Scaling Up an MT Prototype for Industrial Use - Databases and Data Flow
Anna S˚agvall Hein , Eva Forsbom
, J¨org Tiedemann
,
Per Weijnitz
, Ingrid Almqvist
, Leif-J¨oran Olsson
, Sten Thaning
Uppsala University Department of Linguistics Box 527, SE-751 20 Uppsala, Sweden
evafo, joerg, perweij, ljo, sten @stp.ling.uu.se
Abstract
In a cooperative project between Uppsala University, the bus and truck manufacturing company Scania CV AB, and the translation company Explicon AB, issues of scaling up the transfer-based machine translation prototype MULTRA for industrial use is beeing investigated. The project is limited to one domain, automotive service literature, and one translation direction, Swedish to English, but issues concerning the change of domain, translation direction and language pair are also considered. Three focal points of the project work have been the design and implementation of the new MATS system, including the redesign, porting and integration of MULTRA, the redesign and implementation of the dictionaries of the language modules as a lexical database, and the scaling up of the dictionaries and the grammars. The system is currently trained on a corpus of aligned bitexts from the automotive service domain. The coverage of the lexical data is almost complete, and validated by professional translators, but the grammars are still limited. Despite the incomplete state of the grammars, the system already translates more than a third of the segments in the corpus. Preliminary evaluations of system performance and coverage have been made, and further development of evaluation methods and metrics are in progress.
1.
Introduction
The MATS project1is a cooperative project between the Department of Linguistics at Uppsala University, the trans-lation and documentation company Explicon AB (earlier Translator Teknikinformation AB), and Scania CV AB. It aims at the development of a high-quality machine transla-tion system for industrial use based on the research proto-type MULTRA (S˚agvall Hein, 1997). Demo versions of MULTRA translates from Swedish to English and German. The project is a follow-up of a pilot study, in which the steps to be taken from research prototype to industrial sys-tem were investigated. Issues concerning the reverse trans-lation direction, and the change of domain were also con-sidered. For funding reasons, however, the goals of the main project had to be restricted to one translation direction (Swedish to English), and one domain (automotive service literature).
The three focal points of the project work have been the design and implementation of the MATS system, includ-ing the redesign, portinclud-ing and integration of MULTRA, the design and implementation of a lexical database for multi-lingual data, the redesign and implementation of the dictio-naries of the language module as a lexical database, and the scaling up of the dictionaries and grammars of the language module.
The presentation of the project work is centred round these issues, starting by a short description of the original version of MULTRA and the changes that were called for by the MATS system and the scaling up effort.
2.
Background
MULTRA is short for Multilingual Support for Transla-tion and Writing. It is strictly modular transfer-based
sys-1
http://stp.ling.uu.se/mats
tem. In addition to the classical components of a transfer-based system for analysis, transfer, and generation, MUL-TRA comprises a preference module that is responsible for ordering competing analysis structures in a preferred order (S˚agvall Hein, 1994).
MULTRA was primarily intended for high-quality translation from Swedish to English and German within limited domains. Prior to the MATS project, MULTRA has mainly been used for research and teaching purposes.
Analysis is carried out by means of a chart parser, Up-psala Chart Processor, UCP (S˚agvall Hein, 1983). It han-dles dictionary search, morphological analysis, and syntac-tic analysis in a uniform manner. Grammars and dictio-naries in UCP are formulated in a procedural formalism (Ahrenberg, 1984; S˚agvall Hein, 1984b; Dahll¨of, 1989).
The transfer and generation components of MULTRA are based on unification. Generation, in addition, includes concatenation and morphological processing. Transfer and generation rules are expressed in PATR-like formalisms that were specifically developed for MULTRA (Beskow, 1993; Beskow, 1997a; Beskow, 1997b). Lexical and gram-matical transfer rules are formulated in the same formal-ism, facilitating the transfer of lexical units in context. The transfer rules are partially ordered; a more specific rule has precedence over a less specific one, i.e. a lexical transfer rule taking a context larger than the word itself into account will have precedence over a lexical rule out of context. The lexical translation rules are formulated in the MUL-TRA transfer formalism. The transfer and generation com-ponents of MULTRA are written in Prolog. The original version of MULTRA runs on an AIX Unix server.
3.
System Enhancement and Design
Processing in the MATS system proceeds in a number of distinct steps from an SGML version of the source docu-ment to an SGML version of the target docudocu-ment via MUL-TRA. Even though the system was primarily made to pro-cess SGML documents, the modular design of the system allows for other front-ends and back-ends.
The platform itself does not offer a user interface al-though a reference interface has been implemented for test-ing and demonstration purposes2. Most parts of the system
existed as separate components before the project started, others were created from scratch. See further (Weijnitz, 2002).
3.1. Architecture
A starting point in the design was the modular nature of the MULTRA machine translation system. From the strict modularity of MATS follows that every step in the trans-lation is handled by a stand-alone program. The modular-ity makes the system compositional, and it is possible to test parts of the pipe as easy as to test the complete sys-tem. It is easily adapted to new tasks, simply by remov-ing, reordering or adding new modules. Examples of such modifications are replacing the parser or transfer module, or replacing the front-end and back-end in order to process other document formats.
The modules are sequentially connected using a unidi-rectional data pipe. The output of one module is the input of the next. The traffic is multiplexed, meaning that many different data channels may be transported in a shared pipe. This means that even though the traffic flows through the modules in sequential order, it is possible for modules to communicate privately with any module downstream with-out interference from the intermediate modules. All data communication is text based for transparency and traceabil-ity. It is possible to see exactly what happens to data as it is run through the pipe, before and after each module. A protocol specifies how a module communicates with other modules. It is quite simple and not bound to a certain pro-gramming language.
3.1.1. MULTRA Revisited
In the MATS project a light C-version of the parser (Weijnitz, 1999) has been substituted for the original Lisp version. The light version is limited to syntactic process-ing, and so is the new generation process. Thus, morpho-logical analysis and generation have to be handled outside MULTRA. MULTRA has been linked to two monolingual lexical databases for the source and target language, respec-tively. The lexical databases deliver full form lexical rep-resentations in terms of wordforms, lemmas, and linguis-tic codes. Further, the lexical units of the two databases have been linked to each other via translation relations. In this way, an intermediary translation database has been cre-ated, see further 3.2. below. For each lexeme, there is only one translation relation in the database, a default transla-tion. Default translations are retrieved from the database in connection with the dictionary search in the analysis phase. Alternative translations take the context into account are ex-pressed in the MULTRA transfer formalism. This
restruc-2
http://stp.ling.uu.se/˜perweij/mats
turing of the lexical data implies a major simplification and speeding-up of the system.
The two monolingual databases have a uniform struc-ture to facilitate a fustruc-ture change of translation direction. See further 3.2.
The database format implies a restructuring of the lex-ical material as compared to the original version of MUL-TRA. It also implies a re-design and re-implementation of MULTRA itself. In particular, the input to the system will be a list of lemmas and linguistic codes that are retrieved from the database. The codes will be expanded to feature structures before parsing proper starts. The lemmas carry along information about their associated lexemes (distinct senses) in the source and the target language, respectively.
The work to adapt MULTRA to MATS included porting it from AIX to GNU/Linux. The old GUI was outdated and removed, and the code revised to fit the latest version of the Prolog system.
3.1.2. The MATS Modules
Each step in the translation process is handled by one module. Deciding on what should be handled by how many modules was primarily a question of looking at what soft-ware was available for reuse. Some modules have simple tasks and others have complex tasks. The tasks of transfer and generation are handled by one program, MULTRA, as it was already constructed that way. However, MULTRA is itself modular, offering similar kind of traceability as the other modules.
extracting the text segments from the SGML-format and passing them
on segment-wise, tokenising the segments, retrieving the lemmas
and morpho-syntactic codes of the tokens from the source data base,
creating a list structure of lemmas and codes, parsing the list
structure and generating a syntactic feature structure,
transferring the feature structure, generating a string of lemmas
and morpho-syntactic features, substituting codes for the features,
retrieving the words from the target database, generat-ing a strgenerat-ing
of words, finalising the string with capital letter and a proper
placement of signs of punctuation, and transforming the SGML output
with XSLT for presentation.
to present the documents in a graphical environment, in or-der to facilitate a comparison between the source document and the translated target document(Olsson, 2002).
There is also a module for computing the recall of the translation, see5.2.
3.2. MatsLex - a Multilingual Lexical Database
The MatsLex database is designed to provide a flexible and coherent environment for storing and managing multi-lingual lexical data, and for linking them bi-multi-lingually. The internal structure of the lexicon is based on a relational database model. The database can be queried and updated via transparent database ’views’ in web-based interfaces. MatsLex is the central store of all the lexical data avail-able for the translation process, and from this ”run-time lexica” such as bilingual link lexica are compiled. For con-sistency, modifications are allowed in the central database only whereas runtime lexica are strictly read-only. It facili-tates porting, updating and maintenance of the dictionaries, and the future extension of the system for translation from English to Swedish. Prior to the running of the system, the dictionary is compiled.
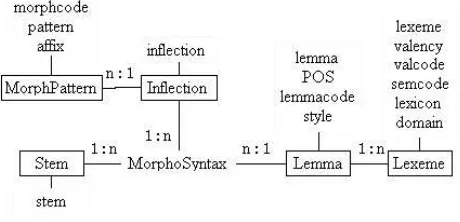
The Database Structure The lexical database comprises a set of entities with morphological, syntactic, and semantic information with appropriate relations between them. The relational structure of a monolingual part of the database is shown in figure 1.
Figure 1: Monolingual database structure.
Morphosyntactic and semantic information is com-monly expressed by feature structures. In the MATS database, compressed, compositional codes are used as short-cuts for feature structures. Codes are defined for expressing morphosyntactic features (morphcode), lemma-specific features (lemmacode), semantic features (sem-code), and valency related features (valcode).
Surface wordforms are not included explicitly in the database. MatsLex keeps inflectional patterns instead and surface words are derived from these patterns and their technical stems. The crucial point of this approach is to de-fine accurate paradigms and to correctly link lexical entries to appropriate paradigms. Generalised patterns may not be suitable for all languages but in the worst (but most un-likely) case each entry would have its own paradigm. The advantage of this approach is to make updating the database easier. All the possible surface forms are included implic-itly when a lemma enters the database. The morphological paradigms in MatsLex are labeled by representative words
and their inflectional patterns are defined in table ’Morph-Pattern’ by regular-expressions. The ’pattern’ field speci-fies a regular expression to be matched against the technical stem and the ’affix’ field holds the modification to be made in the creation of the wordform. In many cases (in Swedish and English) this simply means concatenating appropriate suffixes with the technical stem.
Another distinctive feature of the database is the pos-sibility to use regular expressions as technical stems that match classes of similar tokens with the same morphosyn-tactic and semantic features. Constructions with a gen-eral pattern are, e.g., dates, time-expressions, and numbers. Some examples are given in table 1.
stem examples
([0-9]+),?([0-9]*)(\%) 50,5% ; 99% ([0-9]*1):a 1:a; 261:a ([0-9]+):e 9:e; 764:e ([0-9]{2})\/([0-9]{2})\/([0-9]{2}) 01/03/04
Table 1: Token classes defined by regular expressions.
The MatsLex database stores each table from the mono-lingual lexicon with a language prefix. Hereby, data for ad-ditional languages can be added easily to the database. The advantage of keeping several languages in parallel in one central database is the possibility to link them together. To accomplish this, MatsLex allows the establishment of bilin-gual links between lexemes from different languages. The structure of such links within the relational framework is shown in figure 2.
4.
Scaling Up the Language Resources
4.1. Defining the domain
The coverage of the lexical data should be complete with regard to the automotive service domain. The domain was set by a corpus of service literature documents pro-vided by Scania. This corpus, the MATS corpus, comprises Swedish source documents with English and German trans-lations. The corpus has been split into text segments, i.e. sentences, head lines and other kinds of word sequences or words with an independent status in the text3; further,
translation links have been established between the text seg-ments language pair wise. The MATS corpus has been di-vided into two sub corpora, one for training and one for evaluation. The Swedish training corpus comprises roughly 40,000 current words and the evaluation corpus approxi-mately 10,000 words.
4.2. Dictionaries
4.2.1. Augmenting the Swedish dictionary
The starting point for the Swedish dictionary was Sca-nia Swedish, a vocabulary of some 24,000 lemmas ex-tracted from previous corpora (Almqvist and S˚agvall Hein, 1996; Almqvist and S˚agvall Hein, 2000).4 It was devel-oped as a basic resource for Scania Checker, a language
3
The segmentation of the text into text segments is based on the SGML mark up of the text. Each text segment has its own id number.
4
checker that was built in a previous co-operation project between Scania and Uppsala University (Almqvist and S˚agvall Hein, 2000). The vocabulary of the checker was filtered from a corpus of some 1,8 million words (Tiede-mann, 1999). Initially, only wordforms that had actually occurred in the corpus were included. However, the run-ning of the checker demonstrated that there was a need to fill in the wordform gaps. This was done by means of a wordform generation program that was developed for the purpose (Karlsson and Thaning, 2001). The Scania vo-cabulary includes approved words and non-approved words with replacements. It is assumed that the translation sys-tem should operate on text that has been run through the checker, and thus the non-approved words were deleted from the Swedish dictionary. As a result, the number of lemmas in the dictionary decreased by a couple of thou-sand words to 20,883. In the original version of MULTRA the number of Swedish lemmas was limited to 369. As re-gards the number of lexical units the dictionary should be complete. What is missing, however, is information about valency frames and semantic features, that will be needed in the analysis phase. Two studies were devoted to these tasks. They are completed and reported in (Thaning, 2001) and (Hellstr¨om, 2001), respectively. The material that was generated in the two studies will be included in the lexical database. As regards the valency issue, see further 4.3.1.
4.2.2. The Swedish-English Translation Dictionary
The translation dictionary for MULTRA has been scaled up from 59 lexemes in the prototype to 7,043 lexemes in the new lexical database (Forsbom, 2002b). The translation equivalents for a subset of the units in the Swedish dictionary were previously automatically ex-tracted from the Scania corpus by means of a statistically based word aligner, the Uppsala Word Aligner (Tiedemann, 1999). This raw material was also lemmatised (heuristi-cally, in the case of English), looked up in existing domain dictionaries of varying reliability, and preliminary evalu-ated, so that obvious errors were removed (L¨ofling, 2001).
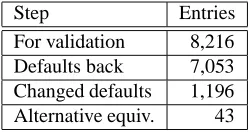
Validation of Translation Dictionary During the MATS project, 8,216 of the remaining 14,128 entries (10,510 Swedish lemmas) were manually reviewed by professional translators, using translation memories of the Scania corpus for reference in tricky cases. In the material, one Swedish lemma could be linked to more than one suggested English equivalent, but in the translation dictionary, there should be only one translation relation, a default translation, for each Swedish entry. Alternative translations were to be ex-pressed as contextual rules in the MULTRA transfer for-malism.
For each entry the translators should either accept or reject the translation. If they rejected a translation, they were to replace it with an acceptable one. If there were two or more translations for a Swedish entry, they were supposed to choose one translation as the default transla-tion, based on frequency or dictionary information. (Re-jected and changed alternatives can later be extracted and entered as not acceptable alternatives in an English checker, in order to reduce unnecessary variation and increase con-sistency.) For some entries with alternative translations,
however, more than one candidate were acceptable, but in different contexts. The most general or frequent alternative was chosen as the default, and contexts were given for the others, as they were to be entered as contextual rules in the grammar. The result is shown in Table 2.
Step Entries
For validation 8,216 Defaults back 7,053 Changed defaults 1,196 Alternative equiv. 43
Table 2: Validation of entries
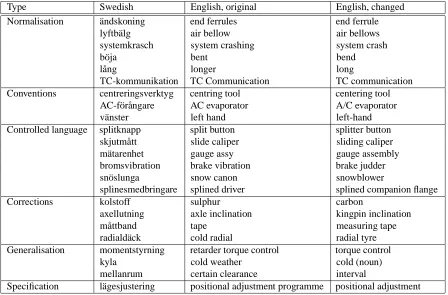
Rejections and changes were made based on, inter alia, the following principles: normalisation, writing conven-tions, controlled language candidacy, corrections of transla-tion and linking errors, generalisatransla-tions, and specificatransla-tions. See examples in Table 3.
Approximately 300 of the new default equivalents had been changed to another part of speech than the Swedish lemma, or to a phrasal expression, etc., and have conse-quently not been added to the dictionary, but will be han-dled by contextual rules instead. The rest have been as-signed a lexeme number each. As we only have checked default translations for the direction Swedish to English yet, some English words are linked to more than one Swedish lexeme. By checking the other direction too, we can find candidates for controlled language on the Swedish side also. For example, adjustable pliers is linked to both
poly-grip and polypoly-gript ˚ang, both of which refer to the same tool.
For some of the alternative translations, the same side ef-fect could be seen. When we looked in the MATS corpus at the contexts for the Swedish word drev with the default translation gear wheel and the contextual translation pinion, we found no occurrences of the relation drev–gear wheel, 7 occurrences of drev–pinion, and 73 occurrences of the new relation pinjong–pinion.
Entries not sent to the translators included simple copies, entries marked as general domain, and translation shifts, such as different parts of speech (certifierad (adj.) vs. certification (noun)), different verb frames (han heter
John vs. he is called John5), and phrasal translations. Most copies are taken care of by regular expressions (see 3.2.), but some need to be added. Translations shifts and phrasal translations are (or will be) handled by contextual rules.
4.2.3. The English Generation Dictionary
The generation dictionary for MULTRA has been scaled up from 184 lexemes in the prototype to 7,280 lex-emes in the new lexical database. The new entries are de-rived from the English part of the validated translation dic-tionary. By changing the translation direction, we have run the English target documents of the MATS corpus through the first three modules of the system to see how well the new dictionary covers them, and got a coverage of 89% of 63,870 tokens.
5
Type Swedish English, original English, changed
Normalisation ¨andskoning end ferrules end ferrule
lyftb¨alg air bellow air bellows
systemkrasch system crashing system crash
b¨oja bent bend
l˚ang longer long
TC-kommunikation TC Communication TC communication Conventions centreringsverktyg centring tool centering tool
AC-f¨or˚angare AC evaporator A/C evaporator
v¨anster left hand left-hand
Controlled language splitknapp split button splitter button
skjutm˚att slide caliper sliding caliper
m¨atarenhet gauge assy gauge assembly
bromsvibration brake vibration brake judder
sn¨oslunga snow canon snowblower
splinesmedbringare splined driver splined companion flange
Corrections kolstoff sulphur carbon
axellutning axle inclination kingpin inclination
m˚attband tape measuring tape
radiald¨ack cold radial radial tyre
Generalisation momentstyrning retarder torque control torque control
kyla cold weather cold (noun)
mellanrum certain clearance interval
Specification l¨agesjustering positional adjustment programme positional adjustment
Table 3: Types of changes made by translators during validation.
In order to move the English generation dictionary into the new lexical database (see 3.2.), we had to de-fine a set of English-specific morphosyntactic codes and inflectional paradigms, analogous to those in the Swedish database (Forsbom, 2002a). The most frequent inflectional paradigm, for example, is labelledDOGand is mapped to four morphosyntactic codes representing four wordforms (dog, dog’s, dogs, and dogs’).
As one project aim was to facilitate a reversal of the translation direction, the codes were supposed to serve both analysis and generation needs. When used in the analysis module, a code is expanded to a feature structure containing all morphosyntactic information needed in the analysis (cf. Figure 2). In the generation module, the procedure is the reverse: a feature structure corresponding to a wordform is conflated into a corresponding code, and the actual word-form retrieved from the dictionary. This two-fold purpose sometimes means balancing between under- and overspec-ification of features with regard to the two modules, as not all information which is used for analysis is used for gener-ation, and vice versa.
"!#$%'&)(*% +-,)./ "!012,"!0./
34
5
Figure 2: FS for the codeNNSBand lemmadog.nn.
4.3. Grammars
There are three grammars in the system: a Swedish grammar, a translation grammar, and an English grammar. The scaling up of the grammars is in progress. The corpus-based training of the grammars has, so far, been limited to a mini training text of 53 text segments of varying complex-ity. It is part of the MATS corpus and constitutes the first part of a fairly large document that by Scania was consid-ered to be representative of the text type.
The MATS platform provides an excellent basis for training the grammars in tandem. Typically, the training corpus is processed via the MATS platform, and the first text segment that is not fully parsed (marked by green) in the output is manually analysed; in particular, the chart of the segment is investigated, and the problems are taken care of. When an appropriate parse is generated, the text is pro-cessed again, and the translation is generated or there are shortcomings in the transfer or generation phases, and, if so, the results are inspected and the grammars are accord-ingly developed.
4.3.1. The Swedish grammar
the training, the variety of clause and phrase types that are covered by the grammar has increased, and the rules have been fine-tuned to the contexts in the training text.
Outside the current scope of the grammar are coordi-nated clauses, some types of infinitive clauses, some types of subjunctive clauses, and some types of valency rules. The extension of the set of valency rules has been in fo-cus of the scaling up effort in the project. The scaling up of the set of valency rules is based on the complete training corpus. Work on this issue is still in progress.
Verb valency Verb valency, i.e. the potential of the verb to participate in constructions with other members of the clause is a primary issue in scaling up the grammar. The analysis of a clause is based on access to a valency rule that is associated with the finite verb. If there is no such rule, the analysis of the clause will fail. In other words, completeness with regard to valency rules is decisive for the coverage of the grammar.
In MULTRA, valency rules are formulated in the pro-cedural UCP formalism and part of the grammar. They are referred to as verb action rules, VA-rules. VA-rules are de-fined in terms of grammatical relations, e.g.
defrule va.plundra {
(act, obj.dir /
pass, (agent // continue)) }
The rule in the example defines the standard transitive rule. It is named by a typical representative plundra [pil-lage]. The rule prescribes that in the active form (diathe-sis), the verb takes an obligatory direct object, while in the passive form, it takes an optional agent.
In the original version of MULTRA, the association be-tween a verb lexeme and its VA-rule is defined in the UCP lexeme base. In the industrial version, it will be provided by the lexical database (see 3.2.).
Verb valency appears to be domain dependent. Thus rather than consulting a standard Swedish dictionary, we decided to analyse the verbs in the MATS corpus with re-gard to valency relations. A total of 680 lemmas (including particle verbs), and 689 lexemes (distinctive senses) were identified (Thaning, 2001).
Prior to the analysis of the valency relations, each con-text was (manually) rewritten into a basic form, a declara-tive main clause in the acdeclara-tive form. The basic forms were investigated with regard to complements and adjuncts. A syntactic valency model was developed. According to this model, the valency of a verb is expressed by means of a syntactic frame and a set of semantic codes. The syntactic frame accounts for the complements of the verb, and the semantic codes for the adjuncts. For instance,NP NPis the syntactic frame for a standard transitive verb. Semantic codes were defined for adjuncts expressing means, degree,
measure, location, manner, time. A total of 105 different
frames were defined. More than a third of the verbs, how-ever, were analysed as standard transitive verbs, 64 were analysed as intransitive verbs, and 28 as transitive or in-transitive (e.g. bromsa [brake]. The remaining verbs are distributed over 102 different frames. 68 frames have only one representative each.
The syntactic valency frames along with the semantic codes will be stored in the lexical database (see 3.2.. Mean-while, links between the verb lexemes and the VA-rules are defined in the grammar. Currently, 354 such links have been established, implying that links are missing for 335 verb lexemes. Test runs with the current version of the grammar show that more than 25% of the parsing failures in the training corpus are due to valency problems.
Before the syntactic valency frames and the semantic codes can be used by the parser, they need to be reformu-lated in the UCP formalism, and grammatical relations cor-responding to the phrase categories have to be established. This work is in progress. As a matter of fact, a total of 113 VA-rules have been defined including the 33 rules in the original version of the grammar. However, the original rules are more fine-grained than the new rules. In particu-lar, they take into account not only complements but also adjuncts. In other words, two valency models have to be adjusted to each other. The old model will be adjusted to the new one, the primary reason being that the new model will be more transparent and facilitate future work on the lexical database.
4.3.2. The transfer grammar
The transfer grammar of the original version of MUL-TRA comprises 87 rules, versus 181 in the new version. The rules are of 6 basic types, see table 4.
Type Old New
Copy a structure 24 54
Delete a feature 4 19
Transfer a structure, no change 57 90 Transfer a structure, with a change 6 10
Transfer a structure, 1 9
Implying lexical disambiguation
Table 4: Rules in the transfer grammar.
A structure preserving transfer rule may include a shift of the value of an individual feature as well as the deletion of a source feature not required by the target language.
4.3.3. The generation grammar
The generation grammar has been scaled up from 100 rules to 166. The rules give a direct characterisation of the syntactic surface structure. So far, there is no provision for the inclusion of valency relations, or for the expression of optional or repeated constituents. Thus it is to be foreseen, that in the further development of the grammars, in tandem, the number of rules in the generation grammar will increase faster than in the analysis grammar.
5.
Preliminary Evaluation
5.1. System Performance
The system performance is measured in CPU seconds, counting both system calls and each program’s processing time. Total performance for the whole MATS corpus is 26 segments/second, or 137 words/second, on a AMD Duron 750MHz processor. Transfer and generation take most of the time, and will probably take even longer as more and more segments pass the analysis module (see Table 5).
Module CPU secs SGML extr. 2.67 Tokeniser 1.74 Lex. lookup 32.79
Parser 89.73
Transf.
& gen. 210.92 Code comp. 9.17 Lex. lookup 4.97
Finish 8.92
Table 5: Performance evaluation (CPU seconds).
5.2. Coverage
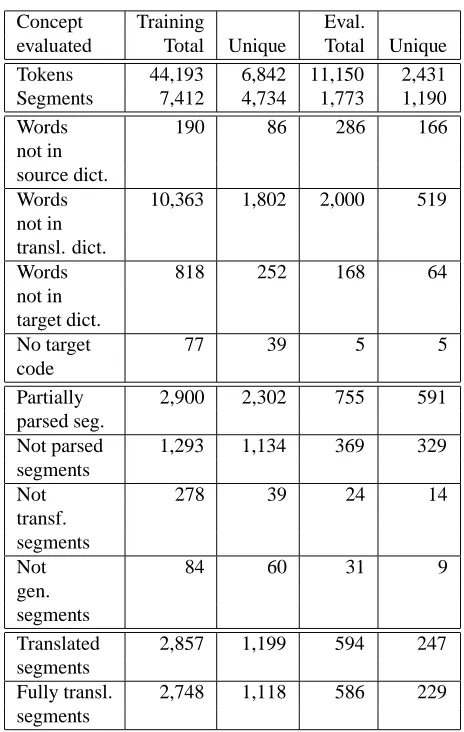
Given the modularity of the system, it is easy to perform a glassbox evaluation of each module’s contribution to the total recall, by simply adding an evaluation module at the end of the pipe. Such a module is currently under devel-opment, and preliminary results have been collected for the MATS corpus (see Tables 6 and 7).
These results are primarily aimed for developing pur-poses, as logfiles on missing words and grammar rules can be used as a basis for updating the dictionaries and gram-mars, but some of them can also be used for comparing the system to other systems.
In an ideal world, there should be no missing words in the Swedish dictionary, since all source documents are sup-posed to adhere to the controlled language (see 4.2.1.). In reality, however, this is not true, and we have to revise the source documents accordingly by running them through the checker. This has not been done for all documents yet.
The number of words reported missing from the trans-lation dictionary is rather large. However, as this number is measured before the disambiguation process in the anal-ysis module, many missing words actually correspond to rejected alternatives. The ideal place to measure this would be after the analysis, but as not all segments pass this mod-ule yet, the current place of measuring yields the best in-formation for development purposes. As it is now, words reported as missing from the English dictionary are mostly disambiguated words missing from the translation dictio-nary, as the analysis module copies the Swedish word if there is no default translation. The overall recall of the tar-get dictionary could instead be measured by reversing the translation dictionary, as described in 4.2.3..
The evaluation module distinguishes between partial parse and no parses for development purposes. Partial parses are caused by lacking coverage of the grammar, while no parses are caused by processing errors, e.g. by calls to non-existent rules.
Concept Training Eval.
evaluated Total Unique Total Unique Tokens 44,193 6,842 11,150 2,431 Segments 7,412 4,734 1,773 1,190
Words 190 86 286 166
not in source dict.
Words 10,363 1,802 2,000 519
not in transl. dict.
Words 818 252 168 64
not in target dict.
No target 77 39 5 5
code
Partially 2,900 2,302 755 591
parsed seg.
Not parsed 1,293 1,134 369 329
segments
Not 278 39 24 14
transf. segments
Not 84 60 31 9
gen. segments
Translated 2,857 1,199 594 247
segments
Fully transl. 2,748 1,118 586 229 segments
Table 6: Module evaluation.
Segments Training Evaluation
Total Unique Total Unique
Translated 38.5 25.3 33.5 20.8
Fully
translated 37.1 23.6 33.1 19.2
Table 7: System evaluation (% recall).
Segments passing the generation module are passed on in their translated form, possibly with markups of copies of Swedish words, English base forms of words with a faulty feature structure or code, or words missing inthe English dictionary. In the evaluation module, these are reported as translated segments. Segments passing all modules with no markups are reported as fully translated, and are included in the figure for translated segments.
The segments counted as translated are primarily the short simple ones (see 4.3.1.). This fact is not reflected in the results of the evaluation module yet, but a count of to-kens per segment will be added shortly, to measure recall also in the context of translated tokens.
6.
Conclusion
de-signed and implemented. The system translates automotive service literature from Swedish to English. Though no for-mal evaluation of the output quality has been made, manual inspection shows that the translations are of high quality and on a par with the manual translations used as evalua-tion standard.
The coverage of the lexical data is complete with regard to the automotive domain. The coverage of the grammars, however, is still limited. In spite of this, the system already translates more than a third of the segments in the corpus.
7.
On-going and future work
Continued evaluation of the system will be performed, with a special focus on the output quality and the develop-ment of an evaluation methodology. User support for the definition of grammar rules and lexical units for new do-mains and language pairs will be emphasised. Work on the grammars is in progress. Extending the system with a trans-lation memory represents another line of development. The translation memory should be built from scratch and based solely on translations generated by the system.
Discussions concerning a commercialisation of the sys-tem are in progress.
8.
Acknowledgements
The research reported herein was supported in part by VINNOVA (Swedish Agency for Innovation Systems), contract no. 341–2001–04917, Scania CV AB, and Expli-con AB.
9.
References
Lars Ahrenberg. 1984. De grammatiska beskrivningarna i SVE.UCP [the grammatical descriptions in SVE.UCP]. In S˚agvall Hein (S˚agvall Hein, 1984a), pages 1–13. Ingrid Almqvist and Anna S˚agvall Hein. 1996. Defining
ScaniaSwedish – a controlled language for truck main-tenance. In Proceedings of the 1st International
Work-shop on Controlled Language Applications (CLAW’96),
pages 159–164, Centre for Computational Linguistics, Katholieke Universiteit, Leuven.
Ingrid Almqvist and Anna S˚agvall Hein. 2000. A language checker of controlled language and its integration in a documentation and translation workflow. In
Proceed-ings of the Twenty-Second International Conference on Translating and the Computer, Translating and the
Com-puter 22, Aslib/IMI, London, November 16–17.
Bj¨orn Beskow. 1993. Unification-based transfer in ma-chine translation. Reports from the Department of Lin-guistics, RUUL #24, Uppsala University.
Bj¨orn Beskow, 1997a. Generation in MULTRA. Uppsala University. Department of Linguistics.
Bj¨orn Beskow, 1997b. Morphology in MULTRA. Uppsala University. Department of Linguistics.
Mats Dahll¨of. 1989. En lexikonorienterad parser f¨or sven-ska [A lexicon-oriented parser for Swedish]. Master’s thesis, Gothenburg University.
Eva Forsbom. 2002a. Scaling up the generation lexicon for Multra. Project report.
Eva Forsbom. 2002b. Scaling up the transfer lexicon for Multra. Project report.
Jan Hellstr¨om. 2001. Semantiska s¨ardrag f¨or substantiv i Multra [semantic features for nouns in Multra]. Project report.
Stina Karlsson and Sten Thaning. 2001. Automatisk generering av ordformer till Scania-databasen [Auto-matic generation of wordforms for the Scania database]. Project report.
Camilla L¨ofling. 2001. Att skapa ett lemmalexikon f¨or manuell och maskinell ¨overs¨attning [To create a lemma lexicon for manual and automatical translation]. Mas-ter’s thesis, Uppsala University.
L-J Olsson. 2002. Rendering of MATS SGML documents with XSL transformations. Working report.
Anna S˚agvall Hein. 1983. A parser for Swedish. status re-port for SVE.UCP, February. UCDL-R-83-1, Center for Computational Linguisics, Uppsala University.
Anna S˚agvall Hein, editor. 1984a. F ¨oredrag vid De nordiska datalingvistikdagarna 1983 [Talks at the Nordic computational linguistics’ days 1983],
UCDL-R-84-1, Center for Computational Linguisics, Uppsala University.
Anna S˚agvall Hein. 1984b. Regelaktivering i en parser f¨or svenska (SVE.UCP) [Rule-activation in a parser for Swedish (SVE.UCP)]. In S˚agvall Hein 1983 (S˚agvall Hein, 1984a), pages 187–199.
Anna S˚agvall Hein. 1994. Preferences and linguistic choices in the Multra machine translation system. In Robert Eklund, editor, Proceedings of ’9:e Nordiska
Datalingvistikdagarna’ (NODALIDA’93), pages 267–
276, Department of Linguistics. Stockholm University. Stockholm, June 3–5.
Anna S˚agvall Hein. 1997. Language control and machine translation. In Proceedings of the 7th International
Con-ference on Theoretical and Methodological Issues in Ma-chine Translation (TMI’97), St. John’s College, Santa Fe,
New Mexico, July 23–25.
Sten Thaning. 2001. Verbvalenser i teknisk text. En fallstudie. [Verb valency in technical texts. A case study]. Master’s thesis, Uppsala University. (http://stp.ling.uu.se/educa/thesis/arch/2001-010.pdf). J¨org Tiedemann. 1999. Word alignment - step by step. In
Proceedings of the 12th Nordic Conference on Computa-tional Linguisics (NODALIDA’99), University of
Trond-heim, Norway.
Per Weijnitz. 1999. Uppsala chart parser light. System documentation. In Anna S˚agvall Hein, editor,
Chart-Based Grammar Checking in SCARRIE, number 12 in
Working Papers in Computational Linguistics & Lan-guage Engineering. Uppsala University.