Part-of-Speech Tagging using Conditional Random Fields: Exploiting
Sub-Label Dependencies for Improved Accuracy
Miikka Silfverberga Teemu Ruokolainenb Krister Lindéna Mikko Kurimob
aDepartment of Modern Languages, University of Helsinki, [email protected]
b Department of Signal Processing and Acoustics, Aalto University, [email protected]
Abstract
We discuss part-of-speech (POS) tagging in presence of large, fine-grained la-bel sets using conditional random fields (CRFs). We propose improving tagging accuracy by utilizing dependencies within sub-components of the fine-grained labels. These sub-label dependencies are incor-porated into the CRF model via a (rela-tively) straightforward feature extraction scheme. Experiments on five languages show that the approach can yield signifi-cant improvement in tagging accuracy in case the labels have sufficiently rich inner structure.
1 Introduction
We discuss part-of-speech (POS) tagging using the well-known conditional random field (CRF) model introduced originally by Lafferty et al. (2001). Our focus is on scenarios, in which the POS labels have arich inner structure. For exam-ple, consider
PRON+1SG V+NON3SG+PRES N+SG
I like ham ,
where the compound labels PRON+1SG,
V+NON3SG+PRES, and N+SG stand for pro-noun first person singular, verb non-third singular present tense, and noun singular, respectively. Fine-grained labels occur frequently in mor-phologically complex languages (Erjavec, 2010; Haverinen et al., 2013).
We propose improving tagging accuracy by uti-lizing dependencies within thesub-labels(PRON, 1SG, V, NON3SG, N, and SG in the above ex-ample) of the compound labels. From a technical perspective, we accomplish this by making use of the fundamental ability of the CRFs to incorporate arbitrarily defined feature functions. The newly-defined features are expected to alleviate data
spar-sity problems caused by the fine-grained labels. Despite the (relative) simplicity of the approach, we are unaware of previous work exploiting the sub-labels to the extent presented here.
We present experiments on five languages (En-glish, Finnish, Czech, Estonian, and Romanian) with varying POS annotation granularity. By uti-lizing the sub-labels, we gain significant improve-ment in model accuracy given a sufficiently fine-grained label set. Moreover, our results indi-cate that exploiting the sub-labels can yield larger improvements in tagging compared to increasing model order.
The rest of the paper is organized as follows. Section 2 describes the methodology. Experimen-tal setup and results are presented in Section 3. Section 4 discusses related work. Lastly, we pro-vide conclusions on the work in Section 5.
2 Methods
2.1 Conditional Random Fields
The (unnormalized) CRF model (Lafferty et al., 2001) for a sentencex= (x1, . . . , x|x|)and a POS
sequencey= (y1, . . . , y|x|)is defined as
p(y|x;w)∝
|x| Y
i=n
expw·φ(yi−n, . . . , yi, x, i)
,
(1) wherendenotes the model order,wthe model pa-rameter vector, andφthe feature extraction func-tion. We denote the tag set asY, that is, yi ∈ Y
fori∈1. . .|x|.
2.2 Baseline Feature Set
We first describe our baseline feature set {φj(yi−1, yi, x, i)}|jφ=1| by defining emission and
transition features. The emission feature set as-sociates properties of the sentence positioniwith
the corresponding label as
{χj(x, i)1(yi =y0i)|j ∈1. . .|X |,∀yi0 ∈ Y},
(2) where the function1(q)returns one if and only if the propositionqis true and zero otherwise, that is
1(yi=yi0) =
1 if yi =y0 i
0 otherwise , (3)
and X = {χj(x, i)}|X |j=1 is the set of functions characterizing the word positioni. Following the classic work of Ratnaparkhi (1996), ourX com-prises simple binary functions:
1. Bias (always active irrespective of input). 2. Word formsxi−2, . . . , xi+2.
3. Prefixes and suffixes of the word formxi up to lengthδsuf = 4.
4. If the word form xi contains (one or more) capital letter, hyphen, dash, or digit.
Binary functions have a return value of either zero (inactive) or one (active). Meanwhile, the transi-tion features
{1(yi−k=yi0−k). . .1(yi =yi0)| y0
i−k, . . . , y0i∈ Y,∀k∈1. . . n} (4)
capture dependencies between adjacent labels ir-respective of the inputx.
2.2.1 Expanded Feature Set Leveraging Sub-Label Dependencies
The baseline feature set described above can yield a high tagging accuracy given a conveniently sim-ple label set, exemplified by the tagging results of Collins (2002) on the Penn Treebank (Mar-cus et al., 1993). (Note that conditional random fields correspond to discriminatively trained hid-den Markov models and Collins (2002) employs the latter terminology.) However, it does to some extent overlook some beneficial dependency infor-mation in case the labels have a rich sub-structure. In what follows, we describe expanded feature sets which explicitly model the sub-label dependen-cies.
We begin by defining a function P(yi) which
partitions any label yi into its sub-label
compo-nents and returns them in an unordered set. For example, we could define P(PRON+1+SG) =
{PRON, 1, SG}. (Label partitions employed in the experiments are described in Section 3.2.) We denote the set of all sub-label components asS.
Subsequently, instead of defining only (2), we additionally associate the feature functionsXwith all sub-labelss∈ S by defining
{χj(x, i)1(s∈ P(yi))| ∀j∈1. . .|X |,∀s∈ S},
(5) where 1(s ∈ P(yi)) returns one in case sis in
P(yi)and zero otherwise. Second, we exploit sub-label transitionsusing features
{1(si−k∈ P(yi−k)). . .1(si∈ P(yi))|
∀si−k, . . . , si∈ S,∀k∈1. . . m}. (6)
Note that we define the sub-label transitions up to order m, 1 ≤ m ≤ n, that is, an nth-order CRF model is not obliged to utilize sub-label tran-sitions all the way up to order n. This is be-cause employing high-order sub-label transitions may potentially cause overfitting to training data due to substantially increased number of features (equivalent to the number of model parameters, |w| = |φ|). For example, in a second-order (n = 2) model, it might be beneficial to em-ploy the sub-label emission feature set (5) and first-order sub-label transitions while discarding second-order sub-label transitions. (See the exper-imental results presented in Section 3.)
In the remainder of this paper, we use the fol-lowing notations.
1. A standard CRF model incorporating (2) and (4) is denoted as CRF(n,-).
2. A CRF model incorporating (2), (4), and (5) is denoted as CRF(n,0).
3. A CRF model incorporating (2), (4), (5), and (6) is denoted as CRF(n,m).
2.3 On Linguistic Intuition
This section aims to provide some intuition on the types of linguistic phenomena that can be captured by the expanded feature set. To this end, we con-sider an example on the plural number in Finnish. First, consider the plural nominative word form
will also be associated to the sub-label PLURAL. This can be useful because, in Finnish, also adjec-tives and numerals are inflected according to num-ber and denote the plural numnum-ber with the suffix
-t (Hakulinen et al., 2004, §79). Therefore, one can exploit-tto predict the plural number also in words such asmustat(plural of black) with a com-pound analysis ADJECTIVE+PLURAL.
Second, consider the number agreement (con-gruence). For example, in the sentence fragment
mustat kissat juoksevat (black cats are running), the wordsmustatandkissatshare the plural num-ber. In other words, the analyses of both mustat
and kissat are required to contain the sub-label PLURAL. This short-span dependency between labels will be captured by a first-order sub-label transition feature included in (6).
Lastly, we note that the feature expansion sets (5) and (6) will, naturally, capture any short-span dependencies within the sub-labels irrespective if the dependencies have a clear linguistic interpre-tation or not.
3 Experiments
3.1 Data
For a quick overview of the data sets, see Table 1.
Penn Treebank. The English Penn Treebank (Marcus et al., 1993) is divided into 25 sections of newswire text extracted from the Wall Street Journal. We split the data into training, develop-ment, and test sets using the sections 0-18, 19-21, and 22-24, according to the standardly applied di-vision introduced by Collins (2002).
Turku Depedency Treebank. The Finnish Turku Depedendency Treebank (Haverinen et al., 2013) contains text from 10 different domains. The treebank does not have default partition to training and test sets. Therefore, from each 10 consecutive sentences, we assign the 9th and 10th to the development set and the test set, respec-tively. The remaining sentences are assigned to the training set.
Multext-East. The third data we consider is the multilingual Multext-East (Erjavec, 2010) corpus, from which we utilize the Czech, Estonian and Ro-manian sections. The corpus corresponds to trans-lations of the novel 1984by George Orwell. We apply the same data splits as for Turku Depen-dency Treebank.
lang. train. dev. test tags train. tags Eng 38,219 5,527 5,462 45 45
Rom 5,216 652 652 405 391
Est 5,183 648 647 413 408
Cze 5,402 675 675 955 908
Fin 5,043 630 630 2,355 2,141
Table 1: Overview on data. The training (train.), development (dev.) and test set sizes are given in sentences. The columns titledtagsandtrain. tags
correspond to total number of tags in the data set and number of tags in the training set, respectively.
3.2 Label Partitions
This section describes the employed compound la-bel splits. The lala-bel splits for all data sets are sub-mitted as data file attachments. All the splits are performeda priorito model learning, that is, we do not try to optimize them on the development sets.
The POS labels in the Penn Treebank are split in a way which captures relevant inflectional cat-egories, such as tense and number. Consider, for example, the split for the present tense third sin-gular verb labelP(VBZ) ={VB, Z}.
In the Turku Dependency Treebank, each morphological tag consists of sub-labels mark-ing word-class, relevant inflectional categories, and their respective values. Each inflec-tional category, such as case or tense, com-bined with its value, such as nominative or present, constitutes one sub-label. Consider, for example, the split for the singular, adessive nounP(N+CASE_ADE+NUM_SG) ={POS_N, CASE_ADE, NUM_SG}.
word class marker. For example, consider the split P(Pw3–r) ={0 : P, 1 : Pw, 2 : P3, 5 : Pr}.
3.3 CRF Model Specification
We perform experiments using first-order and second-order CRFs with zeroth-order and first-order sub-label features. Using the notation introduced in Section 2, the employed mod-els are CRF(1,-), CRF(1,1), CRF(2,-), CRF(2,0), and CRF(2,1). We do not report results us-ing CRF(2,2) since, based on preliminary exper-iments, this model overfits on all languages.
The CRF model parameters are estimated using the averaged perceptron algorithm (Collins, 2002). The model parameters are initialized with a zero vector. We evaluate the latest averaged parameters on the held-out development set after each pass over the training data and terminate training if no improvement in accuracy is obtained during three last passes. The best-performing parameters are then applied on the test instances.
We accelerate the perceptron learning using beam search (Zhang and Clark, 2011). The beam width, b, is optimized separately for each lan-guage on the development sets by consideringb= 1,2,4,8,16,32,64,128until the model accuracy does not improve by at least 0.01 (absolute).
Development and test instances are decoded us-ing Viterbi search in combination with the tag dic-tionary approach of Ratnaparkhi (1996). In this approach, candidate tags for known word forms are limited to those observed in the training data. Meanwhile, word forms that were unseen during training consider the full label set.
3.4 Software and Hardware
The experiments are run on a standard desktop computer (Intel Xeon E5450 with 3.00 GHz and 64 GB of memory). The methods discussed in Section 2 are implemented in C++.
3.5 Results
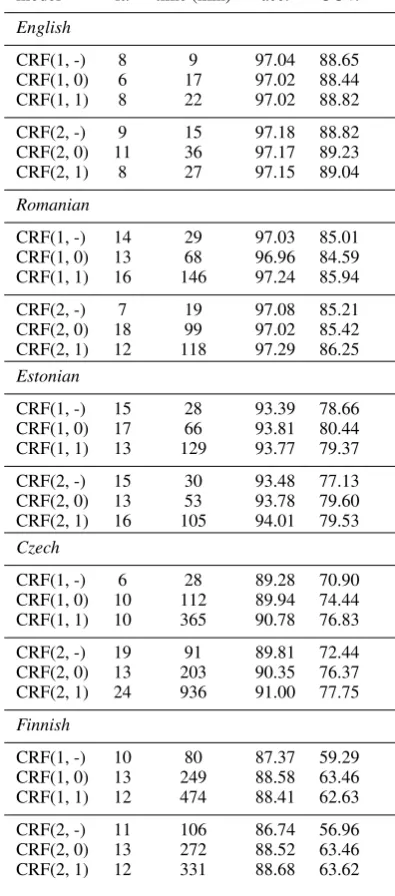
The obtained tagging accuracies and training times are presented in Table 2. The times in-clude running the averaged perceptron algorithm and evaluation of the development sets. The col-umn labeled it. corresponds to the number of passes over the training data made by the percep-tron algorithm before termination. We summarize the results as follows.
First, compared to standard feature extraction approach, employing the sub-label transition
fea-tures resulted in improved accuracy on all lan-guages apart from English. The differences were statistically significant on Czech, Estonian, and Finnish. (We establish statistical significance (with confidence level 0.95) using the standard 1-sided Wilcoxon signed-rank test performed on 10 randomly divided, non-overlapping subsets of the complete test sets.) This results supports the in-tuition that the sub-label features should be most useful in presence of large, fine-grained label sets, in which case the learning is most affected by data sparsity.
Second, on all languages apart from English, employing a first-order model with sub-label fea-tures yielded higher accuracy compared to a second-order model with standard features. The differences were again statistically significant on Czech, Estonian, and Finnish. This result suggests that, compared to increasing model order, exploit-ing the sub-label dependencies can be a preferable approach to improve the tagging accuracy.
Third, applying the expanded feature set in-evitably causes some increase in the computa-tional cost of model estimation. However, as shown by the running times, this increase is not prohibitive.
4 Related Work
In this section, we compare the approach pre-sented in Section 2 to two prior systems which at-tempt to utilize sub-label dependencies in a similar manner.
im-model it. time (min) acc. OOV. English
CRF(1, -) 8 9 97.04 88.65
CRF(1, 0) 6 17 97.02 88.44 CRF(1, 1) 8 22 97.02 88.82 CRF(2, -) 9 15 97.18 88.82 CRF(2, 0) 11 36 97.17 89.23 CRF(2, 1) 8 27 97.15 89.04 Romanian
CRF(1, -) 14 29 97.03 85.01 CRF(1, 0) 13 68 96.96 84.59 CRF(1, 1) 16 146 97.24 85.94 CRF(2, -) 7 19 97.08 85.21 CRF(2, 0) 18 99 97.02 85.42 CRF(2, 1) 12 118 97.29 86.25 Estonian
CRF(1, -) 15 28 93.39 78.66 CRF(1, 0) 17 66 93.81 80.44 CRF(1, 1) 13 129 93.77 79.37 CRF(2, -) 15 30 93.48 77.13 CRF(2, 0) 13 53 93.78 79.60 CRF(2, 1) 16 105 94.01 79.53 Czech
CRF(1, -) 6 28 89.28 70.90 CRF(1, 0) 10 112 89.94 74.44 CRF(1, 1) 10 365 90.78 76.83 CRF(2, -) 19 91 89.81 72.44 CRF(2, 0) 13 203 90.35 76.37 CRF(2, 1) 24 936 91.00 77.75 Finnish
[image:5.595.81.279.73.522.2]CRF(1, -) 10 80 87.37 59.29 CRF(1, 0) 13 249 88.58 63.46 CRF(1, 1) 12 474 88.41 62.63 CRF(2, -) 11 106 86.74 56.96 CRF(2, 0) 13 272 88.52 63.46 CRF(2, 1) 12 331 88.68 63.62
Table 2: Results.
proved open-source implementation of the well-known TnT tagger of Brants (2000). The obtained HunPos results are presented in Table 3.
Eng Rom Est Cze Fin
HunPos 96.58 96.96 92.76 89.57 85.77
Table 3: Results using a generative HMM-based HunPos tagger of Halacsy et al. (2007).
Ceau¸su (2006) uses a maximum entropy Markov model (MEMM) based system for tag-ging Romanian which utilizes transitional behav-ior between sub-labels similarly to our feature set (6). However, in addition to ignoring the most
in-formative emission-type features (5), Ceau¸su em-beds the MEMMs into the tiered tagging frame-work of Tufis (1999). In tiered tagging, the full morphological analyses are mapped into a coarser tag set and a tagger is trained for this reduced tag set. Subsequent to decoding, the coarser tags are mapped into the original fine-grained morpholog-ical analyses. There are several problems associ-ated with this tiered tagging approach. First, the success of the approach is highly dependent on a well designed coarse label set. Consequently, it requires intimate knowledge of the tag set and lan-guage. Meanwhile, our model can be set up with relatively little prior knowledge of the language or the tagging scheme (see Section 3.2). More-over, a conversion to a coarser label set is neces-sarily lossy (at least for OOV words) and poten-tially results in reduced accuracy since recovering the original fine-grained tags from the coarse tags may induce errors. Indeed, the accuracy 96.56, re-ported by Ceau¸su on the Romanian section of the Multext-East data set, is substantially lower than the accuracy 97.29 we obtain. These accuracies were obtained using identical sized training and test sets (although direct comparison is impossible because Ceau¸su uses a non-documented random split).
5 Conclusions
We studied improving the accuracy of CRF-based POS tagging by exploiting sub-label dependency structure. The dependencies were included in the CRF model using a relatively straightforward fea-ture expansion scheme. Experiments on five lan-guages showed that the approach can yield signif-icant improvement in tagging accuracy given suf-ficiently fine-grained label sets.
In future work, we aim to perform a more fine-grained error analysis to gain a better under-standing where the improvement in accuracy takes place. One could also attempt to optimize the compound label splits to maximize prediction ac-curacy instead of applying a priori partitions.
Acknowledgements
References
Thorsten Brants. 2000. Tnt: A statistical part-of-speech tagger. In Proceedings of the Sixth Con-ference on Applied Natural Language Processing, pages 224–231.
A. Ceausu. 2006. Maximum entropy tiered tagging. InThe 11th ESSLI Student session, pages 173–179.
Michael Collins. 2002. Discriminative training meth-ods for Hidden Markov Models: Theory and experi-ments with perceptron algorithms. InProceedings of the 2002 Conference on Empirical Methods in Natural Language Processing (EMNLP 2002), vol-ume 10, pages 1–8.
Toma˘z Erjavec. 2010. Multext-east version 4: Multi-lingual morphosyntactic specifications, lexicons and corpora. InProceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10).
Jan Hajiˇc, Pavel Krbec, Pavel Kvˇetoˇn, Karel Oliva, and Vladimír Petkeviˇc. 2001. Serial combination of rules and statistics: A case study in czech tagging. InProceedings of the 39th Annual Meeting on Asso-ciation for Computational Linguistics, pages 268– 275.
Auli Hakulinen, Maria Vilkuna, Riitta Korhonen, Vesa Koivisto, Tarja Riitta Heinonen, and Irja Alho. 2004. Iso suomen kielioppi. Suomalaisen Kirjal-lisuuden Seura, Helsinki, Finland.
Péter Halácsy, András Kornai, and Csaba Oravecz. 2007. Hunpos: An open source trigram tagger. In Proceedings of the 45th Annual Meeting of the ACL on Interactive Poster and Demonstration Sessions, ACL ’07, pages 209–212.
Katri Haverinen, Jenna Nyblom, Timo Viljanen, Veronika Laippala, Samuel Kohonen, Anna Missilä, Stina Ojala, Tapio Salakoski, and Filip Ginter. 2013. Building the essential resources for Finnish: the Turku Dependency Treebank. Language Resources and Evaluation.
John Lafferty, Andrew McCallum, and Fernando Pereira. 2001. Conditional random fields: Prob-abilistic models for segmenting and labeling se-quence data. InProceedings of the Eighteenth In-ternational Conference on Machine Learning, pages 282–289.
M.P. Marcus, M.A. Marcinkiewicz, and B. Santorini. 1993. Building a large annotated corpus of en-glish: The penn treebank. Computational linguis-tics, 19(2):313–330.
Adwait Ratnaparkhi. 1996. A maximum entropy model for part-of-speech tagging. In Proceedings of the conference on empirical methods in natu-ral language processing, volume 1, pages 133–142. Philadelphia, PA.
Noah A. Smith, David A. Smith, and Roy W. Tromble. 2005. Context-based morphological disambiguation with random fields. InProceedings of the Confer-ence on Human Language Technology and Empiri-cal Methods in Natural Language Processing, pages 475–482.
Dan Tufis. 1999. Tiered tagging and combined lan-guage models classifiers. InProceedings of the Sec-ond International Workshop on Text, Speech and Di-alogue, pages 28–33.