Align and Copy: UZH at SIGMORPHON 2017 Shared Task for
Morphological Reinflection
Peter Makarov†∗ Tatiana Ruzsics‡∗ Simon Clematide† †Institute of Computational Linguistics, University of Zurich, Switzerland ‡CorpusLab, URPP Language and Space, University of Zurich, Switzerland [email protected] [email protected] [email protected]
Abstract
This paper presents the submissions by the University of Zurich to the SIGMOR-PHON 2017 shared task on morpholog-ical reinflection. The task is to predict the inflected form given a lemma and a set of morpho-syntactic features. We fo-cus on neural network approaches that can tackle the task in a limited-resource set-ting. As the transduction of the lemma into the inflected form is dominated by copying over lemma characters, we pro-pose two recurrent neural network archi-tectures with hard monotonic attention that are strong at copying and, yet, sub-stantially different in how they achieve this. The first approach is an encoder-decoder model with a copy mechanism. The second approach is a neural state-transition system over a set of explicit edit actions, including a designated COPY ac-tion. We experiment with character ment and find that naive, greedy align-ment consistently produces strong results for some languages. Our best system com-bination is the overall winner of the SIG-MORPHON 2017 Shared Task 1 without external resources. At a setting with 100 training samples, both our approaches, as ensembles of models, outperform the next best competitor.
1 Introduction
This paper describes our approaches and results for Task 1 (without external resources) of the CoNLL-SIGMORPHON 2017 challenge on Uni-versal Morphological Reinflection (Cotterell et al.,
2017). This task consists in generating inflected
∗These two authors contributed equally.
word forms for 52 languages given a lemma and a morphological feature specification ( Sylak-Glassman et al.,2015) as input (Figure1).
fliegen
flog
{VERB, PASTTENSE,
3RDPERSON, SINGULAR}
Figure 1: Morphological inflection generation task. A German language example.
There are three task setups: a low setting where training data are only 100 (!) samples, a medium setting with 1K training samples, and a high setting with 10K samples. We consider the problem of tackling morphological inflection generation at a low-resource setting with a neu-ral network approach, which is hard for plain soft-attention encoder-decoder models (Kann and Sch¨utze, 2016a,b). We present two systems that are based on the hard monotonic attention model of Aharoni and Goldberg (2017); Aharoni et al.
(2016), which is strong on smaller-sized train-ing datasets. We observe that to excel at a low-resource setting, a model needs to be good at copy-ing lemma characters over to the inflected form— by far the most common operation of string trans-duction in the morphological inflection generation task.
In our first approach, we extend the hard mono-tonic attention model with a copy mechanism that produces a mixture distribution from the charac-ter generation and characcharac-ter copying distributions. This idea is reminiscent of the pointer-generator model ofSee et al.(2017) and the CopyNet model ofGu et al.(2016).
Our second approach is a neural state-transition system that explicitly learns the copy action and thus does away with character decoding altogether whenever a character needs to be copied over. This approach is inspired by shift-reduce parsing with
stack LSTMs (Dyer et al., 2015) and transition-based named entity recognition (Lample et al.,
2016).
2 Preliminaries
In this section, we formally describe the problem of morphological inflection generation as a string transduction task. Next, we show how this task can be reformulated in terms of transduction ac-tions. Finally, we discuss the string alignment strategies that we use to derive oracle actions.
2.1 Morphological inflection generation Morphological inflection generation is an in-stance of the more general sequence transduction task, where the goal is to find a mapping of a variable-length sequence x to another
variable-length sequencey. Specific to morphological
in-flection generation is that the input and output vocabularies—lemmas and inflected forms—are the same set of characters of one natural language, i.e. Σx = Σy = Σ. Formally, our task is to learn
a mapping from an input sequence of characters
x1:n ∈ Σ∗ (the lemma) to an output sequence of characters y1:m ∈ Σ∗ (the inflected form) given a set of morpho-syntactic featuresf ⊆ Φ, where Φis the alphabet of morpho-syntactic features for
that language.
2.2 Task reformulation
To efficiently condition on parts of the input se-quence, we use hard monotonic attention, which has been found highly suitable for this task ( Aha-roni and Goldberg, 2017; Aharoni et al., 2016). With hard attention, at each step, the prediction of an output element is based on attending to only one element from the input sequence as opposed to conditioning on the entire input sequence as in soft attention models.
Hard monotonic attention is motivated by the often monotonic alignment between the lemma characters and the characters of its inflected form: It suffices to only allow for the advancement of the attention pointer up in a sequential order over the elements of the input sequence. Thus, the se-quence transduction process can be represented as a sequence of actions a1:q ∈ Ω∗ over an input string, where the set of actions Ω includes
oper-ations for writing characters and advancing the at-tention pointer. We can, therefore, reformulate the task of finding a mapping from an input sequence
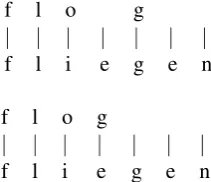
f l o g
| | | | | | |
f l i e g e n
f l o g
| | | | | | |
[image:2.595.362.468.64.155.2]f l i e g e n
Figure 2: Examples of smart alignment (top) and naive alignment (bottom). In each example, in-flected form is at the top, lemma at the bottom.
of lemma characters x ∈ Σ∗ to the output
se-quence of actionsˆa∈Ω∗, given a set of
morpho-syntactic featuresf ⊆Φ, such that:
ˆ
a= arg max
a∈Ω∗ P a|x, f
= arg max
a∈Ω∗
|a| Y
t=1
P at|a1:t−1, x, f (1)
We use a recurrent neural network to estimate the probability distributionP in Equation1 from
training data. To derive the sequence of oracle ac-tions from each training sample, we use two dif-ferent character alignment strategies formally de-scribed below.
2.3 Character alignment strategies
We use two string alignment strategies that pro-duce 0-to-1, 1-to-0, and 1-to-1 character align-ments (Figure2).
Smart alignment uses the Chinese Restaurant Process character alignment implementation dis-tributed with the SIGMORPHON 2016 baseline system (Cotterell et al.,2016).1 This is the aligner
ofAharoni and Goldberg(2017).
Naive alignment aligns two sequences pandq,
such that the length of p is greater or equal to
the length of q, by producing 1-to-1 character
alignments until it reaches the end of q, from
which point it outputs 1-to-0 alignments (and 0-to-1 alignments once it reaches the end of p if |q|>|p|).
3 First approach: Hard attention model with copy mechanism (HACM)
Our first approach augments the hard monotonic attention model ofAharoni and Goldberg (2017)
1https://github.com/ryancotterell/
WRITE_
LSTMy
[ y ; hi ; f ] ReLU
st at=
COPY 1. E(xi) → LSTM
y
2. Append xi to output 3. i := i + 1
1. E( ) → LSTMy
2. Append to output
DELETE 1. i := i + 1 STOP
LSTMy
LSTMy
Pt
(eq 7) (eq 8)
STEP
[ E(at-1) ; hi ; f ] st
at=
WRITE_ Append to output i := i + 1
Ptmix
Ptgen
wtgen [ E(a
t-1) ; hi ; f ; st ]
1– wtgen
Ptcopy x i
sigmoid
LSTM
(eq 2) (eq 3)
[image:3.595.101.499.67.267.2](eq 5) (eq 4)
Figure 3: Overview of the architectures. Hard attention model with copy mechanism (HACM) on the left, hard attention model over edit actions (HAEM) on the right.
with a copy mechanism which adds a soft switch between generating an output symbol from a fixed vocabulary Σtrain and copying the currently
at-tended input symbolxi. In this section, we first
re-view the architecture of the hard monotonic model and then present our copy mechanism.
3.1 Hard monotonic attention model
The hard monotonic attention model operates over two types of actions: WRITE σ,σ ∈ Σ, for
out-putting the character σ and STEP which moves
forward the attention pointer, i.e. Ω = Σ ∪ {STEP}. At each step, the model either generates an output symbol or starts to attend to the next en-coded input character. The system learns to move the attention pointer by outputting a STEP action. To compute the sequences of oracle actions for each training pair of lemma and its inflected form,
Aharoni and Goldberg(2017) apply a determinis-tic algorithm2to the output of the smart aligner.
Architecture The hard monotonic attention model uses a single-layer bidirectional LSTM en-coder (Graves and Schmidhuber, 2005) to en-code input lemma x1:n as a sequence of vectors
h1:n,hi∈R2H, whereHis the hidden dimension of the LSTM layer.
At all time steps t, the model maintains a state
st ∈RH from which the most probable actionat is predicted. The sequence of states is modeled
2We refer the reader toAharoni and Goldberg(2017) for the
description of the algorithm.
with a single-layer LSTM that receives, at timet,
a concatenated input of:
1. the currently attended vector hi ∈ R2H, whereiis the attention pointer,
2. the concatenated vector of feature embed-dingsf ∈ RF·|Φ|, whereF is the dimension of the feature embedding layer,
3. the embedding of the previous output action
E(at−1)∈RE, whereE is the dimension of
the action embedding layer.
st=LSTM [E(at−1);hi;f] (2)
LetΣtrain ⊆ Σbe the set of characters in train-ing data. Then, the distributionPtgen for
generat-ing actions over the vocabularyΩtrain = Σtrain∪ {STEP}is modeled with the softmax function:
Ptgen =softmax W·st+b
(3) When the predicted action is STEP, the atten-tion index gets incremented i := i+ 1, and so at the next time step t+ 1, the model attends to
vectorhi+1 of the bidirectionally encoded lemma
sequence.
3.2 Copy mechanism
1 2 3 4 5 6 7 8 9 10 11 12 13 14 t
hsi f l o g h/si y
hsi STEP f STEP l STEP o STEP STEP g STEP STEP STEP h/si at
hsi hsi f f l l i i e g g e n h/si xi
0 0 1 1 2 2 3 3 4 5 5 6 7 8 i
1 2 3 4 5 6 7 8 9 t
f l o g y
COPY COPY DELETE DELETE o COPY DELETE DELETE STOP at
f l i e g g e n – xi
[image:4.595.72.531.66.147.2]1 2 3 4 5 5 6 7 7 i
Table 1: Examples of generating German “flog” from “fliegen”: HACM (left), HAEM (right). iis the attention pointer,xithe currently attended lemma character,athe sequence of actions,ythe output,tthe index over actions.
At each time stept, the action a∈ Ωtrain is
pre-dicted from the following mixture distribution:
Pt(a) =wtgenPtgen(a) + (1−w
gen
t )1{a=xi}, (4)
wherexiis the currently attended character of the lemma sequence xand 1{a=xi} = Ptcopy(a) is a
probability distribution for copyingxi.
The mix-in parameter of the generation distri-bution wgent ∈ Ris calculated from the
concate-nation of the state vector st and the input vector that produces this state. The resulting vector is fed through a linear layer to the logistic sigmoid func-tion:
wtgen=sigmoid(v·[hi;f;yt−1;st] +c) (5)
The mix-in parameter serves as a switch between a) generating a character fromΣtrainaccording to the generation distribution Ptgen, and b) copying
the currently attended characterxi ∈Σtrain. At test time, we allow the copying of out-of-vocabulary (OOV) symbols by adding the fol-lowing modification to the mixture distribution in Equation4:
Pt(a) =1{a=xi}1{xi∈Σ\Σtrain}+
wtgenPtgen(a)
+ (1−wtgen)1{a=xi}
1{xi∈Σtrain}
(6) Therefore, if the currently attended symbolxi is OOV, we copy it with probability one according to the distribution1{a=xi}; otherwise, we use the
mixture of generationPtgenand copy1{a=xi}
dis-tributions. Thus, the distributionPt is built over an instance specific vocabularyΩtrain∪ {xi}. Af-ter copying the OOV symbol, we advance the at-tention pointer and use STEP as the previous pre-dicted action.
The full architecture of the HACM system is shown schematically in Figure3.
3.3 Learning
We train the system using cross-entropy loss, which, for a single input(x, y, f), equates to:
L(Θ;x, a, f) =−
|a| X
t=1
logPt at|a1:t−1, x, f
,
(7) wherex, y are lemma and inflected form
charac-ter sequences, f the set of morpho-syntactic
fea-tures, a the sequence of oracle actions derived
from(x, y),Θthe model parameters andPtis the probability distribution over actions from Equa-tion4.
4 Second approach: Hard attention model over edit actions (HAEM)
This neural state-transition system also uses hard monotonic attention but transduces the lemma into the inflected form by a sequence of explicit edit actions: COPY, DELETE, and WRITE σ,σ ∈Σ.
The architectures of the two models are also dif-ferent (Figure3).
4.1 Semantics of edit actions
COPY If the system generates COPY, the lemma character at the attention index xi is ap-pended to the current output of the inflected form and the attention index is incrementedi:= i+ 1.
Therefore, unlike other neural morphological in-flection generation systems, the copy character is not decoded from the neural network.
DELETE The system generates DELETE if it needs to increment the attention index.
WRITE σ Whenever the system chooses to
ap-pend a characterσ ∈ Σ to the current output of
Using this set of edit actions, the system can copy, delete, and substitute new characters. The substitution of a new character σ for a currently
attended lemma characterxi,σ 6=xi, is expressed as a sequence of one DELETE and one WRITEσ
action.
This action set directly compares to the Ω = Σ∪ {STEP}actions of the HACM model, which uses most basic actions to express edit operations. Crucially, in the HAEM system, character copying is a single action (which does not require character decoding) whereas it is typically a sequence of one WRITE σ(=σ) and one STEP action in HACM.3
Further, HAEM effectively deals with OOV char-acters through COPY and DELETE actions.
STOP Additionally, to signal the end of trans-duction, the system generates a STOP action.
4.2 Deriving oracle actions
We use the character alignment methods of Sec-tion2.3to deterministically compute sequences of oracle actions for each training example using Al-gorithm1.
Algorithm 1: Derivation of oracle actions from alignment of lemma and form.
Input :A, list of 1-to-1, 0-to-1, and 1-to-0
alignments between lemma and form Output:O, list of oracle actions
1 foreach(t, s)∈Ado
2 ift=then
3 O.append(WRITEs)
4 else ifs=then
5 O.append(DELETE) 6 else ifs=tthen
7 O.append(COPY)
8 else
9 O.append(DELETE)
10 O.append(WRITEs)
11 end 12 end
We then normalize all sub-sequences of only DELETE and WRITE σ in such a way that all
DELETEs come before all WRITE σ actions. This simplifies unintuitive alignments produced by the smart aligner, especially at the low setting.
3Except whenever the next alignment is 0-to-1 the HACM
does not generate STEP. The HAEM system, however, in-crements the attention index on every COPY action.
4.3 Architecture
Similarly to HACM, the input lemma is encoded as a sequence of vectors h1:n,hi ∈ R2H with a single-layer bidirectional LSTM. Additionally, we use a single-layer LSTM to represent the pre-dicted inflected form y1:m, to which we refer as LSTMy. In case the model outputs a character
with WRITE σ or COPY, LSTMy gets updated
with the embedding of this character.
At all time stepst, the system maintains a state
st ∈ RH from which it predicts the most proba-ble actionat. The state sequence is derived
differ-ently. At timet, a concatenation of:
1. the currently attended vectorhi∈R2H,
2. the set-of-features vectorf ∈R|Φ|,
3. the output of the latest statey ∈ RH of the
inflected form representationLSTMy,
passes through a rectifier linear unit (ReLU) layer (Glorot et al., 2011) to finally produce the state vectorst.
The probability distribution over valid actions4
is then computed with softmax:
st= ReLU W·[y;hi;f] +b (8) Pt=softmax V·st+c
(9)
This describes the basic form of the HAEM sys-tem (Figure 3). In our experiments, we extend it to include two more representations: an LSTM that represents the action history,LSTMa, and an-other LSTM that encodes a sequence of deleted lemma characters,LSTMd. The deletionLSTMd
gets emptied once a WRITE σ action is gener-ated. In this way, we attempt to keep in memory a full representation of some sub-sequence of the lemma that needs to be replaced in the inflected form. In the extended system, the statestis thus derived from an input vector[y;hi;f;a;d], where
a ∈RH is the output of the latest state of the ac-tion historyLSTMaandd∈RH the output of the latest state of the deletionLSTMd.
The system is trained using the cross-entropy loss function as in Equation7.
5 Experimental setup
We submit seven runs: a) two runs (1 and 2) for the HACM model; b) two runs (3 and 4) for the
4Some actions are not valid in certain states: The system
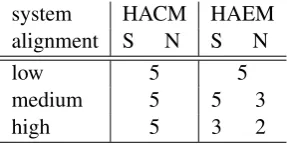
system HACM HAEM alignment S N S N
low 5 5
medium 5 5 3
high 5 3 2
Table 2: Number of single models that we train for each language. N=Naive alignment, S=Smart alignment. E.g. for each language at the medium setting, there are 3 HAEM models trained on data aligned with naive alignment.
Run Systems Strategy
1 CM MAX{E(NCM), E(SCM)}
2 ENSEMBLE7(NCM∪SCM)
3 EM MAX{E(NEM), E(SEM)}
4 ENSEMBLE7(NEM∪SEM)
5
CM& EM MAX{E(NCM), E(SCM), E(NEM), E(SEM)} 6 ENSEMBLE4(NCM∪SCM∪NEM∪SEM)
7 MAX{Run 5, Run 6}
Table 3: Aggregation strategies in submis-sions. CM=HACM, EM=HAEM, NCM=the set
of HACM models trained on naive-aligned data, SCM=the set of HACM models trained on
smart-aligned data, and similarly for HAEM.
HAEM model; and c) three runs (5, 6, and 7) that combine both systems. Detailed information on training regimes and the choice of hyperparame-ter values (e.g. layer dimensions, the application of dropout, etc.) for all the runs is provided in the Appendix. Crucially, for both systems and all settings and languages, we train models with both smart and naive alignments of Section 2.3. Ta-ble2shows the number of single models for each system, setting, and alignment.5 We decode using
greedy search.
We apply a simple post-processing filter that re-places any inflected form containing an endlessly repeating character with the lemma. This affects a small number of test samples—57 for HACM and 238 for HAEM across all languages and alignment regimes—and primarily at the low setting.
All runs aggregate the results of multiple sin-gle models, and we use a number of aggregation strategies. For system runs 1 through 4, these are:
Max strategy For each languagel, we compute
two ensembles over single models—one ensemble
E(S) over smart alignment models and one
en-semble E(N) over naive alignment models. We
5Due to time restrictions, we could not produce the target of
5 HAEM models per setting and alignment.
then pick the ensemble with the highest develop-ment set accuracy forl:
ˆ
M = arg max
M∈{E(S),E(N)}dev acc
(M) (10)
Ensemble n strategy For each languagel, we
pick at mostnmodels from all single models such that they have the best development set accuracies forl. We then compute one ensemble over them:
ˆ M =E
n-best
M∈(S∪N) dev acc(M)
(11)
Runs 5, 6, and 7 are built with aggregation strategies that use as building blocks the MAX and ENSEMBLE nstrategies. Table3shows the
strategies employed in each run.
At the high setting, Runs 5, 6, and 7 addition-ally feature a single run produced with Nematus (Sennrich et al., 2017), a soft-attention encoder-decoder system for machine translation. In all these runs, the Nematus run complements the HAEM models, which perform much worse at the high setting on average. We refer the reader to the Appendix for further information on data prepro-cessing, hyperparameter values, and training for the Nematus run.
6 Results and Discussion
Table5gives an overview on the average (macro) performance for each run on the official develop-ment and test sets at all settings. Accuracy mea-sures the percentage of word forms that are in-flected correctly (without a single character error). For the best system combination, we also report the average Levenshtein distance between the gold standard word form and the system prediction, which represents a softer criterion for correctness. Also, we include the performance of the shared task baseline system, which is a rule-based model that extracts prefix-changing and suffix-changing rules using alignments of each training sample with Levenshtein distance and associates the rules with the features of the sample.6 All our official
runs beat the baseline by a large margin on av-erage in terms of accuracy and also in terms of Levenshtein distance. For all settings, we see an improvement by applying the more complex en-sembling strategies (Table3). It is the largest for low and the smallest for the high setting.
6https://github.com/sigmorphon/
[image:6.595.108.252.62.134.2]System HACM HAEM HACM HAEM HACM & HAEM BS BS
Alignment/Run N S N S 1 2 3 4 5 6 7 7
Metric Acc Acc Acc Acc Acc Acc Acc Acc Acc Acc Acc Lev Acc Lev Development Set
Low 43.8 41.3 45.8 44.3 46.5 47.6 48.9 49.5 49.2 51.1 51.6 1.3 38.0 2.1 Medium 75.8 81.4 70.7 80.0 81.9 82.6 80.5 81.1 82.2 83.4 83.5 0.3 64.7 0.9 High 93.3 94.6 75.9 89.6 95.0 95.3 89.8 90.1 95.2 95.3 95.6 0.1 77.9 0.5
Test Set
Low 46.0 46.8 48.0 48.5 48.2 50.6 50.6 1.3 37.9 2.2
Medium 80.9 81.8 79.6 80.3 81.0 82.8 82.8 0.3 64.7 0.9
[image:7.595.74.523.62.194.2]High 94.5 95.0 89.1 89.5 94.7 95.1 95.1 0.1 77.8 0.5
Table 4: Macro average results over all languages for all settings on the official development and test set. N=Naive alignment, S=Smart alignment, BS=Baseline system, Acc=Accuracy, Lev=Levenshtein.
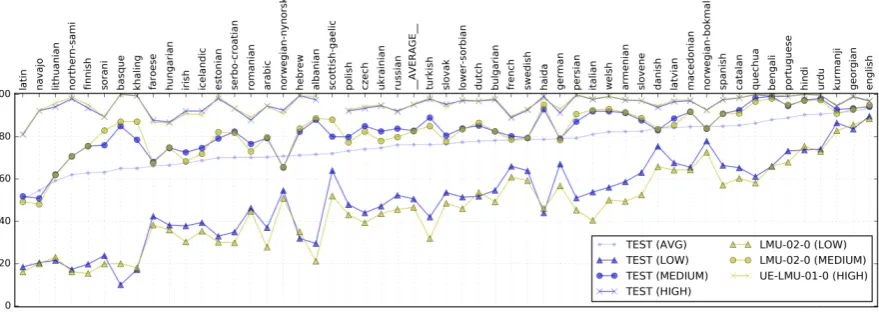
Figure 4: Test set accuracies of Run 7 (blue) and the next best system (yellow). The results are ordered by the averaged (low, medium, high) test set accuracies of Run 7.
At the low setting, HAEM outperforms HACM on average by 2-3 percentage points accuracy and is, therefore, especially suited for a low resource situation. At the medium setting, the performance of HACM is slightly better using smart align-ments. The HAEM system does not seem to learn well with naive alignment for this amount of data. The poorer performance of HAEM when-ever more training data are available is particularly obvious at the high-resource setting where the dif-ference between HACM and HAEM is quite large. At the low setting, both the HACM and HAEM ensembles (Run 2 and Run 4) outperform the next best competitor (LMU-02-0 with 46.59%) by 0.23 and 1.94 percentage points in average accuracy. The margin between Run 7 and the next best sys-tem is an impressive 4.02 percentage points.
At the medium setting, our best Run 7 also outperforms the next best competitor (LMU-02-0 with 82.64%) with a small margin of (LMU-02-0.16
per-centage points. At the high setting, our best Run 7 loses against UE-LMU-01-0 with a small margin of 0.20 percentage points.
[image:7.595.81.521.254.410.2]As future work, we will experiment more with the HAEM model and try to improve its capabil-ities for high-resource settings. One obvious op-tion would be to use more fine-grained acop-tions, for instance, directly learn substitutions for certain characters. This system would probably also profit from more consistent alignments. Even with smart alignments, we observe linguistically inconsistent character alignments that might also prevent use-ful generalizations.
7 Related work
Some task-specific work has been published af-ter the 2016 edition of the SIGMORPHON Rein-flection Shared Task (Cotterell et al., 2016) that dealt with 10 languages, providing training ma-terial roughly at the size of the high setting of the 2017 task edition (a mean training data set size of 12,751 samples with a standard devia-tion of 3,303). The winning system of 2016 (Kann and Sch¨utze, 2016a) showed that a stan-dard sequence-to-sequence encoder-decoder ar-chitecture with soft attention (Bahdanau et al.,
2014), familiar from neural machine translation, outperforms a number of other methods (as far as they were present in the task). Recently, Aha-roni and Goldberg(2017) showed that hard mono-tonic attention works well when training data are scarce. Their approach exploits the almost mono-tonic alignment between the lemma and its in-flected form. The HACM model extends this work with a copying mechanism similar to the pointer-generator model ofSee et al.(2017) and CopyNet ofGu et al.(2016). In HACM, the copying distri-bution, which is then mixed together with the gen-eration distribution, is different: See et al.(2017) employ the soft-attention distribution whereasGu et al. (2016) use a separately learned distribu-tion. Our HACM model uses a simpler copy-ing distribution that puts all the probability mass on the currently attended character. The logic of the HAEM model is similar to that of SIGMOR-PHON 2016’s baseline which uses a linear clas-sifier over hand-crafted features to predict edit ac-tions.Grefenstette et al.(2015) extend an encoder-decoder model with neural data structures to bet-ter handle natural language transduction. Rastogi et al.(2016) present a neural finite-state approach to string transduction.
8 Conclusion
In this large-scale evaluation of morphological in-flection generation, we show that a novel neural transition-based approach can deal well with an extreme low-resource setup. For a medium size training set of 1K items, HACM works slightly better. With abundant data (10K items), en-coder/decoder architectures with soft attention are very strong, however, HACM achieves a compara-ble development set performance.
For optimal results, the ensembling of differ-ent system runs is important. We experimdiffer-ent with different ensembling strategies for eliminating bad candidates. At the low setting (100 samples), our best system combination achieves an average test set accuracy of 50.61% (an average Levenshtein distance (LD) of 1.29), at the medium setting (1K samples) 82.8% (LD 0.34), and at the high setting (10K samples) 95.12% (LD 0.11).
Acknowledgement
We would like to thank the SIGMORPHON or-ganizers for the exciting shared task and Tanja Samardˇzi´c and two anonymous reviewers for their helpful comments. Peter Makarov has been sup-ported by European Research Council Grant No. 338875.
References
Roee Aharoni and Yoav Goldberg. 2017. Morphologi-cal inflection generation with hard monotonic atten-tion. InACL.
Roee Aharoni, Yoav Goldberg, and Yonatan Belinkov. 2016. Improving sequence to sequence learning for morphological inflection generation: The BIU-MIT systems for the SIGMORPHON 2016 shared task for morphological reinflection. In14th Annual SIG-MORPHON Workshop on Computational Research in Phonetics, Phonology, and Morphology at ACL 2016.
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2014. Neural machine translation by jointly learning to align and translate. CoRR
abs/1409.0473.
Ryan Cotterell, Christo Kirov, John Sylak-Glassman, David Yarowsky, Jason Eisner, and Mans Hulden. 2016. The SIGMORPHON 2016 Shared Task— Morphological Reinflection. In Proceedings of the 14th SIGMORPHON Workshop on Computational Research in Phonetics, Phonology, and Morphol-ogy. ACL.
Chris Dyer, Miguel Ballesteros, Wang Ling, Austin Matthews, and Noah A Smith. 2015. Transition-based dependency parsing with stack long short-term memory. InACL.
Xavier Glorot, Antoine Bordes, and Yoshua Bengio. 2011. Deep sparse rectifier neural networks. In Ais-tats. volume 15.
Alex Graves and J¨urgen Schmidhuber. 2005. Frame-wise phoneme classification with bidirectional LSTM and other neural network architectures. Neu-ral Networks18(5).
Edward Grefenstette, Karl Moritz Hermann, Mustafa Suleyman, and Phil Blunsom. 2015. Learning to transduce with unbounded memory. InAdvances in Neural Information Processing Systems.
Jiatao Gu, Zhengdong Lu, Hang Li, and Victor O. K. Li. 2016. Incorporating copying mechanism in sequence-to-sequence learning.CoRR.
Katharina Kann and Hinrich Sch¨utze. 2016a. MED: The LMU system for the SIGMORPHON 2016 shared task on morphological reinflection. In 14th Annual SIGMORPHON Workshop on Computa-tional Research in Phonetics, Phonology, and Mor-phology at ACL 2016.
Katharina Kann and Hinrich Sch¨utze. 2016b. Single-model encoder-decoder with explicit morphological representation for reinflection. InACL.
Guillaume Lample, Miguel Ballesteros, Sandeep Sub-ramanian, Kazuya Kawakami, and Chris Dyer. 2016. Neural architectures for named entity recognition. InNAACL.
Pushpendre Rastogi, Ryan Cotterell, and Jason Eisner. 2016. Weighting finite-state transductions with neu-ral context. InNAACL-HLT.
Abigail See, Peter J Liu, and Christopher D Man-ning. 2017. Get To The Point: Summarization with Pointer-Generator Networks. InACL.
Rico Sennrich, Orhan Firat, Kyunghyun Cho, Alexan-dra Birch, Barry Haddow, Julian Hitschler, Marcin Junczys-Dowmunt, Samuel L¨aubli, Antonio Vale-rio Miceli Barone, Jozef Mokry, and Maria Nade-jde. 2017. Nematus: a Toolkit for Neural Machine Translation. InProceedings of the Software Demon-strations of the 15th Conference of the European Chapter of the Association for Computational Lin-guistics. ACL.