Probabilistic Word Classification Based on Context-
Sensitive Binary Tree Method
Jun Gao, XiXian Chen
Information Technology LaboratoryBeijing University of Posts and Telecommuncations P.O. Box 103, Beijing University of Posts and Telecommuncations
No. 10, Xi Tu Cheng street, Hal Dian district Beijing, 100088, China
e-maih [email protected]
I :
I
I
I
I
I
Abstract
C o r p u s - b a s e d s t a t i s t i c a l - o r i e n t e d Chinese w o r d c l a s s i f i c a t i o n can be r e g a r d e d as a fundamental step for a u t o m a t i c or n o n - a u t o m a t i c , mono- lingual n a t u r a l p r o c e s s i n g system. W o r d c l a s s i f i c a t i o n can solve the p r o b l e m s of data sparseness and have far fewer parameters. So far, much r:,la~v~ work about w o r d c l a s s i f i c a t i o n has b e e n done. All the work is b a s e d on some s i m i l a r i t y metrics. We use average mutual information as global s i m i l a r i t y m e t r i c to do c l a s s i f i c a t i o n . The c l u s t e r i n g p r o c e s s is t o p - d o w n s p l i t t i n g and the b i n a r y tree is g r o w i n ~ w i t h splitting. In n a t u r a l lan~lage, the effect of left neighbors and right n e i g h b o r s of a w o r d are asymmetric. To utilize this d i r e c t i o n a l information, we induce the l e f t - r i g h t b i n a r y and right-left b i n a r y tree to represent this property. The p r o b a b i l i t y is also introduced in our a l g o r i t h m to m e r g e the r e s u l t i n g classes from
l e f t - r i g h t and right-left b i n a r y tree. Also, we use the resulting classes to do e x p e r i m e n t s on w o r d c l a s s - b a s e d language model. Some classes results and p e r p l e x i t y of w o r d c l a s s - b a s e d language m o d e l are presented.
1. Introduction
Word c'lassification p l a y an important role in c o m p u t a t i o n a l _i:~gu~s~.~. Many casks in c o m p u t a t i o n a l linguistics, w h e t h e r they use statistical or symbolic methods, reduce the c o m p l e x i t y of the p r o b l ~ m by d e a l i n g w i t h classes of words r a t h e r than individual words.
spaces is most l i k e l y , to reflect the l i n g u i s t i c p r o p e r t i e s of languaqe? What m e a n i n g f u l label or name s h o u l d be g i v e n to e a c h w o r d group? These q u e s t i o n s c o n s t i t u t e the p r o b l e m of f i n d i n g a w o r d classification. At present, no m e t h o d can find the optimal w o r d classification. However, r e s e a r c h e r s h a v e b e e n t r y i n g h a r d to find s u b - o p t i m a l s t r a t e g i e s w h i c h lead to u s e f u l classification.
From p r a c t i c a l p o i n t of view, w o r d c l a s s i f i c a t i o n a d d r e s s e s q u e s t i o n s of data s p a r s e n e s s a n d g e n e r a l i z a t i o n in s t a t i s t i c a l language models. Specially, it can be u s e d as an a l t e r n a t i v e to g r a m m a t i c a l p a r t - o f - speech t a g g i n g (Brili,1993; Cutting, Kupiec, P e d e r s o n and Sibun, 1992; Chang a n d Chen 1993a; Chang and Chen 1993b; Lee and Chang Chien, 1992; Kupiec,1992; Lee, 1993; M e r i a l d o , 1 9 9 4 ; Pop,1996; Peng, 1993; Zhou, 1995; Schutze, 1995;) on s t a t i s t i c a l l a n g u a g e m o d e l i n g ( H u a n g , Alleva, Hwang, Lee and R o s e n f e l d 1993; Rosefield, 1994;), b e c a u s e C h i n e s e l a n g u a g e m o d e l s u @ i n g p a r t - o f - s p e e c h i n f o r m a t i o n have h a d o n l y a v e r y l i m i t e d success(e.g. Chang, 1992; Lee, Dung, Lai, and Chang Chien, 1993;). The reason w h y there are so m a n y of the d i f f i c u l t i e s in Chineuc part o f - s p e e c h tagging are d e s c r i b e d by Chang and Chen (1995) and Zhao (1995).
M u c h r e l a t i v e w o r k on w o r d c l a s s i f i c a t i o n has b e e n done. The w o r k is
b a s e d on some s i m i l a r i t y metrics. ( Bahl, Brown, D e S o u z a and Mercer, 1989; Brown, Pietra, d e S o u z a and M e r c e r , 1 9 9 2 ; Chang, 1995;
DeRose,1988; Garside, 1987; Hughes, 1994; Jardino,1993; Jelinek,
Mercer, and Roukos, 1990b; Wu, Wang, Yu and Wang, 1995; Magerman, 1994; McMahon, 1994; McMahon, 1995; Pereira, 1992; Resnik, 1992; Zhao, 1995;)
Brill (1993) and Pop (1996) p r e s e n t a t r a n s f o r m a t i o n - b a s e d tagging.
Before a p a r t - o f - s p e e c h t a g g e r can be built, the w o r d c l a s s i f i c a t i o n s are p e r f o r m e d to h e l p us choose a set of p a r t - o f - s p e e c h . T h e y use the sum of two r e l a t i v e e n t r o p i e s o b t a i n e d from n e i g h b o r i n g words as the s i m i l a r i t y m e t r i c to compare two words.
Schutze (1995) shows a l o n g - d i s t a n c e left and right context of a w o r d
as left v e c t o r a n d right v e c t o r and the d i m e n s i o n s of e a c h v e c t o r are 50. MR ~ses Cosine as m e t r i c to m e a s u r e the s i m i l a r i t y b e t w e e n two
words. To solve the s p a r s e n e s s of the data, he applies a s i n g u l a r value d e c o m p o s i t i o n . C o m p a r i n g w i t h B r i l l , E . ' s method, Schutze,H. takes 50 n e i g h b o r s into a c c o u n t for each word.
Chang and Chen (1995) p r o p o s e d a s i m u l a t e d a n n e a l i n g method, the same as J a r d i n o a n d Adda 's (1993). The pel-plexity, w h i c h is the inverse of the p r o b a b i l i t y over the w h o l e text, is measured. The n e w value of the p e r p l e x i t y and a control p a r a m e t e r C p ( M e t r o p o l i s
algorithm) will d e c i d e w h e t h e r ' a n e w c l a s s i f i c a t i o n ( o b t a i n e d b y m o v i n g only one w o r d from its class to another, b o t h w o r d and class being r a n d o m l y chosen) will replace a p r e v i o u s one. C o m p a r e d to the two m e t h o d s d e s c r i b e d above, this m e t h o d a t t e m p t s to o p t i m i z e the c l u s t e r i n g u s i n g p e r p l e x i t y as a global measure.
specifically, t h e y model senses as p r o b a b i l i s t i c c o n c e p t s or clusters
C w i t h c o r r e s p o n d i n ~ cluster m e m b e r s h i p p r o b a b i l i t i e s P(Clw ) for each w o r d w. That is, w h i l e most other c l a s s - b a s e d m o d e l i n g techniques for n a t u r a l l a n g u a g e rely on "hard" B o o l e a n classes, Pereira, F. et al. (1993) p r o p o s e a m e t h o d for "soft" class clustering. He suggests a d e t e r m i n i s t i c a n n e a l i n g p r o c e d u r e for clustering. But as s t a t e d in their paper, t h e y only considers the special case of c l a s s i f y i n g nouns a c c o r d i n g to the d i s t r i b u t i o n as direct objects of verbs.
To addless the p r o b l e m s and u t i l i z e the a d v a n t a g e s of the m e t h o d s p r e s e n t e d above, we put f o r w a r d a n e w a l g o r i t h m to a u t o m a t i c a l l y c l a s s i f y the words.
2. Chinese Word Classification Method 2.1 Basic Idea
We adopt the t o p - d o w n b i n a r y s p l i t t i n g t e c h n i q u e to the all words u s i n g average m u t u a l information as s i m i l a r i t y m e t r i c like M c M a h o n (1995). This m e t h o d has its merits: T o p - d o w n t e c h n i q u e can represent the h i e r a r c h y information explicitly; the p o s i t i o n of the w o r d in c l a s s - s p a c e can be obtained w i t h o u t r e f e r e n c e to the p o s i t i o n s of other words, w h i l e the b o t t o m - u p t e c h n i q u e treats e v e r y w o r d in the v o c a b u l a r y as one class and m e r g e s two classes a m o n g this v o c a b u l a r y a c c o r d i n g to c e r t a i n s i m i l a r i t y metric, t h e n r e p e a t s the m e r g i n g p r o c e s s until the d e m a n d e d n u m b e r of classes is obtained.
2.1.1 Theoretical Basis
Brown r.~. a] . (1992) have shown that any c l a s s i f i c a t i o n system whose a v e r a g e class m u t u a l i n f o r m a t i o n is m a x i m i z e d will lead to c l a s s - b a s e d language m o d e l s of lower perplexities.
The concept of m u t u a l information, taken from i n f o r m a t i o n theory, was p r o p o s e d as a m e a s u r e of w o r d a s s o c i a t i o n (Church 1990; "Jelinek et al. 1990,1992; Dagan, 1995;). It reflects the s t r e n g t h of r e l a t i o n s h i p b e t w e e n words b y comparing t h e i r actual c o - o c c u r r e n c e p r o b a b i l i t y with
the probabi I ity that would be e x p e c t e d b y chance. The mutual i n f o r m a t i o n of two events x and y is defined as follows:
P(x,,x,_ )
(1)
I(x,
,x.,) = log.,
P(x, )P(x,.)
where P(x,)and P(x,)are the p r o b a b i l i t i e s of the events, and P(x,,x2)is
the p r o b a b i l i t y of the joint event. If there is a strong a s s o c i a t i o n
b e t w e e n x,and x, then
P(x,,x:)>>P(x,)P(x:)
as a result I(x,,x2)>>O. If there is a weak a s s o c i a t i o n b e t w e e n x, and x~ thenP(x,,x,)=P(x,)P(x2)
and/(x,,x2)=0. IfP(x,,x,.)<<P(x,)P(x:)
then I(x,,x2)<<O. Owing to the u n r e l i a b i l i t y of m e a s u r i n g n e g a t i v e mutual i n f o r m a t i o n v a l u e s b e t w e e n content words in corpora that are not e x t r e m e l y large, we havec o n s i d e r e d that a n y negative value to be 0. We a l s o set ](xl,x2) to 0 if
= 0 .
", "!
' ' P ( x , , x , )
Z =
Z
)× log.,
(2)
,o, , . ,
P ( x , ) P ( x , )
R a t h e r than e s t i m a t e the r e l a t i o n s h i p b e t w e e n words, we m e a s u r e the
m u t u a l i n f o r m a t i o n b e t w e e n classes. Let C,, C] b e the classes,
i.j=
0,1.2 ... N ; N d e n o t e s the n u m b e r of classes.Then a v e r a g e m u t u a l i n f o r m a t i o n b e t w e e n classes
01,
C 2,...,
C N
isp(c,,c,)
I~ = ~ ~ PC C,, C, ) x log::
(3)
,=, ,=,
P ( c , ) P ( c , )
2.1.2 The Basic Aigo~thm
T h e c o m p l e n i n g p r o c e s s is d e s c r i b e d as follows:
We split the v o c a b u l a r y into a b i n a r y tree. We o n l y c o n s i d e r one d i m e n s i o n n e i g h b o r .
# 1 : T a k e the whole words' in v o c a b u l a r y as one class and take this level " in the b i n a r y tree as 0. That is Level=0, Branch=0, C l a s s ( L e v e l , B r a n c h ) = V o c a b u l a r y Set. Then, L e v e l = L e v e l + l .
# 2 : C l a s s ( L e v e l , B r a n c h ) = C l a s s ( L e v e l - l , B r a n c h / 2 ) .
Old ~ = 0 .C l a s s ( L e v e l , B r a n c h + l ) = e m p t y . Select a w o r d w, E C l a s s ( L e v e l , B r a n c h ) # 3 : M o v e this w o r d to C l a s s ( L e v e l , B r a n c h + l ) .
C a l c u l a t e the ~(w,)
#4:Move this word b a c k to C l a s s ( L e v e l , B r a n c h ) .
If (all w o r d s in Class(Level,Branch) have b e e n selected), t h e n g o t o #5
else s e l e c t a n o t h e r u n s e l e c t e d w o r d w , E C l a s s ( L e v e l , B r a n c h ) to C l a s s ( L e v e l , B r a n c h + l ) , goto #3
# 5 : M o v e the w o r d h a v i n g M a x i m u m ( ~ ) from C l a s s ( L e v e l , B r a n c h ) to
Class(Level,Branch+l).-
#6:If ( M a x i m u m ( ~ ) > O l d ~ ) then
Old ~ = M a x i m u m ( ~ ) , S e l e c t a w o r d W E Class (Level,Branch), g o t o #3 # 7 : B r a n c h = B r a n c h + 2 .
If ( B r a n c h < 2 ~¢''¢' ) goto #2 # 8 : L e v e l = L e v e l + l , Branch=0;
If (Level< p r e - d e f i n e d classes number) g o t o #2; else g o t o end.
F r o m the a l g o r i t h m d e s c r b e d above, we c a n c o n c l u d e that the
c o m p u t a t i o n time is to be order
O ( h V 3)
for tree height h and v o c a b u l a r y size V to m o v e a w o r d from one class to another.If the h e i g h t of the b i n a r y tree is h, the n u m b e r of all p o s s i b l e
classes will be 2 h. D u r i n g the s p l i t t i n g process, e s p e c i a l l y at the b o t t o m of the b i n a r y tree, some classes m a y b e e m p t y b e c a u s e the
classes h i g h e r than t h e m can not be s p l i t t e d f u r t h e r more.
As m e n t i o n e d in Introduction, Brill (1993), a n d M c M a h o n ~1995) o n l y c o n s i d e r one d i m e n s i o n neighbor, w h i l e S c h u t z e (1995) c o n s i d e r 50 d i m e n s i o n s "neighbors. How long the d i m e n s i o n s n e i g h b o r s s h o u l d be indeed? For l o n g - d i s t a n c e bigrams m e n t i o n e d in Huang, et al. (1993) a n d R o s e f i e l d (1994), t r a i n i n g - s e t p e r p l e x i t y is low for the c o n v e n t i o n a l b i g r a m ( d = l ) , and it increases s i g n i f i c a n t l y as t h e y m o v e
t h o u g h W = 2,3,4 a n d 5. For" d = 6,...]0, t r a i n i n g - s e t p e r p l e x i t y r e m a i n e d at about the same level. Thus, H u a n g , X . - D . e t al. (!993) c o n c l u d e that some i n f o r m a t i o n i n d e e d exists in the m o r e distant p a s t but it is spread t h i n l y across the entire history. We do the test on Chinese in the same way. A n d s i m i l a r results are obtained. So, 50 is too long for d i m e n s i o n s and the search in s e a r c h i n g space is c o m p u t a t i o n a l l y prohibitive, a n d I is so small for d i m e n s i o n s that m u c h i n f o r m a t i o n
will be lost.
In this paper, we let d = 2.
so,
P(~), P(C,)and P(~,C/)
can be c a l c u l a t e d as follows:P ( C ) - - -
(4)
s,'~C:
P ( c , ) - - - (5")
•
mtc,I
(6)
P(C,, C, ) =
N,o,ol
d
w h e r e
N,o,,
I
is the total times of words w h i c h are in the v o c a b u l a r y o c c u r r i n g in the corpus.d is the c a l c u l a t i n g distance c o n s i d e r e d in the corpus.
N,,. is the total times of w o r d w o c c u r r i n g in the corpus
]V,~.,w: is the total times of words couple wtw 2 o c c u r r i n g in the corpus
w i t h i n the d i s t a n c e d.
2.2.2 Context-Sensitive Processing
In the works of Brill (1993), Brill,E. et al. u s e the sum of two
the other is to represent the word relation direction from the right to the left. The former is from the left to the right is the default
circumstance m e n t i o n e d in 2.1.2.
The similar idea about directional p r o p e r t y is p r e s e n t e d b y Dagan, et ai.(1995) also. Dagan, et al. (1995) defines a similarity metric of two words that can reflect the directional p r o p e r t y according to mutual information to determine the degree of simil~rity between two words. But the m e t r i c does not have transitivity. The intransitivity of the metric detex-mines this metric can not be u s e d in clustering words to equivalence classes.
To reflect the different influence of left neighbor and right
neighbor of the word, we introduce the p r o b a b i l i t y for each word w to every class. That is, for the classes p r o d u c e d b y the b i n a r y tree which represent the w o r d relation direction from the left to the
right, we distribute probability ~r(~Iw)for each word w corresponding
every class ~ , the probability ~ ( ~ l w ) reflect the degree the word w
belongs to class ~ . For the classes the binary tree which represent
the word relation direction from the right to the left produce,
Pw(~lw) is calculated likewise.
Mutual information can be explained as: the ability of dispelling the uncertainty of information source. A n d entropy of information is defined as the u n c e r t a i n t y of information source. So, the probability
word w which belongs to class ~ can be p r e s e n t e d as follows:
where
I(~,~)
is the mutual information between the class ~ and the iother class ~ w h i c h is in the same binary branch with ~ . S ( ~ ) is the
|
entropy of class ~ .So, 1- ~ denotes the probability that word w didn't belong to class I
That is, in the binary tree, ]-Pc, denotes the p r o b a b i l i t y of the
other branch class corresponding to ~ . Because the average mutual
information is little, it is possible that Pc, is less than
l-Pc.
To I avoid distributing the less probability to the w o r d assigned to thisclass than the p r o b a b i l i t y to the word not assigned to this class, we • distribute the p r o b a b i l i t y 1 to the word assigned to the class.
|
Thus, for each class in the certain level of the binary tree, we
multiple the probabilities either 1 or |- Pc, to its original l
probabilities, in w h i c h ~ is the other branch class opposite to the
J
class the word not b e l o n g i n g to.
The description on above is only word w belong to a certain class in I
certain level without consider the affection from its upper levels. To obtain the real p r o b a b i l i S y of word w belonging to certain class, all
belonging probabilities of its ancestors should be multiplied I
together.
The distribution of the probability is not optimal, but it reflects
~-'~P(~iW)
must b e n o r m a l i z e d b o t h for the l e f t - r i g h t a n d the right-leftresults. A n d the n o r m a l i z e d results of the l e f t - r i g h t a n d the right- left b i n a r y tree a l s o m u s t be n o r m a l i z e d together.
2.2.3 Probabilisfic BoSom-up C~ssesMerging
Since there is d i r e c t i o n a l p r o p e r t y b e t w e e n words, the t r a n s i t i v i t y will not be s a t i s f i e d b e t w e e n d i f f e r e n t directions. That is, if we
didn't i n t r o d u c e the p r o b a b i l i t y ~r(~lw) and P~(~lw), we w o u l d not merge the classes b e c a u s e there is no t r a n s i t i v i t y b e t w e e n the class in w h i c h w o r d r e l a t i o n is from the left to the right and the class in w h i c h w o r d r e l a t i o n is from the right to the left. For example, " ~ ] " ( " w e " ) a n d ~ i ~ . " ( " y o u ") are c o n t a i n e d in one class d e r i v e d by the l e f t - r i g h t b i n a r y tree, a n d o t h e r two words ~ ] " ( ~ y o u " ) and " ~ _ ~ " ( " a p p l e " ) b e l o n g to a n o t h e r class d e r i v e d f r o m r i g h t - l e f t b i n a r y tree. This do not m e a n that the words " ~ ] " ( " w e " ) a n d ~ " ( " a p p l e " ) b e l o n g to one class.
But w h e n we put f o r w a r d the probability, u n l i k e the i n t r a n s i t i v i t y of s i m i l a r i t y m e t r i c p r e s e n t e d b y Dagan, et al. (!995), the classes g e n e r a t e d b y t w o b i n a r y trees can be m e r g e d b e c a u s e the p r o b a b i l i t i e s can m a k e the "hard" i n t r a n s i t i v i t y "soft".
A l t h o u g h this t o p - d o w n s p l i t t i n g m e t h o d has the a d v a n t a g e we
m e n t i o n e d above, it has its obvious shortcomings. Magerman, (1994) describes these s h o r t c o m i n g s in detail. Since the s p l i t t i n g p r o c e d u r e is r e s t r i c t e d to be trees, as opposed to a r b i t r a r y d i r e c t e d graphs, there is no m e c h a n i s m for m e r g i n g two or m o r e n o d e s in the tree g r o w i n g process. That is to say, if we d i s t r i b u t e the words to the w r o n g classes f r o m global sense, we will not be able to a n y longer move it back. So, it is d i f f i c u l t to m e r g e the c l a s s e s o b t a i n e d b y left-right b i n a r y tree and r i g h t - l e f t b i n a r y tree d u r i n g the process of g r o w i n g tree. To solve this problem, we adopt the b o t t o m - u p m e r g i n g m e t h o d to the r e s u l t i n g classes.
A n u m b e r of d i f f e r e n t s i m i l a r i t y m e a s u r e s can be used. We choose to use r e l a t i v e e n t r o p y , also k n o w n as the K u l l b a c k - L e i b l e r distance(Pereira, et ai.1993; Brili,1993;). R a t h e r t h a n m e r g e two words, we merge the two classes which b e l o n g to the r e s u l t i n g classes g e n e r a t e d b y l e f t - r i g h t " b i n a r y tree and r i g h t - l e f t b i n a r y tree respectively, and select the m e r g e d class w h i c h can lead to m a x i m u m value of s i m i l a r i t y metric. This p r o c e d u r e can be done r e c u r s i v e l y until the d e m a n d e d n u m b e r of classes is reached.
Let P and Q be the p r o b a b i l i t y distribution. The K u l l b a c k - L e i b l e r distance from P to Q is d e f i n e d as:
D(PII Q) = ~ Pf w) log Pfw) (8)
,,,
Q(w)
The d i v e r g e n c e of P and Q is then defined as:
miv( P, Q) = D~(Q, P) = D( PIIQ)
+ D(QII P)
(9)
Pa(w1,w),
Pd(w, w2)
a n d Pa(W2,w), are d e f i n e d likewise. A n d letPtr(Cilwl),
Plr(Cilw2), Prt(O/[w,)amLd Prl(Ojlw2)
be the p r o b a b i l i t i e s of w o r d s w I a n d w 2 c o n t a i n e d in c l a s s e s C, a n d C~ in the l e f t - r i g h t a n d r i g h t - l e f t treesrespectively. Then, the K u l l b a c k - L e i b l e r d i s t a n c e b e t w e e n w o r d s w I
and w_, in the l e f t - r i g h t tree is:
t',,( w. .,1)e,. ( C, l w. )
D,,(w, II w.,) = ,,v~F-'Pa(w'w')t"~(C'lw))l°g
P,,(w,w,)P~,.(C~lw,_)
The d i v e r g e n c e of words w I and w 2 i n the l e f t - r i g h t tree is:
Div,,.(w,,
w 2 ) = D,,.(w,
II
w2 ) +
m,,(w.,ll
w,
)Similarly, the K u l l b a c k - L e i b l e r d i s t a n c e b e t w e e n words w I a n d w 2 in the r i g h t - l e f t tree is:
D,~(w, llw,_)= ~"~P,,.(w,w,)P,~(C, lw,)log
wGl"
w h e r e V is the v o c a b u l a r y .
P (w. w.)e. (C, lw.)
P,,(w.w._)e,,(C,l..,..)
We can then d e f i n e the s i m i l a r i t y of wl and w 2 as:
]
S ( ~1", . ~,': ) = ] - ~ { D ~ ' ~ ( w , . ~'~ ) + D i v ~ ( .'t . ~'~ ) } ( 1 O) -
S(w,,w:)
r a n g e s f r o m 0 t o 1, w i t hS(w,w)=l.
The c o m p u t a t i o n cost of this s i m i a r i t y is not high, for the c o m p o n e n t s of e q u a t i o n ( I 0 ) have been o b t a i n e d d u r i n g the e a r l y computation.
The n u m b e r of all p o s s i b l e classes is 2 h. D u r i n g the s p l i t t i n g process, e s p e c i a l l y at the b o t t o m of the b i n a r y tree, it m a y b e e m p t y for some c l a s s e s b e c a u s e the classes at h i g h e r level than it can not be s p l i t t e d f u r t h e r more a c c o r d i n g to the rule of m a x i m u m a v e r a g e m u t u a l information. The .number of the r e s u l t i n g classes c a n not be c o n t r o l l e d a c c u r a t e l y . So, we can define the n u m b e r of the d e m a n d i n g c l a s s e s in advance. As long as the n u m b e r of the r e s u l t i n g c l a s s e s is less than the p r e - d e f i n e d number, the s p l i t t i n g p r o c e s s w i l l be continued. W h e n the n u m b e r of the r e s u l t i n g c l a s s e s is l a r g e r t h a n the p r e - d e f i n e d number, we use the m e r g i n g t e c h n i q u e p r e s e n t e d above to
r e d u c e the n u m b e r until it is equal to the p r e - d e f i n e d number. The p r o c e d u r e c a n be d e s c r i b e d as follows: A f t e r we have m e r g e d two
c l a s s e s t a k e n f r o m the l e f t - r i g h t and the r i g h t - l e f t trees respectively, we u s e this m e r g e d class to r e p l a c e two o r i g i n a l c l a s s e s
respectively. T h e n we repeat this process u n t i l c e r t a i n step is reached. In this paper, we d e f i n e the n u m b e r of steps as e q u a l to the l a r g e r n u m b e r of the classes b e t w e e n two trees' r e s u l t i n g classes.
Finally, we m e r g e all r e s u l t i n g classes until the p r e - d e f i n e d n u m b e r
is reached.
This m e r g i n g p r o c e s s g u a r a n t e e d the p r o b a b i l i l t y to be n o n z e r o w h e n e v e r the w o r d d i s t r i b u t i o n s are. This is a u s e f u l a d v a n t a g e
3. Experimental Resul~ and Discussion
3.1Word Classification Results
W e use P e n t i u m 586/133MHz, 32M m e m o r y to calculate. The OS is W i n d o w s N T 4.0. A n d V i s u a l C++ 4.0 is our p r o g r a m m i n g language.
We use the e l e c t r i c news corpus n a m e d "Chinese One h u n d r e d k i n d s of n e w s p a p e r s - - - 1 9 9 4 " . The total size of it is 780 m i l l i o n bytes. It is not f e a s i b l e to do c l a s s i f i c a t i o n e x p e r i m e n t s on this o r i g i n a l corpus. So, we e x t r a c t a part of it w h i c h c o n t a i n the news p u b l i s h e d in April from the o r i g i n a l news texts.
To be convenient, the sentence b o u n d a r y markers, {
l, ? .... ; : ,} are r e p l a c e d b y only two s e n t e n c e b o u n d a r y markers: "! " a n d " " w h i c h denote the b e g i n n i n g a n d end of the s e n t e n c e or w o r d p h r a s e respectively.
The texts are s e g m e n t e d b y V a r i a b l e - d i s t a n c e a l g o r i t h m [ Gao, J. and Chen, X.X. (1996)]
We select four s u b c o r p o r a w h i c h contains 10323, 17451, 25130 and 44326 C h i n e s e words. The v o c a b u l a r y contains 2103, 3577, 4606 and 6472 w o r d s c o r r e s p o n d i n g l y . The results of the c l a s s i f i c a t i o n w i t h o u t i n t r o d u c i n g p r o b a b i l i t i e s can be s u m m a r i z e d in T a b l e I.
The c o m p u t a t i o n of m e r g i n g p r o c e s s is only equal to the s p l i t t i n g c a l c u l a t i o n in one level in the tree. From table I, we c a n find s u r p r i s e l y that the c o m p u t a t i o n time for r i g h t - l e f t is m u c h s h o r t e r than the time for left-right. But this is reasonable. In the p r o c e s s of left-right, the left b r a n c h contains more w o r d s t h a n the right branch. To m o v e each w o r d from the left b r a n c h to the right branch, we n e e d to m a t c h this w o r d t h r o u g h o u t the corpus. But w h e n we do the p r o c e s s of right-left, the left b r a n c h has less w o r d s t h a n the right. We only n e e d to m a t c h the small n u m b e r of words in the corpus. From this, we can k n o w that the p r e p r o c e s s e d p r o c e d u r e costs m u c h time.
The n u m b e r of e m p t y classes is i n c r e a s i n g w i t h the tree grows. Table II shows the n u m b e r of e m p t y classes in d i f f e r e n t levels in the left- right tree w h e n we p r o c e s s the s u b c o r p o r a c o n t a i n i n g 10323 words.
A l t h o u g h our m e t h o d is to calculate d i s t r i b u t i o n a l c l a s s i f i c a t i o n , it
still d e m o n s t r a t e s that it has p o w e r f u l p a r t - o f - s p e e c h functions.
T a b l e I. S u m m a r i z a t i o n of c l a s s i f y i n g four s u b c o r p o r a
Words in ~he Corpus
L e f t - r i g k t r e s u l t i n g c l a s s e s
R i g h t - l e f t R e s u l t i n g classes
P r e - d e f i n e d n u m b e r of classes
Time for l e f t - r i g h t
T i m e for r i g h t - l e f t
10,323 161 178 150 22 h o u r s 19 hours
17,451 347 323 300 2.4 days I.I days
25,330 642 583 500 5.1 days 2.7 days
1,225 600
' " I
Level 1
!empty
class 0
T a b l e II. The n u m b e r of e m p t y c l a s s e s
L e v e l Level Level Level Level Level
2 3 4 5 6
0 1 3 7 21 63
Level 8
123
Level 9
351
Some typical w o r d classes w h i c h is the part of r e s u l t s of s u b c o r p u s c o n t a i n i n g 17451 w o r d s are l i s t e d below. (Resulting c l a s s e s of left-
right b i n a r y tree) .
class !3:
~
~
~
~
~,~- ~
~
~
~
~
~
class ~ :
,~ ~
~
~
~ T
f@-~ ~
~
~
~
~ - ~
Class
96: _-'-~..
Jq
~ T "
~
H . ~
~
?~ ~,~ [~'~ :~.~ ~
~[~j
But some of classes p r e s e n t n o o b v i o u s p a r t - o f - s p e e c h category. Most
of t h e m c o n Z a i n only' v e r y small n u m b e r of words. This m a y c a u s e d b y the p r e d e f i n e d c l a s s i f i c a t i o n number. Thus, e x c e s s i v e or i n s u f f i c i e n t c l a s s i f i c a t i o n m a y be encountered. A n d a n o t h e r s h o r t c o m i n g is that a small n u m b e r of w o r d s in a l m o s t e v e r y r e s u l t i n g class d o e s n ' t b e l o n g to the p a r t - o f - s p e e c h c a t e g o r i e s w h i c h most of w o r d s in that class
b e l o n g to.
3.2 Use Word Classification Resul~ in Statistical Language Modefing
W o r d c l a s s - b a s e d l a n g u a g e m o d e l is m o r e c o m p e t i t i v e t h a n w o r d - b a s e d
l a n g u a g e model. It has far fewer parameters, thus m a k i n g b e t t e r u s e of t r a i n i n g data to s o l v e the p r o b l e m of data sparseness. We c o m p a r e w o r d c l a s s - b a s e d N - g r a m language model w i t h typical N - g r a m l a n g u a g e model
u s i n g perplexity.
P e r p l e x i t y (Jelinek, 1990a; M c C a n d l e s s , 1 9 9 4 ; ) is an i n f o r m a t i o n - t h e o r e t i c m e a s u r e for e v a l u a t i n g h o w well a s t a t i s t i c a l l a n g u a g e m o d e l p r e d i c t s a p a r t i c u l a r test set. It is an e x c e l l e n t m e t r i c for c o m p a r i n g two l a n g u a g e m o d e l s b e c a u s e it is e n t i r e l y i n d e p e n d e n t of h o w each language m o d e l f u n c t i o n s internally, a n d a l s o b e c a u s e it is v e r y simple to compute. For a g i v e n v o c a b u l a r y size, a l a n g u a g e m o d e l w i t h lower p e r p l e x i t y is m o d e l i n g l a n g u a g e m o r e a c c u r a t e l y , w h i c h will
g e n e r a l l y c o r r e l a t e w i t h lower e r r o r rates d u r i n g s p e e c h recognition. P e r p l e x i t y is d e r i v e d from the a v e r a g e log p r o b a b i l i t y that the language model a s s i g n s to e a c h w o r d in the test set:
~ = _ 1 x ~'~Jog2
P(wilw,,...,w,_,)
(11)
IV I--i
[image:10.612.80.557.35.420.2]b o u n d a r y marker. The p e r p l e x i t y is then 2 ~, S m a y be i n t e r p r e t e d as the a v e r a g e n u m b e r of bits of i n f o r m a t i o n n e e d e d to compress e a c h w o r d in the test set g i v e n that the language model is p r o v i d i n g us w i t h information.
We c o m p a r e the p e r p l e x i t y result of the N - g r a m l a n g u a g e m o d e l with
c l a s s - b a s e d N - g r a m language model. The p e r p l e x i t i e s P P of N - g r a m for w o r d and class are:
U n i g r a m for word: I,%"
¢xp(- ~ ,__~ In(P(~ )11
(12/
B i g r a m for word: | x
exp(- ~ ~ln(P(~ I~-, )11
(13)
1=1
Bigram f o r c l a s s 2
exp(--77~ln(P(~lC(w,))P(C(~)lC(~_t))) )
(14)
where w, d e n o t e s the ith w o r d in the corpus a n d C ( ~ ) denotes the
class that w, is a s s i g n e d to. N is the n u m b e r of words in the corpus.
P(C(wi)IC(w,_,))can
be e s t i m a t e d by:P(C(w, ), C(w,_,
))
P ( C ( w , ) l C ( w , _ , ) ) =
(151
N
where
P(C(~ ),C(w,_,
))
= X e(w,
)P(C(~ )~,
)P(C(~_,)I~
1
i=IN
P(C(w,_,)) = ~P(w,_t)P(C(w,_,)[~_,)
,=2
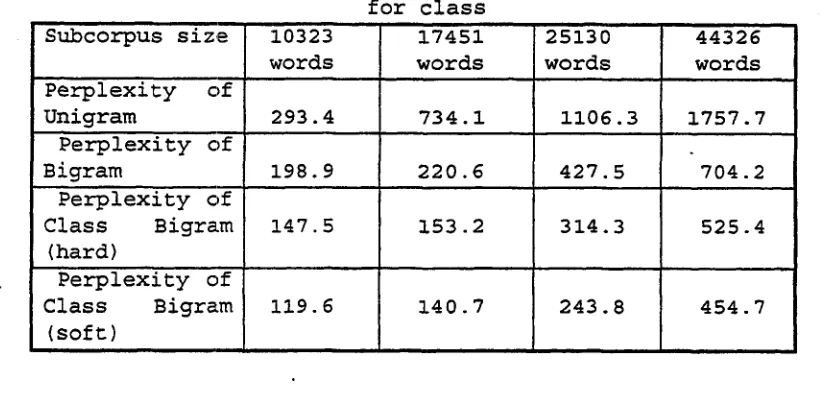
The p e r p l e x i t i e s P P b a s e d on d i f f e r e n t N - g r a m for w o r d a n d class are p r e s e n t e d in table III.
Note that we p r e s e n t "hard" c l a s s i f i c a t i o n and ~soft" c l a s s i f i c a t i o n results in w o r d class- b a s e d language model respectively. For p r o b a b i l i s t i c classification, we define the w o r d as b e l o n g i n g to
c e r t a i n class in w h i c h this w o r d has the largest p r o b a b i l i t y .
The t r a i n i n g corpus contains m o r e than 12,000 C h i n e s e words. A n d the
v o c a b u l a r y has I034 Chinese w o r d s w h i c h are most frequent. We u s e four s u b c o r p o r a m e n t i o n e d above as test sets.
A n a r b i t r a r y n o n z e r o p r o b a b i l i t y is g i v e n to all Chinese words and
1
symbols that do not e x i s t in the vocabulary. We set
P(w)- 2N
to thew o r d w w h i c h are not in the vocabulary. N is the n u m b e r of w o r d s in the t r a i n i n g corpus.
From table III, we can k n o w that p e r p l e x i t y of "hard" c l a s s - b a s e d b i g r a m is 28.7% lower than the w o r d - b a s e d bigram, while p e r p l e x i t y of the "soft" c l a s s - b a s e d b i g r a m is m u c h lower than the "hard" class-
T a b l e I I I . P e r p l e x i t y c o m p a r i s i o n b e t w e e n N - g r a m for w o r d a n d N - g r a m for class
S u b c o r p u s size 10323 443'26
words
P e r p l e x i t y of Class B i g r a m
(soft)
17451 w o r d s
25130
w o r d s words P e r p l e x i t y 0f
U n i g r a m 293.4 7 3 4 . 1 1106.3 1757.7
P e r p l e x i t y of
B i g r a m 198.9 220.6 427.5 704.2
P e r p l e x i t y clf
Class B i g r a m 147.5 153.2 314.3 525.4
(hard)
119.6 140.7 243.8 454.7
6. Conclusions
In this p a p e r we show a n e w m e t h o d for Chinese w o r d s c l a s s i f i c a t i o n . But it can b e a p p l i e d in m u l t i p l e l a n g u a g e too. It i n t e g r a t e s t o p - d o w n and b o t t o m - u p idea in word c l a s s i f i c a t i o n . Thus t o p - d o w n s p l i t t i n g t e c h n i q u e s can learn from b o t t o m - u p i d e a ' s s t r o n g p o i n t s to o f f s e t its o b v i o u s w e a k n e s s and keep the a d v a n t a g e of itself. Especially, u n l i k e o t h e r c l a s s i f i c a t i o n methods, this m e t h o d takes the c o n t e x t - s e n s i t i v e
i n f o r m a t i o n w h i c h most c l a s s i f i c a t i o n m e t h o d s do not c o n s i d e r into a c c o u n t and m a k e it reflect the p r o p e r t i e s of n a t u r a l l a n g u a g e m o r e
clearly. Moreover, the p r o b a b i l i t i e s are a s s i g n e d to the w o r d s to d e m o n s t r a t e h o w well a word b e l o n g s to classes. This p r o p e r t y is v e r y u s e f u l in w o r d c l a s s - b a s e d l a n g u a g e m o d e l i n g u s e d in s p e e c h recognition, for it allows the s y s t e m to h a v e several p o w e r f u l c a n d i d a t e s to be m a t c h e d d u r i n g recognition.
It, however, is important to c o n s i d e r the l i m i t a t i o n s of the method. The c o m p u t a t i o n a l cost fs v e r y high. The a l g o r i t h m ' s c o m p l e x i t y is cubic when we move one w o r d from one class to another. Also, the p r o b a b i l i t i e s the w o r d a s s i g n to e a c h class is not g l o b a l optimal. It r e f l e c t s the degree of a w o r d b e l o n g i n g to c l a s s e s a p p r o x i m a t e l y . A n d e x c e s s i v e or i n s u f f i c i e n t c l a s s i f i c a t i o n m a y o c c u r b e c a u s e the class n u m b e r is f i x e d artificially.
Re~rence
Bahl, L.R., Brown, P.F. DeSouza, P. V. and Mercer, R. L. (1989). A t r e e - b a s e d s t a t i s t i c a l language m o d e l for n a t u r a l l a n g u a g e s p e e c h recognition. I E E E T r a n s a c t i o n s on ASSP, 37(7): 1001-1008.
Brill, E. (1993). A C o r p u s - B a s e d A p p r o a c h To L a n g u a g e Learning.
Ph.D. thesis.
[image:12.612.105.516.98.297.2]I
I
I
I
I
I
I
i
I
I
I
Brown. P., Della Pietra, V., deSouza, P., Lai, J. and Mercer, R. (1992). Class-based n-gram models of natural language. Computational Linguistics 18, pp. 467-479.
Chang C.-H. and Chen, C.-D. (1993a). A Study on Integrating Chinese Word Segmentation and Part-of-Speech Tagging. Communications of COLIPS Vol 3, No i, pp 69-77.
Chang C.-H. and Chen, C.-D. (1993b). HMM-based part-of-speech tagging for Chinese corpora. Proceedings of the workshop on Very Large Corpora: Academic and Industrial Perspectives, pp.40-47, Columbus, Ohio, USA.
Chang C.-H. and Chen, C.-D. (1995). A Study on .Corpus-Based Classification of Chinese Words. Communications of COLIPS, Vol 5, No l&2, pp.l-7.
Church, K. W. and Mercer, R.L.(1993). Introduction to the special issue in computational linguistics using large corpora. Computational Linguistics 19, pp.l-24.
Cutting,D., Kupiec, J., Pederson, J., Sibun, P. (1992). A Practical Part-of-Speech Tagger. Applied Natural Language Processing, Trento, Italy, pp.133-140.
Dagan, I.,Marcus, S. and Markovitch,S. (1995). Contextual word similarity and estimation from sparse data Computer Speech and Language, pp. 123-152.
DeRose, S. (1988). Grammatical category disambiguation by
statistical optimization..Computational Linguistics 14, pp. 31-39. Finch, S.P. (1993). Finding Structure in Language, Ph.D. thesis, Centre for Cognitive Science, University of Edinburgh.
Gao, J. and Chen, X.X. (1996). Automatic Word Segmentation of Chinese Texts Based on Variable Distance Method. Communications of COLIPS, Vol 6, No.2.
Garside, R., Leech, G. and Sampson, G. (1987). The computational analysis of English: A corpus-based approach. Longman.
Huang, X.-D., Alleva, F., Hon, H.-W., Hwang, M.-Y., Lee, K.-F. and Rosenfeld, R. (1993). The SPHINX-II Speech Recognition System: An Overview. Computer Speech and Language, Vol 2, pp.137-148.
Hughes, J. (1994). Automatically Acquiring a Classification of Words. Ph.D. thesis, School of Computer Studies, University of Leeds.
Jardino, M. and Adda, G. (1993). Automatic word classification using
simulated annealing. Proceedings of ICASSP-93, pp. II:41-44.
Minneapolis, Minnesota, USA.
Jelinek, F.(1990a). Self-Organized language modeling for speech recognition. Readings in speech recognition, Alex Waibel and Kai-Fu Lee, eds, pp.450-506.
Jelinek, F., Mercer, R. and Roukos, S. (1990b). Classifying Words for improved Statistical Language Models. IEEE Proceedings of ICASSP' 90, pp.621-624.
Jelinek, F., Mercer, R. and Roukos, S. (1992). Principles of lexical language modeling for speech recognition. Advances in Speech Signal Processing, pp. 651-699, Mercer Pekker, Inc.
markov model. Computer Seech and Language, 6: 225-242.
Lee, H.-J. and Chang, .C.-H. (1992). A Markov language model in handwritten Chinese text recognition. Proceedings of Wordshop on Corpus-based Researches. and Techniques for Natural Language Processing, Taipei, Taiwan.
Lee, H.-J., Dung, C.-H., Lai, F.-M. and Chang Chien. C.-H.(1993). Applications of Markov language models. Proceedings of Wordshop on Advanced Information Systems, Hsinchu, Taiwan.
Lin, Y.-C., Chiang, T.-H. and Su, K.-Y. (1993). A preliminary study on unknown word problem in Chinese word segmentation. Proceedings of ROCLING VI, pp.l19-141, sitou, Nantou, Taiwan.
Magerman, D. M. (1994). Natural Language Parsing as Statistical Pattern Recognition. Ph.D. thesis.
McCandless, M. K. (1994). Automatically acquisition of language models for speech recognition. M.S thesis, Massachusetts Institute of Technology.
McMahon, J. and Smith, F.J. (1995). Improving Statistical Language Model Performance with A u t o m a t i c a l l y Generated Word Hierarchies.
Computational Linguistics.
McMahon,J. (1994). Statistical language processing based on self- organising word classification. Ph.D. thesis, The Queen's University of Belfast.
Merialdo, B. (1994). Tagging English Text with a Probabilistic Model. Computational Linguistics 20 (2), pp. 155-172.
Peng, T.-Y. and Chang, J.-S. (1993). A study on chinese lexical ambiguity - word segmentation and part-of -speech tagging. Proceedings
of ROCLING VI, pp.173-193.
Pereira, F. and Tishby, N. (1992). Distributional similarity, phase transitions and hierarchical" clustering. Working Notes: AAAI Fall symposium on Probabilistic Approaches to Natural Language, pp. 108- 112.
Pereira, F., Tishby, N. and Lee, L. (1993). Distributional
Clustering of English Words. Proceedings of the Annual Meeting of the ACL, pp. 183-190.
Pop, M. (1996). Unsupervised Part-of-Speech Tagging. the John Hopkins University.
Resnik, P. (1992). Wdrdnet and destributional analysis: A class- based approach to lexical discorvery. AAAI Wordshop on Statistically- based Natural Language Processing Techniques, July, pp. 56-64.
Rosenfeld, R. (1994). Adaptive Statistical Language Modeling: A Maximum Entropy Aproach. Ph.D. thesis.
Schutze, H. (1995). Distributional Part-of-Speech tagging. EACL95.
Wu, J., Wang, Z.-Y., Yu, F. and Wang, X. (1995). Automatic
Classification of Chinese texts. Jouznal of Chinese Information Processing. Vol. 9 No.4, pp.23-31.