CUSICK, MARK BELLAIRS. Human Generated Topics: A Gold Standard for Automated Topic Evaluation. (Under the direction of Michael Rappa.)
With the ever increasing amount of online large scale text corpora including product
reviews, news articles, research papers, and social media posts, researchers have proposed
numerous automated topic generation approaches to help users understand and navigate
this information. In this dissertation we propose an approach that improves upon previous
research as well as introduce a means to directly and accurately compare the results of
automated approaches against human judgments of usefulness.
Many automated approaches utilize strong statistical methods but often produce topics
poorly aligned with human judgments. While other approaches use taxonomy resources
to consistently produce well aligned topics at the cost of weak or explicit means of term
selection. We introduce our Extensible Topic Model (ETM): an approach combining
sta-tistical term selection with topic generation based on an external taxonomy. Based on a
comparative evaluation,ETMsuccessfully combines these two forms of topic generation and produces topics aligned with human judgments.
Automated topic generation approaches often evaluate their results by using either
easily manipulated statistical functions or costly human evaluation studies. We introduce
Human Generated Topics (HGT): a repeatable, low cost approach for generating a set of
gold standard topics for any text corpus requiring only non-expert judges. We useHGT to create a gold standard of topics within the domain of online retail product reviews as
by
Mark Bellairs Cusick
A dissertation submitted to the Graduate Faculty of North Carolina State University
in partial fulfillment of the requirements for the Degree of
Doctor of Philosophy
Computer Science
Raleigh, North Carolina
2015
APPROVED BY:
Benjamin Watson Christopher Healey
Mark Bellairs Cusick grew up in Chapel Hill, North Carolina. Seeking colder weather and
snow for skiing, he attended Appalachian State University and graduatedSumma Cum Laudein the Spring of 2009 with a B.S. in Computer Science. After two years of working as a software engineer, Mark decided to return to school and began work on his Ph.D. in
Computer Science at North Carolina State University. In 2012 despite being a nerdy graduate
student, the most wonderful woman in the world made Mark eternally happy by saying "I
do". During the summers of 2013 and 2014, Mark interned with Amazon in Seattle. These
internships were some of the defining moments in Mark’s early career and helped shape
the focus of his dissertation. Upon graduation Mark is excited to continue his work with
I would like to thank my advisor Dr. Michael Rappa for his support and advice, my
com-mittee for their assistance and guidance, and Amazon NLP experts Dr. Kevin Small and
Dr. Gyuri Szarvas for their knowledge and feedback. I also want to thank the amazing,
hardworking, and helpful workers of Amazon Mechanical Turk; without their diligence and
LIST OF TABLES . . . vii
LIST OF FIGURES . . . . x
Chapter 1 Introduction . . . . 1
Chapter 2 Background . . . . 5
2.1 Introduction . . . 5
2.2 Statistical Topic Modeling . . . 8
2.2.1 Early Work . . . 9
2.2.2 Generative Models . . . 11
2.2.3 Hierarchical Models . . . 15
2.2.4 Taxonomy Models . . . 19
2.2.5 Discussion . . . 20
2.3 Taxonomy Based Topic Hierarchies . . . 20
2.3.1 Resource Terminology . . . 22
2.3.2 Subsumption . . . 23
2.3.3 WordNet Approaches . . . 25
2.3.4 Combining Taxonomies . . . 27
2.3.5 Discussion . . . 30
2.4 Keyphrase Extraction . . . 31
2.4.1 Extracting Candidate Keyphrases . . . 32
2.4.2 Graph-Based Ranking . . . 33
2.4.3 Topic-Based Clustering . . . 34
2.4.4 Simultaneous Learning . . . 35
2.4.5 Language Modeling . . . 35
Chapter 3 Extensible Topic Model . . . 37
3.1 Introduction . . . 37
3.2 Preprocessing . . . 38
3.3 Term Selection . . . 40
3.4 Topic Identification . . . 43
3.5 Topic Hierarchy Generation . . . 44
3.6 Conclusions and Future Work . . . 50
Chapter 4 Human Generated Topics . . . 53
4.1 Introduction . . . 53
4.3 Generating Topics . . . 58
4.3.1 Overview . . . 60
4.3.2 Term Identification . . . 61
4.3.3 Term Groups . . . 64
4.3.4 Topic Validation . . . 68
4.3.5 Topic Placement . . . 71
4.3.6 Final Validation . . . 73
4.4 Results . . . 75
4.4.1 Evaluating Automated Approaches . . . 75
4.4.2 Human Evaluation Studies . . . 76
4.4.3 ValidatingHGTEvaluations . . . 79
4.4.4 HGT Completeness . . . 80
4.4.5 Conclusions and Future Work . . . 84
REFERENCES . . . 86
APPENDIX . . . 97
Appendix A Human Generated Topics. . . . 98
A.1 GitHub Data Repository . . . 98
A.2 Dress Topics . . . 98
A.3 Fantasy Book Topics . . . 109
Table 2.1 Publicly available keyphrase gold standard datasets . . . 33
Table 3.1 ETMComparative Evaluation . . . 51
Table 4.1 Simulated Probability of Improperly Disjoint Group Occurrence . . . . 68
Table 4.2 Automated Approach Evaluations . . . 76
Table 4.3 Human Evaluation Study Ratings . . . 79
Table 4.4 Scoring Comparison . . . 80
Table A.1 Dress: Cheap Topic . . . 99
Table A.2 Dress: Too Small Topic . . . 99
Table A.3 Dress: Fits Well Topic . . . 100
Table A.4 Dress: Material Topic . . . 100
Table A.5 Dress: Easy Care Topic . . . 101
Table A.6 Dress: Feel Topic . . . 101
Table A.7 Dress: Positives Topic . . . 101
Table A.8 Dress: Quality Topic . . . 101
Table A.9 Dress: Look Topic . . . 102
Table A.10 Dress: Too Large Topic . . . 102
Table A.11 Dress: Flow Topic . . . 103
Table A.12 Dress: Love Topic . . . 103
Table A.13 Dress: Thin Topic . . . 103
Table A.14 Dress: Comfort Topic . . . 104
Table A.15 Dress: Delivery Topic . . . 104
Table A.16 Dress: Recommended Topic . . . 104
Table A.17 Dress: Great Product Topic . . . 104
Table A.18 Dress: Bad Fit Topic . . . 105
Table A.19 Dress: Compliments Topic . . . 105
Table A.20 Dress: Great Price Topic . . . 106
Table A.21 Dress: Uncomfortable Topic . . . 106
Table A.22 Dress: Temperature Cool Topic . . . 106
Table A.23 Dress: Expensive Topic . . . 106
Table A.24 Dress: Thick Topic . . . 106
Table A.25 Dress: Bust Topic . . . 106
Table A.26 Dress: Stretch Topic . . . 106
Table A.27 Dress: Professional Topic . . . 106
Table A.28 Dress: Arms Topic . . . 107
Table A.29 Dress: Dissapointment Topic . . . 107
Table A.33 Dress: Subpar Construction Topic . . . 108
Table A.34 Book: Fun Read Topic . . . 109
Table A.35 Book: Great Book Topic . . . 109
Table A.36 Book: Story Topic . . . 110
Table A.37 Book: Author Topic . . . 110
Table A.38 Book: Hooked Topic . . . 110
Table A.39 Book: Loved It Topic . . . 110
Table A.40 Book: Well Written Topic . . . 111
Table A.41 Book: Poorly Written Topic . . . 111
Table A.42 Book: Positive Adjectives Topic . . . 111
Table A.43 Book: Dissatisfaction Topic . . . 112
Table A.44 Book: Slow Pace Topic . . . 112
Table A.45 Book: Great Series Topic . . . 112
Table A.46 Book: Positives Topic . . . 112
Table A.47 Book: Violence Topic . . . 113
Table A.48 Book: Characters Topic . . . 113
Table A.49 Book: Plot Topic . . . 113
Table A.50 Book: Engaging Topic . . . 113
Table A.51 Book: Recommdended Topic . . . 113
Table A.52 Book: Anticipation Topic . . . 114
Table A.53 Book: Stars Topic . . . 114
Table A.54 Book: Cliffhanger Topic . . . 114
Table A.55 Book: Style Topic . . . 115
Table A.56 Camera: Defective Topic . . . 116
Table A.57 Camera: Unhappy Topic . . . 116
Table A.58 Camera: Poor Picture Quality Topic . . . 116
Table A.59 Camera: Not Recommended Topic . . . 117
Table A.60 Camera: Bad Camera Topic . . . 117
Table A.61 Camera: Returned Topic . . . 117
Table A.62 Camera: Excellent Picture Quality Topic . . . 117
Table A.63 Camera: Recommended Topic . . . 117
Table A.64 Camera: Quality Topic . . . 117
Table A.65 Camera: Satisfied Topic . . . 118
Table A.66 Camera: Great Camera Topic . . . 118
Table A.67 Camera: Love It Topic . . . 118
Table A.68 Camera: Excellent Positives Topic . . . 118
Table A.69 Camera: Works Well Topic . . . 118
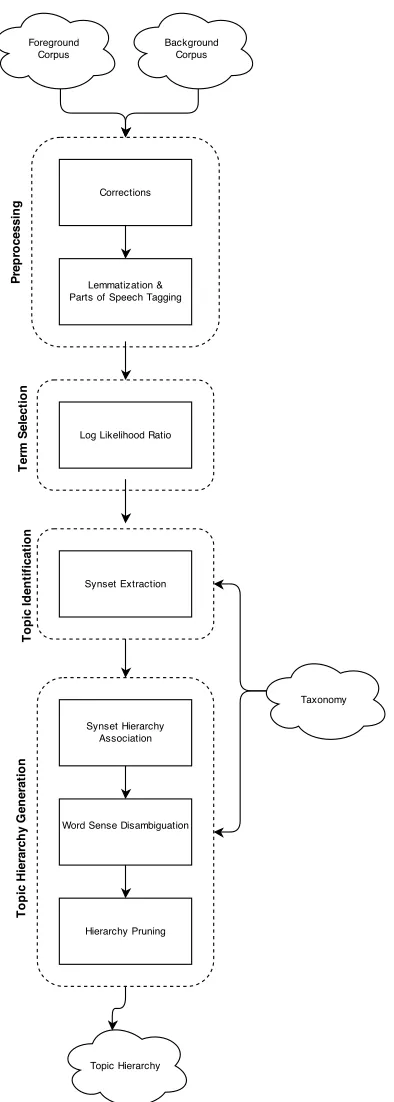
Figure 3.1 Algorithm Overview . . . 39
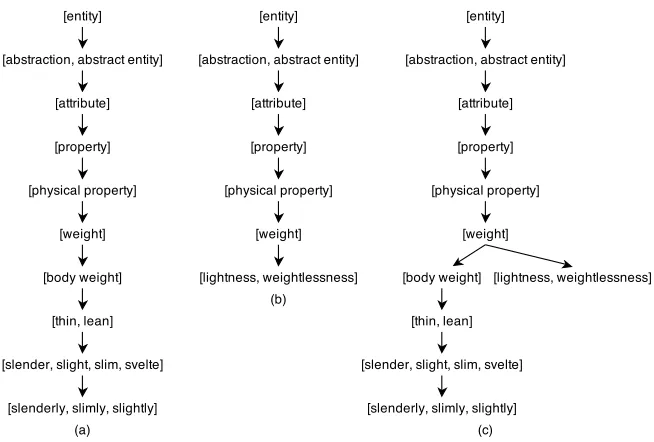
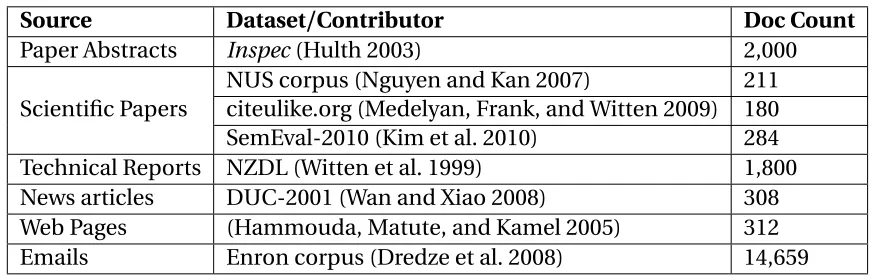
Figure 3.2 Synset Examples . . . 44
Figure 3.3 Merge Synsets . . . 45
Figure 3.4 Synset Hierarchies . . . 46
Figure 3.5 Merge Noun Synset Hierarchies . . . 47
Figure 3.6 Merge Adjective Synset Hierarchies . . . 47
Figure 3.7 Merge Noun and Adjective Synset Hierarchies . . . 48
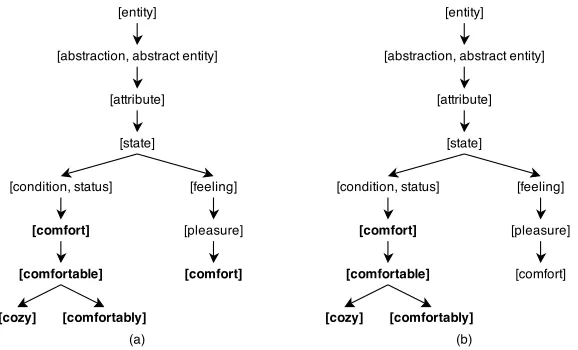
Figure 3.8 Synset Word Sense Disambiguation . . . 49
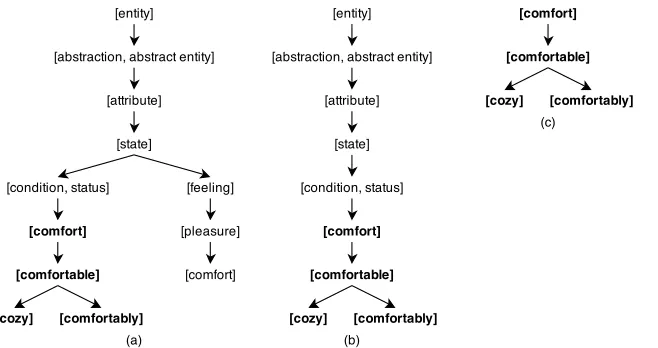
Figure 3.9 Hierarchy Pruning . . . 50
Figure 4.1 Term Identification HIT . . . 63
Figure 4.2 Term Group HIT . . . 66
Figure 4.3 Topic Validation HIT . . . 70
Figure 4.4 Topic Placement HIT . . . 72
Figure 4.5 Final Validation HIT . . . 74
Figure 4.6 Final Validation HIT . . . 78
Figure 4.7 Distribution of Selected Terms Across Reviews . . . 82
1
INTRODUCTION
Recently there has been an ever increasing amount of online large scale text corpora. Many
of these text corpora, such as product reviews, news articles, research papers, and social
media posts, have become so vast that a single user cannot read them all. Researchers have
proposed numerous methods to help users understand the information contained within
these corpora (Blei, Ng, and Jordan 2003; Dakka and Ipeirotis 2008; Kim et al. 2012).
In this dissertation we focus on the field of automated topic generation: transforming a
"topics". The words and phrases, collectively referred to as terms, contained in each topic
aim to express a single area of discussion found within the text corpus. Documents from the
corpus can also be associated with various topics based on the terms contained within each
document. In this way, automated topic generation provides users a high level overview of
the concepts discussed within a corpus as well as the ability to dive deeper into each topic
via the document-topic associations.
In the field of automated topic generation, there are two main areas of research:
statis-tical topic modeling and taxonomy based approaches. Statisstatis-tical methods are based on
mathematical formulas while taxonomy based approaches generate topics using taxonomy
resources external to the text corpus, such as Wikipedia1and WordNet2. While both areas
employ different methods of generating topics, they are focused on the goal of helping
users understand and navigate the content of a text corpus.
In our work, we first seek to improve upon previous research in the areas of statistical
topic modeling and taxonomy based approaches. Statistical methods can automatically
discover interesting associations between terms, but often produce topics that are not
well aligned with human judgments of usefulness (Stoica, Hearst, and Richardson 2007).
Taxonomy based approaches typically produce topics more aligned with human judgments,
but rely on weak statistical or explicit means of selecting key terms from a corpus, such as
selecting only proper nouns or Wikipedia article titles (Dakka and Ipeirotis 2008). Despite
potential synergy, there has been little crossover between these areas of research.
We improve upon existing automated topic generation approaches by combining
statis-tical topic modeling term selection with the topic generation of taxonomy based approaches.
We introduce our Extensible Topic Model (ETM): an approach grounded in statistical term
selection coupled with topic generation based on an external taxonomy well aligned with
human judgments. The goal ofETMis to improve upon the weak term selection of taxon-omy based approaches and the poor alignment of generated topics to human judgments
of statistical topic models. By combining the strengths of these two areas,ETM aims to produce results that do not require explicitly defined term selections and produce
top-ics that are well aligned with human judgments. Based on these results, we successfully
demonstrate a new approach that combines these areas of research, and our results provide
insights for future improvements.
The second focus of this dissertation is the evaluation of automated results. Automated
topic generation approaches struggle to prove their results align with human judgments.
Statistical approaches attempt to prove usefulness by minimizing loss functions (Blei, Ng,
and Jordan 2003) or maximizing functions derived from human judgments (Newman et al.
2010b; Mimno et al. 2011). However, these functions can be easily manipulated (Stevens
et al. 2012), and thus it is difficult to assess their relation to human judgments. Alternatively,
both areas sometimes perform standalone human evaluation studies where human judges
are asked the usefulness of a set of generated topics. It is important to note that these studies
require additional time from the researchers, can be costly, and do not produce artifacts
that can be used for comparison by other researchers (Stoica, Hearst, and Richardson 2007;
Dakka and Ipeirotis 2008). There is a need in the research community for a more efficient
and direct means of evaluating results and comparing results between researchers and
approaches.
topic generation approaches against human judgments. We introduce Human Generated
Topics (HGT): a repeatable, low cost approach for generating a set of gold standard topics
for any text corpus requiring only non-expert judges. By usingHGTto create a gold standard of topics, researchers will no longer have to rely on indirect statistical functions or perform
costly human evaluation studies to score and compare each iteration of their work. After
describing the details ofHGT, we use it to create a gold standard of topics within the domain of online retail product reviews. Finally, we validate our gold standard and demonstrate the
2
BACKGROUND
2.1
Introduction
In the automatic topic generation literature, there are two main areas of research:
statis-tical topic modeling and external taxonomy based topics. Both of these areas attempt to
determine the topics of discussion for a given corpus of documents. The most successful
approaches perform this in three general steps:
single words or multi-word phrases, from a corpus of documents.
2. Topic Identification:the process of clustering the selected terms into related groups or topics.
3. Topic Generation:the process of determining the relationships between topics in the form of a flat list, a single hierarchy, or multiple hierarchies.
In the area of topic modeling, the steps of term selection, term identification, and
topic generation are typically performed solely on the basis of statistical relationships
between terms to produce a flat list of topics (Hofmann 1999; Blei, Ng, and Jordan 2003)
or a hierarchy of topics (Li and McCallum 2006; Blei, Griffiths, and Jordan 2010; Kim et al.
2012). Taxonomy approaches typically perform term selection by simple frequency metrics
or by manually defining the types of terms to be selected and perform topic identification
and generation based on external human generated sources, such as Wikipedia, usually
resulting in a hierarchy of topics (Stoica, Hearst, and Richardson 2007; Dakka and Ipeirotis
2008; Medelyan et al. 2013b).
Despite the similar results of these two approaches, there is little cross-over between
areas. This may be due to the fact that the application of these techniques lie in separate
domains. Typically statistical topic models focus on providing an insight into the topics
of discussion for a particular corpus of documents with little regard for the end-user
visu-alizations (Blei, Ng, and Jordan 2003). One notable exception is an interactive approach
focused on allowing users to retrain and improve a topic model (Hu et al. 2014). In
compar-ison, taxonomy based approaches are highly connected with end-user visualizations in the
additional filtering based on topics or facets identified within the results set (Stoica, Hearst,
and Richardson 2007).
When considering the end-user application of generated topics, much research focuses
on visualizations, particularly in the domain of product reviews (Gamon et al. 2005; Chen
et al. 2006; Wu et al. 2010; Alper et al. 2011; Yatani et al. 2011; Ahmad 2013). The amount of
research in this area is not surprising given the unique challenges presented by product
reviews (Cusick et al. 2013). For example, when compared to commonly used text sources
such as news articles or paper abstracts, product reviews present an exciting challenge due
to their great variety of length and style. Product review length can range from a few words
to several pages; while style can vary from twitter abbreviation and brevity, to colloquial
speech, to well written essays. Any system that intends to aggregate and present the content
contained within reviews must be able to handle all of these differences. Alper et al. (2011)
presents an extremely compelling visualization. In this research Alper et al. describe a
system where key terms selected from a set of reviews are grouped into related topics. The
system allows users to view sentiment for each topic and for key terms within a single
topic. However, the system is informed by manual topic identification and would benefit
from an automated identification process. The topic generation approach proposed in this
dissertation is precisely such a process.
Automatic keyphrase extraction is another similar field from which we draw useful
research. Keyphrase extraction is the process of identifying the most important words and
phrases (called keyphrases) from a document. These keyphrases are often used in document
search (Turney 2000), text summarization (Zhang, Zincir-Heywood, and Milios 2004), text
indexing (Gutwin et al. 1999). Keyphrase extraction is a challenging task where the
state-of-the-art performs lower than many core Natural Language Processing (NLP) tasks (Liu et al.
2010). Much keyphrase extraction research has focused significant effort on the domains of
news articles, scientific paper abstracts, and image captions. Less effort has been shown
in the domain of product reviews which shares the challenges of these other domains,
and it could be argued that the diversity of text found in reviews makes this an even more
challenging domain. One of the reasons for the lack of keyphrase extraction research in
product reviews arises from the fact that these approaches are scored against gold standard
datasets, none of which exist for the product review domain. Our gold standard topic dataset
will focus on product reviews and include a keyphrase gold standard. Thus our dataset will
impact both keyphrase extraction research as well as topic generation.
2.2
Statistical Topic Modeling
Statistical topic modeling is based on statistically valid methods for identifying and
associ-ating terms within a corpus of documents. One of the earliest approaches was proposed by
Luhn (1958). In this approach, Luhn describes a measure called term frequency where the
occurrences of a term are counted across a corpus. Terms considered to be descriptive of
the corpus are then selected if their term frequency ranges between a manually defined
low and high threshold. Term frequency forms the basis of much of the early work in
sta-tistical text modeling. However, the stasta-tistical approaches have continued to evolve, most
notably in recent years. Regardless of the statistical method utilized, most topic modeling
approaches are based on the "bag-of-words" assumption which states that the order of
individual words are important. This assumption is derived from the probability theory
concept of exchangeability (Aldous 1985).
2.2.1
Early Work
The first major advance in statistical topic modeling did not produce topics, but rather
was concerned with the accurate retrieval of relevant documents based on query terms.
This advance was proposed by Salton and Buckley (1988) as the Term Frequency x Inverse
Document Frequency (TFxIDF) technique.TFxIDF was an improvement over term
fre-quency approaches because it added the concept of inverse document frefre-quency, which
is the total number of documents in a corpus in which a term appears. By multiplying
each term’s frequency by its inverse document frequency, terms which occur with high
frequency in only a few documents will be considered more important than terms with
lower term frequency but higher inverse document frequency.TFxIDFvectors must be cal-culated for each unique term found in the corpus in order to produce a term-by-document
frequency matrix. The matrix produces a term vector for each document in the corpus
which identifies the set of words that are most descriptive and can then be used to match
query terms with relevant documents. In addition, by measuring the distance between
these vectors, simple associational relationships can be made between documents. While
TFxIDFproved more useful than simple term frequency, it only provided a small amount of reduction in description length for each document, as well as revealing little in terms of
inter- or intra- document relationships, especially when similar documents and queries do
not share common terms. It is this second problem of associating similar documents and
of terms between documents and queries.
Deerwester et al. (1990) introduced Latent Semantic Indexing (LSI) to provide
associa-tions between similar documents and queries without the necessity of term sharing.LSI uses singular value decomposition to transform aTFxIDFterm-by-document frequency matrix to a reduced dimensionality linear subspace. By plotting the distance between term
and document points in this subspace, relationships can be reliably established, even
be-tween terms or documents that share few common terms. This allows queries with terms
not found in all documents to match more relevant documents thanTFxIDF. To illustrate: for a given corpus of product reviews for books and apparel,LSIwould cluster book reviews and book related terms in one section of the subspace while clustering apparel reviews and
apparel related terms in another. When querying the subspace, query terms that match
some of the documents or terms in a section of the subspace will be related with other
nearby documents and terms. Thus a book query will return most book reviews even if the
book query does not use book terms found in all book reviews. In this sense,LSIforms relationships between terms and documents. However, beyond clusters of similar items,
this approach cannot provide an understanding of the topics being discussed in each
doc-ument, nor does it proscribe a generative model, a model which can be used to generate
values for new data.
Similar to the associations created byLSIbetween terms in a corpus, Dunning (1993) presented Log Likelihood Ratio (LLR). This approach focuses on selecting statistically
descriptive terms of the corpus, also called the Topic Signature. While providing clustering
similar toLSI,LLRdoes not provide a solution for modeling multiple topics. However it is important to note that as a technique for selecting the most significant terms,LLRis an excellent candidate and has proven to produce valid results (Moore 2004) that best results
ofTFxIDF(Lin and Hovy 2000).
2.2.2
Generative Models
To incorporate an understanding of multiple topics in a corpus as well as to provide a
generative model for future terms, Hofmann (1999) introduced probabilistic Latent
Seman-tic Indexing (pLSI). His approach uses a probabilisSeman-tic statisSeman-tical approach called "aspect
model" where each term in a document is modeled as a sample from a fixed number of
mixtures comprised of multinomial random variables which are considered "topics". Thus
each term is associated with one of these multinomials or "topics", and each document
has a probability distribution over all topics. By creating this approach, Hofmann provided
the first true statistical topic model as well as a generative model that can associate new
terms with topics. However, this model provides no means for associating new documents
with topics. Also the number of parameters grows linearly with the corpus size which leads
to potential overfitting.
Blei, Ng, and Jordan (2003) proposed Latent Dirichlet Allocation (LDA) to provide a fully
generative Bayesian alternative topLSI.LDAuses a three-level hierarchical Bayesian model to produce a generative probabilistic model of latent multinomial variables or "topics"
within a corpus. In this hierarchy, documents are a mixture of topics and topics are a mixture
each document to be associated with multiple topics. By using this approach,LDAprovides a fully generative model where both new terms and documents can be associated with
topics. In addition,LDAavoids thepLSIissue of overfitting. Also,LDAcan be applied to any discrete data set which caused a shift in the focus of later research from retrieving
search query relevant documents, where results are tailored for human consumption, to
the creation of statistically valid multinomial clusters.
2.2.2.1 Limitations
WhilepLSIandLDAprovided improvements on previous research and held wide-spread adoption, there are a number of practical problems with these approaches. First, both
ap-proaches require an explicit input parameter of the number of topics in the corpus. Neither
approach provides a way to automatically determine the appropriate number of topics nor
assess the comprehensibility of differing topic quantities. Second each term in the corpus is
given a probability for occurring in each topic, so the number of terms to select for any given
topic is an arbitrarily assigned number. Third, the topics generated by these approaches
have no associated titles or explanations and can be difficult to interpret. In most cases,LDA produces a few coherent topics that can easily be manually assigned titles or explanations,
but many of the resulting topics are incoherent and unusable. AlthoughLDAutilizes the concept of perplexity, defined as the ability for the model to integrate new documents, this
concept does not relate to human notions of coherence and comprehensibility. Beyond
claims of valid probability distributions over a set of terms, the authors ofLDAmake no claims of coherent validity of the resulting topics. Because of this, a significant amount of
topics that are incoherent. Fourth, these approaches provide no relationships or hierarchies
between topics. Fifth, the coherent topics generated are usually very broad in nature. They
will typically describe types of objects in the corpus as opposed to specific object aspects.
Later research addresses some, but not all, of these issues.
2.2.2.2 Topic Coherence
To improve automated scoring of topic coherence two metrics were proposed (Newman
et al. 2010b; Mimno et al. 2011). Both approaches were designed by creating statistical
formulas to model human judges evaluations ofLDAtopic outputs.
Newman et al. (2010b) asked 70 human judges to score topics for "usefulness" on a
scale of 1 to 3. The term "usefulness" was vaguely defined so as to let judges make their own
decisions. Possibly due to their vague explanation of "usefulness", human judges did not
always agree. The inter-rater agreements as measured by Spearman rank correlation varied
from 0.49 to 0.76 across multiple domains. Despite this, the authors created an approach
to mirror the inter-rate agreement score based on pointwise mutual information between
each word pairing in a topic. The distributional probability for each word was computed by
counting word co-occurrence frequencies across a sliding window over external resources
such as Wikipedia. Their measure met or exceeded the inter-rater correlation scores.
(New-man, Bonilla, and Buntine 2011) modifiedLDAto maximize the coherence of topics as measured by this approach.
Mimno et al. (2011) used two medical experts to evaluate topics from medical paper
abstracts as "good", "intermediate", or "bad". After scoring the topics, the experts came
external resources, Mimno et al. (2011) used document co-occurrence frequency to measure
the coherence of topics where positive values were considered "good" topics and negative
values were considered "intermediate" or "bad". By reducing the problem to two states,
"good" and "not good", this approach resulted in 0.94 precision when compared to the
expert gold standard.
2.2.2.3 Evaluating Coherence Metrics
To measure the value of these approaches, Stevens et al. (2012) compared the coherence of
LDAandLSItopics using the approaches from Newman et al. and Mimno et al. Stevens et al. performed this evaluation by measuring both average coherence across all topics
and the entropy of topic coherence defined as the amount of loss in coherence from the
most coherence to the least coherence topic. Their results provided a strong argument for
usingLDAoverLSI, which is not surprising giving the improvementsLDAoffers. However, most importantly they found that each topic coherence measure included a smoothing
factor which heavily influence both the average coherence and the coherence entropy. This
finding brings into question the absolute truth of these measures.
2.2.2.4 Increasing Topic Specificity
To improve the specificity of the topics generated byLDA, Titov and McDonald (2008b) created an expansion called Multi-GrainLDA(MG-LDA). The purpose ofMG-LDAwas to include the creation of "local" topics which consist of rateable aspects of objects. Titov
showed that local topics can be representative of rateable aspects for hotel reviews. Titov
and McDonald (2008a) provided an extension toMG-LDAto incorporate sentiment analysis for the output topics. While their approach provides an improvement on the coherency of
topics, it is still bounded by other problems ofLDA: determining the number of topics, no topic titles, and no relationships between topics.
2.2.3
Hierarchical Models
Blei et al. (2003) introduced a separate line of statistical modeling research involvingLDA. In an approach they called hierarchical Latent Dirichlet Allocation (hLDA), they proposed
to useLDAin such a manner so that it created a single hierarchy ofLDAtopics where parent topics were more general than their children. This approach is based on a concept
called the nested Chinese restaurant process (nCRP). This approach is based on the Chinese
restaurant process metaphor where there are an infinite number of tables in a single Chinese
restaurant. As customers enter the restaurant, the table they sit at as well as the food they
eat is determined by a probability distribution based on the customers that have already
entered, been seated, and served. In thenCRPmetaphor, there are an infinite number of restaurants with an infinite number of tables. There is a single root restaurant that each
customer first visits. At each seat of each table there is a card which directs the customer
to another seat at another table in another restaurant. This process continues until a
finite number of restaurants have been visited. By applying this concept toLDA, tables are considered topics, customers are considered documents, and meals served at a seat
are considered terms. Thus it creates a nested series of Dirichlet distributions that branch
topics is determined during the construction of the hierarchy rather than as a fixed input
parameter. In the resulting output, all nodes in the hierarchy are standardLDAoutputs with the root node typically consisting of functional or "stop" words (e.g., "the", "of", "a")
common to all documents while leaf nodes are more specific sets of terms. In this first
presentation ofhLDA, the depth of the tree must remain fixed and each document can only traverse one path from root to a single leaf. So while this approach improvesLDAin that it creates a hierarchy of topics that advance from general parents to more specific children,
all documents much share the same number of topics (due to the fixed depth of the tree),
topic titles must still be manually determined, and documents must follow a single path
through the tree (so potential topics within the document could be disregarded in favor of
more probable topic paths). Also this approach has problems overcoming local maxima
and requires numerous randomized attempts in order to determine the most probable
posterior likelihood trajectory.
Teh et al. (2006) proposed a modification tonCRPwhich they called the Chinese restau-rant franchise. This approach provides a more advanced statistical method by sampling
Dirichlet distributions from higher-level Dirichlet distributions. The authors title this
method a Hierarchical Dirichlet Process (HDP). Similar tohLDA, anHDPis able to automat-ically discover the statistautomat-ically optimal number of topics. However, this approach requires a
nested structured dataset that pre-defines the topic hierarchy. Although the requirement
of a structured data set is restrictive, later research leveraged the statistics behindHDPto provide more flexible topic models.
gen-erating topics and automatically finding relationships between them. In their Correlated
Topic Model (CTM), Blei and Lafferty abandon Dirichlet distributions and instead adopt a
more flexible topic proportion distribution model based on logistic normal distributions.
CTMdraws topics from the logistic normal distribution and uses a covariance matrix to specify the correlation between documents. While this approach provides an automatic
technique for finding relationships between topics, it has serious drawbacks that ultimately
resulted in no significant impact on latter research. Specifically, this approach can only
find associations between pairs of topics, and thus cannot find clusters of similar topics
nor topic hierarchies. Also, the number of entries in the covariance matrix grows as the
square of the number of topics. Later research returned to Dirichlet distributions with more
inventive and advanced statistical models for creating hierarchies.
Adding to the existing body of research, Li and McCallum (2006) introduced the Pachinko
Allocation Model (PAM).PAMis a more generalized version ofLDA. It expands the standard three-level hierarchy ofLDAwith a fourth level called super-topics. The lowest level of the hierarchy remains the single term leaf nodes, while the next two levels are sub-topics
consisting of standardLDAtopics and the newly introduced super-topics. The root node is fully connected to all super-topics. The super-topics in turn are fully connected to all of
the sub-topics which are in turn connected to select leaf nodes or terms from the corpus.
Similar toLDA, documents are a mixture of topics, with the topics being drawn from the sub-topic level of the graph. Unlike hLDA, documents inPAM do not traverse the graph from root to leaf, but rather are only given a probability mixture of the resulting
sub-topics. To validate their approach, Li and McCallum used five human judges to compare
sub-topics to be more coherent. WhilePAMproved more coherent thanLDA, it still required a manual determination of number of topics. Also it is considered more difficult thanLDA to determine the appropriate number of topics.
As an improvement toPAM, Li, Blei, and McCallum (2007) introduced the Nonparamet-ric Bayesian Pachinko Allocation Model (NPB-PAM). This research combinedPAMwith the Dirichlet structure ofhLDAandHDP. By combining these approaches,NPB-PAM is able to learn both the number of topics (a key feature ofhLDAandHDP) as well as how the topics are correlated (a key feature ofPAM). However, it is still bounded by the four-level hierarchy ofPAM. Topics are organized into multiple levels in a hierarchy where each level is modeled with anHDPto capture uncertainty in the number of topics. The super-topics ofPAMnow use a two levelnCRPbased onHDPprior distributions while the sub-topics are a three levelnCRPbased onHDP. To validate their results, they created a small synthetic data set against which to measure topic hierarchy accuracy. They also provided their own
qualitative analysis of sub-topic examples comparingNPB-PAMtoPAM. The results of this research provided compelling evidence to abandon previous parametric non-hierarchical
approaches of topic modeling and instead to focus on nonparametric Bayesian approaches.
Returning to their originalhLDAresearch from 2003, Blei, Griffiths, and Jordan (2010) proposed an improvement tohLDAbased on the latest advances in nonparametric Bayesian statistics. In their new version ofhLDA, the authors introduced a system that can handle both an infinite breadth of topics as well as an infinite depth of hierarchical topic
relation-ships. This is a significant improvement over the previous hierarchical approaches because
it removes both the requirement for manually determining the number of topics as well as
However, it still does not allow documents to follow multiple paths through the hierarchy
tree, and it is also bounded by the requirement for manual analysis and explanation of the
resulting topics. In addition the ability of this type of model to learn both the number of
topics as well as their relationships comes at the price of ever increasing computational
and statistical complexity.
The most recent work relevant to this discussion of statistical topic modeling was
pre-sented by Kim et al. (2012). In this paper, the authors describe a modification tonCRPwhich they call the recursive Chinese restaurant process (rCRP). The significant improvement
ofrCRPovernCRPis the ability for this approach to model a document as a distribution across all topics in the graph. Thus it removes the more strict requirement ofnCRPthat a document may only traverse one path in the graph from root to leaf. However, all other
restrictions ofnCRPremain. Based on the results tested against a small synthetic data set as well as heldout likelihood, the authors show therCRPis indeed an improvement over previous approaches. In their most recent work, the authors extend their approach to
include sentiment modeling (Kim et al. 2013b).
2.2.4
Taxonomy Models
In work more similar to that proposed in this dissertation, some have incorporated
tax-onomies into their statistical topic models. Boyd-Graber, Blei, and Zhu (2007) proposed
a modification ofLDAfor word sense disambiguation, where random paths through a taxonomy hierarchy were used in conjunction with Dirichlet distributions to determine the
most probable clusterings of terms into topics. Not surprisingly, they found that the topics
Smyth, and Chemuduganta (2011) introduced an approach that again extendedLDAwith a taxonomy hierarchy, but in such a way that the taxonomy topics were treated asLDAtopic distributions except for their fixed set of terms. This results is a set of standard flatLDA topics along with a set of topics from the taxonomy hierarchy. Both of these approaches
used taxonomies as supporting data points for the underlying statistical topic model. We
take the opposite approach and consider the statistics as a support for the taxonomy.
2.2.5
Discussion
The area of statistical topic modeling has evolved from simple term frequency, to
term-by-document matrices, to flat sets of topics, to hierarchies of topics. While the most recent
iterations provide fully automated approaches for determining the number of topics as
well as their hierarchical relationship, their results are not tested against human judgments
outside of small synthetic test sets. In many cases the example outputs found in the literature
contain many of the same incoherent qualities attributed to LDA. Also, none of these statistical models provide an automated approach for creating descriptions or titles for the
topics generated. Compared with taxonomy approaches, statistical topic models are not
grounded in human concepts of relatedness and consistently produce less coherent topics.
2.3
Taxonomy Based Topic Hierarchies
Linguistic taxonomy research is grounded in human concepts of the relationships between
terms and topics. Similar to statistical topic modeling, it focuses on clustering terms into
researchers use structured external resources built on human concepts of relatedness.
Because of this taxonomy research generally falls into one of two categories: research that
creates or extends taxonomies (Hovy, Navigli, and Ponzetto 2013) and research that uses
these taxonomies to build topic hierarchies for a given corpus (Medelyan et al. 2013a). While
there has been significant research in the creation and expansion of taxonomies (Hearst
1992; Caraballo 1999; Navigli, Velardi, and Gangemi 2003; Ben-Yitzhak et al. 2008; Ponzetto
and Navigli 2009; Ponzetto and Strube 2011), these approaches focus on the construction
of such taxonomies, not on their ability to identify topic hierarchies from a specific corpus.
Therefore they will not be discussed further. One of the primary applications of this research
lies in faceted search. Faceted search is the augmentation of standard key-word search
interfaces with selectable facets or topics identified from the key-word search results. This
type of search allows users to fine tune the key-word results based on topics of interest. When
compared to traditional results, studies show that users prefer interfaces that group results
into organized topics (Chen et al. 1998; Pratt, Hearst, and Fagan 1999; Käki 2005). Ensuring
that the topics and their organizations are based on human concepts of taxonomy and
relatedness is key. In fact, such hierarchical interfaces are becoming standard in information
architecture and enterprise search communities (Rosenfeld and Morville 2002; Yee et al.
2003; Weinberger 2005). Another area of research is the selection of the most useful facets
(Liberman and Lempel 2012; Vandic, Frasincar, and Kaymak 2013); however, this research
assumes that topic hierarchies have already been identified from a corpus and will not be
2.3.1
Resource Terminology
Before discussing the evolution of taxonomy based topic hierarchy research, let us provide
background knowledge of taxonomy resources and terms by using as an example the
pre-mier English language taxonomy, WordNet (Miller 1995). WordNet is a machine readable
dictionary and thesaurus containing thousands of terms in the English language. WordNet
divides terms into nouns, verbs, adjectives, and adverbs. Each term in WordNet is
associ-ated with a Synonymous Set or synset which is a set of terms that share a single meaning
or sense(synonymy). Each synset can be associated with synsets of opposing meaning
(antonymy). Each term can have many meanings or senses and thus be associated with
many synsets across parts of speech (e.g., the noun "fall" as in "season", the noun "fall" as in
"a tumble", the verb "fall" as in "to drop down"). If a term is associated with many synsets,
the term is considered polysemous and when found in a document the specific synset
implied by the usage in the text must be determined (word sense disambiguation). Miller
notes that determining which sense of a polysemous term should apply for a given context
is difficult to compute; however, given a specific domain each term is usually limited to
one sense. This assumption of "one sense per discourse" is used frequently in the related
taxonomy research. WordNet includes additional relationships between synsets based on
parts of speech. Noun synset relationships form a complex and deep hierarchy based on the
following: subordinate children (hyponymy), superordinate parents (hypernymy), part-of
relationships (meronymy), and whole-of relationships (holonymy). Verb synsets have a
similar although shallower hierarchy made of the following relationships: subordinate
children (troponymy), superordinate parents (hypernymy), and entailment relationships.
level of children satellite synsets, and satellite synsets have a single parent head synset.
Also head adjective synsets can be associated with the noun synsets of which they are
attributes. For example the adjective synset that contains the term "big" as in "of great
size" is an attribute of the noun synset "size" as in "the physical magnitude of something".
Adverb synsets are only associated with the adjective synsets from which the adverbs were
derived (pertainymy). While WordNet is used by many in the taxonomy literature, others
have focused on expanding the number of WordNet terms and their relationships, often
in a domain specific manner (Agirre et al. 2001; Alfonseca and Manandhar 2002; Agirre,
Alfonseca, and De Lacalle 2004; Agirre and De Lacalle 2004; Cuadros et al. 2005; Knopp,
Völker, and Ponzetto 2013).
2.3.2
Subsumption
Returning to taxonomy approaches for generating topic hierarchies, one of the earliest
such approaches was proposed by Sanderson and Croft (1999). As an early pioneer in
the literature when external resources were scarce and little tested, the authors did not
use an external taxonomy resource but instead presented an approach that both selects
terms from a corpus as well as relates those terms into hierarchies. The authors selected
terms by a combination of Local Context Analysis (Xu and Croft 1996), a technique based
on expanding the number of terms in a search query, and by selecting terms above a
givenTFxIDF threshold. Thus it becomes clear that taxonomy research originated with a stronger focus on creating hierarchies than on term selection since more powerful statistical
term identification techniques had already been developed but were not utilized for this
clustering, where multiple clusters of terms form a set of term hierarchies where each
hierarchy is a single topic. This is unlike polythetic clustering proposed by Rijsbergen (1979)
and later performed by Hearst and Pedersen (1996) where clusters may consist of multiple
topics. For each topic hierarchy, terms from the corpus were related to one another in
parent-child relationships via the proposed process ofsubsumption. The authors defined subsumptionas follows: nodes in a hierarchy consist of terms and parent nodes should subsume or encapsulate the concepts expressed by children nodes by the following formula:
P(x|y)≥0.8,P(y |x)<1. Given two termsx andy,xsubsumesy if the documents which containy are a subset of the documents that containx. The value of 0.8 was chosen through informal analysis and is considered a relaxed value in order to allowx to subsumey even if all of the documents that containy do not also containx. While their approach handles polysemy in theory, they avoid the issue of ambiguous polysemous terms by using highly
correlated documents and working under the assumption that each term will only have one
meaning given a single domain. To evaluate their results, the authors ran a user study. They
presented users with various parent-child pairs from both theirsubsumptionoutput as well as randomly selected pairs and asked if each pairing was interesting, uninteresting, or
unknown. They did not ask if they were related, arguing that knowing this was not possible
without examining the document text. If a user stated that the pair was interesting, the
user was asked to define the association between the two terms in terms of parent-child,
part-of, similar, or opposite. Only 23% of the interestingsubsumptionpairs were found to hold parent-child relationships. These results show two main problems with this approach.
single terms rather than sets of terms that share similar meaning which potentially adds to
the incorrect relationships found in the hierarchies.
2.3.3
WordNet Approaches
To create topic hierarchies more in line with human judgment, an improvement was
intro-duced by Stoica and Hearst (2004). Their approach selected terms from the corpus, retrieved
the hypernym path from WordNet, constructed a tree from the paths, and output a
com-pressed version of the combined trees. They chose to select only a subset of words from the
corpus using a technique similar toTFxIDF (Mitchell 1997). The(distribution) of a word w is the number of documents in the corpus that the word occurs in. Words are ordered by their(distribution), the highest(distribution) word is selected and removed from the ordering, all documents containing the selected word are removed from the corpus, all
re-maining word(distributions) are recomputed using the remaining documents. The process repeats until all documents have been removed. To construct the topic hierarchy, WordNet
is queried for all selected terms. The results for each term query from WordNet provide a
hypernym relationship path from the query term to the highest level of abstraction found
in WordNet. Since words may have multiple senses or meanings in WordNet, the authors
made a decision to ignore word sense disambiguation. Instead, the first sense retrieved
from WordNet is assumed to be correct since WordNet orders results from the most general
meaning to the most specific. After retrieving all hypernym hierarchies from WordNet,
similar hierarchies are merged together, the highest levels of WordNet are removed due
to their high level of ambiguity (e.g., "entity"), and the remaining hierarchies are pruned.
with similar meaning are combined, rarely used synsets are dropped, and parents with few
children are removed. While this approach was the first to produce topic hierarchies based
on a human generated taxonomy, the term selection process is again based on a variation
ofTFxIDFrather than better performing statistical methods. It is also important to note that WordNet is not exploited to its maximum potential as only terms which are nouns are
selected from the corpus and only noun hypernym hierarchies are queried from WordNet.
In 2007, Stoica, Hearst, and Richardson improved their previous research with the
de-velopment of Castanet, again based on the WordNet taxonomy. They refer to this type
of system as automated hierarchical faceted metadata creation or a hierarchical faceted
metadata system (HFC). Castanet, as in their previous approach, creates a set of hierarchies,
each of which correspond to a different topic or facet. As with most taxonomy approaches,
their results are focused on search and collection interface applications. Their approach has
four major steps: 1) select target terms, 2) build the core hierarchies using only
unambigu-ous terms, 3) disambiguate remaining terms, 4) compress the tree and remove top-level
categories. Once again they select only nouns and do so using aTFxIDFthreshold similar to Sanderson and Croft (1999). Also they do not perform any part of speech tagging and thus
ignore terms that are not exclusively nouns. The resulting unambiguous hypernym noun
hierarchies from WordNet form the core set of hierarchies. To handle some word sense
disambiguation, they use Magnini and Cavaglia (2000) resource Wordnet Domains which
assigns a domain to every noun synset in WordNet (e.g., "anatomy", "computers"). The
most represented domains across the corpus are determined, and in a manual step an
in-formation architect selects the subset of domains that most likely apply to the corpus. Thus
Remaining disambiguous terms are added to the hierarchies based on the number of other
documents that already make up existing hierarchy paths. If no hierarchy path is clearly
more frequent, than the first sense or most common sense from WordNet is utilized. Tree
compression and pruning is performed in the same manner as their initial research (Stoica
and Hearst 2004). Rather than focusing on everyday users, Castanet is designed for use
by experts in the field of information architecture. They aim to make the job of such an
architect easier. To evaluated their approach, Castanet’s output is compared with a baseline
of most frequent words,LDA, andsubsumption. They asked information architects to vote if they would be likely to use output from these approaches in their work. The results from
LDAwere strongly rejected as quality outputs, receiving 0% positive approval. In fact the LDAcomparison was removed from the user study before completion due its abysmal performance.subsumptionoutput received 38% positive approval. The baseline of most frequent words received 74% positive approval. However, Castanet was considered the
most useful with 85% responding positively towards utilizing this approach in their work.
2.3.4
Combining Taxonomies
The next major improvement to taxonomy based topic hierarchy creation was introduced
by Dakka and Ipeirotis (2008). A highly influential portion of this research was a small user
study performed to help the authors understand what terms humans use to describe topics
in news articles. The authors found that 65% of the terms assigned by the human judges as
topic labels were general high level topics, such as "location", "history", and "people", and
that these label terms did not exist in the news report corpus. Based on these findings, they
level topic label terms did not exist in the corpus, they would select only names of people
and terms that matched Wikipedia article titles from the corpus. Based on these selected
corpus terms, they selected additional external terms via four methods: 1) querying Google
based on the corpus terms and selecting the most frequent terms in returned snippets, 2)
similar to Castanet they queried noun hypernym hierarchies from WordNet, 3) selecting
Wikipedia titles of the most frequently linked to and from pages of the corpus term pages,
4) they merged terms based on Wikipedia redirects and anchor tags (e.g., "Hillary Clinton"
and "Hillary R. Clinton" both merge based on their mutual redirect to the "Hillary Rodham
Clinton" Wikipedia article page). Using the selected corpus term and external term lists
they selected a single smaller list of topics based on the assumption that high level topic
terms are infrequent in the corpus list but frequent in the external list. They selected terms
that occurred more frequently in the external corpus using a difference in term frequency
as well as a difference in term ranking. They applied Log Likelihood Ratio to double check
that the resulting selected terms are in fact statistically significant in the external term list
compared to the selected corpus term list. However, they do not maximize the utility of
this method and attempt to use this statistical measure to find terms that may have been
excluded by their initial selection process. Hierarchies of the resulting topic term list are
then generated via thesubsumptionprocess. They conclude their research with the most extensive user study to date by leveraging the power of Amazon Mechanical Turk1. However,
they did not conduct the study in such a way that its results can be generalized into a
testbed against which to compare other approaches. Instead they asked users to read news
articles and provide up to 10 terms for each article. The terms could be identified based
on terms in the article or the user’s own conceptions. Terms identified had to be clearly
defined, mutually exclusive, and cover as many aspects, properties, or characteristics of the
article as possible. This resulted in a single pool of terms representing all topics discussed
by the articles, ignoring notions of hierarchy. The authors then evaluated the number of
terms selected from their approach that matched terms in the user study pool of terms.
While this resulting pool of terms could be used to evaluate other approaches, it does
not cluster the terms into topics or create hierarchies which is the key output of most
approaches. To evaluate their hierarchy, they asked users to rate the hierarchy generated
by their approach, but did not ask users to generate their own hierarchy against which
other hierarchies might be compared. While this approach incorporated many different
external sources to create topic hierarchies, it made some critical assumptions that later
research adhered to. First, they assume that names of people and Wikipedia titles are the
only important terms to be found in a corpus of documents. This approach is not domain
independent. Consider product reviews for shoes or cameras where aspects of the product,
the topics most important to consumers reading reviews, are discussed explicitly in the
review text while names of people are not usually mentioned nor are relevant topics. Also,
this approach, as well as Castanet, assume that only nouns are important for determining
topics. Nouns are not unimportant, but they can only answer the question of "what" is being
discussed. Other parts of speech, such as adjectives, answer different and sometimes more
important questions of "why" or "how" certain topics are being discussed. By selecting
only nouns, the authors have limited the results of their hierarchy.
The most recent research presents the F-STEP system (Medelyan et al. 2013b), built to
formats of data can be input and text can be extracted, 2) term selection which, similar to
Dakka and Ipeirotis, consists of selecting names of people and terms that correspond to
Wikipedia article titles, as well as selecting terms that occur in a supplied domain specific
taxonomy (if such a resources is provided), 3) linked data annotation where databases such
as Freebase and DBpedia are queried for associated concepts to the selected terms, 4) when
a selected term is found in multiple external database sources disambiguation is performed
by a comparison of the term co-occurrence between the original document and external
sources, 5) terms are merged via links between items in the external databases. While
the authors claim domain independence, without extensive domain specific taxonomy
databases (few of which exist) their approach falls prey to the assumptions of Dakka and
Ipeirotis that persons and Wikipedia titles provide the basis for all topics in a corpus.
Evaluation of their results is performed against small manually-built taxonomies, qualitative
evaluation of concepts and relations, and feedback from experts.
2.3.5
Discussion
While taxonomy approaches have advanced to include many ways of incorporating
vari-ous external taxonomy resources, the term selection processes used by these approaches
has remained stagnated. Term selection performed by taxonomy research either involves
variations ofTFxIDFor manually selected term types; however, the power of automated statistically significant term selection is a process that has been advanced significantly by
statistical topic models. A combination of the term selection from topic models with the
2.4
Keyphrase Extraction
Automatic keyphrase extraction is the process of determining the most important terms
for a given document with the goal of these terms covering the main topics discussed
in the document (Turney 2000). The extraction of these terms enables fast and accurate
searching of documents as well as improves text summarization (Zhang, Zincir-Heywood,
and Milios 2004), categorization (Hulth and Megyesi 2006), opinion mining (Berend 2011),
and document indexing (Gutwin et al. 1999).
Keyphrase extraction is a challenging task where the state-of-the-art performs lower
than many core NLP tasks (Liu et al. 2010). Many aspects of this task make it challenging.
First as document length increases, the number of potential keyphrases increases and thus
so does the difficultly of correctly identifying the correct keyphrases. While keyphrase
ex-traction research has focused significant effort on various domains including news articles,
scientific paper abstracts, and image captions, the domain of product reviews shares this
length challenge as reviews range from short phrases to multiple well-written paragraphs.
Additionally, while many keyphrase extraction approaches make use of the structure found
in certain types of documents, such as abstracts and introductions in scientific papers (Kim
et al. 2013a), unstructured text increases the difficulty of this task. Some have tried to detect
changes in topic as a way to improve performance on unstructured text (Kim and Baldwin
2012). Finally, in structured text it has been found that keyphrases tend to be correlated to
one another (Turney 2003; Mihalcea and Tarau 2004); however unstructured and informal
text can contain many uncorrelated topics which prevents such approaches from being
Most automatic keyphrase extraction approaches tackle this problem in two steps:
extracting a set of candidate keyphrases from the corpus and determining which of the
can-didate keyphrases are the correct keyphrases. While most approaches use similar cancan-didate
keyphrase extraction methods, there are a number of different approaches to determine
the correct keyphrases. We should note that there are many approaches which use
super-vised methods to determine correct keyphrases, however we focus on the unsupersuper-vised
approaches as they are most relevant to the work of this dissertation.
These approaches are typically evaluated against a gold standard. A list of publicly
available keyphrase gold standard data sets is shown in Table 2.1. The typical approach
to measure keyphrases against a gold standard, used by the SemEval-2010 shared task,
creates a mapping via exact match which is then scored by standard precision, recall, and
F-score. Since exact match can be overly strict, researchers have developed a number
of systems for automatic evaluation via partial match. These systems are often used in
machine translation and summarization evaluations and include Blue, Meteor, Nist, and
Rouge. However these systems only offer a partial solution as they can only detect a subset
of near-misses to exact match terms (Kim, Baldwin, and Kan 2010). Alternatively, keyphrase
ranking can also be used as an evaluation metric to distinguish between systems that score
the same number of exact matches (Liu et al. 2010) or to determine which systems rank the
most correct keyphrases above incorrect candidate keyphrases (Zesch and Gurevych 2009).
2.4.1
Extracting Candidate Keyphrases
To limit and focus the set of candidate keyphrases to those most likely to be important, most
Table 2.1: Publicly available keyphrase gold standard datasets
Source Dataset/Contributor Doc Count
Paper Abstracts Inspec(Hulth 2003) 2,000
Scientific Papers
NUS corpus (Nguyen and Kan 2007) 211 citeulike.org (Medelyan, Frank, and Witten 2009) 180 SemEval-2010 (Kim et al. 2010) 284 Technical Reports NZDL (Witten et al. 1999) 1,800 News articles DUC-2001 (Wan and Xiao 2008) 308 Web Pages (Hammouda, Matute, and Kamel 2005) 312 Emails Enron corpus (Dredze et al. 2008) 14,659
A list of universally unimportant words, or stop words, can be used to ignore irrelevant
keyphrases (Liu et al. 2009b). Some approaches only select terms for specific parts of
speech (Mihalcea and Tarau 2004; Wan and Xiao 2008; Liu et al. 2009a). Others target
only keyphrases that correspond to Wikipedia title (Grineva, Grinev, and Lizorkin 2009).
Finally some researchers select specific lengths of n-grams (Witten et al. 1999; Hulth 2003;
Medelyan, Frank, and Witten 2009) or noun phrases (Barker and Cornacchia 2000; Wu et al.
2005).
2.4.2
Graph-Based Ranking
This approach determines importance of candidates keyphrases by computedrelatedness between keyphrases using co-occurrence (Mihalcea and Tarau 2004) and semantic
related-ness (Grineva, Grinev, and Lizorkin 2009). Each candidate keyphrase is assigned a node in
the graph and edges are created between related nodes where the edge weight is assigned
based on the syntactic or semantic relevance. Each node is recursively scored based on the
be ranked by score where the nodes with the highest rank represent the most important
keyphrases. However, this approach ignores the concept of topics and therefore does not
guarantee that the main topics will all be represented by the selected important keyphrases.
TextRank (Mihalcea and Tarau 2004) is the most well-known graph-based ranking approach.
2.4.3
Topic-Based Clustering
Motivated by the concept that keyphrases should be associated with topics and to
en-sure coverage across all main topics, multiple researchers created approaches to group
keyphrases into topics.
KeyCluster (Liu et al. 2009b) semantically clusters similar candidate keyphrases using
Wikipedia and co-occurrence-based statistics and performs better than TextRank. However,
this approach assumes that all topics are of equal importance, an assumption that is not
necessarily true for all domains.
Topical PageRank (TPR) (Liu et al. 2010) is designed to overcome the assumption of topic
equality. TPR usesLDAtopics to cluster candidate keyphrases and performed TextRank once for each topic. This allows for TextRank to determine the most important keyphrases
for each topic andLDAto determine the probability that a given document contains each topic. Thus keyphrase candidates from the most probable topics will be selected over those
candidates from less probable topics. TPR was shown to outperform bothTFxIDF and TextRank, but was not compared to KeyCluster although in theory it should outperform
that approach as well.
CommunityCluster (Grineva, Grinev, and Lizorkin 2009) is similar to TPR as it weighs
keyphrase candidate from important topics, CommunityCluster selects all keyphrase
candi-dates from important topics. It thus assumes that less important candidate in an important
topic should still be included. Interestingly, it does not lose precision and actually increases
recall when compared toTFxIDFand TextRank.
2.4.4
Simultaneous Learning
Based on the potential benefits of performing keyphrase extraction and text summarization
simultaneously, Zha (2002) proposed the idea that sentences important to summarization
contain important keyphrases and important keyphrases occur in summarization
sen-tences. Based on this idea Zha created the first graph-based approach for simultaneous
summarization and keyphrase extraction. This work was further extended by Wan, Yang,
and Xiao (2007) who included two additional concepts: summarization sentences should
be connected in the graph to other summarization sentences and keyphrases should be
connected to other keyphrases. Thus Wan, Yang, and Xiao combined the ideas of Zha (2002)
along with TextRank Mihalcea and Tarau (2004) to create an approach using three ranked
graphs that showed improvement over both.
2.4.5
Language Modeling
Most similar to the work proposed in this dissertation, Tomokiyo and Hurst (2003) utilize
multiple language models trained on a foreground and background corpus. Alanguage modelis often used in speech recognition to resolve acoustically ambiguous utterances. Language models are trained on a corpus to determine a probability value for each phrase

![Figure 3.4:(a) noun synset hierarchy for[ [fall, autumn] synset (b) adjective hierarchy forslenderly, slimly, slightly] adverb synset: root synset is [body weight] attribute noun synset,followed by head adjective synset, satellite adjective synset, and pertainym adverb synset](https://thumb-us.123doks.com/thumbv2/123dok_us/1493567.1182826/58.612.107.522.108.470/adjective-hierarchy-forslenderly-attribute-adjective-satellite-adjective-pertainym.webp)