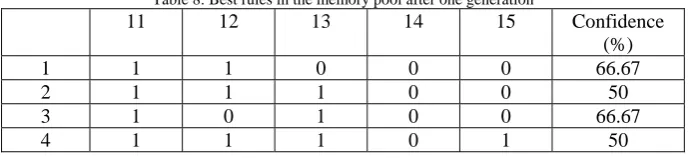
minConfidence that can be used to select rules from the population into the memory pool. Table 8 shows the rules in the memory pool after the completion of one generation.
Table 8: Best rules in the memory pool after one generation
11 12 13 14 15 Confidence (%)
1 1 1 0 0 0 66.67 2 1 1 1 0 0 50 3 1 0 1 0 0 66.67 4 1 1 1 0 1 50
After completing one generation we continue the same process for next generation. We repeat each process and update the memory pool with new rules after each generation. After the specified number of generations, the set of rules in the memory will be the final set of rules.
for integrating WEKA functionalities into standalone allocations. WEKA has been made open source, allowing academics and industry to extend the platform by adding algorithm and tool plug-ins for the platform. Figure 2 shows the WEKA environment interface for knowledge analysis.
Figure 2: WEKA machine learning workbench interface
As far as we know, there does not exists an implementation of the FP growth based Clonal Selection algorithm for professional and academic level application that is both documented and open source. It should be noted that the version of Clonal Selection Algorithm (CLONALG) provided is preliminary.
DATA PREPROCESSING
An ARFF (Attribute-Relation File Format) file is an ASCII text file that describes a list of instances sharing a set of attributes. ARFF files were developed by the Machine Learning Project at the Department of Computer Science of The University of Waikato for use with the WEKA machine learning software.
ARFF files have two distinct sections. The first section is the header information, which is followed the data information.
The header of the ARFF file contains the name of the relation, a list of the attributes (the columns in the data), and their types. An example header on the standard IRIS dataset looks like this:
% 1. Title: Iris Plants Database %
% 2. Sources:
% (a) Creator: R.A. Fisher
% (b) Donor: Michael Marshall (MARSHALL%[email protected]) % (c) Date: July, 1988
%
@RELATION iris
@ATTRIBUTE sepallength NUMERIC @ATTRIBUTE sepalwidth NUMERIC @ATTRIBUTE petallength NUMERIC @ATTRIBUTE petalwidth NUMERIC
@ATTRIBUTE class {Iris-setosa,Iris-versicolor,Iris-virginica}
The data of the ARFF file looks like the following: @DATA
5.0,3.6,1.4,0.2,Iris-setosa 5.4,3.9,1.7,0.4,Iris-setosa 4.6,3.4,1.4,0.3,Iris-setosa 5.0,3.4,1.5,0.2,Iris-setosa 4.4,2.9,1.4,0.2,Iris-setosa
4.9,3.1,1.5,0.1,Iris-setosaLines that begin with a % are comments. The @RELATION, @ATTRIBUTE and @DATA declarations are case insensitive.
CLASSIFICATION
In our work we set the antibody pool size population of 30 for the datasets like, Car, Wine and Zoo. We take the results at varying clonal factor from 0.1 to 0.9 and at different number of generations like 10, 20, 30, 40, 50. In each generation we find the accuracy rate of classification by changing clonal factor.
RESULTS AND DISCUSSION
DATASETS USED
We used three benchmark datasets from the UCI machine learning repository [6] namely Car, Zoo, and Wine. These datasets vary in number of classes, samples, number of items, number of attributes and in number of training and test datasets. The Car, Wine and Zoo datasets are very small datasets. The Car dataset has 1728 samples with 1158 samples as training set and 570 samples as test set. Car dataset has 4 different classes with 6 attributes and 21 items. The wine dataset consists of only 178 samples with 120 training set and 58 test set. Wine dataset contains 3 classes with 13 attributes and 47 items. The Zoo dataset contains 101 samples which are divided into 67 training set and 34 test set. The zoo dataset has 7 classes with 17 attributes and 24 items. We have developed a method for artificial immune system based associative classification. That uses apriori algorithm for association rule mining. We present the results of these systems on different benchmark datasets and perform a comparative study on the basis of accuracy for varying clonal factors 0.1 to 0.9 and at different generations 10. 20, 30, 40, 50
1. From the results it is clear that
i. For a fixed clonal factor, when we vary the number of generations the classification accuracy varies in a random fashion.
ii. For a fixed number of generation, when we vary clonal factor the classification accuracy varies in a random fashion.
iii. Maximum classification accuracy is reported at clonal factor 0.4.
2. From the above points, it is clear that the system gives the best performance at clonal factor 0.4.
REFERENCES
[1] T.D.Do, S.C. Hui, A.C.M. Fong and Bernard Fong, “Associative Classification With Artificial Immune System”, IEEE Transactions on Evolutionary Computation, vol.13, No. 2, pp. 217-228, 2009.
[2] L. N. d. Castro and J. I. Timmis, “Artificial immune systems as a novel soft computing paradigm,” Soft Comput., vol. 7, no. 8, pp. 526–544, 2003.
[3] Artificial Immune Systems and Their Applications, D. Dasgupta, Ed.. Berlin, Germany: Springer-Verlag, 1999.
[4] D. Dasgupta and J. Zhou, “Reviewing the development of AIS in last five years,” in Proc. 2003 IEEE Congr. Evol. Comput., 2003. [5] L. N. d. Castro and F. J. V. Zuben, “The clonal selection algorithm with engineering applications,” in Proc. Workshop Artificial
Immune Syst. Their Applicat. (GECCO’00), 2000, pp. 36–37.
[6] L. N. d. Castro and F. J. V. Zuben, “Learning and optimization using the clonal selection principle,” IEEE Trans. Evol. Comput., vol. 6, no. 3, pp. 239–251, Jun. 2002.