Category Based Automatic Classification of
Online News Articles Using Machine Learning
Jeelani Ahmed, Muqeem Ahmed
Abstract— Today, a sudden increase in online information over the web is forcing the industry to adopt new methods and tools that could help in searching, filtering, and managing high dimensional data. A considerable amount of valuable information has recorded in the documents. This recorded data can be mine for both personal and professional purposes. Data stored in documents can be access by the users by many sou rces like digital media, electronic media, and much more. This data is available in the unstructured format, and many methods are available, by which this data may turn into the structured format. It is highly desirable and imperative to classify the information in an appropriate set of categories. Automatic text classification needed because there is a quick increase in these numbers of machine-readable documents. Text classification is a supervised learning task whose aim is to classify the unlabeled documents into the labeled documents with the predefined categories. This paper presents a machine learning approach to classify online news articles based on category. This process assigns labels to unlabeled news articles using a classifier. H ere classifier is train using the training data set, and by providing testing data set, we can measure the performanc e. The result of the proposed framework is that it classifies the online news articles into different categories using a different classifier, and using various validation metrics, we can measure th e performance. News content is one of the most important factors that influence the various sections of the society. Due to the association of news articles with the busy lifestyle of humans, customization of news articles as per the individual requirements is becomes necessary. In this paper, we discuss a m achine learning approach to classify online news articles. This paper further consists of results, performance analysis of the method, and further research to improve the accuracy.
Index Terms— Text Classification, Naïve Bayes, Support Vector Machine, KNN, News Articles, Machine Learning, News Categorization
————————————————————
1 I
NTRODUCTION Nowadays, the vast amount of digital information is spreading and continuously increasing. Automatic text classification into existing categories has continuously measured as an essential method to process and manage this vast amount of information. This kind of information has generated from various sources and available in the form of conference materials, editorials, digital/electronic documents, web pages, emails, publications, and journals. Today’s many people use these online sources for day-to-day information access instead of being limited to printed material such as newspapers, magazines, and books. The access to such information has become more comfortable; however, the organization of information is difficult, which makes it challenging to manage. Organizing this kind of digital data has considered as one of the critical methods, which effectively manage and classify this digital information. Since the start of the digital world, it is not very easy to manage the enormous data present over the web, and automatic classification of text has always been an important application (Ikonomakis et al., 2005). A technique that habitually created a classifier by observing the properties of labels from a set of predefined files is termed as Text Classification (Sebastiani, 2002). The classification has a vital part in text retrieval, information extraction, and summarization and question- answering. Usually, maximum data that are available on the web used for classification are diverse, which comes from various sources like broadcast or printed news, bulletin boards, newsgroups, advertisements, and movie reviews. Because of theirdiverse nature like multi-source, having different vocabularies, different formats, different writing styles for documents, automatic text classification is essential [1]. When we classify a document under an already defined category is termed as Text classification (see figure 1.1). A document can have a single label or multi-label depending upon the classes. A document is termed as a single label if it is allocate to only one class and called “multi-label” if the document has allocated to more than one class (Wang & Chiang, 2011). Text classification comprises feature selection, document representation, applying the algorithm, and performance assessment. Due to the quick development of online transactions and the colossal accessibility of text documents, it is essential to retrieve vital data from the documents using classification. Today, it has considered an essential practice of organizing and managing text information [2]. Support Vector Machines [3], Neural Network [4], k-Nearest Neighbor [5] classification, and Naïve Bayesian [6] are such methods that have used for constructing classification methods. Due to the enormous amount of data that is storing in the electronic format, it is necessary to understand and examine such data and extract such information, which may be helpful in the decision making [7], [8], [9]. For this purpose, a very powerful tool Data mining is used, which is helpful in hidden mining information from large data sets. Until the start of the last decade, news information was not merely and rapidly available. However, now via online content providers such as online news services, this news information is readily available and accessible [10], [11].
————————————————
Jeelani Ahmed is currently pursuing research program in Computer Science in Maulana Azad National Urdu University, Hyderabad, India, PH-8310616610. E-mail: [email protected] Muqeem Ahmed is currently working as assistant professor of
Figure1.1: Text Classification Process
A considerable volume of information is available in the text in different fields whose examination could be essential and helpful in many fields [12]. In Data Mining, text classification is an exciting thing as it involves steps to convert diverse unstructured data into structured information. As it increases in the number of news and news sources, it is becoming complicated for users to get the individual’s interest in the news, so it is necessary to categorize news so that it could be readily available for users. Users will get access to the news of their personal choice and interest in real-time by not wasting their time if internet news is dividing into different categories [13], [14], [15]. As news is uninterruptedly generating, it could belong to any category, the classification of those news articles becomes very difficult. Due to the advances in the digital era, people are worried about their busy lifestyle and thus their desire to read the news articles of their interests only [16]. It is a big task of pertinent mining news concerning an individual’s Interest because much of the news articles are enlightening but could be less significant to an individual. The Interest of an individual can be contingent on many factors like place of the news and type of news articles. [17]. Here we classify the news articles based on the type/category of the news articles. For example, if an individual prefers to read news related to politics and the web is full with an ocean of news articles. Therefore, it would be challenging a particular person to read articles related to the politics category. In this work, to customize the news articles for a specific category, we have applied machine-learning techniques. The category may be politics, crime, sports, entertainment, or world news. We trained and tested the classification model using the huff post data set, which contains around 75k news articles. After training & testing, we applied this model for the news articles taken from different live news websites such as the Hindu, the Print, Indian express, and the Quint. The rest of the paper follows the below pattern: section ii contains some background knowledge regarding the classification algorithm. Section iii contains a comprehensive study of the existing research, which has carried out up to date in the field of text classification, which let us have a reasonable assessment of the work that has done to date. Studies of earlier work have tabulated in a table concerning the publication year by highlighting the number of essential factors. Proposed methodology has presented in section iv, and results have
discussed in section v. Finally, section vi presents a conclusion and future work.
2
B
ACKGROUND2.1 Naïve Bayes
Naïve Bayes is using as the classifier for classifying the news articles. It is a prevalent method of classification when we are dealing with the multiclass classification. It works based on the probabilistic technique first proposed by D.Lewis [23] and drives its roots from Bayes Theorem. This classifier can run very efficiently with the large dataset. For text classification problems, this algorithm is use as a standard because it has a fast run time as paralleled to further classifiers. Naïve Bayes is also used to solve problems like spam detection. Due to its simplicity, it outpaces many advanced classification techniques.
2.2 K- Nearest Neighbors (KNN)
KNN is a simple, supervised machine learning algorithm using which we can solve the problems of classification and regression domains [5]. It works by calculating the space between a query and all the instances (K) nearer to the query then selects the majority recurrent label. It is comprehensible and applied very quickly. It slows down its performance when there is an increase in the data size. It stores all the training data, due to which it is a bit costly algorithm. It requires high memory storage as compare to other methods. KNN is use in many areas, such as in politics, it can classify a voter into various classes like ‘Will not Vote,’ ‘Will Vote,’ ‘Will Vote to AAP Party.
2.3 SVM Classifier
SVM is a supervised machine-learning algorithm [3]. It works when provided a training set of data and its associated labels. Once the training is over, if we supply a data set, the model assigns a label to it. Support vector machine works well when dealing with linear classification problems. For classification, it made a hyper-plane by choosing the maximum distance between adjacent data points. It is both a flexible and powerful technique of machine learning, which use for regression and classification. When dealing with high dimensional space, svm works well and offers excellent accuracy, and it requires very little memory for processing. It is not suitable for the large dataset as it takes high training time. It does not work well with overlapping classes.
3 R
ELATEDW
ORKMachine Leaning is another approach that uses automatic rules generation to classify the documents [20]. The Various methods of classification are: Support Vector Machines [3], Neural Networks [4], Bayesian classification [6], Nearest Neighbor (KNN) [5], Association based classification [21], [22], [23], Term
Graph Model [24], [25] and Decision Tree [26], [27] etc. Many authors use the above mentioned machine learning techniques; we studied them briefly and formulated them according to the year in the following table.
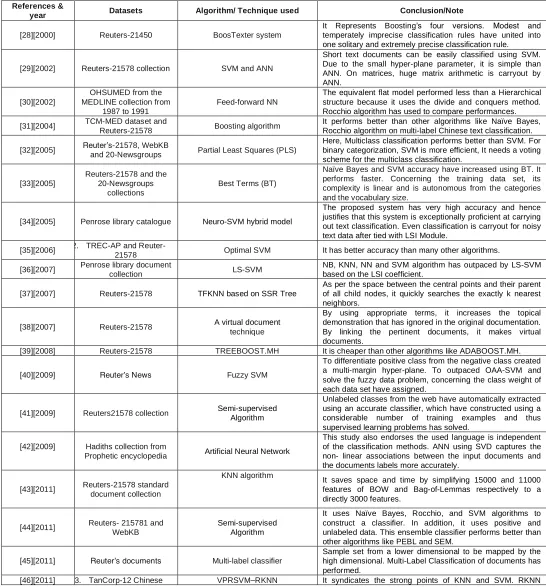
Table 1: Related work in the field of Text classification by various authors
References &
year Datasets Algorithm/ Technique used Conclusion/Note
[28][2000] Reuters-21450 BoosTexter system
It Represents Boosting’s four versions. Modest and temperately imprecise classification rules have united into one solitary and extremely precise classification rule.
[29][2002] Reuters-21578 collection SVM and ANN
Short text documents can be easily classified using SVM. Due to the small hyper-plane parameter, it is simple than ANN. On matrices, huge matrix arithmetic is carryout by ANN.
[30][2002]
OHSUMED from the MEDLINE collection from
1987 to 1991
Feed-forward NN
The equivalent flat model performed less than a Hierarchical structure because it uses the divide and conquers method. Rocchio algorithm has used to compare performances.
[31][2004] TCM-MED dataset and
Reuters-21578 Boosting algorithm
It performs better than other algorithms like Naïve Bayes, Rocchio algorithm on multi-label Chinese text classification.
[32][2005] 1. Reuter’s-21578, WebKB
and 20-Newsgroups Partial Least Squares (PLS)
Here, Multiclass classification performs better than SVM. For binary categorization, SVM is more efficient, It needs a voting scheme for the multiclass classification.
[33][2005]
Reuters-21578 and the 20-Newsgroups
collections
Best Terms (BT)
Naïve Bayes and SVM accuracy have increased using BT. It performs faster. Concerning the training data set, its complexity is linear and is autonomous from the categories and the vocabulary size.
[34][2005] Penrose library catalogue Neuro-SVM hybrid model
The proposed system has very high accuracy and hence justifies that this system is exceptionally proficient at carrying out text classification. Even classification is carryout for noisy text data after tied with LSI Module.
[35][2006] 2. TREC-AP and
Reuter-21578 Optimal SVM It has better accuracy than many other algorithms.
[36][2007] Penrose library document
collection LS-SVM
NB, KNN, NN and SVM algorithm has outpaced by LS-SVM based on the LSI coefficient.
[37][2007] Reuters-21578 TFKNN based on SSR Tree
As per the space between the central points and their parent of all child nodes, it quickly searches the exactly k nearest neighbors.
[38][2007] Reuters-21578 A virtual document
technique
By using appropriate terms, it increases the topical demonstration that has ignored in the original documentation. By linking the pertinent documents, it makes virtual documents.
[39][2008] Reuters-21578 TREEBOOST.MH It is cheaper than other algorithms like ADABOOST.MH.
[40][2009] Reuter’s News Fuzzy SVM
To differentiate positive class from the negative class created a multi-margin hyper-plane. To outpaced OAA-SVM and solve the fuzzy data problem, concerning the class weight of each data set have assigned.
[41][2009] Reuters21578 collection Semi-supervised
Algorithm
Unlabeled classes from the web have automatically extracted using an accurate classifier, which have constructed using a considerable number of training examples and thus supervised learning problems has solved.
[42][2009] Hadiths collection from
Prophetic encyclopedia Artificial Neural Network
This study also endorses the used language is independent of the classification methods. ANN using SVD captures the non- linear associations between the input documents and the documents labels more accurately.
[43][2011] Reuters-21578 standard document collection
KNN algorithm
It saves space and time by simplifying 15000 and 11000 features of BOW and Bag-of-Lemmas respectively to a directly 3000 features.
[44][2011] Reuters- 215781 and
WebKB
Semi-supervised Algorithm
It uses Naïve Bayes, Rocchio, and SVM algorithms to construct a classifier. In addition, it uses positive and unlabeled data. This ensemble classifier performs better than other algorithms like PEBL and SEM.
[45][2011] Reuter’s documents Multi-label classifier
Sample set from a lower dimensional to be mapped by the high dimensional. Multi-Label Classification of documents has performed.
dataset classifier impact has minimized by filtering noisy data by VPRSVM.
[47][2011] Games datasets from
news websites Clustering Algorithm
A group of certain text data have successfully classified by the Neural Network where the classifier did not know all classes priory.
[48][2012]
Automobiles dataset Mathematics dataset Vehicles dataset
SVM-NN approach
It consumes high processing time. In KNN classification, SVM classification incorporated into the training stage. It retains the accuracy of KNN classification as it has a low impact on parameter K.
[49][2012] RCV1-v2 collection DCEPU
Each base classifier assigned a weight by a dynamic weighting scheme and validation set of the drift concept. Each classifier assigned a global weight and even local weight by the weighting scheme.
[50][2012] 4. Fu Dan’s data set of
Chinese websites KNN algorithm
KNN algorithms’ lazy learning has overcome by eager learning. It also minimizes the substantial processing cost.
[51][2013] Newsgroup20 Multilayer feed forward networks Very high processing time
[52][2013] Arabic text documents Artificial Neural Network
The performance of the ANN using feature reduction performs better as compared to the essential ANN and gives better results for the classifications.
[53][2014] Reuter-21578 KNN algorithm
Accuracy of the KNN is maximum compared to Term Graph and Naïve Bayes. Its time complexity is maximum as compared to others is the only drawback
[24][2014] Sohu laboratory corpus SVM-KNN algorithm
The SVM-KNN algorithm can improve the performance of the classifier by the suggestions and enhancement of the classifying probability. This algorithm increases the low amount of processing difficulty. Moreover, SVM is efficient and fast for the classification.
[55][2016] Online news articles Neural Network Classifier The training process is prolonged.
[3][2017] Various news websites
articles Naïve Bayes, SVM, Random Forest Performance of the SVM is at the bottom.
4
M
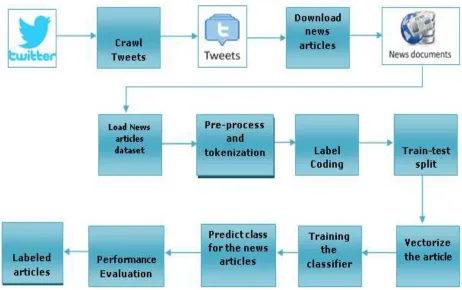
ETHODOLOGYThe process starts with a data collection module. In which we crawl tweets from twitter using tweepy then using the URL links in the tweets, we download news articles from different live news websites. We used a dataset that contains around 75k news headlines with its content and category from the year 2012 to 2018 taken from the Huff Post (figure 4.1). These news articles contain eight categories, namely Entertainment, crime, politics, business, world news, sports, media and Tech. The percentage of each class of news article has shown in figure 4.2. First data preprocessing is carryout to clean the data set. The data set we are using has divided into train and test parts. Train data hold 70%, and test data hold 30% of the data set. The classifier is train using this data set that will predict the multi-class labels for the collected news articles and assign a category label to it. Thereby performance evaluation of the classifier is carryout using some performance metric. The detail process of news classification have shown in figure 4.3
4.1 Data Retrieval
In this phase, news articles are crawled from different news websites, as shown in figure 4.3. Firstly, tweets of various news twitter handles are crawled from twitter using tweepy from crawled tweets URLs of various news articles have extracted. Further, news articles web page from each news website has extracted by visiting each URL. In the course, tweets from seven news websites have collected, and news articles of these seven websites have downloaded.
Figure 4.2: Percentage of observation belong to each class
4.2 Data Preprocessing
190 IJSTR©2020
www.ijstr.org
Figure 4.1: Description of the dataset, which contains eight categories of news articles in csv format
4.3 Label Coding
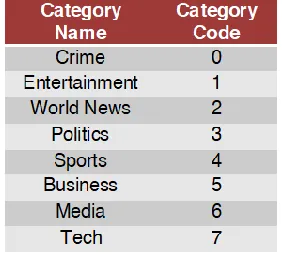
In this phase, we created a mapping scheme because to deliver the prediction; machine learning models require labels and numeric features. Because of this reason, we must build a dictionary to map every category label of the news article with a numerical category code. We used the mapping scheme shown in table 4.1
Table 4.1: Label Coding for different news category
4.4 Train-test split
To prove the model quality for predicting the unclassified data, we need to divide the data set in training and testing parts. We have divided the dataset as a random split with training set consists of 70% and a testing set consists of 30% dataset. In training data, we have performed the hyper-parameter tuning process with the cross-validation, fitted the final model to it and then evaluated with the unclassified data and got evaluation metrics as less biased as possible.
4.5 Training the classifier
In the training phase, training data and the set of labels have used to train the classifier. The training data and labels need vectorizing because the classifier accepts two vectors as its inputs. Once vectorization is complete, both objects given input to the classifier. And classifier training is carried out using a 70% data set.
5
E
XPERIMENTALR
ESULTSA
NDA
NALYSISThis section discusses the experimental results and analysis performed in the above sections. We have used various performance metrics as discussed below
5.1 Accuracy
Accuracy is termed as the number of all correct predictions made by the classifier divided by the total number of the data set. It can be represents in a formula as: accuracy= (TP + TN) / (P + N) or 1- Error. Where TP indicates True Positive and TN indicates True Negative.
5.2 Precision
The ratio of the number of correctly judged articles (True Positive) to the number of articles that are predicted by the classifier belongs to a particular category (True Positive and False Positive) is referred to as precision. The precision can be defined as P=m/ (m+n), where m indicates True Positive and n indicates False Positive.
5.3 Recall
The ratio of correctly predicted positive articles to all articles in the actual class is termed as Recall. The Recall is mathematically express as R= m / (m + t), Where t indicates False Negative and m indicates True Positive.
5.4 F1 Score
F1 score is the Harmonic mean of precision and recall. If we combine Precision and Recall, then it will become the F1 score. The optimal and worst value for F1 is 1 and 0, respectively. It is efficient to use one value for measurement instead of using two values precision and recall as it combines both. F1 score can be calculated as f1=2* (P * R)/ (P + R), where P indicates precision, and R indicates recall.
Figure5.1: Confusion Matrix for the Naïve Bayes Classification
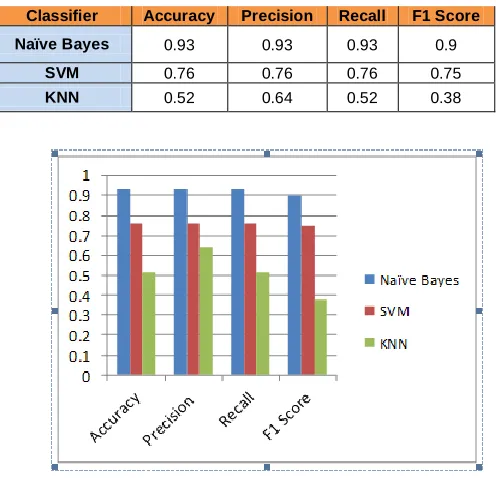
The above discusses performance metrics are shown below in figure 4.4 concerning the three classifier algorithms we used in this experiment in order to perform the classification of news articles. Confusion matrices of all three classifiers (Naïve Bayes, KNN and SVM) has shown from figure 5.1 to 5.3
Figure 5.3: Confusion Matrix for KNN Classification
Table 5.1 Result table
Figure 5.5: Comparing all three algorithms
6 C
ONCLUSIONIn this paper, we discussed the importance of text classification and reviewed some text classification cases using various techniques. Further discusses the possibility of using the machine-learning algorithm for the classification of news articles based on the categories. In this experiment, we uses Naïve Bayes, SVM and KNN algorithms for the successfully classification of news articles problem. Multinomial Naïve Bayes outperformed the other two classifiers.Improving the classifier accuracy is the future work of this proposed work and also tries this implementation with the other classifiers like Neural Networks, Decision Tree etc., and provides more customize news articles for the users.
REFERENCES
[1] Jindal, Rajni, Malhotra, Ruchika, & Jain, Abha “Techniques for text classification: Literature review and current trends. Webology”, 12(2), Article 139. http://www.webology.org/2015/v12n2/a139.pdf [2] Fouzi Harrag,Eyas,EI-Qawasmah, Abdul Malik S.AI
Salman, “Comparing dimension reduction techniques for Arabic text classification using BPNN algorithm”, international journal conference on integrated intelligence computing.2010
[3] N. I. Sapankevych and R. Sankar, "Time Series Prediction Using Support Vector Machines: A Survey," In IEEE Computational Intelligence Magazine, vol. 4, no. 2, pp. 24-38, May 2009. doi: 10.1109/MCI.2009.932254
[4] Zhihang chen, Chengwe Ni and Yil, “Neural network approaches for text document categorization” p(1050-1060).
[5] Xianfei Zhang, Zhengzhou, Zhengzhor, Bichengli, Xianzhu Sun, A K-nearest neighbor text classification algorithm based on fuzzy integral ,p(2228-2231) [6] M. Martinez-Arroyo and L. E. Sucar, "Learning an
Optimal Naive Bayes Classifier," 18th International Conference on Pattern Recognition (ICPR'06), Hong
Kong, 2006, pp. 1236-1239. doi:
10.1109/ICPR.2006.748
[7] P. D. Turney, “Thumbs up or thumbs down?: semantic orientation applied to unsupervised classification of reviews”, In 40th Annual Meeting of the Association for Computational Linguistics, 2002, pp. 417–424
[8] T. Wilson, J. Wiebe, and P. Hoffmann, “Recognizing contextual polarity: An exploration of features for phrase-level sentiment analysis”, Computational Linguistics, vol. 35, no. 3, pp. 399–433, 2009
[9] C. Quan and F. Ren, “Construction of a blog emotion corpus for Chinese emotional expression analysis”, In Conference on Empirical Methods in Natural Language Processing, vol. 3, 2009, pp. 1446–1454 [10]D. Das and S. Bandyopadhyay, “Word to sentence
level emotion tagging for Bengali blogs”, In ACL-IJCNLP 2009 Conference, 2009, pp. 149–152
[11]Y. Chen, S. Y. M. Lee, S. Li, and C.-R. Huang, “Emotion cause detection with linguistic constructions”, In 23rd International Conference on Computational Linguistics, 2010, pp. 179–187
[12]M. Purver and S. Battersby, “Experimenting with distant supervision for emotion classification”, In 13th Conference of the European Chapter of the Association for Computational Linguistics, 2012, pp. 482–491
[13]K. H.-Y. Lin, C. Yang, and H.-H. Chen, “what emotions do news articles trigger in their readers?” In 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, 2007, pp. 733–734
[14]Kevin Hsin-Yih Lin , Changhua Yang , Hsin-Hsi Chen, Emotion Classification of Online News Articles from the Reader's Perspective, In IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, p.220-226, December 09-12, 2008
Classifier Accuracy Precision Recall F1 Score
Naïve Bayes 0.93 0.93 0.93 0.9
SVM 0.76 0.76 0.76 0.75
[15]Y.-j. Tang and H.-H. Chen, “Mining sentiment words from micro blogs for predicting writer-reader emotion transition”, In 8th International Conference on Language Resources and Evaluation (LREC), 2012, pp. 1226–1229
[16]B. Pendharkar, P. Ambekar,P. Godbole, S. Joshi, and S. Abhyankar, Topic categorization of rss news feeds, Group vol. 4, p. 1, 2007
[17]Rao, V., Sachdev, J., “A machine learning approach to classify news articles based on location”, In International Conference on Intelligent Sustainable Systems, pp. 863–867 (2017)
[18]Nawei Chen and Dorothea Blostein, 2006, “A survey of document image classification: problem statement, classifier architecture and performance evaluation”, Springer-Verlag, doi: 10.1007/s10032-006-0020-2 [19]Vishal Gupta, Gurpreet S. Lehal, “A Survey of Text
Mining Techniques and Applications”, Journal of Emerging Technologies in Web Intelligence, Vol. 1, No. 1, August 2009
[20]Christopher D. Manning, Prabhakar Raghavan and Hinrich Schutze, “Introduction to Information Retrieval”, Cambridge University Press, 2008
[21]Wenmin Li, Jiawei Han and Jian Pei, 2001, “CMAR: Accurate and Efficient Classification Based on Multiple Class-Association Rules”, In IEEE International Conference on Data Mining - ICDM, pp. 369-376, DOI: 10.1109/ICDM.2001.989541
[22]Xiaoxin Yin, Jiawei Han. CPAR, “Classification based on Predictive Association Rules”, In SDM, 2003. doi=10.1.1.12.7268
[23]Fernando Berzal, Juan-Carlos Cubero, Nicolás Marín Daniel Sánchez, Jose-María Serrano, Amparo Vila:”Association rule evaluation for classification purposes” Actas del III Taller Nacional de Minería de Datos y Aprendizaje, TAMIDA2005, pp.135-144 ISBN: 84-9732-449-8 © 2005 Los autores, Thomson [24]Chuntao Jiang, Frans Coenen, Robert Sanderson,
Michele Zito, “Text classification using graph mining-based feature extraction”, Journal Knowledge- Based Systems Volume 23 Issue 4, Elsevier
[25]Dat Huynh, Dat Tran, Wanli Ma, Dharmendra Sharma, “A New Term Ranking Method Based on Relation Extraction and Graph Model for Text Classification”, Faculty of Information Sciences and Engineering, University of Canberra ACT 2601, Australia
[26]Jiawei Han, Michelin Kamber, “Data Mining Concepts and Techniques”, Morgan Kaufmann publishers, USA, 70-181
[27]Jingnian Chen, Houkuan Huang, Shengfeng Tian and Youli Qu, “Feature selection for text classification with Naive Bayes”, Expert Systems with Applications: An International Journal, Volume 36 Issue 3, and Elsevier [28]Schapire, R.E., & Singer, Y., “BoosTexter: A boosting-based system for text categorization”. Machine Learning, 39, 135–168
[29]Basu, A., Watters, C., & Shepherd, M, “Support vector machines for text categorization”, In 36th Hawaii IEEE International Conference on System, HICSS’03
[30]Ruiz, M.E., & Srinivasan, P., “Hierarchical text categorization using neural networks”, Information Retrieval, 5, 87–118
[31]Z. Wang and M. Jiang, "Multi-labeled Chinese Text Categorization Based on the Boosting Algorithms," 2009 Fifth International Conference on Natural Computation, Tianjin, 2009, pp. 205-208 [32]Namburu, S.M., Tu, H., Luo, J., & Pattipati, K.R.
“Experiments on supervised learning algorithms for text categorization”, IEEE Aerospace Conference, 1-8 [33]Fragoudis, D., Meretakis, D., & Likothanassis, S.,
“Best terms: an efficient feature-selection algorithm for text categorization”. Knowledge and Information Systems, 8, 16–33
[34]Vikramjit Mitra, Chia-Jiu Wang and Satarupa Banerjee, “A neuro-SVM model for text classification using latent semantic indexing”, In 2005 IEEE International Joint Conference on Neural Networks, 2005, Montreal, Que., 2005, pp. 564-569 vol. 1 [35]Z. Wang, X. Sun, D. Zhang and X. Li, "An Optimal
SVM-Based Text Classification Algorithm," In 2006 International Conference on Machine Learning and Cybernetics, Dalian, China, 2006, pp. 1378-1381. [36]Mitra, V., Wang, C.J., & Banerjee, S “Text
classification: A least square support vector machine approach”. Applied Soft Computing, 7, 908–914 [37]Wang, Y., & Wang, Z.O., “A fast kNN algorithm for
text categorization”, In Sixth IEEE International Conference on Machine Learning and Cybernetics, Hong Kong, 19-22 August 2007
[38]Lee, K.S., & Kageura, K., “Virtual relevant documents in text categorization with support vector machines”, Information Processing and Management, 43, 902– 913
[39]Esuli, A., Fagni, T., & Sebastiani, F, “Boosting multi-label hierarchical text categorization”, Information Retrieval, 11, 287-313
[40]Wang, T-Y., & Chiang, H. M., “One-against-one fuzzy support vector machine classifier: An approach to text categorization”. Expert Systems with Applications, 36(6)
[41]Cabrera, R.G., Gomez, M.M.Y., Rosso, P., & Pineda, L.V., “Using the Web as corpus for selftraining text categorization”, Information Retrieval, 12, 400–415 [42]F. Harrag and E. El-Qawasmah, “Neural Network for
Arabic text classification”, In 2009 Second International Conference on the Applications of Digital Information and Web Technologies, London, 2009,pp.778-783.
[43]Zelaia, A., Alegria, I., Arregi, O., & Sierra, B., “A multiclass/multilabel document categorization system: Combining multiple classifiers in a reduced dimension”. Applied Soft Computing, 11, 4981–4990 [44]Shi, L., Ma, X., Xi, L., Duan, Q., & Zhao, J, “Rough set
and ensemble learning based semi-supervised algorithm for text classification”, Expert Systems with Applications, 38, 6300–6306
[46]Li, W., Miao, D., & Wang, W., “Two-level hierarchical combination method for text classification”, Expert Systems with Applications, 38, 2030–2039
[47]D. Saha, “Web Text Classification Using a Neural Network”, In 2011 Second International Conference on Emerging Applications of Information Technology, Kolkata, 2011, pp. 57-60.
[48]Wan, C.H., Lee, L.H., Raj Kumar, R., & Isa, D., “A hybrid text classification approach with low dependency on parameter by integrating K-nearest neighbor and support vector machine”. Expert Systems with Applications, 39, 11880–11888.
[49]Pan, S., Zhang, Y., & Li, X., “Dynamic classifier ensemble for positive unlabeled text stream classification”, Knowledge Information System, 33, 267–287
[50]T. Dong, W. Cheng and W. Shang, "The Research of kNN Text Categorization Algorithm Based on Eager Learning," In 2012 International Conference on Industrial Control and Electronics Engineering, Xi'an, 2012, pp. 1120-1123.
[51]Anuradha, “Neural Network Approach for Text Classification using Relevance Factor as Term Weighing Method”, IJCA Journal, Vol. 68, Issue.17, pp-37-41
[52]F. A. Zaghoul and S. Al-Dhaheri, “Arabic Text Classification Based on Features Reduction Using Artificial Neural Networks”, In 15th International Conference on Computer Modelling and Simulation, Cambridge, 2013, pp. 485-490
[53]Bijalwan, Vishwanath & Kumari, Pinki & Espada, Jordán & Semwal, Vijay. “KNN based Machine Learning Approach for Text and Document Mining”. International Journal of Database Theory and Application. 7.
[54]Y. Lin and J. Wang, “Research on text classification based on SVM-KNN”, In IEEE 5th International Conference on Software Engineering and Service Science, Beijing, 2014, pp. 842-844