2016 International Conference on Electronic Information Technology and Intellectualization (ICEITI 2016) ISBN: 978-1-60595-364-9
A Positive Region Based Incremental Attribute
Reduction Algorithm for Incomplete System
Fumin Ma, Jingwen Chen and Wei Han
ABSTRACT
The dynamic update of data in real application is one of the most important characteristics in current information age; the incremental attribute reduction for incomplete information system is accordingly becoming the focal point. Combining the rough set extensional model based on limited tolerance relation, a positive region based incremental attribute reduction algorithm for incomplete information system is developed. The experimental results show that this algorithm can achieve the dynamic update of attribute reduction rapidly and effectively when new objects are merged.
INTRODUCTION
In current information age, data increased explosively in every field. However, the collected data is valuable and meaningful only when the underlying useful information can be extracted. Rough set theory [1] is a powerful tool to extract useful information hidden in data, which captured much concern in the past decades. In many real-life applications, data sets have missing values. The classical rough set is not useful in the analysis of incomplete information system with missing values.
Some extensions of rough sets under incomplete information system have been introduced in the past decades. The popular models, including limited tolerance relation, attract more attention in the field of knowledge reduction for incomplete
_________________________
information systems [2-4]. In recently, the dynamic update of the data is one of the vital characteristics, accordingly, incremental attribute reduction, especially for the incomplete information system, has been became the focal point [2-8]. Focusing on the merging or deleting attributes in incomplete information system, a positive region based attribute reduction algorithm, using tolerance relation, was proposed in literature [4]. By introducing the concept of generalized decision, different cases with new object merging were analyzed in literature [3].
Combining the rough set extensional model based on limited tolerance relation, a positive region based incremental attribute reduction algorithm for incomplete information system is developed in this paper. The experimental results show that this algorithm can achieve the dynamic update of attribute reduction rapidly and effectively when new objects are merged.
PRELIMIMINARIES
In this section, we illustrate the main concepts of rough set theory, which are necessary for our further formulation.
Definition 1 (positive region) Given a decision system DT ( ,U CD V f, , ), for
C
B
, the B positive region of decision attribute D is defined as:
( ) { | , / ( ), / ( )}
B
Pos D Y YX XU IND D YU IND B .(1)
Definition 2 (attribute reduction) In system DT, PC, if PosP( )D PosC( )D and for cp, PosP{ }c ( )D PosC( )D , then P is a relative attribute reduction of C.
Definition 3 (limited tolerance relation) In incomplete information system DT,
A
B , the binary relation L, namely the limited tolerance relation, is defined as:
( , ) ( ( , ) ( , ) *) (( ( ) ( ) ) (( ( , ) *) ( ( , ) *) ( ( , ) ( , )))))
B b B B B
b B
L x y f x b f y b P x P y
f x b f y b f x b f y b
(2)
where, P xB( ) { | b b B f x b( , ) *} .
INCREMENTAL ATTRIBUTE REDUCTION ALGORITHM
Generalized Decision of Incomplete Information System
Definition 4 (generalized decision) Given an incomplete system DT, xU, the
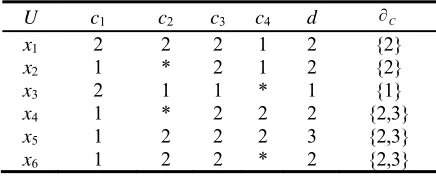
Take for example an incomplete decision system represented in Table I, which was used in literature [14], the generalized decision table is shown in Table II.
TABLE I. INCOMPLETE DECISION TABLE.
U c1 c2 c3 c4 d
x1 2 2 2 1 2
x2 1 * 2 1 2
x3 2 1 1 * 1
x4 1 * 2 2 2
x5 1 2 2 2 3
x6 1 2 2 * 2
TABLE II. GENERALIZED INCOMPLETE DECISION TABLE.
U c1 c2 c3 c4 d C
x1 2 2 2 1 2 {2}
x2 1 * 2 1 2 {2}
x3 2 1 1 * 1 {1}
x4 1 * 2 2 2 {2,3}
x5 1 2 2 2 3 {2,3}
x6 1 2 2 * 2 {2,3}
It can be seen that |C( ) | 1x means there are inconsistent objects in this class. So, all the objects in this class do not belong to PosC( )D . Therefore, given an incomplete system DT, for x U, xPosC( )D if and only if |C( ) | 1x .
For a new object x, if f x D( , ) C(XT xC( )), x is consistent with U under limited tolerance relation. For convenience, let PosC( ) | (D U{ })x be the positive region of
{ }
U x . PC is a reduction, if and only if Pos DP( ) | (U{ })x Pos DC( ) | (U{ })x ,
and P' P, PosP'( ) | (D U{ })x Pos DC( ) | (U{ })x .
Incremental Attribute Reduction Algorithm
Based on generalized decision, an incremental attribute reduction updating algorithm under limited tolerance relation is proposed, which fully considered the possible situations caused by new object merging.
Algorithm 1. Incremental attribute reduction algorithm for incomplete system. Input: incomplete system DT, a known reduction P and a new merged object x. Output: a updated attribute reduction P' for U{ }x .
Step 1: Based on limited tolerance relation, update the generalized decision for
{ }
[image:3.612.187.405.290.378.2]Step2: To judge whether x is consistent with U according to C. If|C( ) | 1x , go to step 3, else further to judge whether x is consistent with U according to P.
Step 2.1: if |P( ) | 1x , go to Step 2.2; else if |P( ) | 1x , that is to say x is consistent with U under relation L according to P, then let P'=P and go to step 4.
Step 2.2: let DT'', the limited tolerance class of x, according to P, denotes as the sub decision table, to compute the attribute reduction R of DT'', P'PR.
Step 3: considering that x is inconsistence with U according to attribute C, let
{ | ( C( ) C( )) C( ) C( )} Y y y L x Pos D y x
' { | ( ( )P C( )) C( ) C( )} Y y y L x Pos D y x
Step 3.1: if YY', go to step 3.2, else keep original attribute reduction result, let
P'=P, go to step 4 directly.
Step3.2: recomputed a reduction P' of U{ }x , and realize the reverse deletion
test for c P'. If Pos(P'c)( ) | (D U{ })x PosP'( ) | (D U{ })x
, then c is indispensable, else delete c from P'.
Step4: Output the reduction P'.
EXPERIMENTS ANALYSIS
Examples Analysis
For the purpose of describing in detail the process of algorithm, the table I is taken for example, an original attribute reduction result is P={c3, c4}.
(1) Given a new merging object x={2, * , 1, *, 1}. |C( ) | 1x can be easy obtained with limited tolerance relation, thus the new merged object x is consistent with U. In addition, |C( ) | |x P( ) | 1x , so, P is also a attribute reduction for U{ }x . (2) Given x={2, 1 , 2, *, 2}, |C( ) | 1x can be obtained with limited tolerance relation, x is consistent with U. however, |P( ) | 2 1x , that is to say, some other attributes, together with attribute set P to keep x consistent with { |y yLP}, need to be added. The final reduction, P={c1, c3, c4}, can be obtained for U{ }x .
(3) Given x={*, 1, 1, *, 2}. |C( ) | 2x can be obtained, thus x is inconsistent with U. Furthermore, x is inconsistent with x3 in PosC( )D . Thus Y ={x3}, and Y' ={x3} can be easy obtained. In addition, Pos D UC( )| ( { })x Pos D UP( )| ( { }) { , }x x x1 2 , For
'
P P
, Pos D UC( )| ( { })x Pos D UP'( )| ( { })x , so, P is a reduction of U{ }x .
reduction needs to be recomputed. Finally, {c1, c3, c4} can be obtained as a reduction.
Experiments Analysis
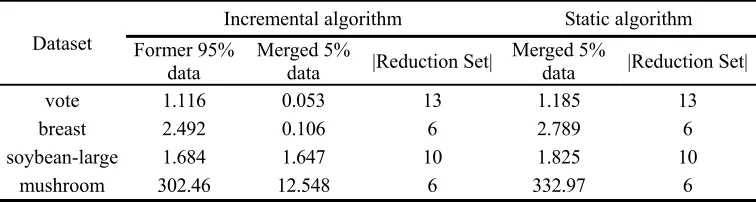
[image:5.612.116.481.319.400.2]In order to further validate the superiority of our algorithm, four incomplete UCI data sets, namely vote, mushroom, breast, and soybean-large data, are used to further illustrate the performance of the proposed algorithm. Some characteristic information is given in Table III as follows. For describing the dynamic characteristic, 95% of each data set is selected firstly to get the basic reduction, the remainder 5% as the dynamic merging data is used to get the incremental reduction. The results together with the computing time are recorded in Table IV. The results of static attribute reduction, where the basic data together with the merged data are used to compute repeatedly the reduction, are also recorded.
TABLE III. UCI DATA SETS.
Dataset condition attributes Number of Number of decision attributes Decision classes Number of objects
vote 16 1 2 435
breast 9 1 2 699
soybean-large 35 1 19 307
mushroom 22 1 2 8124
TABLE IV. REDUCTION RESULTS AND COMPUTATIONAL TIME (s).
Dataset
Incremental algorithm Static algorithm Former 95%
data
Merged 5%
data |Reduction Set|
Merged 5%
data |Reduction Set|
vote 1.116 0.053 13 1.185 13
breast 2.492 0.106 6 2.789 6
soybean-large 1.684 1.647 10 1.825 10 mushroom 302.46 12.548 6 332.97 6
It can be seen that there is obvious superiority for our incremental algorithm comparing with the static algorithm.
CONCLUSION
[image:5.612.108.486.439.540.2]incremental attribute reduction algorithm is developed in this paper. The validity of the proposed algorithm is demonstrated by the example and experiments results.
ACKNOWLEDGMENT
The authors acknowledge the support of the National Natural Science Foundation of China (61403184), Natural Science Foundation of Jiangsu Province, China (BK2012470), the Priority Academic Program Development of Jiangsu Higher Education Institutions, China (PAPD) and National Center for International Joint Research on E-Business Information Processing (2013B01035).
REFERENCES
1. Pawlak Z., Skowron A. “Rough sets: some extensions”. Information sciences, 2007, 177(1), pp. 28-40.
2. Clark P.G., Grzymala-Busse J.W., Rzasa W. “A comparison of two MLEM2 rule induction algorithms extended to probabilistic approximations”. Journal of Intelligent Information Systems, 2015, pp. 1-15.
3. Zhang Dedong, Li Renpu, Tang Xinting, et al. “An incremental reduct algorithm based on generalized decision for incomplete decision tables”. IEEE International Conference on Intelligent System and Knowledge Engineering, 2008, 1, pp. 340-344.
4. Shu Wenhao, Qian Wenbin. “An incremental approach to attribute reduction from dynamic incomplete decision systems in rough set theory”. Data and Knowledge Engineering, 2015, 100, pp. 116-132.
5. Yang Ming. “An incremental updating algorithm for attribute reduction based on improved discernibility matrix”. Journal of Computers, 2007, 30(5) , pp. 815-822.
6. Liu Dun, Li Tianrui, Zhang Junbo. “A rough set-based incremental approach for learning knowledge in dynamic incomplete information systems”. International Journal of Approximate Reasoning, 2014, 55(8), pp. 1764-1786.
7. Shu Wenhao, Shen Hong. “Incremental feature selection based on rough set in dynamic incomplete data”. Pattern Recognition, 2014, 47(12), pp. 3890-3906.