623
All Rights Reserved © 2013 IJARCSEEAnalyze the Different Kernel Function in SVM for IDS
Krishna Kant Tiwari 1, Susheel Tiwari 2, Sriram Yadav 3 1
Student of Millennium Institute of Technology, RGPV University, Bhopal, India 2
Asst. Professor (CSE), Millennium institute of technology, RGPV University, Bhopal, India 3
Asst. Professor & Head (CSE), Millennium institute of technology, RGPV University, Bhopal, India
Abstract— In these days an increasing number of public and commercial services are used through the Internet, so that security of information becomes more important issue in the society information Intrusion Detection System (IDS) used against attacks for protected to the Computer networks. IDS used for monitoring and detecting user behaviour to identify intruders. The field of intrusion detection has received increasing attention in recent years. One reason is the explosive growth of the Internet and the large number of networked systems that exist in all types of organizations. Intrusion detection techniques using data mining have attracted more and more interests in current years. As an weighty application area of data mining, they aim to meliorate the great burden of analysing huge volumes of audit data and realizing performance optimization of detection protocols. The objective of this dissertation is to try out the intrusion detection on large dataset by classification algorithms binary class support vector machine and improved its learning time and detection rate in the field of Network based IDS.
Keywords— intrusion detection, data mining, ANN
I. INTRODUCTION
Intrusion detection is defined [1] as the process of intelligently monitoring the events occurring in a network, or computer system analysing them for signs of violations of the security policy. the primary aim of intrusion detection systems (ids) is to protect the confidentiality, accessibility and probity of critical networked information systems. an ids is exact if it does not trigger spurious indication and if it don't miss intrusions. too many false positives are detrimental, as the system administrator will be crushed by warnings. And any false negative can have direct distinctions. As a result, IDSs aim to be as exact as possible (keeping the number of false negatives low but at the same time maintaining a low level of false positives. Classification Intrusion Detection Systems, Latest IDSs fall into two categories:
Network-based Intrusion Detection Systems (NIDSs)
Host-based Intrusion Detection Systems (HIDSs).
These systems can be categorized based on which events they monitored, how they catch dust information and how they
deduce from the information that an intrusion has happened. IDSs that scrutinize data circulating on the network are called Network IDSs (NIDSs), while IDSs that reside on the host and collect logs of operating system-related events are called Host IDSs (HIDSs). IDSs may also vary according to the technique by which they detect intrusions.
Network-Based IDS, because they only scrutinize network traffic [2], NIDSs do not benefit from running on the host. As a result, they are often run on dedicated machines that observe the network flows, sometimes in conjunction with a firewall. In this case, they are not affected by security vulnerabilities on the machines they are monitoring. Nevertheless, only a limited amount of information can be inferred from data gathered on the network link. Besides, widespread adoption of end-to-end encryption further limits the amount of information that can be gathered at the network interface .Another major shortcoming of NIDSs is that they are oblivious to local root attacks. An authorized user of the system that attempts to gain additional privileges will not be detected if attack is performed locally. An authorized user of the system may be able to set up an encrypted channel when accessing the machine remotely.
HOST-BASED IDS, HIDSs have an ideal vantage point [2].
624
All Rights Reserved © 2013 IJARCSEEA. Intrusion Detection Techniques
Intrusion Detection Systems used one of the detection techniques [3]: statistical anomaly based and signature based.
Signature/Misuse based IDS Statistical/ Anomaly based IDS
B. Signature/Misuse Based IDS
The signature based IDS also known as misuse detection looks for a specific signature to match, signalling an intrusion. Provided with the signatures, they can detect many or all known attack signature, but they are of little use for as yet unknown attack technique. Most popular intrusion detection systems fall into this category. This means that an IDS using misuse detection will only detect known attacks or attacks that are similar enough to a known attack to match its signature.
C.Statistical/Anomaly Based IDS
Another approach to intrusion detection is called anomaly detection. Anomaly detection applied to intrusion detection and computer security has been an active area of research since it was originally proposed by Denning (1987). Anomaly detection algorithms have the advantage that they can detect new types of intrusions as deviations from normal usage. Here, given a set of normal data to trained from, and given a new part of test data, the ambition of the intrusion detection algorithm is to determine whether the test data belong to ‘‘normal’’ or to an anomalous behavior. However, anomaly detection schemes suffer from a high rate of negative alarms. This occurs primarily because previously unseen (yet legitimate) system behaviors are also recognized as abnormal, so flagged as potential intrusions.
II. Related works of IDS
A. Machine learning
Application and development of specialized machine learning techniques is gaining increasing attention in the intrusion detection community. A various way of learning techniques proposed for different intrusion detection problems can be roughly classified into two broad categories:
Supervised (Classification) Unsupervised ( Clustering)
The supervised learning methods significantly outperform the unsupervised ones if the test data contains no unknown attacks. Following are the data mining related work for intrusion detection.
B. General and Systematic Methods for
Intrusion Detection
Wenke Lee and Salvatore Stolfo [9] have developed systematic methods for intrusion detection. They have built a framework using data mining techniques to discover consistent and useful patterns of system features that describe program and user behaviour, To detect anomalies and known intrusions, they have used a set of relevant system features to compute (with inductively learned) classifiers. Two major data mining algorithms they have implemented are: the association rules algorithm and the frequent episodes algorithm, which are used to recognize intra- and inter- audit record patterns. To meet the challenges of both efficient learning (mining) and real-time detection, they have proposed an agent-based architecture in which the learning agents continuously compute and provide the updated models, while a detection agent is equipped with a (learned and periodically updated) rule set from the remote learning agent.
C. Application of ML Algorithms to KDD
IDS Dataset
A simulation study was performed (Mahesh Sabhnani, Gursel Serpen [10]) to assess the performance of a comprehensive set of machine learning algorithms on the KDD 1999 Cup intrusion detection dataset. Simulation results demonstrated that for a given attack category certain classifier algorithms performed better. Consequently, a multi-classifier model that was built using most promising classifiers for a given attack category was evaluated for examine, denial-of-service, user-to-root, and remote-to-local spike categories. The proposed multi-expert classifier showed improvement in detection and false alarm rates for all attack categories as compared to the KDD 1999 Cup winner. Furthermore, degradation in cost per test example was also achieved using the multi-classifier model. However, none of the machine learning classifier algorithms evaluated was able to perform detection of user-to-root and remote-to-local attack categories significantly (no more than 30% detection for U2R and 10% for remote-to-local category). In conclusion, it is reasonable to assert that machine learning algorithms employed as classifiers for the KDD 1999 Cup data set do not offer much promise for detecting U2R and R2L attacks within the misuse detection context.
D. Adaptive Framework for NIDS by Using
GBMLA
625
All Rights Reserved © 2013 IJARCSEEnormal network packet. Among different techniques, steady state genetic - based machine leaning algorithm (SSGBML) objective of this paper was to incorporate different techniques into classifier system to detect and classify intrusion from which will be used to detect intrusions. Steady State Genetic Algorithm (SSGA) and 0th Level Classifier system (ZCS) are investigated. SSGA is used as a find mechanism for classifiers, although ZCS plays the role of detector by matching incoming environment message with classifiers to determine whether it is normal or intrusion Also, matching difference between environment message and classifier rules became adaptive according to DR values. Discover engine has been improved by using SSGA instead of SGA taking into account the suitable method for selection. Also, when performing some training on SGA, we dramatically reached premature convergence early. So, training phase was stopped and not continued. The proposed work focused on reducing the number of features to be used in classifying and detecting various attacks types.
Machine Learning Framework for NAD
Using SVM and GA
(Taeshik Shon, Yongdue Kim, Cheolwon Lee, and Jongsub Moon [12]) concentrates on machine learning techniques for detecting attacks from internet anomalies. His machine learning framework consists of two major components: Genetic Algorithm (GA) for feature selection and Support Vector Machine (SVM) for packets classification. This framework consists of four components as follows. 1. Feature selection via GA (genetic algorithm) 2.data pre-processing; 3.data analysis via our modified SVM; and 4.testing and comparison with real-world products. For Enhanced SVM and one-class SVM, the dataset contained 100,000 normal packets for training and 1,000 to 1,500 various kinds of packets for testing. In this SVM experiments, he used SVMlight for a supervised SVM and LIBSVM for an unsupervised SVM and set the parameters as follows c between 0.9 and 10, d in the polynomial kernel at 1, σ in a radial basis kernel at 0.0001, and K and θ in a sigmoid kernel at 0.00001, respectively. In the case of single-class SVM, the RBF kernel provided the best effective performance (94.65%); however, the false positive rate was high. Moreover, he could not see the results of the sigmoid kernel experiment because the sigmoid kernel of one-class SVM was over fitted
An Incremental SVM for IDS Based on Key
Feature Selection
Here (Yong-Xiang Xia, Zhi-Cai Shi, Zhi-Hua Hu [13]) has proposed a method of detecting intrusion using incremental SVM based on key feature selection. A center SVM up short the scattered samples and incorporates them to build the incremental SVM for locals. By eliminating the redundant
features of sample tuple, the space dimension of the sample shortages of SVM time-consuming of training and massive data tuple is reduced. Using this process, it can overcome the dataset storage. He uses KDD Cup 1999 dataset in which training data set contains 494,021 connection records, and the test data set contains 311,029 records. In his experiments, He samples the data only from the training data set and use in both the training and testing stages. He uses polynomial and Gaussian kernel function in LIBSVM and detection rate 99.85 % on 65 unit time and false positive rate 0% on 65 unit time.
An IDS Method Based On SVM and KPCA
Before the classifier (Yuan-Cheng LI, Zhong-Qiang Wang [14]) added a pre-process module. He uses principal components extracted from the input data using KPCA, which is the heart of the pre-process function, as input of the SVM classifier that distinguish the normal and abnormal actions. He uses some sample data out of 494021 training and 311029 testing dataset and achieves the performance accuracy 98.5% in KPCA+SVM.
ACO Based NIDS and Feature Selection
626
All Rights Reserved © 2013 IJARCSEEIII.
M
ETHODOLOGY
A. KDD Dataset Description
The DARPA/MIT Lincoln Lab evaluation (IDEVAL) data set has been used to test a large number of intrusion detection systems [7]. The data can be used to test both host based and network associated systems, and both signature and anomaly detection systems. The 1998 network data has also been used to develop the 1999 KDD cup machine learning competition. The data tuple we used in our research is the data set for 1999 KDD cup machine learning competition, which is a subset of the 1998 DARPA Intrusion Detection Evaluation data tuple, and is executed, extracting 41 features from the raw data of DARPA 98 data set. Attacks fall into four main categories:
DOS: denial-of-service, e.g. syn flood;
R2L: unauthorized access from a remote machine tool, for e.g. guessing password; U2R: unauthorized access to local super user
(root) privileges, e.g., various ``buffer overflow'' attacks;
Examine: surveillance and other examine, for example: port scanning.
Removing Redundant Attributes
WEKA is used in our work for collaborate of machine learning algorithms for data mining process. From this whole dataset another dataset is created for training. This new data set is created using feature selection algorithm called as CFS subset removal. In which 10 feature are selected for creation of data set.
Removing Training Instances
SVMs have shown attractive potential and promising performance in classification, they have the limitation of speed and size in training large data sets. The hyper plane fabricated by SVM is dependent on only a fraction of training samples called support vectors that lie close to the decision boundary (hyper plane). Thus, removing any training instances that are not relevant to support vectors may have no effect on building the proper decision function [33]. If it is possible to identify such non-relevant instances from the training set, it is possible to decrease the computational cost, and in turn permit us to use complex kernels that can increase the accuracy obtained from the result of classification . The problem to be solved here is how the non-relevant instances in the training data set can be identified. The K-Mean algorithm reduces instances for support vector machine. K-mean clustering technique applied to the whole training set to identify initial clusters. Once the initial clusters are detected, a
variable radius from the cluster center is used to identify ‘crisp clusters’. Crisp clusters are the clusters as the same class samples. Crisp clusters are further refined to avoid possible instances, and then the instances in refined crisp clusters are removed from the training set. Here we are using k-means through WEKA.
B.Effects for Classification Result
There can be advantages in reducing the number of training instances before trying to select support vectors, in terms of speed and space requirements. However, reducing instances from the training set should not affect the result of classification. If it can improve the classification results when compared with using the whole training set, it would be an increased benefit. On the other hand, if the classification rate is reducing, it must be within an allowable range, depending on the application requirements.
C. Initial Clusters
In the proposed technique, there are three major steps toward reducing the number of instances in the training set, without considerably affecting the SVM results. They are as follows:
First Identify initial clusters or cluster centres Identify crisp clusters
Detect instances to be removed
First Identify initial clusters or cluster
centres
There are many well-known clustering techniques which can be categorized into supervised or unsupervised clustering. In this case, K-mean algorithm we used to identify the initial clusters. The main consideration here is that the initial K-mean clustering method is simple to implement and less costly in terms of computing power.
Identification of Crisp Clusters
627
All Rights Reserved © 2013 IJARCSEEDetection of Instances to Be Removed
This is the most important part of the proposed technique of reducing the size of the training set so that the effect on selecting support vectors to be a minimum. Instances that are likely to be support vectors cannot be removed in order to have the same results, when compared to the obtained result of full training set. Support vectors are selected from the instances close to the decision boundary. Therefore, it is safer to remove instances far from decision boundaries. Here, the problem is how to detect instances far from decision boundaries, or the instances that have less effect on selecting support vectors. It is obvious that some of the instances within crisp clusters are either on the decision boundary or very close to it. Hence it is not a good idea to discard all instances within the crisp cluster in order to reduce the training set size. The presentiment of this problem was the motivation for the following progress in order to select instances that have less effect in SVM fabrication.
D. Fixed Safety Region
Instances close to the cluster boundary have a high probability of affecting the support vector selection. Therefore, it is better to keep a safety region close to the cluster boundary, so that no instances would be away from that region. This region is described based on the cluster radius or number of instances within the cluster. The outcome would be an inner cluster, where instances within are far from the decision boundary. Instances within this inner cluster are the detected instances to
be removed. Instances between the inner cluster and the outer cluster are the instances within the safety region and are not to be removed. To decide the internal radius, a threshold percentage value based on the number of instances, is used and defined as:
Threshold instances percentage= (instances within the inner cluster)/ (instances within the outer cluster)*100
K-mean initial clustering is applied to identify cluster centers and then above algorithm is used to identify crisp clusters. Inner clusters are obtained using a fixed threshold percentage of 50%. If the number of instances in the outer cluster = N, then the number of instances in the inner cluster ≥ 50% N.
E. Proposed SVM Model for Classification
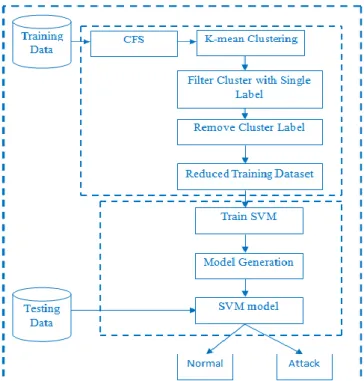
Over all steps in the above section are summarized below in the fig.3.1. In first step attributes are reduced using CFS algorithm. In the second step K-mean clustering used to reduce the training data by filtering instances which are not support vectors. Clustering algorithm insert one more attribute cluster at the end of training dataset. In the third step remove the clusters which contain instances corresponding to single class. In fourth step remove the cluster label to obtain reduced training dataset which will used to train the SVM. SVM model is evaluated using original test data and the modified test data containing only new spikes.
Figure 3.1: Proposed SVM model for classification
IV. Test data and Test result
Step 1:
For all the cluster centres, increase the cluster radius (n=1) until 3 or more instances are in the cluster. Assign label ‘undecided’.
Step 2:
Select a cluster with the label ‘undecided’, t=1. If no instances with label ‘undecided’, STOP. Check the output class of each sample within the cluster.
Step 3:
If all the instances are in same class, increase the radius by NR and check again (n=n+1).
Where, NR can be an arbitrary value depending on the cluster size.
628
All Rights Reserved © 2013 IJARCSEEA. Experiment Design
KDD99 dataset is used for conducting the experiments. Original training dataset contains 4, 94,021 instances and test dataset contains 3, 11,029 instances which has 17 additional attacks. To apply K-mean clustering and CFS algorithm WEKA is used. RunWEKA.ini file is edited to assign 600 MB of memory to WEKA. New test set is created by deleting the instances belonging to attacks presents in training data. Tool SVMlight is extended by implementing new kernel functions and is used for classification.
B. Data Pre-processing
It has been discussed in previous chapters that model generation is computation intensive. So in order to reduce time redundant attributes and instances can be removed, (which may also insert noise in the task of classification) by feature selection algorithm and K-mean clustering algorithm. The search method used to generate dataset Ds1 from original data set.
Table 4.1 Precision and recalls for linear kernel on original test data set
C rec_nor pre_nor rec_atk pre_atk 4 70.57086 83.68102 96.67021 93.13967 10 70.39262 84.51661 96.87984 93.11488
The results highlighted are the best results for linear kernel. High precision values are required for normal class. That is none of the attacks should be missing classified as normal class. For normal class precision is more important than recall. For attack recall is more important than precision that is some of the normal packets may be misclassified as attack
Fig 4.1 Graph for linear kernel on original dataset
Table: 4.2 Precision and recalls linear kernel on new test dataset.
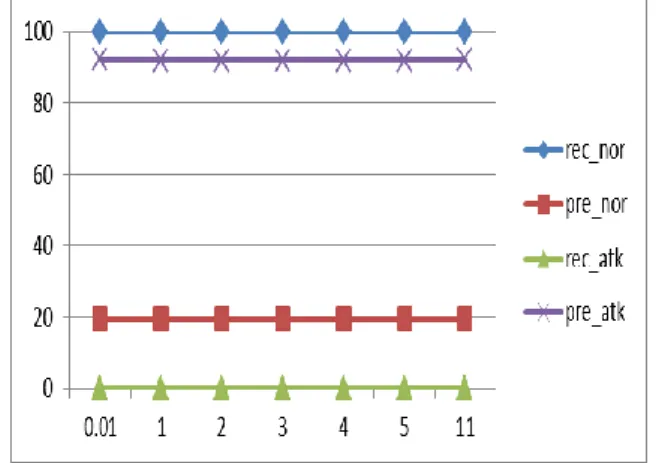
C rec_nor pre_nor rec_atk pre_atk 4 70.57086 87.93855 68.68493 41.90774 5 75.97577 88.37611 67.67046 46.54254
As seen from above table best results obtain for C=5. The highest precision obtained for normal class is 88.4%. The highest value of recall is 68.7% at C=4.
Fig 4.2 Graph for linear kernel in new test dataset
None of the results for either class shows acceptable performance. The performance was nearly same for different values of C and d.
Fig 4.3 Graph for polynomial kernel in original test dataset
Table: 4.3 Precision and recall for RBF kernel on original test dataset
629
All Rights Reserved © 2013 IJARCSEEThe results obtained are not acceptable because recall for attack class drops to 3% which is too low. The instances
belong to attack category are miss classified as normal.
Fig 4.4 Graph for polynomial kernel in new test dataset
Results for RBF Kernel
Table: 4.4 Precision and recall for polynomial kernel on new test data set
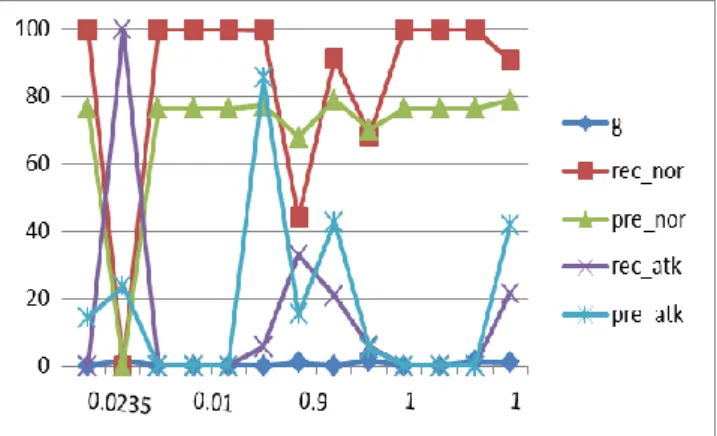
The above table shows that the best results are obtained for c=1 and g=1.
Fig 4.5 Graph for RBF kernel in original test dataset
Table: 4.5 Precision and recall for RBF kernel on new test data set
For novelty test set better results are obtained for same values of c and g. the results are better than original test set.
Fig 4.6 Graph for RBF kernel in new test dataset
Table: 4.6 Precision and recall for RBF kernel on new test data set
The above table shows that results are not acceptable for sigmoid kernel in the original test dataset.
Fig 4.7 Graph for sigmoid kernel in original test dataset
Table: 4.6 Precision and recall for RBF kernel on new test data set
630
All Rights Reserved © 2013 IJARCSEEFig 4.7 Graph for sigmoid kernel in original test dataset The results are not acceptable for sigmoid kernel function in the new test dataset. We have seen that linear kernel gives better performance for novelty test dataset as comparative original test dataset. Linear kernel function performs better than RBF function for novelty detection also.
Results for Multiclass SVM on Different Kernel Function
The tables, displays the results for multiclass SVM. It can be observed that the results are not acceptable for any of the five classes. Paper discussed in section II D of this dissertation states that SVM gives accuracy above 90% for different classes of SVM using a part of test dataset. The above experiments were performed using complete test dataset and the results obtained are not acceptable except for R2L class. For R2L class SVM with polynomial kernel gives 100% precision with recall of 15.8%.
V. CONCLUSION AND FUTURE
WORK
The achievements are as follows, Reduced model redundancy using feature selection algorithm without affecting performance, Reduced training dataset for SVM using K-means clustering algorithm, Evaluated binary and multi class SVM using different kernel functions over bench mark dataset. Limitation of the proposed method is, none of the machine learning classifier algorithms evaluated was able to perform detection of user-to-root attack categories significantly, Due to computational requirement of multiclass SVM no of kernel functions evaluated was less, No procedure was devised for kernel width delimitation that is to obtain the best kernel function. Future Work we are consider in our work, Procedure can be devised for kernel width delimitation to obtain optimal kernel function, Different algorithms may be explored to find suitable solution for U2R category of attack, Parallel SVM classifier may be developed to speed up the computation.
REFERENCES
[1] Anderson, J. "An introduction to neural networks." Cambridge: MIT Press. (1995)
[2] Chen, W.H., Hsu, S.H., and Shen, H.P. "Application of SVM and ANN for intrusion detection." Computer & Operations Research 32, 2617-2634. (2005)
[3] Cho, S.B., and Park, H.J. "Efficient anomaly detection by modeling privilege flows using hidden Markov model." Computer & Security 22, 44-55. (2003)
[4] Dokas, P.,Ertoz, L.,Kumar, V., Lazarevic, A., Srivastava, A.J., and Tan, P.N. "Data Mining for Network Intrusion Detection." Denning, D.E. "An Intrusion Detection Model, IEEE Trans-actions on Software Engineering." SE-13:222-232, 1987.
[5] Depren, O., Topallar, M., Anarim, E., Ciliz, M.K. "An intelligent intrusion detection system (IDS) for anomaly and misuse detection in computer networks." Expert System with Applications 29, 713-222.
[6] Didaci,L.,Giacinto,G.and Roli, F. "Ensemble Learning for Intrusion Detection in Computer Networks"(2002), Proc. of AIIA, Siena, Italy, Friedman, J.H. "Multivariate adaptive regression spines." Anal Stat, 19:1–141. (1991)
[7] Han, S.J., and Cho, S.B. "Detecting intrusion with rule-based integration of multiple models." Computer & Security 22,613-623. (2003)
[8] Javitz, H.S.and Valdes, A.The NIDES Statistical Compo-nent: Description and Justification, Technical Report, Computer Science Laboratory, SRI International. (1993)
[9] Jiang, S.Y., Song, X., Wang, H., Han, J.J., and Li, Q.H. "A clustering-based method for unsupervised intrusion" Pattern Recognition Letters 27,802-810. (2006)
[10] Joachims, T. "SVM light is an implementation of support vector machines (SVMs) in C". University of Dortmund" Collaborative Research Center on Complexity Reduction in Multivariate Data (SFB475), http://ais.gmd.de/,thorsten/svm_light 2000.
[11] Joo, D., Hong, T., and Han, I. "The neural network models for IDS based on the asymmetric costs of false negative errors and false positive errors." Expert Systems with Applications 25, 69–75 2000.
[12] Lee, W., and Stolfo, S.J... "Data Mining Approaches for Intrusion Detection." Seventh USENIX Security Symposium (SECURITY ‘98), San Antonio, TX. (1998)
[13] Li, X.B. "A scalable decision tree system and its application in pattern recognition and intrusion detection." Decision Support System 41,112-130. (2005) [14] Lippmann, R.P., and Cunningham, R.K. "Improving
631
All Rights Reserved © 2013 IJARCSEE[15] Lippmann, R.P., Haines, J.W., Fried, D.J., Korba, J., and Das, K. "The 1999 DARPA off-line intrusion detection evaluation." Computer Networks 34,579-595. (2000)
[16] Liao, Y., and Vemuri, V.R. "Use of K-Nearest Neighbor classifier for intrusion detection." Computer & Security 21,439-448. (2002)
[17] Liu, Y., Chen, K., Liao, X. and Zhang, W. "A genetic clustering method for intrusion detection" Pattern Recognition 37,927-942. (2004)
[18] Mukkamala, S., Sung, A.H., and Abraham, A. "Intrusion detection using an ensemble of intelligent paradigms." Computer Applications 28,167-182. (2005)
[19] NikulinV"Threshould-based clustering with merging and regularization in application to network intrusion detection." Computational Statistics & Data Analysis. (2005)
[20] Ozyer, T., Alhajj, R., and Barker, K. "Intrusion detection by intelligent boostering genetic fuzzy classfier and data mining criteria for rule pre-processing." Journal of Network and Computer Applications. (2005)
[21] Perdisci, R., Giorgio, G., and Roli, F. "Alarm clustering for intrusion detection systems in computer networks." Engeering Applications of Artificial Intelligent 19,429-438. (2006)
[22] Pietraszek, T., and Tanner, A. "Data mining and machine learning- Toward reducing false positives in intrusion detection." Information Security Technical Report 10,169-183. (2005)
[23] Rhodes, B., Mahaffey, J., and Cannady, J. "Multiple self-organizing maps for intrusion detection Proceedings of the 23rd national information systems security conference" Baltimore, MD, 2005.
[24] Ryan, J., Lin, M.J., and Mikkulainen, R."Intrusion Detection with Neural Network” 2005.
[25] Thompson, H.H., Whittaker, J.A., Andrews, M. "Intrusion detection: Perspectives on the insider threat." Computer Fraud & Security, 2004, pp13-15. (2004)
[26] Vaprik, V. "Statistics learning theory." John Wiley, New York. (1998)
[27] Zh Zhang, C. Jiang, J., and Kamel, M. "Intrusion detection using hierarchical networks." Pattern Recognition Letter 26,779-791, 2005.