2017 2nd International Conference on Software, Multimedia and Communication Engineering (SMCE 2017) ISBN: 978-1-60595-458-5
CuSAO: Parallel Optimization of Sample Adaptive
Offset (SAO) for Video Encoder
Qing-ge JI
1,2,*, Ting ZHU
1,2, Run-yang LIN
1,2and Fan LIANG
31School of Data and Computer Science, Sun Yat-sen University, Guangzhou 510006, P.R. China
2Guangdong Key Laboratory of Big Data Analysis and Processing, Guangzhou 510006, P.R. China
3School of Electronics and Information Technology, Sun Yat-sen University, Guangzhou 510006,
P.R. China
*Corresponding author
Keywords: Sample adaptive offset, Encoder parallelization, HEVC, CUDA.
Abstract. Conventional SAO module in encoder decides classification mode and offsets based on the statistical data of pixels for accuracy. It needs to traverse all pixels several times, which is extremely time-consuming. All improving works for efficiency either reduce statistical data or concentrate only on SAO decoder. To tackle this, a fast parallel algorithm for standard SAO in encoder named CuSAO based on Graphics Processing Unit (GPU) is proposed. We proposed a pixel grid – thread mapping method and adopted parallel computing of multi-granularity in different stages of SAO encoder. Experimental results demonstrate our method outperforms state-of-the-arts modules and shows impressive results in terms of efficiency,reaching a significant time saving by average 75% and up to more than 85%.
Introduction
SAO reduces the ringing artifacts effectively to improve visual quality of reconstructed frames by classifying pixels into certain categories and obtaining the best offset to modify the pixels of these categories. However, conventional SAO needs to traverse all pixels several times to obtain all statistics data, which is extremely time-consuming. Many researchers have proposed improved methods to reduce run-time of SAO module. Joo, et al. and Rhee, et al. [1][2] proposed faster algorithms to reduce calculation time of SAO by avoiding the statistics-based method, nevertheless, resulting in a compromise with accuracy. Some researchers went further in improving efficiency by introducing parallelization technology into SAO processing [3][4], but all concentrated on SAO in decoder.
In this paper, we propose a fast parallel algorithm based on Graphics Processing Unit (GPU) to implement conventional SAO module in encoder by continuously using the statistics-based method to maintain accuracy.
Conventional SAO Module in Encoder
In encoder process, SAO collects statistical information to derive offsets and then decisions are made in accordance with Relative Rate-Distortion (RRD). SAO uses different offsets in a region depending on the sample classification [5]. SAO includes two types of sample classification: edge offset (EO) and band offset (BO). EO classifies pixels into 4 patterns by comparing them with their neighboring pixels. And each pattern can be divided into 5 categories according to the results. BO classifies pixels into 32 categories by value. SAO collects statistical information according to the classification categories. Also parameters fusion mechanism is introduced to SAO, meaning that the current LCU can transmit new SAO parameters or reuse all parameters of its adjacent blocks.
RRD should be taken into consideration in the deciding process. Therefore, the classification pattern and offsets at the lowest cost are the final SAO parameters of the LCU.
The cost of RRD is given by Eq.1, where 𝜆 denotes the Lagrange multiplier and R represents estimated bits of side information. And ∆𝐷 is the relative distortion as Eq.2.
J D R
(1)
2 2
post pre
D D D Nm mE
(2)
2 ( , ) ( ( , ) ( , ))
pre x y C
D
s x y u x y (3)2 ( , ) ( ( , ) ( , ) )
poxt x y C
D
s x y u x y m (4)( , )x y C( ( , ) ( , ))
E
s x y u x y (5)Where 𝐷𝑝𝑜𝑠𝑡 is the distortion between the original samples and reconstructed post-SAO samples of one coding tree block (CTB), while 𝐷𝑝𝑟𝑒 is the distortion between the original samples and the reconstructed pre-SAO samples. N indicates the number of pixels and E is given by Eq.5. We define
(𝑥, 𝑦) ∈ 𝐶, where x is the horizontal coordinate component and y is the vertical coordinate
component of a pixel in a region 𝐶. Lastly, s represents the original pixel value, 𝑢 represents the reconstructed pixel value and 𝑚 is the candidate offset.
Similar calculations are involved in standard SAO module. We need to traverse all pixels several times to obtain the statistics data N and E in order to calculate parameters in each sample classification pattern. The whole statistic calculation process takes up over 95% of the total computing time of the SAO module.
Proposed Method
[image:2.595.168.430.497.575.2]We divide the whole encoder process into 4 stages and introduce CUDA technology for parallel computation of different pixels’ granularity. The whole cuSAO process is illustrated in Figure 1.
Figure 1. Process illustration of cuSAO.
Stage 1: parallel statistics in grid-scale. We need to calculate 𝑁𝑖 and 𝐸𝑖 in every classification pattern. In a practical LCU, pixels share high correlation within a small region. It means pixel’s values are quite similar or even the same. See Figure 2. Therefore, pixels are likely to be classified into a same classification pattern, leading to threads competing to rewrite the same variables. We came up with a pixel grid-thread mapping method, which takes full advantage of high similarity of pixels’ value in a square region. A LCU will be split into multiple grids. All statistical work in a grid is undertaken by one thread.
1
N
Figure 2. Pixels share high correlation within (left) a LCU and (right) a Pixel grid. one frame
Pixel Statistics
Cost Calculation
Parameters Decision
Pixel Modification
[image:2.595.221.373.695.763.2]We define a parameter split to denote the granularity of a grid. For example, split with a value of 64 indicates that a LCU is split into 64×64 grids of the same size. The greater the size of grid is, the more pixels every thread accounts for, and fewer threads are needed. Each thread block maps a LCU. Technically, when a thread block contains fewer threads, it facilitates cuSAO efficiency. And according to CUDA official documentation, computing resources can be fully used when a thread block contains more than 192 threads. Therefore, we conclude that cuSAO reaches its best performance when split equals 16. See Figure 3. And split of the luminance component is twice that of the chrominance component. Also we employ shared memory to serve as cache for every LCU. We complete all statistic work of every grid in shared memory, then summarize the final LCU data in the global memory, thus reducing the threads competing phenomenon. See Figure 4.
thread1 thread2 thread3 LCU
16
[image:3.595.231.372.210.332.2]64
Figure 3. Pixel grid – thread mapping method.
Th
re
ad
i
Th
re
ad
i+
1
Th
re
ad
n
Shared Memory
Global Memory Thread block 1
Th
re
ad
i
Th
re
ad
i+
1
Th
re
ad
n
Thread block n
Shared Memory
LCU 1 LCU n
grid n
grid i
grid n
[image:3.595.203.388.348.541.2]grid i
Figure 4. Statistics work process of one classification pattern.
After statistics stage, we calculate relative rate-distortion of different categories of each classification pattern respectively in stage 2. Since the obtained data between all kinds of categories in different LCUs are mutually independent, parallel computing on category-scale can be implemented.
Stage 3 decides the optimal pattern and parameters for the component of LCU. Due to parameters fusion mechanism, cuSAO completes this stage in the same way as standard SAO module. And the last stage of cuSAO is to modify the frame according to stage 3. Modification for each pixel shares no association, so it can work in a pixel-scaled parallel way.
Experiments
Table 1. Video sequences dataset and experimental results.
Type Size Name rdSAO cuSAO
Time(ms) Time(ms) Reduction(%) Class A:1920×1080 ParkScene & BQTerrace 310 78.5 76.7
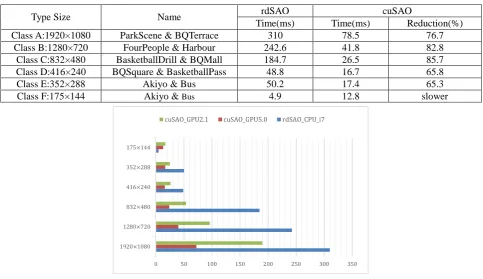
Class B:1280×720 FourPeople & Harbour 242.6 41.8 82.8 Class C:832×480 BasketballDrill & BQMall 184.7 26.5 85.7 Class D:416×240 BQSquare & BasketballPass 48.8 16.7 65.8 Class E:352×288 Akiyo & Bus 50.2 17.4 65.3 Class F:175×144 Akiyo & Bus 4.9 12.8 slower
Figure 5. The influence of different GPU performance to cuSAO speed.
We encoded 120 frames of the video sequences twice in RA coding and with QP of 37 to calculate the average computing time. The results were compared with those obtained through the use of the conventional SAO module. Along with experiments regarding the pure GPU performance, another was devised to verify the optimal split value. The results are shown as follows.
[image:4.595.175.434.542.688.2]From Table 1 and Figure 4-5, a major difference can be seen between the CPU-only versions and the ones that employed GPU. A relevant difference can be seen between different video types as well. However, our proposed method did not show superiority in case of 175*144-size. We conclude that parallelization does not apply when frame size is too small. When it comes to greater sizes, proposed method can reach an 85% boost for the module time. Stronger GPU ability will only make the gap more visible between the CPU-only and GPU accelerated versions.
Figure 6. The verification of optimal split value.
Conclusion
In this paper, a computationally efficient parallel method based on GPU – cuSAO - is introduced for a robust and fast SAO encoder. Experimental results demonstrate that our method can outperform state-of-the art approaches, reaching a significant time saving by average 75% and up to
0 50 100 150 200 250 300 350
1920×1080 1280×720 832×480 416×240 352×288 175×144
cuSAO_GPU2.1 cuSAO_GPU5.0 rdSAO_CPU_i7
sp4/ms sp8/ms sp16/ms sp32/ms sp64/ms
416×240 147 26 16.2 18 37
352×288 151 28 16.8 18 38
175×144 91 24 13 13 18
more than 85%. Furthermore, the proposed method using GPU facilitates for robust, real-time and economical video coding, which is important for widespread industrial adoption.
Acknowledgments
The authors acknowledge the support by National High-Technology Research Development Program of China (863 Program) under Grant No. 2015AA015903. The authors express grateful thanks to Lily Liu for her suggestions resulting in improvement in the quality of the paper.
References
[1] Jaehwan Joo, Yongseok Choi, Kyohyuk: ‘Fast sample adaptive offset encoding algorithm for HEVC based on intra prediction mode’, IEEE 3rd International Conference on Consumer Electronics, Berlin, German, September 2013, pp. 50-53, doi 10.1109/ICCE-Berlin.2013.6698011
[2] Jang J, Rhee C.: ‘Rate-distortion aware skip control for sample adaptive offset’, International
SoC Design Conference. Gyungju, Korea, November 2015, pp. 289-290, doi:
10.1109/ISOCC.2015.7401701
[3] Jo Hyunho, Sim Donggyu, Jeon Byeungwoo.: ‘Hybrid parallelization for HEVC decoder’, 6th International Congress on Image & Signal Processing (CISP), Hangzhou, China, December 2013, pp. 170-175, doi 10.1109/CISP.2013.6743980
[4] Anand Meher Kotra, Mickael Raulet, Olivier Deforges.: ‘Efficient Parallelization of Different HEVC Decoding Stages’, Data Compression Conference, Utah, USA., March 2013, p. 502, doi 10.1109/DCC.2013.82
[5] Chih-Ming Fu, Elena Alshina, Alexander Alshin, et al.: ‘Sample Adaptive Offset in the HEVC
Standard’, IEEE Trans. Cir. and Sys., 2012, 22, (12), pp.1755-1764, doi