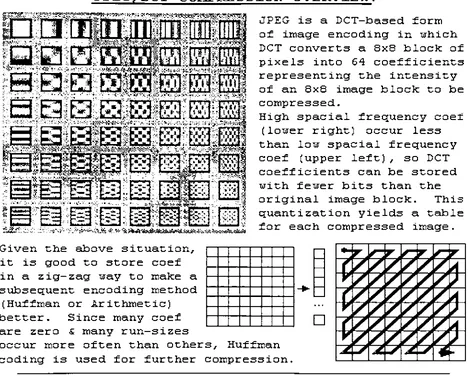
Rochester Institute of Technology
RIT Scholar Works
Theses
Thesis/Dissertation Collections
1999
Genetic algorithm and tabu search approaches to
quantization for DCT-based image compression
Michael Champion
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion
in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact
Recommended Citation
Rochester Institute of Technology
Computer Science Department
Genetic Algorithm and Tabu Search
A pproaches to Quantization
for DCT-based Image Compression
by Michael S. Champion
A thesis, submitted to
The Faculty of the Computer Science Department
in partial fulfillment of the requirements for the degree of
Master of Science in Computer Science
Approved by:
Dr. Roger Gaborski
Rochester Institute of Technology
Dr. Peter Anderson
Rochester Institute of Technology
Dr. Fereydoun Kazemian
Rochester Institute of Technology
Signed:
Rochester Institute of Technology
Computer Science Department
Genetic Algorithm and Tabu Search
Approaches to Quantization
for DCT-based Image Compression
I, Michael Champion, hereby grant permission to the
Wallace Library of the Rochester Institute of Technology
to reproduce my Thesis in whole or in part.
Any reproduction will not be for commercial use or profit.
Michael Champion
Masters
Thesis
(Winter
1998/1999)
GENETIC ALGORITHM
AND TABU SEARCH APPROACHES
TO
QUANTIZATION FOR
DCT-BASED
IMAGE
COMPRESSION
Michael
S. Champion (e-mail:
Rochester Institute
ofTechnology
January
28,
1999
1
Abstract
Today
thereare severalformal
and experimental methodsfor
image compression,
some of whichhave
grownto
be
incorporated into
theJoint
Photographers Experts
Group
(JPEG)
standard.Of
course, many
compressionalgorithms are still used
only
for
experimentationmainly
due
to
variousperformanceissues.
Lack
of speed whilecompressing
orexpanding
animage,
poor compressionrate,
and poorimage
quality
after expansion are afew
ofthemost popular reasons
for
skepticism about a particular compression algorithm.This
paperdiscusses
current methods usedfor
image
compression.It
also gives adetailed
explanation ofthe
discrete
cosinetransform(DCT),
usedby JPEG,
and the effortsthathave
recently
been
madeto
optimizerelatedalgorithms.
Some
interesting
articlesregarding
possible compressionenhancements willbe
noted,
andin
association withthese methodsa new
implementation
of aJPEG-like image coding
algorithm willbe
outlined.This
newtechniqueinvolves adapting
between
one and sixteen quantizationtables
for
a specificimage using
eitherKohonen self-organizing
map
(SOM)
algorithms willbe
examinedto
find
their
effectiveness atclassifying blocks
of edge-detected
image
data.
Next,
the
GA
andTS
algorithms willbe
tested to
determine
theireffectiveness atfinding
the
optimum quantizationtable(s)
for
a wholeimage.
A
comparison ofthetechniques
utilized willbe
thoroughly
explored.2
Acknowledgments
I
wouldlike
to thankDavid
Foos,
Lori
Barski,
Dr.
Susan
Young,
andDr.
Roger
Gaborski
ofEastman
Kodak's
Health
Imaging
Research
Labs
(HIRL)
for sharing
theirknowledge
ofimage
compression andimage
understanding.
Dr.
Gaborski
also providedinsights concerning
theKohonen SOM
and edge-detectionalgorithms,
in
additionto supplying
currentliterature
aboutthese subjects.I
wouldalsolike
to thankDr. Peter
Anderson
ofthe
Rochester Institute
ofTechnology
(RIT)
Department
ofComputer Science for
accesstohis
generic genetic3
Table
of
Contents
0.0
Title
Page
andApprovals
1.0
Abstract
2.0
Acknowledgments
3.0
Table
ofContents
4.0
Introduction
andBackground
4.1
Problem Statement
-an expl-anation of
DCT
versusDWT,
DCT's
relationtoJPEG,
andtheusageof
GA, TS,
Kohonen
SOM,
and pixel neighborhoodtechniques4.2
Previous Work
-a
descriptive
listing
ofmany
relatedarticles4.3
Theoretical
andConceptual Development
-a
description
of optimization and classification methods4.4
Glossary
-a
brief
listing
of relatedterms5.0
Implementation
5.1
Functional Description
-functions
performed,limitations
and restrictions, userinputs
andoutputs,
and systemfiles
generated5.2
System
Design
-system organization and
data flow
chart,
equipmentconfiguration,
andimplementation tools
used5.3
Decisions
andTradeoffs
-some
brief design
and usagelimitations
5.4
Experimentation
-verificationand validation
(testing
anddebugging)
procedures used6.0
Analysis
6.1
Results
andConclusions
-analysis of results and conclusions
based
onthem6.2
Problems
andDiscrepancies
-resolvedand unresolved shortcomings ofthe system
6.3
Lessons Learned
-alternatives
for
animproved
system and possiblefuture
work4
Introduction
and
Background
Currently
there
aremany
waysin
whichimages
canbe
compressedfor leaner
storage orfaster data
transmission,
andthey
all canbe defined
in
one oftwoclasses:lossless
andlossy.
Lossless
methodsare abletorestorethe
data
identical to the original, normally
at the expense ofa worse rate of compression.However, lossy
techniques compromise
quality
for
alower
transmissionrateby
quantizing
to minimizeirrelevant information. This
method
is
considereddesirable
if
thedecrease
in
compressed sizeis relatively larger
than the amount ofloss in
quality.
Transform coding is usually
usedtominimize output values ofthe transformationused(e.g.
DCT),
anda
lossy
coding
compressionstrategy exploiting
this traitis
often usedbecause
all natural measurements containsome sort of noise
([COMP97]). There
aremany
examplesofboth lossless
andlossy
types
ofimage coding, many
of which
have
been
usedin
nearly-lossless algorithms(see Appendix
A,
Figures
2
and3).
Most
ofthefocus
ofthis paper concerns theJPEG
image
compression algorithm.In
JPEG,
theimage
is
initially
transformedfrom
red-green-blue(RGB)
to video-basedencoding in
order to separatethe greyscaleimage
(luminance)
from
the colorinformation
(chrominance).
Each
portionis
compactedseparately
because
it is
possible tolose
more colorthan greyscaleduring
compression.Next,
subregions are processed withDCT
using
real number values,but based
upon the complex numbers ofthe
Fast Fourier Transform (FFT).
Finally,
additional compression
is
done
by
truncating
the precision ofterms
andusing
acoding
scheme that avoidsrepetition of characters
(see Appendix
A,
Figure
4).
DCT
fits
in
well with thedesire
to
performforward
and reverse transforms
quickly
with minimalloss
ofimage
quality.It
can encodeimage information
that canbe
reconstructed within an arithmetic precision ofthe
computer.This
precisionis generally better
than theprecisionof an original
image
sensoror analog-to-digital converter.However,
thehuman
eye uses greyscale edgesto
detect
boundaries,
allowing
colors tobleed
acrossthese
boundaries
without confusion.JPEG
shouldtake
more
into
account these edgefactors
throughthe
implementation
of edge-specific quantization matrices whichcould
be
classifiedusing
a method such astheKohonen self-organizing
map
(SOM)
algorithm orConnected Pixel
4.1
Problem Statement
This
purpose ofthispaperis to
describe
a new adaptive compression processwhereby
multiplequantizationtables are used to code an
image.
Quantization
is the step
which allows a continuous amplitudeanalog
signalto
be
placedin the
discrete
amplitude representation ofadigital
computer.The
classification ofdifferent
typesof quantizationtables are attempted
using
aKohonen
SOM,
and thencompared withtwo
simpler techniques.In
the case oftheKohonen
SOM,
edge-detectedblocks
ofthe image
arefed
astraining
vectorsinto
the neuralnetwork until convergence on a set of weights
is
achieved.The
easier methodssimply
usethe
edge-detecteddata
alone orthey try
to perimeterize the edgesusing
connected pixel neighborhoods.Once
the
classificationis complete, both
theGA
andTS
algorithms are compared asthey
eachtry
tofind
the optimum quantizationtable
for
the different
types of classifiedblocks.
The DCT is
used to transform eachblock
withits
assignedquantization
table
during
this
testing
period.An
evaluation ofthis
entire processis
exploredin
detail based
onits
applicationto
severaldifferent
images
and someimages
ofthe
same type.The
results shouldindicate
thatthemethods
just
described
providea meanstoeffectively
assistJPEG
image
compression.The
problem withenhancing image
compressionobviously
lies
in
thefact
that there aremany different
formats
whichstill could use some optimization.Many
ofthe methodsshownin
Figures
2
and3
ofAppendix A
are
complex,
but
withenough researcheach ofthemstandthe
chance ofbeing
improved using
an abundance ofoptimization techniques.
Relatively
simplelossy
compressionalgorithms,
like DCT
andDWT (discrete
wavelettransform),
arelinear
operationsgenerating
adata
structurethat
has log2N
segments of variouslengths,
whereN
is
thelength
ofone side of animage.
Usually
the algorithmfills
the structure and transformsit
into
achanged
data
vector 2^in length. Both
transforms arerelatively easy
tocode,
andthey
canbe
viewedsimply
as a rotation to a
different
domain in
function
space.For DCT
the
domain
is
madeup
only
of cosine(or sine)
functions,
andfor
DWT
thebasis functions
are more complex ones calledwavelets([GRAP95]).
Analyzing
(or
mother)
waveletfunctions have
their
frequencies localized
in
space so thatfunctions
andoperators
using
them willbe
"sparse"
when
transformed
into
the waveletdomain.
This
sparseness aidsfeature
given wavelet systemto
be
adaptedfor
a givenproblem.They
also processdata
atdifferent
scales ofresolution.The
fast
DWT,
like
the FFT
usedfor
DCT,
is
capableoffactoring
its
transforminto
a product offew
sparsematrices
by
using self-similarity
properties.Wavelet
packets,orlinear
combinations ofwavelets,
are computedby
a recursive algorithm which makes each new packettheroot of an analysistree
(see Appendix
A,
Figure
5).
This
tree
is
usedto
retainorthogonality, smoothness,
andlocalization
propertiesof parent wavelets.Adaptive
waveletsare used
by
researchers tofind
abasis for
measuring
rates ofdecrease
orincrease in
coefficients([GRAP95]).
DWT has
many
usesin
computer andhuman
vision analysis,FBI
fingerprint
compression,
"denoising"
noisy
data, detecting
self-similarbehavior
in
a time-series ofimages,
and even musical tone generation.In
adaptivequantization with waveletsthere are
two
popular methods:(1)
fixed
quantizationfor
all coefficientsin
a givenband
using
layered
transmission of coefficientsin
binary
(low)
order arithmeticcoding,
and(2)
using
different
quantizers and
entropy
codersfor different
regions of each subband.In
particular a context-based adaptivearithmetic coder
operating in
the subbanddomain has been
explored.Unlike
theimage domain
the contextsare
based
upon past quantizeddata,
not the originalimage data. Results
from
this novelalgorithmindicate it
performs as well as
existing DWT
methods without the useoftrees([CHRI96]).
DCT
functions,
on the otherhand,
do
not possesslocalization
offrequencies. The
DCT takes
advantageof the
large
amount ofredundancy in images
and thefact
that
there are constant-variance contoursin the
cosine transform over typical
image
sets.Usually
a zonalcoding
strategy is
sufficientto
use these traitsin
ordertoassign a number of quantization
levels based
onthe
variance ofthe
coefficient([EMBR91]). The JPEG
algorithm
is significantly based
onDCT,
and unlikeDWT it
has been
abletobe
implemented in both
hardware
and
software, yielding
compression ratios of over50:1.
DCT
is
also afairly
simple algorithm toprogram sinceit
is
based
ononly
twodimensional
FFT
cosinefunctions (see Appendix
A,
Figure
6).
So
althoughDWT
usesa variable
kernel
(window)
size andinfinite
sets of possible shorthigh-frequency
andlong low-frequency
basis
functions
(some
evenhaving
fractal
structure), DCT
willbe
usedfor
experimentationin this
paper.It
shouldbe
noted that there areWavelab
andMatlab
utilities availablefrom Stanford
University,
but
theprogramming
presented
in this
paperis predominantly
original codedesigned
by
the
author.This
wasnecessary
from both
aHowever,
the programming
wasnoticeably
patterned afterformal
types of signalprocessing
algorithms(e.g.
edge-detection)
as well asthe
DCT
andbit-packing
portionsofthe
JPEG
image
compression algorithm.4.2
Previous
Work
Moderate
amounts of workhave been done
in
researchtodesign
image-adaptive
quantizationtables,
especially in the
field
of medicalimaging
whereimage quality is
paramount(see Appendix
A,
Figures 10
and11).
In
an article
by
Good,
JPEG
is
saidtohave
difficulty
in
being
appliedtoradiographicimages
because
the standarddoes
notspecify
a certain quantization table.This
quantization tableis
a major part of whatdetermines
thecompression ratio and
quality degradation
of compressedimages.
Usually
psychovisual considerations are usedin
thisfield.
However,
these methods aredependent
upondisplay
characteristics andviewing conditions,
sothese considerations
may
notbe
optimal.This
article reveals two methodsfor
improving
the currentJPEG
algorithm:
(1)
removing
frequency
coefficients wheremany
bits
are expected tobe
saved,
and(2)
preprocessing
the
image
with a non-linearfilter
usedtomaketheimage
more compressible.Optimally,
theresults shouldbe
robust enough so
that
they
arequalitatively independent
of a specificimage
or quantizationtable
([GOOD92]).
That
is,
the
quantization table shouldhave
theability to
be
used ondifferent
images
ofthe sametype
suchas chest or cervical radiographic
images
([BERM93]). The
author's conclusions were thatissues
related to theuse ofthe
JPEG
standard should notbe
confinedexclusively
to quantization tables.Subjective
differences
aremore
important
on softdisplays
than onfilm,
and eventhe
MSE
measurementdoes
not always correlategreatly
with the visual evaluation of
images
by
human
observers([GOOD92]). Other
methodsmay
be better
suited toimitate
such subjective classifications.Another
such paper, writtenby Fung
andParker,
presents an algorithm to generate a quantizationtable
that
is
optimizedfor
a givenimage
anddistortion. The
most popular current practicein
JPEG
is to
scale thetable according to
ascaling curve,
but
this methodis
not optimalbecause
the
bit
rate anddistortion
ratearenot
both
minimized.In
theory,
the
optimal quantizationtable
canbe determined
with an exhaustive searchover
the
set of possible quantization tables.With
valuesfalling
between
1
and255,
there is
no single uniformsearch over all possible values
is impractical.
The
algorithm presentedby
these
authors starts with aninitial
quantization
table
ofvery
coarsequantizers,
then thestep
sizes ofthe
quantizers aredecreased
one at atimeuntil a given
bit
rateis
reached.At
eachiteration the
element ofthe quantizationtable to
be
updatedis
varieddepending
on whether a coarser orfiner
quantizationtableis
neededto
achievethe
targetdistortion
value.The
resulting
algorithmhas
a poor computational complexityuntil anentropy
estimatoris
usedtoestimatethebit
rate and
further
reducethe
complexity.Convergence
is
achieved whentwo
points oscillatefrom
oneto
anotheras
downslope
and upslopebecome
about the same.A
mean-squared quantization error(MSQE)
is
usedfor
a
distortion
measurebecause
it swiftly
calculatesit
from
unquantized anddequantized DCT
coefficients andbecause MSE
is
morecomputationally
expensive.Also,
it
canbe
weighedby
theHuman Visual System
(HVS)
response
function
withoutcomplication sothat the weightedMSQE
correspondstoperceptual quality.The
bit
rate estimate was measured
using the entropy
of quantized values withoutactually going
through theentropy
coding.
The
results showedthatthe
optimizedimage-adaptive
quantizationtableyieldsa14%
to
20%
reductionin
bit
rate comparedto
algorithms which use standard scaled quantization tables.Once
an optimizedtable
is
made
for
a givenimage,
it
canthenbe
appliedto
similarimages
withonly
a smallincrease in
bit
rate.That
is,
the
algorithm needstobe
runonly
oncefor
a given set of similarimages
([FUNG95]).
There have
been very
few
attempts atusing
GA-type heuristics
to
solve the problem of adaptive quantization
for
image
compression.But in
an articleby
Kil
andOh,
they
outline vector quantizationbased
on agenetic algorithm.
Vector
quantization(VQ),
although notspecifically
relatedto
image coding, is
themapping
of a sequence of continuous or
discrete
vectors(signals)
into
adigital
sequence.The
goalofVQ
is to
minimizecommunication channel
capacity
or storage needs whilemaintaining
thefidelity
ofthedata. In this
particularexample,
the authorstry
to
find
the optimal centroids which minimize the chosen costfunction
by
iterating
throughthe
selection,
crossover, mutation,
and evaluation operations associated with atypicalGA. LBG
(Linde,
Buzo,
Gray)
andLVQ
(learning
vectorquantization)
are algorithms used as update rulesfor
the centroids,
whichare represented as
64
bit
(8x8)
chromosomes.Each
centroid(i.e.
vector) is
initially
evaluatedaccording to
the error
function,
then selectionis
performedbased
on a certain probability.Next,
a recombination called abased
on a certain probability.Finally,
centroids are"fine-tuned"
using
anLVQ
update rule.The
ultimatesimulation contained
3
sets ofdata
generatedfrom
Gaussian, Laplacian,
andGamma
probabilities.A
total of10000
training
samples were created over100
generations, and a population size of20
chromosomeswas used.The
crossover and mutation probabilities were0.25
and0.01,
respectively.LVQ
was appliedto
chromosomeswith or without
the
GA
applied.Results
indicated
thatit is very
effectiveto quantizeimage
data
compared toLVQ
alonebecause
the
computationalcomplexity is
reduced([KIL096]).
In
other articlesit
has been
shownthat theKohonen self-organizing map
(SOM),
whichis strongly
relatedto
LVQ,
canbe
usedin
severaldifferent
waysfor image
compression.One
such articleby
Yapo
andEmbrechts
discusses
the use ofaKohonen self-organizing
feature
map
(SOFM)
to make a codebookfor
coding
animage
upon which the
SOFM
was trained.This
type
of neural vector quantizationhas
three
phasesincluding
the
design
ofthe
codebookusing
best
matchedblocks
createdby
theSOFM,
the
compression ofthe codebookusing
a
lossless
method, andthe coding
ofthe
image
by
finding
the
closest codebookblock
for
eachimage block in
O(N)
or0{logN)
time.The image
reconstructionis
done in
reverseorder,
and mean-squared error(MSE)
andsignal-to-noise ratio
(SNR)
are usedfor
comparisons.The
resultsofapplying the
SOFM
toVQ
arepromising
because
the codebooks produced canaccurately
quantizeimages
for
whichthey
aretrained
andthe resulting
codebooks can
be
compressed.However,
more researchis
still required todetermine
if this
use of aSOFM
is
worthwhile
([YAP
096]).
An
articleby
Xuan
andAdah
builds
onthe
ideas
ofYapo
andEmbrechts
by
introducing
aLearning
Tree
Structured
Vector
Quantization
(LTSVQ)
codebookdesign. The SOFM
provedtohave
good performance compared
to
theLBG
(Linde,
Buzo,
Gray)
algorithm,
but
it is
limited
tosmall vectordimensions
and codebook sizesfor
most practical problems.The
LTSVQ
codebookdesign
scheme uses a competitivelearning
(CL)
algorithmto
make aninitial
codebook.Then it
partitionsthe
training
setinto
subsets which are usedto design
a newcodebook.
The
resultsshowed that the algorithmhad
good performance withlow
computational complexity.In
another related articleby Anguita, Passaggio,
andZunino
aSOM-based
interpolation
schemeis
createdsample,
andits
main advantageis that
prototypes are expressedin
the sameform
anddomain
asthe
processeddata.
However, VQ
does
attainhigh
compression ratios atthe
expense oflower
visual quality.The
"multi-best"algorithm presented usesthe
interpolation
processinstead
ofVQ
schemesto correctly
reconstructthe unknownpatterns not
in the
codebook.Thus,
the
codebookis
more well-defined and yields abetter
reconstruction ofdetails. The
systemis
also sensitiveto the
training
setadopted,
andit
uses morethan one reference vectorto
code an
image block.
The
algorithmis
appliedto
alarge
set of naturalimages allowing
reliable evaluations.The
experimentation, using
aKohonen SOM
with256
neurons,showedthatassociated generalization propertiesgreatly
compensatesfor less
compression.The details
are reconstructedbetter
andthe edges are more accurate.These
results were reinforcedusing
analytical(i.e.
MSE)
and qualitativemeasures.Compared
to
VQ
and otherDCT-based
methods, this technique is
suitablefor very high
compression ratios([ANGU95]).
All
ofthe preceding
resources were used asinspiration
for
the new methodfor
solving
the problem ofmaking
a set of edge-adaptive quantization tables presentedin
this paper.Many
different
evaluation schemesutilizing
bits
per pixel(BPP)
and peak signal-to-noise ratio(PSNR)
are examined.The details
ofthe
GA,
TS,
and
image block
classification algorithms used still requiresome explaining.4.3
Theoretical
andConceptual Development
Several
researchersincluding
David
Goldberg, Philip Segrest,
Lawrence
Davis,
Jose
Principe,
Michael
Vose,
Gunar
Liepins,
andAllen
Nix
have
created mathematical models of simple genetic algorithms which capture allassociated
details
in
the mathematicaloperators utilized.Mitchell
outlinesthe
formal
modeldeveloped
by
Vose
and
Liepins
concisely.First,
start with a simple random population ofbinary
stringshaving
length
/.
Then
calculatethe
fitness
f(x)
of eachstring
xin the
population.Next,
using
replacement, selecttwo
parentsfrom
the current population with a
probability
thatis
proportional to each string's relativefitness
in
the overallpopulation.
Then
crossover the two parents at a single random point with a certainprobability
toform
two
offspring.
If
no crossover occursthe offspring
are exact copies ofthe
parents.Finally,
mutate eachbit
in the
chosen
offspring(s)
with anotherprobability, and place one(or
both)
in the
new population.Normally
only
oneofthese childrensurviveand
the
otheris
discarded for
the
nextgeneration,
but
simple geneticalgorithmsallowboth
to
live
(^ffTC97]). This
selection, crossover,
and mutation process continues until theglobally
optimumsolution
is
achieved orthe upperbound
oniterations
is
reached.Although
thereis
no rigorous answer to when a genetic algorithm(GA)
yields a good answerto a givenproblem, many
researchers share theintuition
that aGA has
a goodif
notbetter
chance atquickly
finding
asufficient solutionthan other weaker methods
if
the environmentis
right.That
is,
if
the search spaceis
large,
not well
understood,
notperfectly smooth,
has
a single smoothhill
(unimodal),
has
anoisy
fitness
function,
andthe task
does
not need aglobally
optimumsolution,
then aGA
may
be
a good algorithmto use(see
Appendix
A.
Figure
8).
This is especially
the case when alternative methodshave
nodomain-specific knowledge
in
theirsearch procedure.
The coding
of candidate solutionsis generally
centraltothesuccess of aGA
([MITC97]).
Another
heuristic
called tabu search(TS)
wasdeveloped
by
Fred
Glover
as astrategy
to overcometheproblemof
finding
only local
optima as a solutionfor mainly
combinatorial optimization problems([HOUC96]).
Instead
ofonly accepting
solutionsleading
tobetter
costvalues,thissearch methodexaminesthewhole neighborhood
of a current solutiontotake thebest
one asthenext move evenif
thecost value gets worse.Optimization
is usually
performedby
aniterative
"greedy"
component as a modified
local
search tobias
the searchtowardpoints with
low
function
values, whileusing
prohibition strategiesto avoid cycles([TOTE95]).
It is different
from
thetraditionalhill
climbing local
searchtechniquesin
the sensethatit
does
notbecome
trappedatlocally
optimal solutions.
That
is.
it
allows moves out of a current solution which makesthe objectivefunction
worsein
hopes
thatit
willeventually
find
abetter
solution([HURL97]).
Generally,
aTS
requires certain specificationsin
orderfor
it
to work properly.First,
it
needs aconfig
uration which
is
the usage of a solution as an assignment ofvalues to variablesin
an admissible search space(sometimes
calleda"search
trajectory").Second,
it
needs a move whichis
theprocessofgenerating,
from
alocal
neighborhood, a
feasible
solutionto the combinatorial problemthatis
relatedtothe current solution.Third,
it
requiresa set
of
candidate movesout ofthecurrentconfigurationbased
on a costfunction. If
thissetis
toolarge,
a subset ofthis set willsuffice.
Fourth,
it
shouldhave
specifictabu
restrictionsas conditionsimposed
on moveswhichmake some
forbidden for
a certain "prohibition period."This
period canbe
representedby
atabusize ofiterations,
andit may
be
dynamically
adjusted tohandle
cycles.This includes
atabu
list
of a certain sizethat
records
forbidden
moves.Fifth,
it
should alsohave
aspirational criteria as rules which regulatediversification
and allowthe override of a given
tabu
restriction(see
Appendix
A,
Figure
8).
Tabu
search canbeen
usedfor
optimizationin
manufacturing,planning,
scheduling,
telecommunications,
structures and
graphs,
constraintsatisfaction,
financial
analysis, routing
and networkdesign,
transportation,
neural
networks,
and parallelcomputing among
others([GLOV97]). Although
therehave been
no citings ofTS
being
usedfor image
processing, this thesis
attempts to useit
as an alternative to theGA
methodpreviously
described.
For
classificationpurposes,
a simpleKohonen SOM
operatesin
such away that
theresulting
neighborhoodis
set so thatonly
one cluster updatesits
weights at eachstep,
andonly
a certainlow
number of clustersare selected
(see Appendix
A,
Figure
7).
The
learning
rateis slowly
(and
linearly)
decreased
as afunction
oftime while the radius ofthe neighborhood around a cluster unit
decreases
as theclustering
process progresses.The formation
of amap
occursin
two phasesby initially
forming
the correct order andthenhaving
thefinal
convergence.
The
second phase takeslonger
thanthe
first
as thelearning
ratedrops,
and theinitial
weightsmay
be
random.Some
applications of theKohonen
SOM
include
computer-generatedmusic,
thetraveling
salesman
problem,
and character recognitionamong many
otherslike
the
ones mentionedin
thearticlespreviously
presented.
Other
classification strategies specifictoedge-detectedimages include
skeletonization and perimeterization.Skeletonization is the
process ofstripping away
the exterior pixels of an edge pattern withouteffecting the
pattern'sgeneralshape
([AZAR97]).
Perimeterization
achieves a similar resultby
using
theconnected neighborhoodof adjacent pixels
for
each edge pixelin
order tostrip away the interior
ofedgesfound
by
the
edge-detectionalgorithm
(see Appendix
A,
Figure
7).
A
generalization ofthis
perimeterdetermination,
based
onthe
relativepercentage of edge area
found
perimage
block,
is
used as a simple substitutefor
theKohonen
SOM
classificationscheme.
4.4
Glossary
BPP
-bits
per pixelDCT
-discrete
cosinetransformGA
-genetic algorithm
JPEG
-Joint Photographers Experts
Group
MSE
-mean-squared error
RMS
-rootmean-squared error
SOM
-self-organizing map
PSNR
-peak signal-to-noise ratio
TS
-tabusearch
5
Implementation
The
generalstatement oftheproblem given earlieronly
gives acursory
viewof whatis
tobe done for
thisthesis.
The
following
subsections elaborate more on whatexactly
theprogramdoes
(see Appendix
B,
Figure
1).
The
userandtechnicaldocumentation
ofAppendix
C
gives additionalinformation
aboutthedevelopment
oftheprogram.
5.1
Functional Description
The
mainfunction
takes as argumentsfrom
the commandline
thoseparameters whichare requiredby
thegacompress,
tscompress,
and classifyimage routines.The
commandline
is
fairly
rigidin
format
with argumentsat specific
locations,
andtherearemany
specializedfunctions for
thisapplication.The GA
andTS
algorithms axeconfinedtothegacompressandtscompress
functions,
respectively.Each
ofthesefunctions
receives as parametersthe number of
bits
per pixel,kernel size, image rows,
image
columns,
number of quantization matricesused,
maximum
iterations allowed, input
filename,
outputfilename,
andthe compressedimage
filename.
However,
the
GA has
tournament size,
populationsize,
crossovertype,
crossover probability, andmutationprobability asadditional
inputs
whereastheTS
only
has
tabusize astheextrainput.
These
twofunctions
are subdividedinto
routines
defining
thedifferent
main operations thateach performinitially
anditeratively.
Before entering
either ofthesemajor routinestheimage
mustbe
classifiedinto
a given number of quantizationmatrixtypes
by
calling
the classifyimagefunction. This function
takesas argumentsthenumberofbits
perpixel,
kernel
size, image
rows,image columns,
numberofquantizationmatricesused,input
file,
outputfile,
andthe
Kohonen SOM
inputs consisting
of maximumclusters, initial
radius, maximumiterations,
threshold value,learning
rate,
and adjustment rate.Since
theKohonen
networkhas
been
disabled
only
the maximum clustersparameter
is
usedfor
the simple relative edginessform
of classification mentioned earlier.These
classificationparameters are
fed
into
the claskohonen routine aslabeling
of eachblock
ofimage
data
proceeds.The
compressimage and expandimage routines eachtakeas parameters thenumber ofbits
perpixel, kernel
size, image
rows,image columns,
number of quantizationmatrices,input
file,
andoutputfile. These functions
controlthecompression and expansion ofthe
images,
asdictated
by
the gacompressandtscompress
routinesby
iteratively
calling packing
andDCT
functions for
eachimage block.
The
associated packrecfunction
takes asinput
thenumber ofbits
perpixel,
kernel
size,
quantization matrixindex,
andthepackedand unpackedbuffers.
This
function
uses packbitsfor
packing
andunpacking
bits
within ablock
(record),
using
thestoragebits based
on the assigned quantizationtable
instead
ofthekernel
size.Scaling
theDC
coefficient,
as well asapplying
thezig-zag
patternofblock
coding, is
controlledin
thepackrecfunction. Note
that thequantization matrix valuesfor
eachkernel
member of eachimage
block
is
usedtomultiply
thecorresponding
packedblock
kernel
memberuponretrievaland
divide
theunpackedblock
kernel
member upon storage(see
Appendix X
for
DCT
dissection).
The
global matrices usedby
theprogram mustbe
createdby
separatefunctions.
The
makerefbitsfunction
simply
storesthepossible powers of2
being
used,
andit only
takes thenumber ofbits
perpixel as a parameter.The
makestorematrixroutine makes the storage matrix(how
many
bits
to storein
eachblock)
based
on theparameter
input
ofbits
perpixel,
kernel
size,
andthe
specificquantizationtableindex.
The
makecosinematricesfunction
makesboth
forward
andinverse
DCT
matrixkernels
by
taking
thekernel
size asinput.
All
associated matrix operationshave
their ownseparatefunctions
withinthe
program.The
matrixinsertfunction
allowsinsertion
andextraction ofshort-integerimage
block data
to andfrom
theimage
data
matrix,and
it takes
as parametersthe
number ofbits
perpixel,kernel
size, image
rowoffset, image
columnoffset, image
rows,
image columns, image
data
matrix,
and theblock
data
matrix.The
matrixconvert routine converts afloating-point
matrix to a short-integer matrix(and
vice versa), andit
takes asinput
thebits
per pixel,kernel
rows,
kernel columns,
thefloating-point
matrix,
and the short-integer matrix.The
matrixmultiply function
simply
multiplies twofloating-point
matrices,
andit
takes as parameters the rowsand columns of eachimage
block
as well astheinput
and outputbuffers.
The
matrixtransposefunction
transposesa givenmatrix,
based
onits
rows andcolumns, using input
and outputbuffers.
The
matrixshowroutineis only
usedfor
matrixdisplay
debugging,
andit
takes asinput
the rows,columns,
andbuffer
oftheimage block
being
handled.
The
function
edgedetect performs edge-detection onimage
data
to produce anedge-only
representation,and
it
takes asinput
thebits
perpixel, image
rows,image columns, image
data
buffer,
edgedata
buffer,
and athresholdvalue
for
determining
whatresulting
code values correspondto
anedge.A Gaussian blur
is
done
on9
byte
(3x3)
blocks
ofimage
data
followed
by
twodimensional
convolutions withSobel
orLaplacian filter
kernels,
thenthethreshold
is
applied.The
associated convolve2dfunction
takesasinput
thekernel
rows,kernel columns,
filter
matrix,input
matrixblock,
and output matrixblock.
There
areonly
twofunctions
responsiblefor file
input
and output.The
accessimagefunction
takes aflag
for
compressed or uncompresseddata,
bits
perpixel,
kernel
size, image
rows,image columns,
filename,
andimage
data
matrixin
orderto perform the appropriate read or write operation.It
usesthe testaccessbyte routine toload
or unload onebyte
at atime associated withtheimage data
matrix,
andit
takes as parameters aflag
for
writing
orreading
data,
thebyte
toaccess,
thecurrentbit
valuetoaccess,
thecurrentbit count,
andthepointertothe
file
structurebeing
usedfor
access.There
are alsovariousmiscellaneous andimportant
supplementary functions.
The
dct2d
function
usesthematrixmultiply routine to perform the
discrete
cosinetransform
on animage
block (i.e.
in two
dimensions),
and
it
takes as argumentsthenumberofbits
perpixel,
block
rows, block
columns, andtheshort-integer matrixbuffer. The
evalimages routineevaluatesanimage
tofind
BPP, MSE, RMS, PSNR,
andthe cost ratio(RAT). Its
arguments aretheoutput values
for
these
calculationsas well askernel
size, image rows, image
columns,numberof quantization
matrices,
test matrixbuffer,
and reference matrixbuffer.
The
getrandomintfunction
gets arandom
integer
withinthe
range entered asparameters.The
getrandomfltfunction
gets a randomfloating-point
number
between 0
and1.
In
addition,
the randomize routine should always proceed either ofthese twofunctions
in
ordertoinitialize
the random number generatorbased
on a random number seed.5.2
System Design
There
are8
different
modulesfor
thisapplication.The
quanmainmodule containsthe main routineas wellas a subordinate
testtest function.
Since
classification comesfirst,
the quanclas modulecontaining
theclassify-image
and claskohonenfunctions
is
nextin
thehierarchy. The
affiliated quanedge modulecontainsthe edgedetectand convolve2d
functions
that are usedfor
edge-detection.The
gacompress andtscompress routines,
aswellastheir component
functions,
arelocated
in
thequanadap
module.Next
is
the quanpack modulecontaining
thecompressimage and expandimage
functions
in
additionto thepackrec and packbitshelper
routines.The
order ofthe other modules
is
somewhathazy
since theirusageis intermixed.
The
quanmake module contains themak-erefbits, makestorematrix, and makecosinematrices
functions
mentioned earlier.The
quanmatr module containsall practical matrix operations
including
thematrixinsert, matrixconvert, matrixmultiply, matrixtranspose,
andmatrixshow
functions.
Finally,
thequanmisc modulecontainstheaccessimage,
testaccessbyte,
dct2d,
evalimages,
getrandomint, getrandomflt, and randomize routines responsible
for
theremainder ofthe mathematics andfile
transactions.
The
flow
ofdata between
thesefunctions
and modulesis
shownin
Figure
1
ofAppendix B.
The
equipmentconfigurationconsists of
any
SUN
Workstation running
under version2.6
ofSolaris (i.e.
in
aUNIX
environment).In
addition, animplementation
tool(e.g. osiris)
is
requiredfor
psychovisualtesting
in
orderto supplement theobjective evaluation
using
thecostfunction
givenin
Figure
9
ofAppendix
A.
5.3
Decisions
andTradeoffs
This
quanmain programis
not capable ofprocessing
anything
other than8
bit
images
that are256
rowsby
256
columnsin
dimension.
Also,
for
quantizationtheprogramonly
accepts an8 byte
kernel
size and1,
2, 4,
8,
or16 for
the number of quantization matrices.All
otherdirections
givenin
Figure
2
ofAppendix
B
shouldbe
followed
explicitly.These limitations
madetheprogrameasierto code such thatmorefocus
was abletobe
placed on the taskof
finding
an optimum set of quantizationtablesfor
animage.
The
entire project couldhave been better
outlinedusing
an object-oriented(00)
softwareengineering ap
proach, ultimately resulting in
the codebeing
writtenin
an00 language (e.g.
C++).
However,
thefunctional
design
ofthecode, along
withthedescriptive
comments,
allowsfor
aneasy understanding
abouthow
all ofthecomponents ofthe thesisproject
fit
together.5.4
Experimentation
As
statedin
theTechnical
Documentation
ofAppendix
C,
the code of eachfunction
in every
module wastested
independently.
However,
thefunctions
in
thequanadap
module were testedin
conjunction withall othercodeto prove their correctness.
A
totalof11
rawimages,
5
similar abdominalimages
and6
others ofvarying
edginess,wereused
for
experimentation.Some
oftheimage
typeswere radiographicin
origin.The
purposeof allsubsequentanalysis
is
tocompare recoveredimages
to theoriginals andtheirlowest-compressed forms.
Also,
theobjectiveand subjective results produced
for
all variations of classification and optimization weresystematically
contrasted
(see
Appendix
B,
Figure
8).
Note
that thelowest-compressed
images
were compressed andexpandedwith a quantization matrix
consisting
ofonly
Is,
using only
the code writtenfor
this thesis.All
calculationswere verified
using
a calculator.6
Analysis
The
referenceimages
for
alloriginal,
lowest-compressed,
Sobel
edge-detected,
andLaplacian
edge-detectedimages
are givenin
Appendices D
through
G,
respectively.All
otherresulting
expandedimages,
analysis,results,
and conclusions aredetailed
in
Appendices H
throughM.
The
following
subsections arebased
uponthese appendices.
6.1
Results
andConclusions
The
resultsusing
GA
andTS
optimization methodsfor
finding
thebest
set of quantization matricesfor
animage
are givenin
Figures
1
through16
ofAppendix
M.
The
analysis of these results yieldsmany
interesting
observations.First,
theedge-transitions producedfrom
theperimeterization method usedfor
block
classification,
gives thebest
results overall.Second,
only
sets of1
or2
quantization matrices usedfor
both
GA
and
TS
methods yield thebest
objective results,employing
thebasic
costfunction
without weights.Third,
aset of quantization matrices
designed for
an abdominalimage
works well on other similar abdominalimages.
Fourth,
both
subjectively
andobjectively
theGA
method appearstooutperform theTS
methodin just
aboutevery
respect.Many
otherless
significant resultspertaining
tohow
each optimization method performed canbe
viewed
in
Figure
15
ofAppendix M.
The
computationalcomplexity
of each algorithmis
detailed
in
Figure
16
ofthesame appendix.
The GA
ranin
afaster
O(N)
time that oftheTS
algorithmdue
to thefact
that tabusearch requiredtheexamination of each possible
kernel
movein every iteration
(where N
is
thenumberof pixelsin
animage).
In
looking
at all theresulting data
morefirm
conclusions canbe
made.Subjectively,
both
optimizationmethods appear to produce recovered
images
which areless detailed
and moreblurry
thanboth
the originaland
lowest-compressed
set ofimages.
However,
therecoveredimages
did
appearto showless blockiness
aroundthe edges
in
all ofthe testimages,
and that was one ofthe
aims ofthis thesis.Perimeterization
used withthe
Laplacian
operatorappearsto
providethebest
meansfor
classification oftheimage blocks.
Although
the
GA
outperformsTS
in
both
cost and computationalcomplexity
(time
duration),
both
methods worked wellafter
applying
a quantization matrix of animage
toimages
ofthe sametype.The GA
performedbest
using
atwo-point crossover,
a crossover rate of about0.90,
a mutation rate of about0.06,
atournamentsize of around30,
and a population size of around30.
The TS
method performedbest
using
atabu size of around70.
All
oftheseconclusionstake
into
account objective and subjective analysis(see Appendix
M,
Figure
17).
It
is
toodifficult
to
tell what amount of quantization matrices performsbest
using
the weightless costfunction
givenin
Figure
9
ofAppendix A.
However,
preliminary results show that an optimum number ofquantization matrices can
be
found for
any image using
the weighted costfunction.
This
amount appears tovary
based
upontherelativeedginess of certainimages
(i.e.
moreedginess means more quantization matricesfor
classification).
Results
alsoindicate
thatraising
thePSNR
weightfrom
1
to32
(by
powers of2)
has
a negativeaffect on the
BPP
calculationonly,
whileraising
theBPP
weightin
a similar mannerhas
a negative affect onthe
PSXR
calculation only.Objective
and subjective results were also usedin
this analysis.6.2
Problems
andDiscrepancies
Many
problemsoccurredduring
theimplementation
ofthisthesis,
but
all ofthemwere abletobe
overcome.One
ofthemajorhurdles
wasgetting
theinitial
compression and expansion of animage
towork.To beat
thisproblemthe
DC (upper
left)
termof eachimage
block
had
tobe
scaled anddescaled
whenpacking
andunpacking,
respectively.
Another
problemthatwas abletobe
solved wasfinding
an appropriate weighted costfunction
for
allowing better image quality
orbetter
compressionbased
upon user preference.Over
several weeksmany
different
variations weretested,
but
in
the endthe alternate costfunction
givenin Figure 9
ofAppendix
A
waschosen
for
extratesting.There
weresome peculiaritiesthat transpiredwhich were not expectedin
the results.It
wasintended
thatmorequantization
tables,
regardless ofthedegree
of edginess of a givenimage,
wouldalwaysbe
beneficial.
This
did
notturnouttobe
thecase afteranalyzing
thedata.
Also,
theSobel
edge-detection operatordid
not appearto
be
goodfor
classification,
but
in
some casesit
did
performbetter
on the sameimages
whoseblocks
wereclassifiedwiththe
Laplacian
operator.6.3
Lessons Learned
As
statedpreviously I
would ratherhave
attemptedthis thesisfrom
more of an object-orientedstandpoint.This
wouldhave
put an envelope ofinheritance
andexpandability
aroundthe project suchthat others couldmore
easily
understandthecomponentsand add more wherenecessary.However,
sinceDCT
is apparently
being
replaced
by
DWT for
thefuture JPEG
standard,
thelikelihood
of someoneadding
to this exact thesisprojectis
fairly
remote.It
shouldbe
stated,
though,
that the techniques used within this thesismay
very wellhave
applicationsto the
different
typeof quantization containedwithinDWT.
In
referenceto thearticlesinspected in
thisthesis, Good
saidthatpsychovisualexperiments are sometimesdependent
upon suboptimaldisplay
characteristics.The
weightedcostfunction
usedfor
alternate studiesin
thisthesis provedto
be
afairly
good substitute(although
not areplacement)
for
such experiments.Quantization
tables wereableto
be
successfully
appliedtoimages
ofsimilartypes,
just
asit
wasproclaimedin
thearticleby
Berman, Long,
andPillemer. Although
estimations were not usedfor
BPP
andPSNR
calculations,
theweightedcost
function
andinitial
random coarse quantization matrices were similar to those mentionedin
thearticleby
Fung
andParker.
It
shouldbe
notedthatalthoughusing
estimations wouldhave
reducedtherunning
timeoftheprogram, the computational
complexity
ofthe algorithms used would stillhave
been asymptotically
the same.The
balance
ofimage quality
andcompressibility
for
transmission or storage wasimplemented in
a comparablemannerto themethods
described
in
the articleby
Kil
andOh.
Possible
future
enhancements,
such asadding
thecapability
for
applying
the algorithms tolarger
anddenser
images,
canbe
made tothe code.Also,
althoughit is
notrecommended,
thekernel
size couldbe
mademorevariable.
Skeletonization
may
be
usedfor
classificationinstead
ofthemodified perimeterizationtechnique,
and other neural networks can
be
examined tofind
out theirability
tohelp
classify
theblocks
of animage.
Moreover,
lossless coding
algorithmsmay
be
used toincrease
the compression rate evenfurther.
Of
course.simply
modifying
the quantization tablesis
not a panaceafor
any
type ofimage
compression.Other
factors,
including
those thatmay
have
nothing
todo
withedge-detection,
shouldbe
considered whentrying
to create anoverall
better image
compression algorithm.Although I had
neverdone investigations
or projects relatedtoimage
compressionbefore
doing
thisthesis,
I
believe I
nowhave
thecapability
ofapplying my knowledge
ofimage
compression optimization to othercompression strategies.
This has
truly
been
anenlightening
experiencefor
me andI
am gratefulfor
all theofpeople who
have helped
mein
this attempt.7
Bibliography
URL REFERENCES:
Azar.
Danielle.
jeff.cs.mcgill.ca/"godfried/teaching/projects97/azar/skeleton.html,
1997.
Compression Overview.
www-ise.stanford.edu/class/ee392c/demos/bajC-and-vitus/node6.html,1997.
Data Compression
Reference,
www.rasip.fer.hr/research/compress/algorithms/fund/ac/index.html,1997.
Edge-detection.
www.cclabs.missouri.edu/~c655467/CECS-365/ObjectJmg/LaplaJmg/part_3.htrnl,1997
Hurley. S.
www.es. cf.ac.uk/User/Steve.Hurley/Ra/year2/nodel4.html,
1997.
Measures
ofImage Quality.
seurat.uwaterloo.ca/~tvelcmui/MAScThesis/nodel8.html,1997.
Smith,
Steven W.
www.dspguide.com/datacomp.htm,1996.
Totem
(The
Reactive Tabu Search),
infn.science.unitn.it/totem/totem95/node2.html,
1995.
BOOK REFERENCES:
Althoen,
Steven
C.
andBumcrot,
Robert J. Matrix Methods in Finite Mathematics. New
York,
NY. W. W.
Norton
andCompany,
1976.
Embree,
Paul M.
andKimble,
Bruce.
C
Language
Algorithms for
Digital
Signal
Processing.
Englewood
Cliffs, NJ,
Prentice-Hall
Inc.,
1991.
Fausett,
Laurene Y. Fundamentals
ofNeural Networks.
Englewood
Cliffs, NJ,
Prentice-Hall
Inc.,
1994.
Glover,
Fred W
andLaguna,
Manuel. Tabu
Search.
Norwell,
MA,
Kluwer Academic
Publishers,
1997.
Mitchell,
Melanie.
An Introduction
toGenetic
Algorithms.
Cambridge,
MA,
The MIT
Press,
1997.
Russ,
John
C. The
Image
Processing
Handbook.
Boca
Raton,
FL,
CRC
Press,
1992.
PAPER
REFERENCES:Anguita, Davide, Passaggio,
Filippo,
andZunino,
Rodolfo. SOM-Based
Interpolation
for
Image
Compression.
World Congress
onNeural
Networks,
Washington,
DC,
Vol.
1,
1995.
Berman,
L.
E., Long,
R.,
andPillemer,
S.
R. Effects
ofQuantization Table Manipulation
onJPEG Compres
sion of
Cervical Radiographs.
Society
for
Information
Display
International
Symposium,
Volume
24,
1993.
Christos,
Chrysalis
andOrtega,
Antonio. Context-based Adaptive Image Coding. Integrated
Media Systems
Center, USC,
Los
Angeles,
CA,
1996.
Distasi, Riccardo, Nappi, Michele,
andVitulano,
Sergio.
A B-Tree Based Recursive Technique for
Image
Coding.
13th
International Conference
onPattern
Recognition, Vienna, Austria,
Volume
2,
1996.
Fung,
Hei
Tao
andParker,
Kevin
J. Design
ofImage-adaptive Quantization
Tables for
JPEG. Journal
ofElectronic
Imaging, April,
1995.
Good,
Walter F
Quantization Technique for
theCompression
ofChest
Images
by
JPEG
Algorithms.
SPIE
Yolume
1652 Medical
Imaging
VI:
Image
Processing,
1992.
Graps,
Amara. An Introduction
toWavelets.
IEEE Computational Science
andEngineering,
Summer,
1995.
Houck,
C.
R., Joines,
J.
A.,
andGray,
M.
G.
Characterizing
search spacesfor Tabu Search.
Dept.
ofIndus
trial
Engineering,
North
Carolina State
University,
Raleigh,
NC,
1996.
Jiang,
J. Algorithm Design
of anImage
Compression Neural Network. World
Congress
onNeural
Networks,
Washington, DC,
Volume
1,
1995.
Kil,
Rhee
M.
andOh,
Young-in.
Vector
Quantization Based
onGenetic Algorithm.
World
Congress
onNeural
Networks,
Washington,
DC,
Volume
1,
1995.
Ramos,
Marcia
G.
andHemami,
Sheila S. Edge-adaptive JPEG Image Compression.
School
ofElectrical
Engineering,
Cornell
University, Ithaca,
NY. 1996.
Xuan,
Kianhua
andAdah,
Tulay.
Learning
Tree-Structured
\
ectorQuantization for
Image
Compression.
World
Congress
onNeural
Networks,
Washington, DC,
Vol.
1,
1995.
Yapo,
Theodore
C.
andEmbrechts,
Mark J.
Neural Vector Quantization for Image Compression. Rensselaer
Polytechnic
Institute,
Troy,
NY,
1996.
8
Appendices
(all
subsequent
pages)
Masters
Thesis
(Winter
1998/1999)
APPENDIX
A
-Background Information
Michael S. Champion (e-mail:
Genetic Algori&im
<Tabu Search
Approaches
to
Adaptive Quantization
in
DCT
Image Compression
(by
Michael Champion
for MS Thesis in. Computer
Science,
Winter
98/99)
Today
there
are severalformal
and experimental methodsfor image
compression,
some
ofwhich
have
grownto
be incorporated into
the
Joint
Photographers Experts
Group (JPEG)
standard.Of
course,
many
ofthe
associated
algorithms are still usedonly for
experimentationmainly due
to
variousperformance
issues. Lack
of speed whilecompressing
orexpanding
animage
as well as poorimage
quality
after expansion are acouple
ofthe
most
popular reasonsfor
skepticismabout a particular
compression
algorithm.This
paper
discusses
current methods usedfor image
compression.It
alsogives
adetailed
explanation ofthe
discrete
cosinetransform
(DCT),
usedby
JPEG,
andthe
effortsthat
have recently been
madeto
optimize related algorithms.
Some
interesting
articlesregarding
possible compression enhancements will
be
noted,
andin
associationwith
these
methods a newimplementation
of aJPEG-
like image coding
algorithm will
be
outlined.This
newtechnique
involves adapting
between
one&
sixteen quantizationtables
for
a specificimage using
both
genetic algorithm(GA)
andtabu
search
(TS)
approaches.
First,
a simple algorithm will
be
usedto
classify
the
edge-detected
blocks
ofa given
image.
A
complexKohonen
self-organizing
map
algorithmis
attempted,
but
the
resultsusing
this
algorithm
appearedto
be
worsedue
to
lack
of convergence upon atrusted
set ofweights.Next,
the
GA
and
TS
algorithmswillbe
used
to
iteratively
seek
outthe
optimumquantizationmatrices.
The
selected costfunction
minimizesbits
perpixel while
maximizing
the
peak signal-to-noise ratio
afterthe
compressionand expansion of
the
original
image.
LOSSLESS
CODING
METHODS:
Lossless coding
methods
are ableto
restore acompressedimage
that
is exactly identical
to the
originalimage.
Lossless coding
techniques
include
optimalentropy
coding,
Huffman
coding,
Lempel-Ziv
coding,
adjacent
pixel paircoding
,predie tive
pixelcoding,
lossless
pyramidcoding,
and
differential
pulse code modulation(DP CAT).
Optimal entropy coding
worksin
suchaway
that the
length
of each codewordis
proportionalto the
frequency
used,
andit
has
achieved
7%
compression at7.39 bits
per pixel(bpp). Huffman
coding
is
anexample of
this type
ofuniquely decodable
variablelength coding
methodin
whichthe
codeis
madeby
examining
the
probabilities ofsourcesymbols andassigning
codewordsto
minimizethe
average codelength
for
instantaneous
recognition.The
Lempel-Ziv
methodwhich
usually
usesHuffman coding
operates on asliding
window ofdata
whichis
parseduntil a
dictionary
is
created,
andit is
ableto
achieve18%
compression with654 bpp.
Lempel-Ziv
is
a member of a set ofmany
dictionary
coding
methodsin
whichthe
dictionary
does
notalwayshave
to
be
sent withthe
data. Adjacent
pixel paircoding
exploitsthe
correlationof
neighboring
pix