2016 International Conference on Manufacturing Science and Information Engineering (ICMSIE 2016) ISBN: 978-1-60595-325-0
Bayesian Spam Detection System Using
Hybrid Feature Selection Method
JUNYING CHEN, SHUNFENG ZHOU and HUAQING MIN
ABSTRACT
With the rapid development of Internet, the amount of text information has increased dramatically. As such, how to effectively and accurately identify, classify and deal with these information becomes a major challenge. In this paper, we used a term frequency hybrid filter which combines the refined naïve Bayesian classifier and innovative hybrid feature selection method to detect spams. According to our experiment results, we found that the hybrid feature selection method had better spam detection performance than traditional feature selection methods.1
INTRODUCTION
By the end of 2015, the number of Chinese Internet users had broken through 650 million. E-mail has become an important method for communicating, gaining information and looking for jobs. However, in recent years, more and more spams have not only affected people’s daily work and life, but also brought huge economic loss to the society [1]. Current mainstream spam-blocking method is collecting a large amount of spams and using such spams to train a classifier, so as to get the classifier to work intelligently, which can identify spams among new e-mail messages [2-4].
However, spams can attack some widely-used spam filters which use specific spam detection algorithms. Such attacks seriously affect the effectiveness and practicality of current spam technology. So we should improve current anti-spam technology. In this paper, we put forward a new hybrid feature selection method based on refined naïve Bayesian classification, which is called term frequency hybrid filter. The experiment results demonstrate that such classifier improves performance.
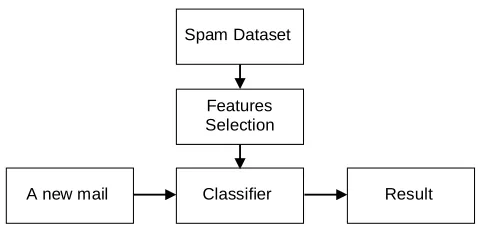
A new mail Classifier Result Spam Dataset
[image:2.612.176.415.100.214.2]Features Selection
Figure 1. Spam detection system.
SPAM DETECTION SYSTEM DESIGN
The spam detection system block diagram is shown in Figure 1. Before the e-mail classification process, pre-processing is required, which switch e-e-mails into text messages. Then the sentences are split into word list, which is called space vector model. In order to reduce the calculation time and suppress noise, the classifier usually selects part of the word features [5]. Furthermore, dimensionality reduction is performed on the dataset in advance to improve performance. Finally, such trained classifier is used to identify a new e-mail and output the classification judge result.
Refined Naïve Bayesian Classification Algorithm Description
If the feature wi appears in document d, then the probability of document d
belongs to class Ci, as shown in the following:
(1)
In this paper, we refined the classifier by also considering the feature wi does
not appear in document d:
(2)
(3)
Hybrid Feature Selection Module
Huge amount of documents will produce huge feature set, which will cost a long time in training and classifying, and bring in many noises. As a result, a dimensionality reduction method is needed. General dimensionality reduction methods include feature extraction and feature selection. The feature selection methods used in text classifying include term frequency, information gain [7], mutual information[8] and chi-square detection, etc. However, traditional feature selection algorithms don’t help to improve the classifier performance much.
In this paper, we put forward a new hybrid feature selection method, which is called term frequency hybrid filter. Firstly, all feature words are sorted by frequencies. Then we can set the information gain, mutual information, chi-square detection or their combinations as the filter selection feature. If one word’s index is more than k in the word list which is sorted by filter feature selection algorithm, filter it out and continue to choose; or select this word as a component of the feature set. Generally, k is 40%, 50% or 60% of the total amount of features, depending on the actual dataset. This hybrid feature selection method considers the classifying ability of the high-frequency words, but filters the high-frequency words with low classifying ability. Therefore, the term frequency hybrid filter combines the advantages of term frequency method and other feature selection algorithms.
EXPERIMENTS AND RESULTS
The e-mail dataset is collected from user mailbox, consisting of totally 811 mails, including 490 spams and 321 non-spams. Each mail had deleted the attachments, and left the theme, sender address, main body and attachment file names.10-fold cross-validation was performed on arbitrary dataset, and the result was the average of the 10 tests. Recall rate and F1 score were used as evaluation measurements, which were widely used in machine learning algorithm evaluations. F1 score considered both the correct and complete identification capabilities of the algorithms, while the recall rate was related to the misjudgment possibility.
feature set components.
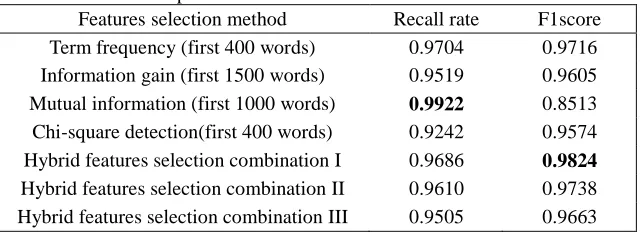
[image:4.612.139.459.248.364.2]After applying feature selection methods, the refined naïve Bayesian classifier was used to classify the dataset, and the evaluations was conducted, as shown in the Table I. As shown in Table I, mutual information method had the highest recall rate, but its F1 score was too low to use in normal cases. Hybrid feature selection combination I had a good balance in recall rate and F1 score. By applying hybrid feature selection method, useless high-frequency words were intelligently filtered out, so the performance of the naïve Bayesian classifier was improved.
TABLE I. The performance of different features selection methods. Features selection method Recall rate F1score Term frequency (first 400 words) 0.9704 0.9716 Information gain (first 1500 words) 0.9519 0.9605 Mutual information (first 1000 words) 0.9922 0.8513 Chi-square detection(first 400 words) 0.9242 0.9574
Hybrid features selection combination I 0.9686 0.9824
Hybrid features selection combination II 0.9610 0.9738 Hybrid features selection combination III 0.9505 0.9663
CONCLUSIONS
In this paper, we refined the naïve Bayesian classifier,increasing its spam detection correctness. When applying appropriate hybrid feature selection method, as investigated in this paper, not only the classifier's detection performance can be improved, but also the computational complexity can be reduced. The experiments described in this paper demonstrated that our refined naïve Bayesian classifier combined with hybrid feature selection method can fulfill our everyday spam detection requirements.
ACKNOWLEDGEMENTS
REFERENCES
1. Kanich, C., et al. 2008. “Spamalytics: An empirical analysis of spam marketing conversion R,”15th ACM Conference on Computer and Communications Security, 2008.
2. Alpaydin, E. 2014. “Introduction to machine learning,” MIT press, pp. 640.
3. Harrington, P. 2012. “Machine learning in action M,” Manning Publications Co.pp. 230.
4. Hearst, M. A., Dumais S. T., Osman E., et al. 1998. “Support Vector Machines,” IEEE J. Intelligent Systems and their Applications, 13(4),pp. 18-28.
5. Guyon, I. and Elisseeff, A. “An introduction to variable and feature selection,” The Journal of Machine Learning Research, 3,pp. 1157-1182.
6. Androutsopoulos, I., Koutsias J., Chandrinos K.V., et al. 2000. “An evaluation of naive bayesian anti-spam filtering C,” Workshop on Machine Learning in the New Information Age, 2012. 7. Kent, J. T. “Information gain and a general measure of correlation,” Biometrika, 70(1), pp.
163-173.