Document Classification Using Support
Vector Machine
Shweta Mayor1, Bhasker Pant2
[email protected], [email protected] Graphic Era University, Dehradun1, 2
ABSTRACT: Information like NEWS FEEDS is generally stored in the form of documents and files created on the basis of daily occurrence in the world. Classifying an unstructured text in these large document corpora has become cumbersome. Efficiently and effectively retrieving and categorizing these document is a hard task to perform. This research paper discuss in detail the implementation of Support Vector Machine (SVM) for calculating term frequency of the features used as Sports, Business and Entertainment for categorization with the help of a manual domain dictionary.SVM is a comparatively new technique solving a variety of ‘learning from examples’ problem and results high performance in any practical applications.
Keywords: Unstructured document, Categorization, SVM Text and data mining.
1. INTRODUCTION
Text mining is a burgeoning new field that attempts to glean meaningful information from natural language text or unstructured text. Thus,the phrase “text mining” is generally used to denote any system that analyzes large quantities of natural language text and detects lexical or linguistic usage patterns in an attempt to extract probably useful information [8]. And Information is basically stored in the form of documents and files. It is relatively less cumbersome to define categories broadly classifying the information contained in these collections. The process of deriving high-quality information from large collections of documents like news feeds, databases, or the Web is coined as Document mining [2]. Text classification which is automated is attractive because it frees organizations from the need of manually organizing document bases, which can be too expensive, or simply not feasible given the time constraints of the application or the number of documents involved [13].
Since Inception News papers were the basic medium for communication of the information and reaching to the people. Now from past few years’ news are exponentially increasing and the mode of medium also increased through newspapers, news channels, news sites etc. Thus, it has become a tedious task for the database administrator (DBA) to distinctly separate the news according to the area like Sports, business, entertainment, religion, weather etc. To solve and reduce the burden of the DBA is to classify the news according to their specific classes and also give high performance practically.
In this paper, we study how the information from the newspapers can be categorized into different classes and then classified using Support Vector Machine(SVM).This concerns with the demarking the information and extract it according to the need of the reader choice. This will help the reader to directly search for the specific news needed.
1
http:// aajtak.intoday.in
2
http://ibnlive.in.com The Times of India
Table 1: Some examples of news taken from the new papers
I have collected around 50 news instances from the newspapers or sites which are further automatically distributed into three classes as follows:
1. News related to Sports like cricket, hockey, chess, squash etc into a Sports.txt file. 2. News related to Business like shares, stocks, revenues, profit etc into a Business.txt file.
1.1. CONTRIBUTION
This Paper will contribute in many ways as:
1. Method used is this paper result in finding how the extraction of the feature is done.
2. Classifier is designed and developed to classify the collected news clipping into desired classification and store the frequency of the feature in distinct files.
3. After the classification linguistic analysis can be done to improve the results.
Table 1: Some instances of news taken from the newspapers
1.2. ORGANISATION
This paper further fulfils the purpose of exploring the crystal clear picture of the tool and method used for classification which has been described in section 2.0. Then training and prediction is carried out with the mathematical evaluation in section 3.0. Finally conclusion is presented for this paper.
2.0 MATERIAL METHODS AND APPROACH
In this section I have discussed the methods and approaches used for classifying the documents.
TEXT CATEGORIZATION
Text categorization (TC – also known as text classification, or topic spotting) is the task of automatically sorting a set of documents into categories (or classes, or topics) from a predefined set [13].The concept of text categorization is the classification of documents into a fixed number of predefined categories or classes [5]. DOCUMENT classification can be defined as the task of automatically categorizing collections of electronic documents into their annotated classes based on their contents [9]. Each document can be in exactly one, multiple or no category at all. Using machine learning, the objective is to learn classifiers from examples which perform the category assignments automatically. This is a supervised learning problem. Since categories may overlap, each category is treated as a separate binary classification problem [5]. Categorization helps to identify as to exactly which category of the domain in use, a certain text file relates to [1]. The categorization that we implemented requires extensive tokenization. Tokenization refers to the extraction of feature terms in the document [1].
In this section I have decided my news instances or clipping to be sectioned into three classes as Sports, Entertainment and Business which is further tokenized for extraction. A manually domain dictionary has been made for each class consisting of all the features related to it. Each feature is then vectorized that inferring the frequency of each feature in the dictionary through classifier tool as shown in figure 1. This further becomes the input or entry point for the SVM.
The third-seeded Belarusian overpowered Sharapova to win 6-3, 6-0 in 82 minutes to lift the trophy and become women's tennis's fourth first-time Grand Slam winner in a row. Azarenka came from 0-2 down in the first set to win 12 of the next 13 games for a comprehensive victory as Sharapova's games disintegrated in the face of all-out aggression from the Belarusian.
"Kareena comes on the sets with this thing of 'let’s do work'. She doesn't have time to waste on things like, which angle you are shooting me from, my costume, hair, make-up is like this and all. She is utterly unconcerned about this stuff. She is a good actress, she knows it and she has that security and confidence to just do her work," said the 29-year-old.
Shares of ICICI Bank today jumped nearly 6 per cent, after the country's largest private-sector lender reported 20 per cent growth in net profit for the third quarter ended December. Investors flocked to buy ICICI stock at the BSE pushing up its price by 5.87% to Rs 902. Intra-day, the scrip that is among top heavyweights on Sensex zoomed 6.39%.
One of the most popular tracks 'Mehndi Laga Ke Rakhna' of 'Dilwale Dulhaniya Le Jayenge' that features Bollywood super star Shah Rukh Khan and the effervescent actress Kajol was originally thought to be a part of another movie.
Figure 1: Snapshot of Classifier Tool
2.1 SUPPORT VECTOR MACHINE IMPLEMENTATION
SVM is first proposed by Vapnik [10,11] and its Group at AT&T Bell Laboratories proposed a new technique Support vector machines [SVM] providing a group of supervised learning methods that can be applied to classification or regression [3,7,12]. Supervised learning is a very popular approach, in which, Text Classification (TC)algorithms learn classification patterns from a set of labeled examples, given a large enough number of labeled examples (training set), and the task is to build a TC model. Then we can use the TC model to predict the category (class) of new unseen examples (test set) [14].SVM learns to construct N-dimensional hyper plane as a decision surface such that the margin of separation between positive and negative examples is maximized [6].
For implementing SVM, a Software called LIBSVM by Chung Chang and Chih-Jen Lin was used. LIBSVM is integrated software for support vector classification, regression and distribution estimation [one-class SVM].It supports multiclass classification [3, 4]. The goal of using LIBSVM is to identify positives so that the classifier can accurately predict the unknown data [i.e. testing data].The values from the testing file is fed into the LIBSVM tool for training and predicting the data set and analysis is done [3].
2.2 PROPOSED ALGORITHM FOR THE CLASSIFICATION
Step 1: Corpus collection
The first step is to collect the instances [i.e. News clipping] from the Newspapers or News sites.
Step 2: Creation of domain dictionary
In this Step all the features from the instances are extracted and stored in file.
Step 3: Classification from Classifier Tool
The next step is to classify those collected instances into sub-classes as Sports, Entertainment and Business through the classifier tool. The classifier generally takes a single instance and then matches it with the features in domain dictionary containing some synonym of features. This mapping is done to generate the threshold frequency for each feature and automatically generate a text file of it.
Step 4: Processing of LIBSVM tool
The generated text files is then processed in the LIBSVM tool that provides the accuracy rate for testing classification which is further been trained and predict to be analyzed. The result of the training and predicting produces a contour graph shown in section 3, figure 2.
Step 5: Analyzing the results
3. RESULT AND DISCUSSION
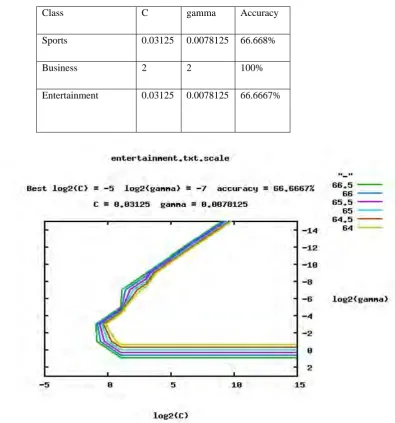
The performance of the method is evaluated through the contour graph as show in figure 2 below. The accuracy rate of the prediction has been depicted as 66.6667% with the values[ gamma=0.0078125 and C=0.03125] .The libSVM provides a parameter selection tool using the cross validation via grid search. A grid search was performed on C and Gamma using an inbuilt module of libSVM tools as shown in table 2. Here pairs of C and Gamma are tried and the one with the best cross validation accuracy is picked [3]. This observation can also be extended to other kind of documents like journals, novels, medicines by establishing good data sets.
The future work can be done when any document is directly been fetched from the web and then classified accordingly.
Table 2: C and Gamma values for training set of News Feeds with accuracies.
Figure 2: Contour graph of the entertainment class showing accuracy after the classification.
This Contour graph predicts the accuracy rate of the classification done on the entertainment class. Likewise classification is done on the remaining two classes : Sports and Business and contour graph is produced respectively for the same .
Class C gamma Accuracy
Sports 0.03125 0.0078125 66.668%
Business 2 2 100%
4. CONCLUSION
We determined the average accuracy of three classes is 66.667%. We finally conclude our work by proving that we developed very efficient and reliable classification technique. Our technique majorly focused on news collected from different news resources including websites. Technique we developed is mainly useful for news available on the web. This concept can be customizing on broad level to categorized news content on web which also provide fast content management. In our work we only take three classes of news that could be extended up to large level of classes and subclasses. As we defined above LibSvm used for multiclass classification so it can apply for any number of classes containing news of different categories.
5. REFERENCES
[1] Atika Mustafa, Ali akhbar and ahmer Sultan, Knowledge discovery using text mining: A Programmable implementation on Information Extraction and Categorization, (2009).
[2] Debnath Bhattacharyya, Poulami Das, Debashis Ganguly, Kheyali Mitra, Purnendu Das, Samir Kumar Bandyopadhyay, Tai-hoon Kim, Unstructured Document Categorization: A study, (2009).
[3] Bhasker Pant, K.R. Pardasani, DiRiboPred: A Web Tool for Classification and Prediction of Ribonucleases, (2010). [4] Chang, C.-C., & Lin, C.-J., LIBSVM: a library for support vector machine, (2003).
[5] Thorsten Joachims, Proceeding ECML '98 Proceedings of the 10th European Conference on Machine Learning, (1998). [6] Saurav sahay, Support vector machine and document classification, (2004).
[7] Hyun-Chul Kim, Shaoning Pang, Hong-Mo Je, Daijin Kim, Sung Yang Bang, Constructing support vector machine ensemble, (2005).
[8] Ian H.Witten, Text mining, (2005).
[9] Dino Isa, Lam Hong Lee, V.P. Kallimani, and R. RajKumar,Text Document Preprocessing with the Bayes Formula for Classification Using the Support Vector Machine. IEEE Transactions on Knowledge and Data Engineering archive Volume 20 Issue 9, (September 2008).
[10] V.N. Vapnik, “The Nature of Statistical Learning Theory,” Springer, New York, (1995).
[11] Ya Gao and Shiliang Sun, An Empirical Evaluation of Linear and Nonlinear Kernels for Text Classification Using Support Vector Machines, (2010).
[12] C. Cortes, V. Vapnik, Support vector network, Mach. Learn. Pages 273–297, (1995). [13] Fabrizio Sebastiani, Text Categorization, (Jan 2004).