International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 1, January 2015)
94
Content Based Image Retrieval from Web Based Data Sources
Anwar Sarkeja
1, Atul Nandwal
2, Amit Mandloi
31,3VITM, RGTU, India 2Oriental University, Indore, India Abstract— Web is concentration of information and
different data, which allows user to access the data as per their use. It has so many applications one of which is search engine. The data from search engines can be found in different formats and types. But now in these days multimedia data which is available on search engines is most frequently accessed and consumed. To satisfying demand of multimedia data, different studies have been conducted on multimedia data search. On the basis of studies a new model for image search is proposed and implemented in this work. The proposed work presents a way to find the most relevant image as per the content. In traditional content based image search relevance feedback and re-ranking are most popular methods, but these techniques produces delay. To reduce delay, image annotation technique is proposed without including re-ranking or relevance feedback. The annotation based techniques includes tag with image object. This will help to search the image on the basis of image content and text too. Implementation of the proposed technique uses the LBP features, Grid color movement analysis, and canny edge detection techniques. To properly demonstrate all strategy two different modules are prepared, first training which extracts features and preserves them and finally search implementation which uses normalized features to optimize the image search results. After implementation of the proposed model the performance of the system is analyzed in terms of search time, resource utilization and search accuracy defined in percentage gain and it is clearly reflected in results that the overall performance of the proposed solution is better than the previous approaches.
Keywords— image search, CBIR, feature computation, annotation, tag based image search.
I. INTRODUCTION
Internet is a large source of information and data nowadays and in the same time data on web is rapidly increasing in unstructured way. Finding user oriented data from these unstructured data structure requires some extra efforts. As of internet users are rapidly growing and these growing internet users consumes a large amount of multimedia data of different formats such as images, video and other file formats. In study we found that there are various tools techniques and algorithms developed to search this content and promises to provide the user specific data from web.
The proposed work focuses on the image search based on content of images. Re-ranking and relevance feedback are two basic models that are frequently used to filter results or in other terms optimize the results. But to provide the feedback and re-ranking consumes extra time to extract effective results because first results are listed than the algorithms works to improve the results.
In addition to that the search results contains a large amount of time sensitive contents in results, these contents affect the accuracy of results, thus some improvements on the existing system is required.
Content Based Image Retrieval is a set of techniques for retrieving semantically-relevant Images from an image database based on automatically-derived image features [1]. This aims at avoiding the use of textual descriptions and instead retrieves images based on their visual similarity to a user-supplied query image or user-specified image features.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 1, January 2015)
95
Most of the existing CBIR systems consider each image as a whole. But, a single image can include multiple objects with completely different semantic meanings. A user is often interested in only one particular region of the query image instead of the image as a whole. Therefore, rather than viewing each image as a whole, it is more reasonable to view it as a set of provinces. The features engaged by the majority of Image Retrieval systems include color, texture, shape and spatial layout. Such features are apparently not effective for CBIR [6]. If they are extracted from a whole image because they suffer from the differing backgrounds, overlaps, occlusion and cluttering in different images and they do not have adequate ability to capture important properties of objects, as a result most popular approaches in recent years is to change the focus from the global content description of images into the local content description by regions or even the objects in images. RBIR is a promising extension of the classical CBIR: rather than deploying global features over the entire content, RBIR systems partition an image into a number of homogenous regions and extract local features for each region then features of regions are used to represent and index images in RBIR. For RBIR, The user supplies a query object by selecting a region of a query image and then the corresponding similarity measure is computed between features of region in the query and a set of features of segmented regions in features database and the system returns a ranked list of images that contain the same object. The content-based approach can be summarized as follows [7]:
1.Computer vision and image processing techniques in are used to extract content features from the image. 2.Images are represented as collections of their
prominent features. For a given feature, an appropriate representation of the feature and a notion of similarity are determined.
3.Image retrieval is performed based on computing similarity or Dissimilarity in the feature space, and results are ranked based on the similarity measure.
II. PRAPOSED WORK
A. System modelling
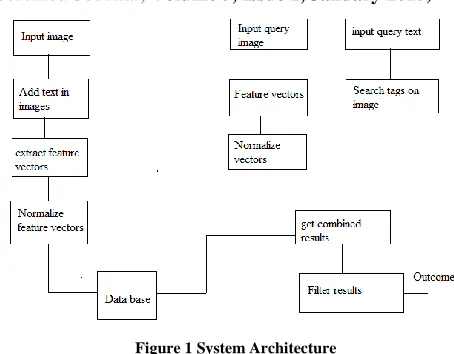
[image:2.612.326.553.128.305.2]The proposed system is designed in two different modules, where first is the training and second is test module. Where in training module system accepts user data in form of text, image and their feature vectors are calculated, in testing phase system accepts user query in form of text and image for search after searching system produces results and performance of results are listed. The basic overview of the system is given below.
Figure 1 System Architecture
Input image: That is training phase of the system where system accepts user images as input to learn from example.
Add text in images: A small note on image also stored in the data base as annotation of text.
Extract features: In this phase on training system extract different feature vectors and pass these vectors into next phase to normalize them.
Normalize feature vectors: In this phase from multiple values a common value is prepared and stored in data base in place of complete image.
In testing session we use these stored values from the database and consumes to extract the optimum results from the database.
Input query image: User can make query for search results as image from the query image feature vectors are estimated as in training phase.
Feature vectors: Here grid colour movement, canny edge detection, local binary patterns are estimated as feature set.
Normalize feature vector: Individual features are contains their own definition and comparison and storage of each features can take more space and time for comparison thus a common value is calculated to store them.
Text input: User can also place text for search image contains.
Search similar tag: The text in images is searched on local database to get images from database.
Combine results: Here the results obtained from text query and image query is listed in same place.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 1, January 2015)
96
B. Algorithm design
This includes the steps of the proposed system which executes during system processing, the system module is designed in two steps, first training and second testing module the algorithm implemented also works in two modules.
The Training Phase:
In training phase we can create the database of images and provide the labels to various sections of images and calculate the feature vectors of the image by applying all the four methods on each image which reduces the search of image from data base.
Training
Input: user image, text
Output: low level feature vectors
Process Image
1. Read input image from supplied path (image path); 2. Return buffered image;
3. Label the image on selected area for buffered image; 4. LBP feature vector;
5. Grid Colour movement feature extraction; 6. Gabor wavelet feature extraction;
7. Edge detection of the image; 8. Store to database;
Testing Phase
In testing phase the user query is processed using text processor and image processor to extract actual image content which is required by the user and the trained model provides the search results. This phase contains the image search algorithm for finding the actual image using the text query or the query by image over stored database. The main process and execution is explained here, user can make query by image for image search and/or query by the text. In testing phase Query for Image is processed and Searching of Images by Different Annotation Models and similarity Match is performed by Hybrid Graph Method.
Testing
Input: query image/ text
Output: list image
Search image (image, text) {
if (image!=null) {
Extract image low level features;
Apply annotation feature matching schemes for search relevant content;
Apply hybrid graph random walk algorithm for image list; }
else {
Search keyword using Query;
List all image and tags related to keyword;
Apply hybrid random walk algorithm for content image; }
}
III. RESULT ANALYSIS
A. Training Time
Training time of the system provide the time value consumed by the system to train the system. In our case the time is measured as the time required in extracting the low level features of image and adding the tags to it, additionally storing it into the database.
The below given results provided is estimated by performing operations on different size and format of images and the best values are provided here. To perform operations two varieties of data is provided and the data storage increases one by one for estimating the accurate performance of the system.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 1, January 2015)
97
[image:4.612.323.577.125.297.2]Case2: Here the operations are performed in real world data like traffic, crowed, persons, building and about our surroundings.
Figure 2 Training time
Form the results analysis we found that the training of the system directly depends upon the size of image. As the file size increases the time required to train the system increases.
B. Search Time
Search time is known as the time required to find relevant results after the query, here the file size does not matters for searching process. But the factor o0n which searching slightly depends upon the size of images in the query database and feature vectors. The values are provided here using number of experiments performed and time used to search the images. The operations are performed with increasing the number of images in the data base and for both cases performance is given in figure 3.
[image:4.612.48.300.175.334.2]In above analysis we found that the search time of the image from database not only depends upon the size of images but also depends upon some other factors, like feature vector estimation and matching of these vectors. Thus the search time vary according to the available values in database, image size, vectors size and others.
Figure 3 search time
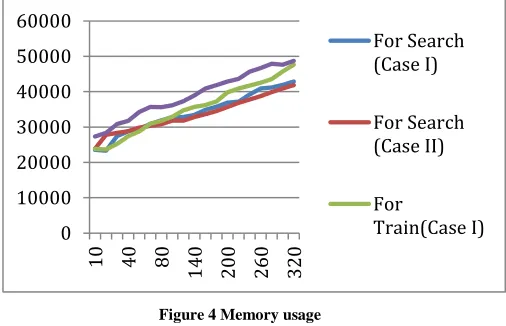
C. Memory Uses
Memory used is defined as the memory consumed during the algorithm processing of the system. The memory used by the system is calculated during the execution of the system for both operations that is searching time and training time.
Figure 4 Memory usage
This section provides the memory used by the system during system execution, form the above graph we can see the memory requirement of training and testing phases. We found that for training the system required less memory than testing phase, thus this is because at the time of testing various algorithms parallel execute to find images using text and image.
0 10 20 30
Training time
0 1 2 3 4 5 6 7 8
10 30 50 80 120 160 200 240 280 320
Time Case 1 Time Case 2
0 10000 20000 30000 40000 50000 60000
10 40 80 140 200 260 320
For Search (Case I)
For Search (Case II)
For
[image:4.612.324.577.376.539.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 1, January 2015)
98 Figure 5 Accuracy for text
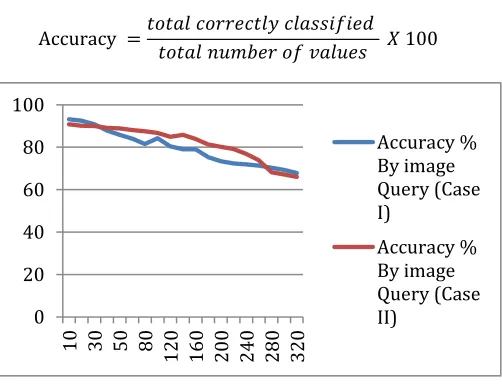
D. Accuracy
The term accuracy of any system is defined as the correctly classified values over total number of values required to evaluate.
For example suppose we have 100 items to evaluate and the system classify all the values where suppose 70 objects are correctly recognized by the system and remaining perform inaccurate values. Thus the accuracy of the system is 70 %.
[image:5.612.66.569.109.293.2]
Figure 6 Accuracy of system for Image
Figure 7 Accuracy of system for text and image
Here we provide the results for accuracy of the system that is evaluated through, for evaluating the accuracy we place different 500 images in directory and make search for the images the results is calculated.
IV. CONLUSION AND FUTURE WORK
The main aim of the research work is to design a content based image retrieval system with text annotation technique. With this approach user can find the relevant images. The proposed method promises to provide the more accurate search results then previously designed techniques.
To obtain a promising model various techniques and methods are analysed first and various research papers and articles are studied during analysis. After analysing them problem domain is established, after that solution steps are concluded.
After implementation of the desired system performance and QoS parameters are evaluated. The testing of proposed model is performed using two cases where accuracy of the system gets improved, for first case of the wild photos, the limited amount of variations in images are found thus the accuracy is improved between 7-12%, and for second case the real time image having a large amount of variation thus this is less effective and accuracy is improved between 4-9%., training time, search time, error rate gets reduced and resources in terms of memory is evaluated. After performance evaluation of the proposed technique we found that the performance of the implemented technique is adoptable and required less time and memory for searching images from source directory.
0 20 40 60 80 100
10 30 50 80 120 160 200 240 280 320
Accuracy % By text Query (Case I) Accuracy % By text Query (Case II)
0 20 40 60 80 100
10 30 50 80 120 160 200 240 280 320
Accuracy % By image Query (Case I)
Accuracy % By image Query (Case II)
0 20 40 60 80 100
10 30 50 80 120 160 200 240 280 320
Accuracy % By Both Query (Case I)
[image:5.612.49.300.411.604.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 1, January 2015)
99
Acknowledgement
This work performs for our academic research only. It’s not feasible for real time for all industrial application. The authors would like to thank the anonymous reviewers for their invaluable feedback.
REFERENCES
[1] Priti Maheswary, Dr. Namita Srivastava, ―Retrieval of Remote
Sensing Images Using Colour & Texture Attribute‖,(IJCSIS) International Journal of Computer Science and Information Security,Vol. 4,No. 1&2, 2009
[2] S. Oraintara, T. T. Nguyen, ―Using Phase and Magnitude
Information of the Complex directional Filter Bank for Texture Image Retrieval‖, IEEE International Conference on Image Processing, Vol. 4, Pages 61-64, Oct. 2007
[3] P. S. Hiremath and Jagadeesh Pujari. ―Content Based Image
Retrieval based on Color, Texture and Shape features using Image and its complement‖, International Journal of Computer Science and Security, Volume (1) : Issue (4)
[4] Philipp Sandhaus, Mohammad Rabbath, and Susanne
Boll,―Employing Aesthetic Principles for Automatic PhotoBook Layout‖,Advances in Multimedia Modeling, 2011 – Springer
[5] Michele Saad, ―Low-Level Color and Texture Feature Extraction for
Content-Based Image Retrieval‖, Final Project Report, EE 381K: Multi-Dimensional Digital Signal Processing, Pages: 20-28, May 2008
[6] Alaa M. Riad, Hamdy.K. Elminir, Sameh Abd-Elghany, ―A
Literature Review of Image Retrieval based on Semantic Concept‖, International Journal of Computer Applications (0975 – 8887) Volume 40– No.11, February 2012
[7] Gaurav Mandloi, ―A Survey on Feature Extraction Techniques for