Procedia CIRP 33 ( 2015 ) 345 – 350
2212-8271 © 2014 Published by Elsevier B.V. This is an open access article under the CC BY-NC-ND license (http://creativecommons.org/licenses/by-nc-nd/4.0/).
Selection and peer-review under responsibility of the International Scientific Committee of “9th CIRP ICME Conference” doi: 10.1016/j.procir.2015.06.079
ScienceDirect
9th CIRP Conference on Intelligent Computation in Manufacturing Engineering
Automatic proposal of assembly work plans
with a controlled natural language
M. Manns
a*, R. Wallis
b, J. Deuse
c aDaimler AG, Wilhelm-Runge-Str. 11, 89081 Ulm, GermanybDaimler AG, Hanns-Martin-Schleyer-Str. 21-57, 68305 Mannheim, Germany
cTU Dortmund University, Institute of Production Systems, Leonhard-Euler-Str. 5, 44227 Dortmund, Germany
* Corresponding author. Tel.: +49 731 505 2975; fax: +49 711 30 52 13 81 08 E-mail address: [email protected].
Abstract
Manufacturing companies are progressively applying digital manufacturing tools to respond to increased product complexity in shortened product lifecycles. The application results in a comprehensive documentation of the product emergence process. Furthermore at Daimler, a controlled natural language has recently been established, which enables automated analysis of natural language work task description texts. This work proposes a methodology, which enhances planning efficiency by automatically presenting a set of potentially suitable work plans for novel products. The presented work plans are reused from past planning activities. Assessment of work plan suitability is based on a statistical analysis that employs Methods-Time Measurement (MTM) data as well as work task descriptions in a controlled natural language (cnl). The proposed methodology is compared to a previously presented approach, in which text mining is used instead of a controlled natural language. The test comprises 104 work tasks of a Daimler assembly line. While result quality is only slightly improved for the cnl based approach, mapping results from product clusters to assembly sequences are simplified and analysis effort can be reduced if a cnl is already established. Future investigations should focus on investigations of applicability to different production and assembly domains.
© 2014 The Authors. Published by Elsevier BV. Selection and/or peer-review under responsibility of Professor Roberto Teti. Keywords: Digital process planning; data mining; controlled natural language
1.Introduction
Manufacturing industry responds with increasing numbers of product variants to satisfy customer demands [1]. The total number of product variants becomes particularly visible in the final assembly line [2], as most of the variants are created there. Thus, assembly planning needs to take into account all possible product combinations and define the respective assembly processes. In order to support process planning and consequently shorten production development times, a wide range of specialized software tools is used, which can be summarized with the term Digital Manufacturing [3].
The software application results in a comprehensive documentation of the product emergence process [4]. In the assembly planning phase this documentation is
commonly structured in a product, a process and a resource tree, in which tree elements are linked by relations [5].
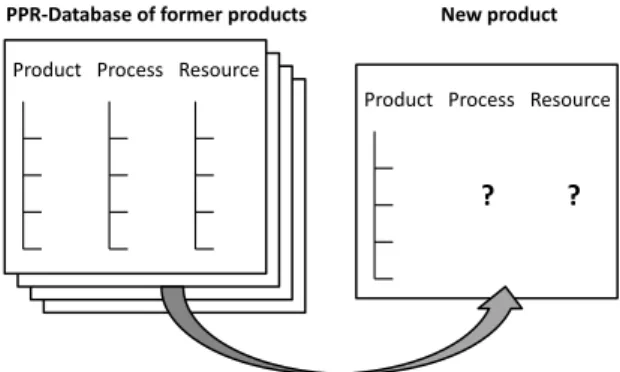
These data structures represent a primary knowledge base of assembly planning processes. When planning new processes, it can serve as basis for an adaptive planning approach if a similar assembly process plan for a resembling part is available [6] (s. Fig. 1). However, it has to be taken into account that planning premises have been different for former products. The ability to search for an existing process plan that resembles the one that needs to be planned today requires expert knowledge. Especially in the case of globally allocated companies producing a multitude of different product variants, the efficient retrieval of existing process plans cannot be taken for granted.
© 2014 Published by Elsevier B.V. This is an open access article under the CC BY-NC-ND license (http://creativecommons.org/licenses/by-nc-nd/4.0/).
Product Process Resource
Product Process Resource
?
?
PPR-Database of former products New product
Fig. 1. Existing data structures serve as a basis for adaptive planning. The utilization of existing planning knowledge can be organized more efficiently with the help of data mining techniques [7]. Such an intelligent assistance function can be a vital success factor for manufacturing companies, because it provides the assembly planners with relevant subject-specific planning knowledge with comparably less efforts.
2.Data mining-supported generation of assembly work plans
The approach to improve the automatic proposal of assembly work plans with the help of a controlled natural language adjoins to three major research areas: Attempts to standardize, enhance and facilitate reusing product respectively process descriptions and the application of data mining techniques to manufacturing data.
Regarding product model representation, [8] propose a versatile product model representation integrating geometric and assembly-specific information content based on manually defined rules. Approaches to enrich product model data with ontologies are presented in [9] and [10]. In [11] and [12] extensions for the Business Process Modeling Notation to model manufacturing processes are proposed. Work plans written in standard language are automatically analysed for potential economic concerns in [13], but no reutilization of existing planning knowledge is aimed at.
While the above mentioned approaches describe systematic procedures to structure product or process data, most of them require the initial definition of rules and / or the setting up of a knowledge base. In contrast, data mining describes the concept of applying data analysis and discovery algorithms to produce a particular enumeration of patterns or models over data [14]. Rules representing the planning knowledge can be inferred automatically with the help of data mining algorithms. Approaches to support manufacturing process planning and the automatic proposal of assembly work plans focus on finding similar products, e.g., based on group
technology principles [15], [16], or on planning manufacturing processes of higher automation degrees [17].
The potential provided by the implicitly available planning knowledge available in the databases of digital manufacturing systems is insufficiently used and the potentials of data mining to discover dependencies and correlations are not fully exhausted.
In [7] a methodology has been proposed, which identifies recurrent patterns in existing assembly work plans and the corresponding product data. Derived data mining models were applied to newly designed products to provide a first set of assembly operations based on product characteristics. Products were clustered using e.g. outer dimensions, weight, center of gravity, and the amount of both designed and standard parts of the entire subassembly. In parallel, assembly work plans were clustered independently based on work plan text segments and their Methods-Time Measurement (MTM) building blocks (s. [18]). With help of existing product-process-relations in the digital manufacturing system, a mapping function was trained to assign product clusters to their respective process clusters.
During model application, new products were classified into existing product clusters and suitable process clusters including the respective assembly operations were derived by means of the mapping function.
3.Improving proposals with a controlled natural language
One limitation of the proposed methodology is that misclassification of a testing dataset into a wrong product cluster and the resulting mapping to a (wrong) process cluster may result in a discrepancy between the proposed and actually required assembly processes.
In order to reduce the risk of misclassification, the clustering of product and process data should be based on input data standardizing the description of the manipulated parts. Hereby, semantic roles provide an opportunity to identify parts and their usage in a particular process step. Furthermore, a standardization of process activity types might improve the clustering partitions, because different names for similar activities (e.g., tighten / fasten / mount / assemble screw resp. part) can lead to the assigning to two different process clusters.
A consistent sentence structure of the work tasks such as “tighten part A to part B with screw and cordless screwdriver” allows identifying the roles of the (major) manipulated parts, utilizing a standardized set of verbs and revealing the required resource.
However, the use of free text form in the assembly work plans cannot ensure the representation of this
planning knowledge. The mere information about the bill of materials content for product clustering does not seem sufficient because part names are normally not unique. Free text as well as abbreviations and acronyms can relate to subjectivity and cause ambiguity and lack of consistency. The previously proposed approach exhibits a high initial data preparation effort for the free text fragments. After a uniform case transformation of the textual descriptions of the assembly operations, umlauts had to be replaced and textual descriptions had to be harmonized. Stopwords had to be filtered out by means of both an automatic stopword filtering algorithm and a manual filtering. The resulting word vector representing the input data for the work plan clustering algorithm consisted of approximately 300 attributes. The quality of the process clusters had been both acknowledged by domain experts and mathematically demonstrated by the calculation of low average within centroid distance values.
One recently presented approach to reduce ambiguity of textual assembly process information in automotive production is using a controlled natural language [19]. The controlled natural language has also been successfully employed for measuring planning project effort in collaborative engineering [20]. Therefore, it shall be investigated if controlled natural language information can be used to improve automatically proposing adequate process plans for novel products.
This work proposes a methodology to integrate controlled natural language content into the previously presented data mining approach so that automated assembly process proposal is improved. Classification quality is measured for both the proposed methodology with a controlled natural language and the free text approach, in which only MTM information is combined with text segments of the assembly work plans. The tests comprise 104 work tasks of a Daimler assembly line. 4.A controlled natural language for assembly planning
Descriptions of production processes in text are hard to interpret by computers. Since language is domain specific and abbreviations are commonplace, such descriptions are also hard to interpret for non-specialists. This is disadvantageous if process information is distributed amongst different sites. Furthermore, it increases the risk of translation errors when employing process information worldwide.
In order to improve comprehensibility and computer interpretability, a controlled natural language for assembly process descriptions in automotive end assembly was set up. In order to ease implementation and dissemination, one objective of this controlled natural language is to change existing free text work task
descriptions as little as possible. Therefore, a frequency analysis of grammatical components of 1,824 existing process descriptions was conducted. In a first step, verbs were identified. For each description with an identified verb, a manual semantic analysis was conducted, and a generalized grammatical structure that covers the majority of the clusters was derived. The resulting structure comprises single sentences without subordinate or conditional clauses. Since sentence structure is found to mainly depend on the activity, an activity based grammar was thus set up. This grammar constructs sentences from the following semantic roles:
x ACTIVITY Main process activity
x THEME Part that is manipulated
x GOAL Part that the THEME is joint to
x SOURCE Part that the THEME is separated from
x FASTENER Part that secures a fastening
x TOOL Part that is used to conduct the ACTIVITY
x INSPECTION Objective of an inspection ACTIVITY
x NUM Number of times an ACTIVITY is conducted
x LOC One to three locational attributes of a part The grammar of the controlled natural language consists of one fixed role sequence per activity, which allows simple parsing. LOC roles can only exist as an extension of THEME, GOAL or SOURCE roles. Each extension can comprise up to three LOC roles. The controlled natural language has been tested in different areas of automotive end assembly. It has been found to cover between 70 and 90 % of the work task descriptions depending on the planning domain.
5. Controlled natural language based automatic proposal of assembly work plans
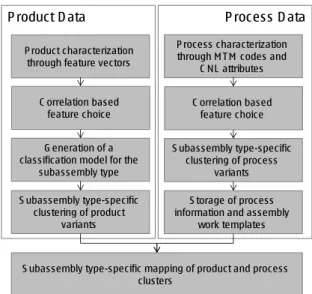
The concept for an automated proposal of assembly work begins with the transformation of product and process into a suitable format for data mining (c. Fig. 3). Thus, the hierarchical nature of the product structure –
initially represented by the bill of materials and enriched with meta data of the 3D geometric representations– is transformed into a flat data table. In order to reduce the bias resulting from specific textual part descriptions, the individual parts that are contained in one subassembly are mapped to their matching categories in the global product structure. For each subassembly, a feature vector including the outer dimensions, the weight, the center of gravity as well as the amount of designed and standard parts of the whole subassembly is created. The frequency of occurrence of the product categories per subassembly is added. The feature vectors are required to be independent from part identification numbers. While part identification numbers often contain an implicit coding, coding mechanisms do not provide the flexibility to incorporate new or additional features, which might occur in future product generations.
P roduct characterization through feature vectors
G eneration of a classification model for the
subassembly type S ubassembly type-specific
clustering of product variants
P rocess characterization through M T M codes and
C NL attributes
S ubassembly type-specific clustering of process
variants S torage of process information and assembly
work templates
S ubassembly type-specific mapping of product and process clusters
P roduct D ata P rocess D ata
C orrelation based
feature choice C orrelation basedfeature choice
Fig. 2: Automatic proposal of assembly work plans.
The assembly work plans describe the processes (operations) required to assemble each subassembly variant. The utilization of the controlled natural language allows the segmentation of the complete assembly operation descriptions into semantic roles, which can be transformed into supplemental attributes with the help of text mining algorithms. The semantic roles that are considered in the analyses are ACTIVITY, THEME, GOAL, NUM, and PREFIX (to indicate pre-assembly processes).
The amount of semantic roles and corresponding MTM building blocks is aggregated for each work plan (for each subassembly). The attributes generated for product and process data are analyzed by means of a correlation analysis. In the following model learning, only product attributes having a correlation coefficient higher than 0.7 to the process attributes and the process attributes having a correlation coefficient higher than 0.7 to the product attributes have been used. Since the controlled natural language contains information about the part being manipulated (THEME), these pieces of information have been used to enrich the product data.
Subsequent to the initial data preparation, the product feature vectors are used to train a naïve Bayes classification model, which is able to distinguish between the various subassembly types automatically. Examples for subassembly types are cylinder head, and crankcase. This step makes data mining more robust and enables proposals of work plans for multiple subassembly types at the same time.
After the differentiation into single subassembly types, an agglomerative clustering with a complete linkage algorithm and a mixed Euclidean distance as distance measure is executed to the normalized product
data in order to determine an appropriate number of clusters k. Subsequently, a k-means clustering algorithm is applied to all variants of each subassembly type in order to reduce variant complexity.
In order to reuse the defined product clusters in model application, a decision tree leading to the resulting clusters is set up. The clustering of assembly work plans (process data) is realized independently from the product clustering for each subassembly type. The normalized process data, composed of the attribute instantiations of the above mentioned semantic roles forming the controlled natural language descriptions of the assembly operations and the corresponding MTM building blocks, is clustered with agglomerative clustering algorithms to deduce an appropriate number of clusters k analog to the procedure described for the product data.
The required process information, such as assembly characteristics and the assembly time in particular, is stored with the process clusters.
Due to existing references between subassemblies and their required assembly processes, which are available in the digital manufacturing system, a mapping function is computed to assign product clusters containing subassemblies with similar characteristics to their respective process clusters. Here again, a naïve Bayes classifier is used.
In the subsequent model application to propose the assembly work plan for a newly designed subassembly, the subassembly is first classified into its respective assembly type by applying the first naïve Bayes model. Next, the decision tree model is applied to classify the product into an existing product cluster. Based on the product cluster, the product-process-classification model identifies the process cluster with the highest probability and provides a cluster specific template for the assembly work plan.
The information, which has been stored with the process clusters, is used to generate the work plans. In order to validate the approach, the generated work plans are compared with the actual work plans, which have been created by assembly planners. In this way, quality of the model is validated with three different indicators:
x Number of correctly predicted operations
x Number of falsely predicted operations, i.e. proposed but unnecessary operations
x Number of missing operations, i.e. required but not proposed operations
The sum of the number of correctly predicted operations and the number of missing operations equals the total number of operations the considered subassembly requires. The number of falsely predicted operations represents the errors the model made.
6.Application results
The presented approach for an automatic proposal of assembly work plans with a controlled natural language has been applied to three multi-variant subassembly types of a Daimler Trucks power train assembly line. The implementation of the described steps has been realized in RapidMiner 5.3, which is an open source data mining and machine learning software [21].
The considered dataset has been extracted from both the product data management system and the digital manufacturing system. The datasets describe manual assembly tasks for the different product variants in series production. Prior to the tests, the data has been evenly divided into training and testing dataset.
In a first step, testing data is classified into assembly types by means of a naïve Bayes model. Hereby, all examples of the testing data set have been classified correctly into their respective types.
Subsequently, the decision tree model is applied to classify the test instances into the existing product clusters. These are mapped to their corresponding process clusters in the next step.
In 63% of the cases, a 1:1-mapping from one product cluster to another process cluster is possible. In 27% an explicit mapping from one product cluster to a process cluster with a probability greater than 66% can be achieved. In the remaining 10%, only a mapping from one product cluster to two equally probable process clusters could be obtained. If only a mapping from one product cluster to two equally probable process clusters can be obtained, the process cluster with the smaller number is chosen.
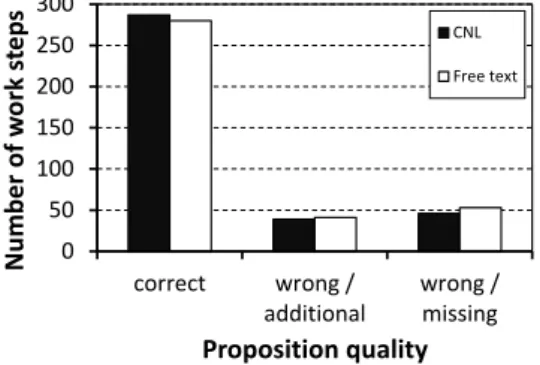
The assembly operations required for the products of the testing data set are correctly predicted 287 times, falsely predicted 39 times and not predicted 46 times (s. Fig. 3). 0 50 100 150 200 250 300 correct wrong / additional wrong / missing Number of w o rk s tep s Proposition quality CNL Free text
Fig. 3: Classification results of controlled natural language and free text approaches.
7.Discussion
Tests of both the controlled natural language based and the data mining based approaches have been successfully conducted for a realistic use case of automotive power train assembly planning. Results show that both approaches are able to successfully predict operations for new products. The controlled natural language based approach that is presented in this work yields slightly improved results in comparison to the previously presented text mining based approach.
Furthermore, the proposed methodology makes considerable text mining effort unnecessary if a controlled natural language is present. This data preparation required ca. 8 h for the test cases, which is considered an obstacle to practical adoption of the text mining based approach. However today, the presence of a controlled natural language is not established in most production planning environments, which makes it a prerequisite for broad adoption of the methodology.
Differences of both approaches are in the range of improvement that had been achieved by optimizing parameters of data mining algorithms in the text mining approach. This may mean that the controlled natural language based approach may have further potential but also that yet untested parameter variations might improve the text mining approach so that the difference becomes insignificant. Further tests with additional data may help clarifying significance of results.
One interesting property of the controlled natural language approach is that it requires less product attributes, i.e. 174 instead of 147. Such a reduction improves interpretability of results. Furthermore, a planner who has to judge if the proposed operation sequence is appropriate has less problems understanding terms that may be common at another planning site because terms are standardized. However, such benefits of the controlled natural language approach are hard to quantify objectively and should be investigated in pilot tests with planners.
The measured improvements result mainly from improved product clustering because both methodolo-gies showed no problems mapping product clusters to process clusters. Therefore, adding standardized terms to product meta-data and enforcing the usage of these terms in process planning (e.g. in a process product mapping table) may show similar improvements for the considered use cases and should be further investigated.
The considered use cases only comprise power train assembly tasks. Other areas of automotive assembly and assembly of other types of products may show different properties that may affect result quality. Such differences have been experienced e.g. in interior assembly, where tasks can be more easily differentiated in main and auxiliary activities. In this case, controlled
natural language work task descriptions tend to be more expressive because semantic roles cover auxiliary activities such as holding parts in place more effectively. Future tests should reveal if the controlled natural language based approach benefits from this situation.
In all use cases, product variance plays a predominant role. Since PDM data and meta-data is used as input information, its structure obviously influences results. Representation of product variance is normally done at a specific layer of the product structure tree. Changing to a different layer could change the number of operations that are proposed for a new product. This may affect effectiveness of clustering. Therefore, the presented tests may not be generalizable for all types of product structures.
8.Conclusion and outlook
In this work, a novel methodology for automatic proposal of assembly work plans with a controlled natural language for work task descriptions has been presented. In comparison to a previously presented text mining based approach, the methodology yields results from less attributes that are easier to interpret. Result quality is only slightly improved. It can reduce analysis effort if a controlled natural language for work tasks is established in production planning.
Future research should concentrate on investigations of applicability to different production and assembly domains as well as to practical acceptance of the approach by production planning engineers. If these tests yield favorable results, the methodology could considerably reduce planning effort in variant rich environments and therefore improve competitiveness and agility of producing companies.
Acknowledgements
This paper represents the background, objectives and
first results of the research project “Prospective Determination of assembly work content in Digital
Factory (ProMondi)”. This research and development
project is funded by the German Federal Ministry of Education and Research (BMBF) within the Framework
Concept “Research for Tomorrow’s Production”
(funding number 02PJ1110) and managed by the Project Management Agency Karlsruhe (PTKA). The authors are responsible for the contents of this publication.
This research activity was conducted in collaboration with the research project INTERACT - Interactive Manual Assembly Operations for the Human-Centered Workplaces of the Future that has received funding from the European Union Seventh Framework Programme (FP7).
References
[1] Daimler Annual Report 2013. Daimler AG 2013, p. 2.
[2] Bley H, Zenner C. Variant-oriented Assembly Planning. CIRP Annals – Manufacturing Technology 2006;55:23-28.
[3] Petzelt D, Schallow J, Deuse J. Data Integration in Digital Manufacturing based on Application Protocols. 3rd IEEE Int. Conf.
on Computer Science and Information Technology 2010;475-479. [4] Erohin O, Kuhlang P, Schallow J, Deuse J. Intelligent Utilisation of
Digital Databases for Assembly Time Determination in Early Phases of Product Emergence. Procedia CIRP - Conference on Manufacturing Systems 2012;3:424-429.
[5] Digital Factory – Fundamentals. Düsseldorf: VDI; 2008. [6] Eversheim W. Organisation in der Produktionstechnik –
Arbeits-vorbereitung. Berlin: Springer; 2002.
[7] Wallis R, Erohin O, Stromberger F, Deuse J. Data Mining Application in Digital Process Planning - RapidMiner in Auto-motive Industry. In: Fischer S, et.al. Proc. of the 4th RapidMiner
Comm. Meeting and Conf. Aachen: Shaker, 2013. p.165-174. [8] Tallinen T, Velez Osuna R, Martinez Lastra JL, Tuokko R. Product
Model Representation Concept for the Purpose of Assembly Process Modelling. 5th IEEE International Symposium on Assembly and Task Planning 2003;222-227.
[9] Barbau R, Krima S, Rachuri S, Narayanan A, Fiorentini X, Foufou S, Sriram RD. OntoSTEP: Enriching Product model data using ontologies. Computer-Aided Design 2012:44;575-590.
[10] Warwas S, Klusch M, Fischer K, Slusallek P. A Development Environment for Engineering Intelligent Avatars for Semantically-enhanced Simulated Realities. Proceedings of the 11th International Conference on Autonomous Agents and Multiagent Systems 2012:3; 1479-1480.
[11] Rajsiri V, Lorré, JP, Bénaben F, Pingaud H. Knowledge-based system for collaborative process specification. Computers in Industry 2010:61;161-175.
[12] Zor S, Leymann F, Schumm D. A Proposal of BPMN Extensions for the Manufacturing Domain. Procedia CIRP - Conference on Manufacturing Systems 2011:1-6.
[13] Rychtyckyj N, Klampfl E, Gusikhin O, Rossi G. Application of intelligent methods to automotive assembly planning. IEEE International Conference on Systems, Man and Cybernetics, 2007:2479–2483.
[14] Fayyad U, et.al. From Data Mining to Knowledge Discovery in Databases. AI Magazine 1996;17:37-54.
[15] Eversheim W, Deuse J. Formation of Part Families based on Product Model Data. Production Engineering 1997;IV/2:97-100. [16] Romanowski CJ, Nagi R. A data mining approach to forming
generic bills of materials in support of variant design activities. ASME Journal of Computing and Information Science in Engineering 2004:4;316-328.
[17] Agard B, Kusiak A. Data Mining for Selection of Manufacturing Processes. Maimon O, Rokach L, editors. Data Mining and Knowledge Discovery Handbook, New York: Springer, 2005. p. 1159–1166.
[18] Maynard HB, Stegmerten GJ, Schwab JL. Methods-Time Measurement, New York: McGraw-Hill, 1948.
[19] Manns M, Arteaga Martin NA. Automated DHM Modeling for Integrated Alpha-Numeric and Geometric Assembly Planning. Abramovici M, Stark R, editors. Smart Product Engineering, LNPE. Berlin/Heidelberg: Springer, 2013. p. 325–334.
[20] Manns M, Arteaga Martin NA. A Vagueness Measure for Concurrent Engineering of Manual Assembly Lines. Production Engineering 2014:8;225-231.
[21] Mierswa I, et.al. YALE: Rapid Prototyping for Complex Data Mining Tasks. Proceedings of the 12th ACM SIGKDD Int. Conf.
on Knowledge Discovery and Data Mining, New York: ACM-Press, 2006. p. 935–940