User Related Rare Sequential Topic Pattern Using Data Mining
M.Lakshmi Shireesha & N.Satyavathi1.Pg Scholar, Department Of Cnis, Vaagdevi College Of Engineering, Autonomous, Warangal 2. Assistant Professor,Department Of Cse, Vaagdevi College Of Engineering, Autonomous, Warangal,
Email id:[email protected] ; Email id:[email protected] ABSTRACT
Individuals utilize Internet for various purposes
e.g. long range informal communication,
blogging and so on concerning their unique
situation. This prompts dynamic change in
creation and circulation of archive streams over
the Internet. This would challenge the theme
demonstrating and development of individual
points. In this paper, we have proposed
Sequential Topic Patterns (STPs) mining over the
distributed client mindful report streams and
figure the issue of mining User Aware Rare
Sequential Topic Patterns(URSTPs) in archive
streams on the Internet to discover uncommon
clients. They are for the most part uncommon and
rare over the Internet. For URSTPs mining we
have to perform three stages: pre-preparing to
separate points, creating STPs, deciding URSTPs
by irregularity examination of STPs. The test can
be performed on both genuine circumstances
(Twitter) and manufactured informational
collections. In the proposed work, we have
concentrated on engineered datasets.
I. INTRODUCTION
Step by step the world is ending up increasingly
pervasive because of the sensational increment in
the prominence of the Internet administrations
viz. informal communication, web based business
sites, e-learning sites and so on. This creates and
spreads the gigantic number of archive streams
over the Internet. So to determine the specific
client's trademark from its archive stream is
urgent. Information mining is the first and
fundamental advance during the time spent
learning revelation in this specific circumstance.
Different information mining strategies are
accessible, for example, affiliation run mining,
successive example mining, shut example mining
and regular thing set mining to perform diverse
learning revelation undertakings from archive
streams. Progressively situation we go over the
small scale blog, for example, Twitter and so
forth where the clients are precipitously
distributing their statuses. These messages are
constant and report what client is feeling and
doing. So it can uncover clients attributes. Be that
as it may, it's hard to figure the genuine intension
substance data and worldly relations are required
for breaking down the client's qualities. There are
a few clients which can utilize the Internet for
strange purposes viz. online misrepresentation,
capturing movement, spreading psychological
oppression and so on. Their conduct is
unfortunate for society and henceforth
distinguishing such uncommon clients turn out to
be exceptionally fundamental. We plan the issue
of URSTPs digging for finding such irregular and
uncommon clients. It is important that the
thoughts above are additionally pertinent for
another kind of archive streams, called perused
record streams, where Internet clients act as
perusers of reports rather than creators. For this
situation, STPs can portray finish perusing
practices of perusers, so contrasted with
measurable techniques, mining URSTPs can
better find exceptional interests and perusing
propensities for Internet clients, and is
accordingly competent to give successful and
setting mindful suggestion for them. While, this
paper will focus on distributed archive streams.
Keeping in mind the end goal to discover
uncommon clients from their distributed report
streams, we ponder the connections among points
separated from their archive streams, particularly
the successive relations, and determine them as
Sequential Topic Patterns (STPs). Some of these
STPs are much of the time regular for every one
of the clients yet there are a few examples which
are uncommon and rare. These RareSTPs
(RSTPs) over the client mindful report streams
constitute the URSTPs which are utilized to
locate the uncommon clients
II. RELATED WORK Theme mining in report accumulations has been broadly examined in the
writing. The creators in [2] proposed Rare
Sequential Topic Patterns over report stream. In
this plaintext reports are created and coursed over
the Internet in progressively evolving structure. It
concentrates on point showing and ignored the
progressive cases of themes in document stream.
Likewise, traditional continuous illustration
mining figurings fundamentally focused on
progressive cases for deterministic data sets and
from now on not fitting for record streams with
theme vulnerability and unprecedented cases. Our
work can be contrasted and this work as we are
proposing the framework which finds the
uncommon examples purported STPs in archive
streams. Z. Zhao, D. Yan, W. Ng in their work
has concentrated on probabilistic consecutive
example mining in huge dubious databases.
Remote sensors, GPS are substantial and
questionable databases where information is
changing powerfully in enormous settings. The
quantities of clients are incredible in numbers
not. The information in this database application
is from now on extremely dubious as it changes
client to client promptly. The creators
in[3],proposed probabilistic consecutive example
mining in substantial indeterminate database. The
creator utilizes PrefixSpan calculation; the creator
inferred two new structures asU-PrefixSpan for
p-SFS mining and UPrefixSpan to maintain a
strategic distance from the issue of conceivable
world blast. Calculations can be checked by
probes genuine and manufactured datasets. X.
Yan, J. Guo, Y. Lan, and X. Cheng have
proposed demonstrate for short messages as bit
term subject model (BTM)in their work [4]. This
model is utilized to uncover themes inside the
short messages, for example, tweets and
messages and so forth rather than standard
subject models viz.LDA, PLSA. The writers
found that BTM beats LDA in short content and
standard writing.BTM unequivocally models the
word co-occasion cases to enhance the topic
learning. BTM uses the amassed cases as a piece
of the whole corpus for learning themes to deal
with the issue of lacking word religious
community plans at report tlevel. We do wide
examinations on certifiable short substance
collections. The results display that our approach
can discover more unmistakable and clear
themes, and in a general sense outmaneuver
standard procedures on a couple of evaluation
estimations. Additionally, we find that BTM can
beat LDA even exceptional works, exhibiting the
potential agreement and more broad usage of the
new point appear. The consecutive examples for
points in setting mindful music suggestion
framework are proposed by the creators N.
Hariri,B.Mobasher [5].In this point set of every
tune is at first controlled by an edge on the
subject probabilities got from LDA. At that point
visit subject based successive examples
happening among playlists are found to play next
tune. The tunes are played in framework as
indicated by client's specific situation. The
information created as for some ongoing
applications, for example, remote sensors;
moving article following and so on is dynamic.
The creators in [6], creator focuses on case
burrowing for questionable groupings and present
unremitting spatial examples with back to back
case with hole limitations. Such cases are basic
for exposure of learning given undetermined
course data. Creator propose a dynamic
programming approach for handling the repeat
probability of these illustrations, which has
coordinate time multifaceted nature, and Author
examine its embeddings into case detail
estimations using both broadness first interest and
significance initially chase techniques. Our
expansive exploratory examination exhibits the
built and genuine - world datasets. C.H. Mooney,
J.F. Ruddick the creators [7] have proposed
design digging for interim based occasions. They
proposed CTPrefixScan calculation for it. The
fascinating examples are mined by applying
different requirements on the occasions to get
Interesting examples and along these lines
themes. Grouping of occasions, things, or tokens
occurring in an asked for metric space show up
routinely in data and the need to distinguish and
dismember visit sub-arrangements is an ordinary
issue. Back to back Pattern Mining developed as
a subfield of data mining to focus on this field.
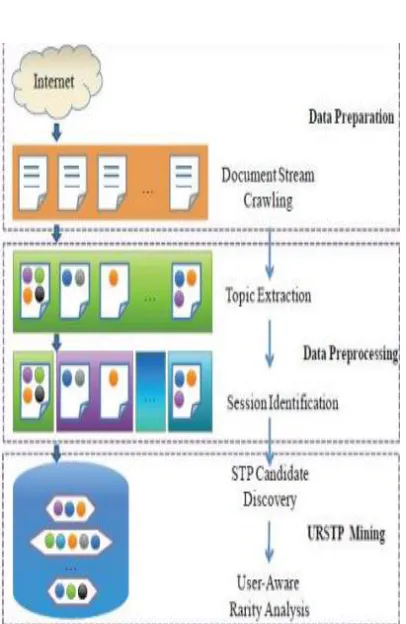
III. SYSTEM ARCHITECTURE AND WORKFLOW
A. System Architecture: In the proposed framework, the clients can join or sign in by
entering their points of interest. The framework
administrator can deal with the clients' entrances
with their subtle elements and certifications in
storehouse. In this setting we are utilizing printed
records as archive streams which the client can
refresh and distribute from its side. Framework
administrator can transfer these to the server or
database in encoded shape once the client has
presented this. The client of framework can
perform different inquiry operations by utilizing
distinctive pursuit key characteristics. The
outcomes are recovered and shown to the client
as needs be. Among the list items the themes are
extricated from the record streams distributed by
particular clients. These subjects are utilized to
decide the conduct of clients and if certain
occasional examples watched it will then assign
the uncommon clients.
Fig. 1 System Architecture
B. Mining Workflow :
In our proposed work we have to mine RSTPs
over client mindful report stream called
URSTPs[1]. It includes basically three stages as
archive streams creeping, pre-preparing to change
into subject level report stream and mining RSTP
sover client mindful record streams. The
operations are expressed underneath. • Document
Stream Crawling: It creeps the literary reports
and go about as info stream for point extraction. •
crept archive stream by specific calculations to
frame the theme level record stream.
Session Identification: In this topic level document streams are mapped to different
sessions.
Fig 2. Mining Workflow
STP candidate discovery: The sessions contain the topic level document streams for different
users. In this step the STPs are identified for
particular user.
RSTPs mining: This step deals with RSTPs mining. These are very rare and infrequent
patterns which are used to detect rare users.
IV.PSEUDO CODE A. System Operations:
Step 1: Sign up or Sign in done by user by entering its details or credentials respectively.
Step 2: System admin module will update the entries for new users.
Step 3: Users publishes document streams. Step 4: System admin uploads document streams published by users.
Step 5: Users can view results by various search key attributes such as date, name etc.
Step 6: Users can find out rare users.
These steps shows the operations that system can
perform from sign in or sign up to retrieving
results according to users query. The results can
be based on various attributes passed by the users
and finally can return rare users.
B. URSTP Mining:
Step 2: Extract Sequential Topic Patterns (STPs). Step 3: Rarity analysis of STPs from derived sessions. Step 4: Discover Rare Sequential Topic
Patterns (RSTPs) from STPs.
Step 5: Identify rare users from RSTPs. The above steps briefly show the mining workflow.
V CONCLUSION AND FUTURE WORK Information disclosure by different information
mining procedures in reports streams is essential.
Points are extricated in report streams and by
theme displaying the successive relationship is set
up to decide Sequential Topic Patterns (STPs).
There are extremely uncommon extraordinary
examples called Rare Sequential Topic Patterns
called RSTPs. Mining RSTPs over client mindful
report stream (URSTPs) is testing errand as
clients distributed the archive streams .so as to
discover uncommon clients from its distributed
record streams over the Internet is troublesome.
So by mining RSTPs from the distributed client
mindful report streams (URSTPs) we can
discover uncommon clients. The future work
comprises of utilizing predefined word references
for RSTPs assigning anomalous clients. On the
off chance that examination of found RSTPs by
existing framework to that of lexicons' entrances
surpasses some limit then framework
administrator can piece such clients.
Notwithstanding this future work will comprise
of describing client's conduct by mining RSTPs
over its perused/surfed report streams and
planning proposal framework.
REFERENCES
1. Jiaqi Zhu, Kaijun Wang, Yunkun Wu, Zongyi
Hu, “Mining User Aware Rare Sequential Toppic
Patterns in Document Streams”, IEEE
Transactions on Knowledge and Data
Engineering,vol.28, no. 2, pp.1790-1804,2016.
2. Z. Hu, H.Wang, J. Zhu, M. Li, Y. Qiao, and C.
Deng, “ Discovery of rare sequential topic patterns in document stream”, in Proc.SIAM SDM’14, pp. 533-541,2014.
3. Z. Zhao, D. Yan, and W. Ng, "Mining
probabilistically frequent sequential patterns in
large uncertain databases”, IEEE Trans.
Knowledge Data Eng., vol. 26, no. 5, pp.
1171-1184, 2014.
4. X. Yan, J. Guo, Y. Lan, and X. Cheng, “A
biterm topic model for short texts”, in Proc. ACM
WWW’13, pp. 1445-1456,2013.
5. N. Hariri, B. Mobasher, and R. Burke,
6. Y. Li, J. Bailey, “ L. Kulik, and J. Pei, Mining
probabilistic frequent spatio-temporal sequential
patterns with gap constraints from uncertain
databases”, in Proc. IEEE ICDM’13, pp.
448-457,2013.
7. C. H. Mooney and J. F. Roddick, “Sequential
pattern mining - approaches and algorithms”,
ACM Comput. Surv., vol. 45, no. 2, pp. 19:1-
19:39, 2013.
8. T. Bernecker, H.-P. Kriegel, M. Renz, F.
Verhein, and A. Zuefle, “Prob-abilistic frequent itemset mining in uncertain databases”, in Proc. ACM SIGKDD’09, pp. 119-128,2009.
9. Somesh D. Kalaskar, Dr.Archana Lomte, “A
survey on User-Aware STPs in Document
Streams” ,International Journal of Innovative
Re-search In Computer And Communication
Engineering(IJIRCCE),vol. 4,no.
12,pp:21016-21021,2016.
10. K. Chen, L. Luesukprasert, and S. T. Chou,
“Hot topic extraction based on timeline analysis
and multidimensional sentence modeling, IEEE
Trans. Knowl. Data Eng.”, vol. 19, no. 8, pp.
1016-1025, 2007.
11. J. Han, J. Pei, B. Mortazavi-Asl, Q. Chen, U.
Dayal, and M. Hsu, “FreeSpan: frequent
pattern-projected sequential pattern mining”, in Proc.