LEABHARLANN CHOLAISTE NA TRIONOIDE, BAILE ATHA CLIATH TRINITY COLLEGE LIBRARY DUBLIN OUscoil Atha Cliath The University of Dublin
Terms and Conditions of Use of Digitised Theses from Trinity College Library Dublin
Copyright statement
All material supplied by Trinity College Library is protected by copyright (under the Copyright and Related Rights Act, 2000 as amended) and other relevant Intellectual Property Rights. By accessing and using a Digitised Thesis from Trinity College Library you acknowledge that all Intellectual Property Rights in any Works supplied are the sole and exclusive property of the copyright and/or other I PR holder. Specific copyright holders may not be explicitly identified. Use of materials from other sources within a thesis should not be construed as a claim over them.
A non-exclusive, non-transferable licence is hereby granted to those using or reproducing, in whole or in part, the material for valid purposes, providing the copyright owners are acknowledged using the normal conventions. Where specific permission to use material is required, this is identified and such permission must be sought from the copyright holder or agency cited.
Liability statement
By using a Digitised Thesis, I accept that Trinity College Dublin bears no legal responsibility for the accuracy, legality or comprehensiveness of materials contained within the thesis, and that Trinity College Dublin accepts no liability for indirect, consequential, or incidental, damages or losses arising from use of the thesis for whatever reason. Information located in a thesis may be subject to specific use constraints, details of which may not be explicitly described. It is the responsibility of potential and actual users to be aware of such constraints and to abide by them. By making use of material from a digitised thesis, you accept these copyright and disclaimer provisions. Where it is brought to the attention of Trinity College Library that there may be a breach of copyright or other restraint, it is the policy to withdraw or take down access to a thesis while the issue is being resolved.
Access Agreement
By using a Digitised Thesis from Trinity College Library you are bound by the following Terms & Conditions. Please read them carefully.
S alien cy D eterm in a tio n for C o m p u ter
G raphics: A n E x p erim en ta l A p p roach
A Thesis
S ubm itted to the Office of G raduate Studies of
Trinity College Dublin in Candidacy for the Degree of
Doctor of Philosophy
December, 2005
TRINITY COLLEGE 1 5 MAY 20U6
D ecla r a tio n
This thesis has not been subm itted as an exercise for a degree at any other University. Except where otherwise stated, the work described herein has been carried out by the author alone. This thesis may be borrowed or copied upon request with the permission of the Librarian, Trinity College, University of Dublin. The copyright belongs jointly to the University of Dublin and Sarah Howlett.
A cknow ledgem ents
I am extremely grateful to my supervisor, Carol O ’Sullivan, for giving me the opportunity to do my PhD. I really appreciate all her help and ideas over the past three years. I ’d also like to thank all the “wonderful” people I have m et in the Image Synthesis Group, Richard for his help with the hard stuff and everybody who took p art in my experiments.
I ’d like to acknowledge my house mates, because they made me, in order of preference; Anne S., Louise and Nicola. My friends; Anne H. (my walking buddy), Helen and Jemiy (the crazies from Ballylaiiders) and not forgetting Caitriona. For friends who d idn ’t get a mention, you should probably try a bit harder.
A bstract
111 the com puter graphics reahn complex objects are abundant, b u t often need to be simplified in order to be displayed interactively. As the hum an visual system is far from flawless, advantage can be taken of its weaknesses by using perceptually adaptive graphics during the rendering of images or anim ations. In this thesis, we a tte m p t to establish if visual fidelity can be improved by em phasising the detail of salient p arts of models, found with an eye-tracking device, at the expense of un im p ortant areas. In an extension to this, we com pared the effect of tasks on eye-movemerits in a real and virtual environment.
To begin with, we considered the problem of determ ining feature saliency for 3D objects and describe a series of experim ents th a t exam ined if salient features existed and could be predicted in advance. To find these salient aspects an eye- tracking device was used to capture hum an gaze data. In general, results implied th a t th e heads of natural objects were especially salient features. Following this, we investigated if the visual fidelity of simplified polygonal models could be im proved by em phasising the detail of salient features identified in this way. In the evaluation of visual fidelity a set of nam ing time, m atching tim e and forced-choice preference experim ents were carried out. We found th a t perceptually weighted simplification led to a significant increase in visual fidelity for th e n atu ral objects at th e lower levels of detail (LOD), however, in the case of the m an-m ade artifacts the opposite was true.
objects, b ut our results showed th a t saliericy prediction for synthetic objects is more difficult, perhaps because it is more strongly affected by non-passive tasks th a t are more related to the objects.
Extending upon this, the next natural step would be to investigate w hat con trols the salient features of man-m ade artifacts. Moreover, a large quantity of psy chology research points to such prom inent features being defined by the current task. Unfortunately, before these insights can be applied to com puter graphics research, the differences between the effects of tasks in a real and virtual setup have to be recognised.
As a step towards finding salient features of m an-m ade artifacts, the latter p art of thesis concerns the framework we built, which was designed to allow the com par ison of task performance in real and virtual environments. Realistic graphics, back projection, haptics and rapid prototyping were used to m atch the virtual scene to the real scene. Some placement tasks were carried out which were evaluated using eye-tracking. Prelim inary findings established th a t atten tio n differs between the real and virtual worlds. From analysis of the video overlay and the average fixa tion duration found, it is clear th a t eye-movements are more constrained in virtual circumstances than in the real world setup. In the virtual scenario atten tio n is consumed far more by the object currently being m anipulated.
In this thesis, we experim entally show th a t the visual fidelity of n atural objects can be preserved by emphasising their salient features a t the expense of unim por ta n t areas. We hope th a t our results will be insightful to others performing mesh simplification. In addition, the framework developed should be a helpful tool for the exam ination of eye-movements during tasks. The prelim inary experim ents suggest th a t there is potential here and th a t further exam ination of tasks in a real
R ela ted P u b lica tio n s
1. “A framework for comparing task performance in real and virtual scenes” , S. Howlett, R. Lee, and C. O ’Sullivan. In A PG V ’05: Proceedings of the symposium on Applied perception in graphics and visualisation, 2005.
2. “Predicting and evaluating saliency for simplified polygonal models” , S. Howlett, J. Hamill, and C. O ’Sullivan. In ACM Transactions on Applied Perception, 2005.
3. “An experim ental approach to predicting saliency for simplified polygonal models” , S. Howlett, J. Hamill, and C. O ’Sullivan. In A PG V ’04: Proceed ings of the symposium on Applied perception in graphics and visualisation, pages 57-64, 2004.
4. “Perceptually A daptive G raphics” , C. O ’Sullivan, S. Howlett, Y. Morvan, R. McDonnell and K. O ’Conor. Eurographics 2004, S tate of the A rt reports, September 2004.
5. “Saliency determ ination for polygonal simplification” , S. Howlett, J. Hamill, and C. O ’Sullivan. Poster in European Conference on Eye Movements, 2003.
C ontents
1 In tr o d u ctio n 1
1.1 M o tiv a tio n ... 1
1.2 O verview ... 2
1.2.1 M ethodology ... 4
1.2.2 C ontribution ... 9
1.2.3 Sum m ary of C hapters ... 10
2 A tte n tio n , E y e-tra ck in g an d Tasks 12 2.1 In tr o d u c tio n ... 12
2.2 H uman v i s i o n ... 13
2.2.1 In tro d u c tio n ... 13
2.2.2 The Imman e y e ... 13
2.2.3 Working of the e y e ... 15
2.2.4 E y e-m o v em e n ts... 16
2.2.5 Top-down and bottom -up a t t e n t i o n ... 16
2.2.6 Visual a tte n ti o n ... 17
2.2.7 Change blindness and inattentional blindness ... 18
2.2.8 D is c u s sio n ... 18
2.3 E y e-track in g ... 19
2.3.1 In tro d u c tio n ... 19
2.3.3 Focus plus context s c r e e n s ... 21
2.3.4 A ttentive user interface techniques ... 22
2.3.5 D isc u ssio n ... 23
2.4 Task p e rfo rm a n c e ... 23
2.4.1 In tro d u c tio n ... 23
2.4.2 Familiar t a s k s ... 24
2.4.3 Block-copying t a s k s ... 26
2.4.4 Driving t a s k s ... 26
2.4.5 Additional task f i n d i n g s ... 27
2.4.6 D isc u ssio n ... 27
2.5 Tasks in graphics and perception ... 28
2.5.1 In tro d u c tio n ... 28
2.5.2 Selective rendering during t a s k s ... 28
2.5.3 Performance gains during t a s k s ... 31
2.5.4 Tasks in virtual e n v iro n m e n ts ... 32
2.5.5 D isc u ssio n ... 33
2.6 Concluding comments ... 33
3 S im p lifica tio n and V isu a l F id e lity 35 3.1 In tro d u c tio n ... 35
3.2 Simplification and levels of d e t a i l ... 36
3.2.1 In tro d u c tio n ... 36
3.2.2 Level of detail (LOD) techniques and related w o r k ... 37
3.2.3 Geometric s im p lific a tio n ... 39
3.2.4 User defined s im p lific a tio n ... 40
3.2.5 D isc u ssio n ... 42
3.3.3 Simplification driven by perceptual r n c tr ic s ... 46
3.3.4 Predicting f i x a t i o n ... 48
3.3.5 D isc u ssio n ... 49
3.4 S a l i e n c y ... 49
3.4.1 In tro d u c tio n ... 49
3.4.2 Previous research on saliency ... 50
3.4.3 Fixation metrics we u s e d ... 52
3.4.4 D isc u ssio n ... 53
3.5 Measures of visual f i d e l i t y ... 53
3.5.1 In tro d u c tio n ... 53
3.5.2 A utom atic fidelity evaluation ... 53
3.5.3 Experim ental fidelity e v a lu a tio n ... 54
3.5.4 Experim ental measures of visual fidelity we u s e d ... 56
3.5.5 D is c u s sio n ... 56
3.6 V irtual e n v iro n m e n ts ... 57
3.6.1 In tr o d u c tio n ... 57
3.6.2 Benefits and limitations of virtual e n v iro rm ie n ts ... 57
3.6.3 D is c u s sio n ... 58
3.7 Concluding corrunents ... 59
4 P e r c e p tu a lly G u id ed S im p lifica tio n 61 4.1 I n tr o d u c tio n ... 61
4.2 A pparatus (Eye-tracking d e v ic e )... 63
4.3 P articipants and a p p a r a tu s ... 65
4.4 M ethod ... 67
4.5 R e s u lts ... 69
4.6 Modified quadric error m e t r i c ... 76
4.6.1 Quadric error metric and m o d ific a tio n s... 76
4.7
Concluding comments ...
79
5 E v a lu a tio n 80
5.1
In tro d u c tio n ...
80
5.2
Finding the naming t i m e s ...
81
5.2.1 In tro d u ctio n ...
81
5.2.2 Participants and ap p aratu s...
82
5.2.3 Method ...
84
5.2.4 R esu lts...
85
5.2.5 D iscussion...
89
5.3
Acquiring the picture-picture matching tim e s ...
89
5.3.1 In tro d u ctio n ...
89
5.3.2 Participants and a p p aratu s...
90
5.3.3 Method ...
91
5.3.4 R esu lts...
93
5.3.5 D iscussion...
97
5.4
Forced-choice preferences experim ents...
98
5.4.1 In tro d u ctio n ...
98
5.4.2 Participants and a p p aratu s...
99
5.4.3 Method ...
100
5.4.4 R esu lts...
102
5.4.5 D iscussion...
104
5.5
Concluding comments ...
105
6 V a lid a tio n 107
6.1
In tro d u ctio n ...
107
6.2
Background on face ‘pop-out’ ...
107
6.3
Validation e x p erim en ts...
110
6.3.3
Method ...
112
6.3.4
R esu lts...
113
6.4
Concluding comments ...
122
7 C o m p a r in g T ask P erfo rm a n ce in R ea l and V ir tu a l S cen e s 125
7.1
Im p lem e n ta tio n ...
125
7.1.1
In tro d u ctio n ...
125
7.1.2
Real env iro m nent...
126
7.2
Virtual environment ...
128
7.3
Preliminary e x p e rim e n ts...
132
7.3.1
Participants and s t i n m l i ...
132
7.3.2
Method ...
132
7.3.3
Preliminary r e s u l t s ...
133
7.3.4
Concluding comments ...
137
8 C o n c lu sio n s and F u tu re W ork 139
8.1
Summary ...
139
8.2
L im ita tio n s ...
142
8.3
Future w o r k ...
143
List o f Figures
1.1 Predicting, evaluating and validating saliency for simplified polyg onal m odels... 6 1.2 Building a framework to examine task perform ance in real and
virtual scenes... 8
2.1 The hum an eye... 14 2.2 EyeLink II eye-tracker with scene cam era... 19 2.3 A Focus Plus Context Screen. (Image from [BDDG03] courtesy of
Andrew T. Duchowski.) ... 22 2.4 A selective quality image, whereby it is mostly rendered a t a low
LOD except for the visual angle of the fovea (2 degrees) centred on each teapot. (Image from [CCW03] courtesy of Alan Chalm ers.) . 29 2.5 K alabsha tem ple scene - high quality image on the left and on the
right, w hite objects show the task quality areas and the surround ing w hite circles show the selective quality areas. (Image from [SCCD04] courtesy of Alan C h a l m e r s .) ... 30 2.6 A schem atic view of W atson’s placement experim ents - two pedestals
3.1 The ideal instantaneous image th a t reflects th e latest input is shown in silhouette (coloured outlines). The left image is coarsely sam pled, representing some spatial errors. The right image is finely sampled but as a result is quite late. The coarsely sampled burmy actually represents lower dynam ic visual error. (Image from [WLWD03] courtesy of David L u e b k e .)... 38 3.2 Reducing sem antic blurring of th e head. Original cow on left(10,000
faces), autom atically simplified cow in middle (588 faces). M anu ally improved cow on right (588 faces). (Image from [LWOl] cour tesy of Ben W a t s o n . ) ... 40 3.3 Reducing functional blurring. Here, the entire horse is covered with
texture, but there is a strong colour discontinuity in the texture. The last two models have the same rmmber of faces, the middle produced by qslim, the right with semisimp.(Image from [LWOl] courtesy of Ben W a ts o n .)... 40 3.4 A view presented in the second experiment. Here th e periphery uses
the 20 x 15 LOD, while the lowest contrast background is used. The central area is (always) displayed at the highest HMD resolution. Four distractors are shown. (Image from [WWH04] courtesy of Ben W a ts o n .)... 45 3.5 Original Stanford Bunny (69,451 faces) and a simplification by Lue
bke and Hallens perceptually driven system (29,866 faces) (Image from [LHOlb] courtesy of David L u e b k e .)... 47 3.6 Human (left) and artificial (right) scanpaths. (Image from [MD02]
courtesy of Andrew T. D u c h o w sk i.)... 49 3.7 One set of stimuli from W atson’s experiment: Original (top),
4.1 T he initial SMI EyeLink eye-tracking device... 63
4.2 T he new EyeLirik II eye-tracker w ith scene cam era and setup screen. 64 4.3 T he EyeLink II setup screen... 65
4.4 A subset of the natural objects used... 66
4.5 A subset of the man-made artifacts used... 66
4.6 A subset of the animal, fish, car and gear models used... 67
4.7 An exam ple of a participant performing the saliency determ ination experim ent... 68
4.8 Results from the saliency experiment (white representing the great est rmmber); the total length of fixations on the familiar natural objects... 70
4.9 Results from the saliency experiment (white representing the great est number): the duration of the first fixations on the man-rnade artifacts... 71
4.10 Results from the saliency experim ent (white representing the great est number): the total immber of fixations on the unfam iliar objects in the second se t... 72
4.11 Images of the Video Curvid Overlay of one participant on a car o b ject... 73
4.12 Images of the Video Curvid Overlay of one participant on a fish o b ject... 74
4.13 Images of the Video Curvid Overlay of one participant on an anim al o b ject... 75
4.14 P air C o n tr a ctio n - Selected Vertices are contracted to a single point. Shaded Triangles become degenerate and are removed. . . . 76
5.1 N atural objects simplified to 5% LOD using the original (1st row) and modified (2nd row) simplification approach. M an-m ade a rti facts simplified to 5% LOD using the original (3rd row) and modi
fied (4th row) simplification approach... 82
5.2 N atural object simplified to 2% LOD using the original (1st row) and modified (2nd row) simplification approach. M an-m ade arti facts simplified to 2% LOD using the original (1st row) and modified (2nd row) simplification approach... 83
5.3 An exam ple of a participant performing the nam ing tim e experim ent. 85 5.4 Naming tim es for the n atu ral objects... 88
5.5 An exam ple of a participant performing the m atching tim e experi m en t... 92
5.6 Com paring the average m atching times for the anim al models. . . 95
5.7 Com paring the percentage of correctly m atched anim al models. . 96
5.8 Screen shots of trials from the web-baised forced-choice preference experim ents... 99
5.9 An exam ple of a participant performing the forced-choice preference experim ent... 101
5.10 Percentage preferences for th e natural objects... 102
5.11 Percentage preferences for th e m an-m ade artifacts... 103
5.12 Percentage preferences for th e fish objects... 103
6.1 Fixation maps of all fixations for some n atural objects in the nam ing tim e experim ents... 114
6.2 Fixation maps of all first fixations for some n atu ral objects in the nam ing tim e experim ents... 115
6.4 Fixation maps of all fixations for some m an-m ade objects in the naming tim e experim ents... 117 6.5 Fixation maps of all fixations for the matching tim e experiments
for some animal objects... 118 6.6 Fixation maps of all fixations for the m atching tim e experim ents
for some fish and gear objects... 119 6.7 Fixation maps of all fixations for the forced-choice experim ents for
some animal objects... 121 6.8 Fixation maps of all fixations for the forced-choice experim ents for
some man-m ade (1st row) and fish objects (2nd and 3rd row). . . 122
7.1 Real environm ent... 127 7.2 V irtual environm ent... 129 7.3 Projected virtual environment (front projected onto a white wall
to produce a higher quality photograph) with the P hantom haptic device... 131 7.4 Comparing fixation duration in the real and virtual world... 134 7.5 Com paring saccade am plitude in the real and virtual world. . . . 135 7.6 The effects of task type on saccade am plitude... 135 7.7 The effects of task type on fixation d uration... 136
List o f Tables
5.1 The effects of sirnphfication level on the nam ing tim e results. . . 87 5.2 The effects of simplification level on the num ber of errors in the
nam ing tim e experim ent... 87 5.3 The effects of object type and simplification type on the naming
tim e results... 88 5.4 The effects of simplification level on th e m atching tim e... 94 5.5 The effects of simplification level on the number of correctly m atched
objects... 94 5.6 The effects of simplification type on the results for m atching time. 95 5.7 The effects of simplification type on the results for the number of
correctly matched objects... 96 5.8 The significant effects of simplification type on the preferences (All
P-values < 0.05)... 104
C hapter 1
In trod u ction
1.1
M o tiv a tio n
The development of interactive graphics has brought with it a need for techniques to manage the cost of rendering. There is a plentiful supply of complex polygonal meshes currently available in com puter graphics, therefore, highly detailed scenes can be created. Unfortunately, for interactive applications, lag is not an option as it degrades hum an performance [MW93], so the complexity of these scenes has to be controlled in order to save on the am ount of com putational power needed. Often, highly detailed scenes have to be simplified in order to be displayed in real time. The m ajor challenge is in m aintaining visual fidelity under simplification. Simplifying models in these scenes based upon geometric properties alone may not be adequate if their distinguishing characteristics are rapidly lost, so, when a low polygon count is necessary other approaches need to be examined. One such area is perceptually adaptive graphics, where knowledge of the hum an visual system and its lim itations are exploited during the rendering of images and anim ations.
to coiriinoii belief a fully detailed representation of the world around us is not kept in visual memory and only the currently attended objects are stored in any great detail. Although we have the impression of high-resolution over the entire visual field, vision is sharpest only in the fovea, therefore, the point of gaze is closely related to the course of attention and perception. The eyes are moved toward areas where high-acuity, central vision is required or toward objects of interest to th e current task. W hen tasks are involved atten tion is largely consumed by this, with little or no visual attention focussing elsewhere. Therefore, observing eye-movernents during different situations can provide insights into perception.
Thus, one promising solution to preserving visual fidelity under simplification, is to exploit knowledge of the hum an visual system and its weaknesses when displaying images and animations. If visual perception is considered, there is the opportunity of reducing the required com putational resources. In this way, if only the aspects of a scene th a t receive visual attention or th a t are currently being focussed upon are m aintained at a high level of detail (LOD), the com putational power needed can be significantly reduced.
1.2
O v e r v ie w
these results; to verify the evaluation studies and th a t the actual features found to be salient were indeed those focussed upon during the three tasks used in our evaluation.
Towards our ultim ate goal of determ ining prom inent features, inspired by pre vious task related research from the psychology domain, and our own experim ental results, we designed an experim ental framework to further exam ine these issues. Psychological research suggests th a t individuals have a tendency to process infor m ation from only one p art of the envirom nent with th e exclusion of other p arts and th a t this lim ited mental capacity is usually allocated to th e task, at th a t given time. Research involving a range of tasks; including hand washing [HSMP03], food preparation [LHOla], driving [SHSOl] and block copying [PHLOl], all indicate th a t visual atten tion is nearly always consumed by the current task. Moreover, some work indicates th a t it might be the task related aspects of objects th a t receive attention [JWBFOl]. This inform ation would be very useful in determ ining salient features if it could be transferred directly to com puter graphics research. However, it is likely th a t performance differences exist between tasks in a real and virtual environment, and it is therefore im po rtant to establisli these before any further exam ination of salient features can be carried out.
1.2.1
M e th o d o lo g y
The work in this thesis involves:
1. D eterm ining if sahent features for a set of 3D polygonal models exist and can be predicted in advance, using eye-tracking.
2. Evaluating, using some psychological metrics, if the visual fidelity of these models can be enhanced by taking saliency d a ta into consideration during the simplification process.
3. Validating previously found salient features and our evaluation studies, using eye-tracking.
4. Finding how tasks control the salient aspects of objects, by building a frame work to compare task performance in a real and virtual environm ent, and recording eye-rnovements during the evaluation.
Often it is necessary for com puter graphics to operate under real-tim e con straints as well as m aintaining realistic and dynam ic scenes. Therefore it is useful to know w hat factors influence perception and can be allocated more resources at the expense of other aspects. The approach taken in this thesis, was to experim en tally determ ine the saliency of 3D polygonal models using eye-tracking. In it we attem p ted to take advantage of some weaknesses of the hum an visual system. As perceptual im portance is determ ined by the visual atten tio n of th e user, fixation d a ta was gathered from participants, using an eye-tracker, while viewing a set of models a t a high LOD. We predicted th a t, if we could ascertain the salient features of a set of objects in this way and m aintain these aspects during simplification, we could improve the visual quality of a set of simplified models.
had. Then, we investigated if the perceptual quality of these models could be enhanced by presenting these areas of high-acuity in greater detail, thus preserving the perceptually im po rtan t regions. To do this, the recorded fixation d a ta was applied as a weighting to th e model simplification metric. In order to investigate if the models simplified this way actually did have higher perceptual quality, we used some experim ental measures of visual perception.
The first psychological measurem ent gathered was nam ing tim es [WFMOl, WFMOO], on the set of familiar objects, this involved saying th e name th a t de scribed an object. In the case of picture-picture matching tim es [LBD02], pictures of a second set of objects were presented sim ultaneously and had to be matched. Finally, to determ ine if fam iliarity played a role forced-choice preferences experi m ents were carried out on both sets of models, this involved picking the stim ulus w ith more of the experimenter-identified qualities. We wished to determ ine if there was a significant decrease in the nam ing or picture-picture m atching times or a preference towards the models simplified using our approach, especially at the lower LO D ’s.
Additionally, in the final experim ent we used th e eye-tracker to see which aspects of objects received the most attention. To validate the previously found salient features and our evaluation studies, we recorded eye-rnovements during the actual tasks of naming, m atching and forced-choice preferences. Moreover, it was possible th a t the natu re of the task affected the results, so we exam ined the difference between where attention was focussed when viewing images and making image quality judgem ents through comparisons.
Figure 1.1: Predicting, evaluating and validating saliency for simplified polygonal models.
Psychological research suggests th a t individuals have a tendency to process in form ation from only one p art of the environm ent with the exclusion of other p arts and th a t this lim ited m ental capacity is usually allocated to the task, a t th a t given time. Research involving a range of tasks; including hand washing [HSMP03], food preparation [LHOla], driving [SHSOl] and block copying [PHLOl], all indicate th a t visual atten tio n is nearly always consumed by the current task. Moreover, some work indicates th a t it might be the task related aspects of objects th a t receive atten tio n [JWBFOl]. This inform ation would be very useful in determ ining salient features if it could be transferred directly to com puter graphics research.
[image:25.534.58.519.55.648.2]w here a tte n tio n is focussed. M any recent studies in psychology show th a t visual a tte n tio n is controlled to th e m ost p a rt by th e c u rre n t task , th is includes h a n d w ashing [HSMP03], food p rep a ra tio n [LHOla], driving [SHSOl] an d block copying [PHLOl]. F u rtherm ore, Johan sso n et al. [JW BFOl] d e m o n stra te s th a t it is th e task rela te d asp ects of o b jects th a t receive a tte n tio n , w hich could be useful in determ in in g th e salient features of objects. Such insights w ould be useful if th ey could be applied to im prove ta sk perform ance in g rap h ical system s. However, it is very likely th a t eye-m ovem ents p a tte rn s differ betw een a real w orld a n d v irtu a l environm ent. T herefore, before it is possible to apply insights from psychological research in predicting th e salient features of m an-m ade a rtifa c ts, it is im p o rta n t th a t th e differences in task perform ance betw een real a n d v irtu a l environm ents are established.
F u rtherm ore, extending from these insights a n d o th e r background research on task s from b o th th e psychology and c o m p u ter graphics lite ra tu re , we im plem ented a fram ew ork for evaluating visual a tte n tio n d u rin g task s, in a real a n d v irtu a l environm ent. It is tru e th a t our experim ent is lim ited to one s e tu p a n d th a t th ere are m any factors th a t define a task, such as th e environm ent, th e n a tu re of th e task and th e o b jects involved in th e task. However, alth o u g h we only exam ined task s in one specific environm ent, du rin g th e im p lem e n ta tio n of our fram ew ork we trie d to m atch these factors, such as th e environm ent, n a tu re of th e task and th e o b jects involve in th e task using realistic graphics, back p ro jectio n , h ap tics and rap id p ro to ty p in g to com pare task.
Figure 1.2: Building a framework to examine task perform ance in real and virtual scenes.
possible future directions with this framework include; investigating how attention is captured for a variety of tasks, determ ining the differences in performance and strategies between real and virtual situations, finding th e lim itations of carrying out sim ilar tasks in a virtual environment. U ltim ately our aim is to to ascertain salient feature for m an-m ade objects and to determ ine how th e user experience could be improved, perhaps through previewing or by displaying salient object features [HH004] or task related objects [CCW03] in greater detail.
[image:27.534.44.518.49.691.2]1.2.2
C ontribu tion
T h is thesis im proves th e s ta te of u n d e rsta n d in g a b o u t th e role th a t saliency d a ta can play in m esh sim plification. We experim entally established t h a t th e heads of n a tu ra l o b jects were p a rticu la rly salient features, by o b tain in g p e rc e p tu a l inform a tio n th ro u g h eye-tracking. E x p an d in g upon previous, user-guided sim plification research, we w eighted th e sim plification m etric, n o t w ith user-defined aspects, ju d g ed by individual preferences and requirem ents, b u t w ith p e rc e p tu a l inform a tion g ath ered from a group of su b jects, in order to produce p e rc e p tu a lly guided sim plified m odels.
We im proved upon previous work by carrying o u t a th o ro u g h ev alu atio n of our sim plified m odels, and proved t h a t th e visual q u ality of n a tu ra l o b jec ts is im proved w hen saliency inform ation is considered d u rin g th e sim plification process. We used th ree different ex p erim en tal m easures of visual fidelity, orig in atin g from th e psychology dom ain, in our studies. E xp erim en tal m etrics com pared to a u to m atic ones provide a m ore a c cu ra te m easure of how sim ilar surfaces ac tu a lly look com pared to a u to m a tic ones. M oreover, th e resu lts from our e x p e rim e n tatio n provide us w ith o th er less positive b u t useful inform ation; t h a t th e visual fidelity of m an-m ade a rtifa c ts can n o t be preserved in th is way, and t h a t it m erits fu rth e r investigation. T hese insights into th e im p o rta n t p e rc e p tu a l d etails are useful for o th ers perform ing m esh sim plification, e.g., user-guided sim plification. T h is work is described in H ow lett et al. [HH004].
T h e a d d itio n al validation studies published in H ow lett et al. [H H 005], provide a confirm ation of th e previous work. T h e eye-tracker was used as a v alidation tool to confirm t h a t th e heads of th e n a tu ra l o b jects were p a rtic u la rly salient and those focussed upon d u rin g th e evaluation task s of nam ing, p ic tu re -p ic tu re m atch in g and forced-choice preferences.
th e large a m o u n t of psychological research and m ore im p o rta n tly th ro u g h building a system , to com pare task perform ance in a real a n d v irtu a l environm ent. C on siderable care was tak e n to recreate as accu rately as possible a real w orld scene in a v irtu a l envirom nent and som e in terestin g p relim inary resu lts were found w hen we used it for ex p erim entation. Using eye-rnovem ent d a ta as th e in d icato r, we carried o u t som e novel experim ents, in which we found th a t th ere were perfor m ance differences betw een th e real an d v irtu a l environm ents. We provide a useful fram ew ork for ta sk com parisons and our results m erit fu rth e r investigation, pro viding a d irection for fu tu re research in th is area. T h is work has been published in H ow lett et al. [HL005]
1.2 .3
S u m m a ry o f C h a p ters
T h e rem aining ch a p te rs are organised as follows:
C h a p t e r 2 offers an in tro d u c tio n to eye-m ovem ents, visual a tte n tio n and eye- tracking, in p articu la r, gaze-contingent system s. F u rth e rm o re , it provides a detailed review of previous task related lite ra tu re from th e psychology and com p u ter graphics dom ains.
C h a p t e r 3 gives an in -d ep th description of th e background in fo rm atio n on LOD rendering techniques and m odel sim plification as well as th e use of p erc e p tu a l m odels, saliency, th e fixation m etrics th a t we use, m easures of visual fidelity and finally th e lim itatio n s of v irtu a l environm ents.
C h a p t e r 4 describes th e first set of experim ents we c arried o u t in w hich we used th e eye-tracker to ascertain th e salient features of 3D polygonal m odels and a discussion of our results.
of the resulting models. These included naming time, m atching time and forced-choice preference experiments.
C h a p t e r 6 outlines the validation study, whereby we tracked th e p articip an ts’ eye-movements when they carried out the three tasks of naming, m atching and forced-choice preferences, in order to confirm the saliency and evaluation results th a t we had previously found.
C h a p t e r 7 describes the im plem entation details of our framework, which allows the comparison of similar tasks in a real and virtual setup, followed by some experim ents carried out and a discussion of w hat was found.
C h ap ter 2
A tte n tio n , E ye-track in g and
Tasks
2.1
In tro d u ctio n
In our work we investigated w hat aspects of objects received the most visual atten tion by using an eye-tracking device to record eye-movements. We incorporated this into a siraphfication algoritlnn and performed an evaluation study. A ddition ally, for further exam ination of how attention is controlled by task, we built a framework th a t allows us to compare tasks in a real and virtual situation.
2.2
H u m an vision
2.2.1
In trod u ction
In our work, we attem p ted to take advantage of the weakness of the hum an visual system when rendering 3D models. We recorded eye-movements, to determ ine where visual attention was focussed for a num ber of reasons. Initially, we used an eye-tracking device to determ ine w hat aspects received the most visual a t tention while a participant was viewing a particular model. This eye-rnovement inform ation provided us with the input weighting for the simplification algorithm . Following the evaluation of our simplified models, we used the eye-tracker in a validation m anner, to confirm th a t the salient features found, were those actu ally focussed upon. Finally, as means of evaluation for the framework we built, we recorded eye-movements, which allowed us to com pare task performance in a real and virtual environment. Therefore, we mention some general eye-rnovement term s and give an introduction to visual attention.
2.2.2
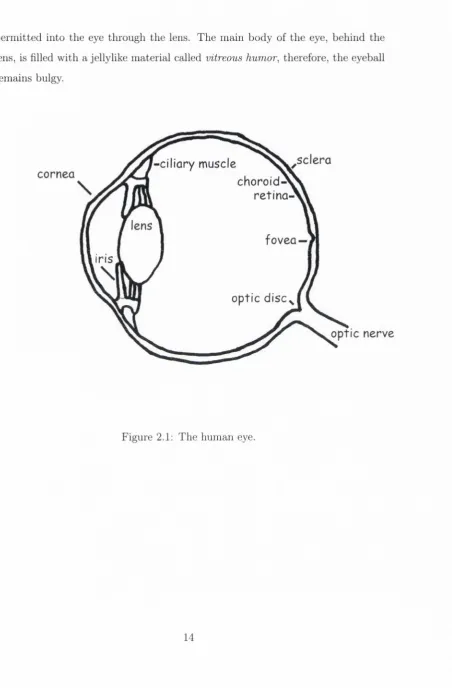
T he hum an eye
The hum an eye (see Figure 2.1) is a specialised light sensitive organ, it receives visual images which are then carried to the brain. The eye has a spherical structure and is roughly 2.5 cm in diam eter. Three layers of tissue make up the outer p art of the eye, these include; the sclera: the outerm ost layer of protective coating, the choroid: a vascular layer which lines the back of the eye-ball and the retina: the innerm ost light-sensitive layer.
perm itted into the eye through the lens. The main body of the eye, behind the lens, is filled with a jellylike m aterial called vitreous humor, therefore, th e eyeball remains bulgy.
.sclera
-ciliary muscle
cornea
ch oroid -V
re tin a
-lens
fovea —
ris
optic disc
optic nerve
[image:33.532.65.518.78.767.2]The retina lies and the back of the eye, and is m ade up largely of light- sensitive nerve cells, which are shaped like rods and cones. These photoreceptor cells capture light rays and convert them into electrical impulses, which travel along the optic nerve to the brain where they are turned into images. The optic disk, is where the optic nerve leaves the eye and has no visual receptors, therefore, it forms the blind spot. The macula lutea, lies directly behind the pupil and the fovea is located at the centre of the m acula lutea. Cone-shaped rods make up the sensory layer at the centre of the fovea.
2 .2 .3
W ork in g o f th e ey e
The process which allows the eye to focus is known as accommodation. T he ciliary muscle controls the focal length of the lens by flattening it. D istant objects can be seen w ithout accom m odation bu t for closer objects th e lens is m ade increasingly round by the ciliary muscle. The lens brings objects to focus on th e retina.
The visual field of the eye consists of a tiny central region of sharpness sur rounded by an area of less visual acuity. Due to the neural stru ctu re of the retina, the eye sees with most clarity only in the region of the fovea. T he reason for this is th a t this area is made up of cone-shaped cells. These cells are individually con nected to other nerve fibers, so th a t stimuli to each individual cell are reproduced and fine details are distinguished. The cone-shaped cells give us the ability to appreciate colour.
Despite this, we are not aware th a t our visual field contains a region of high acuity or central vision surrounded by an area of decreasing detail. This is because the eyes are always in motion, continually bringing different p arts of the visual field into the foveal region of interest as the atten tion shifts from one object to another.
2.2.4
E ye-m ovem en ts
Eye-rnovements carry the fovea and visual attention to p arts of the scene to be fixated upon and processed at high resolution. A num ber of different types of eye- movements have been identified by researchers [BG85]. Here, we are particularly interested in fixations. Movements, called saccades, enable us to direct our eyes to different areas of our visual field to be focussed upon. Research has shown th a t when viewing an image or scene, the eye tends to fixate and saccadc between a certain rmmber of locations repeatedly [Yar67, NS79]. A sequence of these locations create w hat is referred to as a scanpath. Scanpaths are regarded as being idiosyncratic; th a t is, although people may share the same locations of interest in a scene, they will move around them in different sequences. Furtherm ore, the task a t hand can affect the resultant eye-movements, as pointed out by Yarbus [Yar67],
2.2.5
Top-dow n and b o tto m -u p a tte n tio n
In the other scenario, where attention is top-down, atten tio n is directed vol untarily towards object of current interest. These are controlled by th e particular goals of the viewer when a scene is being studied. There are many cases of task related research which show evidence of this [LHOla, SHSOl, PHLOl]. In addition, these mechanisms implement our longer-term cognitive strategies.
2 .2 .6
V isu a l a tte n tio n
A great deal of research literature theorises th a t attentio n consists of a hierarchical, two-stage selection mechanism. The first stage is referred to as th e pre-attentive stage and refers to the early processes th a t operate in parallel across the whole visual field. It is unlim ited in capacity [IKOO]. This stage precedes an attentive stage th a t is of limited capacity and can only process a lim ited num ber of items. W hen items move from the pre-attentive stage to the attentiv e stage, they are considered to be selected and regarded as having entered into th e consciousness of the observer and been made available for higher level cognitive processing. The development of com putational models of attentio n began w ith Feature Integration Theory [TG80], which viewed the perception of objects w ithin the framework of the two-stage process.
2.2 .7
C hange b lin dn ess and in a tten tio n a l b lin d n ess
T he role of attention in perception is a big topic within the psychophysical commu nity. Studies on change blindness have shown th a t even som ew hat large changes in a scene can go unnoticed when the view is otherwise interrupted. Numerous ex perim ents have dem onstrated th a t hum ans can miss large changes in their field of view when they occur simultaneously with brief visual disruptions, such as an eye saccade, flicker, shift of the picture, a film cut or a blink [SirnOO, Ren02a, Reri02b].
A nother perceptual phenomenon th a t has been recognised more recently is inattentional blindness. This occurs when a stim ulus th a t is not atten ded is not perceived, even though the person is looking directly at it. This suggests th a t conscious perception is not possible w ithout atten tion [MR98].
A m ajor point from this work is th a t perception of the visual world is not as detailed as our subjective experience lets us believe. We do not have the capability to process everything in our visual field to the same degree, even though we are under the impression of having a fully detailed representation. We have a limited field of view, and the fovea our most acute visual area being only a small subset of this. Furtherm ore, it has been shown th a t focussed atten tio n is needed for the conscious perception of change [ROC97]. Visual attentio n is a selective mechanism whereby some inform ation receives enhanced cognitive processing.
2.2.8
D iscu ssion
c arried o u t sim ilar tasks in real and v irtu a l envirom nents.
2.3
E ye-t racking
2.3.1
In trod u ction
In our research we used an eye-tracking device to record th e necessary eye-m overnent d a ta an d found th e aspects of m odels th a t received th e m ost visual a tte n tio n (see F igure 2.2). E ye-tracking provides inform ation on w here an d how visual a tte n tio n is focussed while viewing a scene. It is often used to analyse th e p e rcep tio n of th e p a rtic ip a n t, as it gives inform ation th a t is often lost in a verbal rep o rt. A d ditionally, it shows w here a p a rtic ip a n t fixates before th ey perform an action as well as th e aspects th a t are focussed upon w ith o u t any cognitive processing. Eye- track in g gives a ccu rate inform ation on w hat asp ects receive focussed a tte n tio n (i.e., are visually im p o rta n t), for investigation, evaluation an d te stin g purposes. V isual inform ation is often a m ore a c cu ra te m easurem ent th a n opinions and pref erences, p a rticu la rly when try in g to predict w hat m ight h a p p e n in th e future. R ecently, eye-tracking has been used in stead of tra d itio n a l m eth o d s such as tim e, error m easurem ents or subjective ratin g s in usability te stin g [PHG"'"04].
[image:38.531.56.527.53.787.2]Additionally, eye-tracking has been used in an a tte m p t to com pensate for the increasing dem and on rendering power, this includes the development of gaze- contingent systems [Duc02] and peripherally degraded displays [Red98, WWHW97] Gaze direction can be exploited by finding the area of screen space th a t corre sponds to the foveal region of interest, which is tiny at approxim ately 2, and rendering only this in any detail. As single user can only focus on the portion of the display directly under the fovea, com putational power can be saved by de grading the image quality in the periphery. Following, is an account of some of these techniques.
2.3.2
GEize-contingent sy stem s
2.3.3
Focus plus co n tex t screens
In a d d itio n to th e regular gaze-contingent displays, B audisch et al. [BDDG03] present several o th er a tte n tiv e displays, th a t take ad v an tag e of th e h u m an vi sual system . T hey use eye-tracking and aim to m atc h th e su b jectiv e q u ality of a non-degraded display. T h e y describe research into Focus P lu s C o n te x t Screens an extension to norm al gaze-contingent displays, which only d egrade th e resolution in th e p eripheral im age regions (see F igure 2.3). Foveal regions of a rb itra ry sh ap e or size can be created, w ith perip h eral regions degrad ed by a rb itra ry m eans such as colour or c o n tra st a n d n o t sim ply resolution. A dditionally, th e sim ultaneous display of m ultiple foveal regions is possible, which can be used for prediction. Usually, when peripheral co n te n t is rendered a t low resolution, th e display h a rd w are is still th e sam e resolution as any o th e r p a rt of th e screen surface. However, in th e case of a focus plus co n te x t screen, th ere is a difference in resolution betw een th e focus and th e context area. It contains a wall sized low -resolution display w ith an em bedded high-resolution screen. T h e display co n te n t pans a n d can be bro u g h t into high resolution focus as required. T h is is in terestin g for large m aps or chip design w here certain areas need to be focussed upon.
Figure 2.3: A Focus P lus C on tex t Screen. (Im age from [BDDG03] co u rtesy of A ndrew T. Duchowski.)
2 .3 .4
A tte n tiv e u ser in terfa ce te c h n iq u e s
[image:41.532.61.519.37.501.2]2 .3 .5
D isc u s sio n
In all of the cases described here, the idea is to use the characteristics of hum an vision when designing com puter displays, the most significant characteristic being the difference between foveal and peripheral vision. Using eye-tracking in varia tions of gaze-contingent displays increases display frame rates and responsiveness. Even though rendering and display hardw are continuously improve, there will always be a need for alternative means to com pensate for the dem and for more power and resolution. However, we do not use the eye-tracker in a gaze-contingent way, b ut rather for determ ining the prom inent features of a set of models in ad vance of rendering. Only a small group of people have access to an eye-tracking device, so the aim of our research is to gain valuable insights which m ight enable the design of b etter LOD strategies. As we found the use of visual saliency to be beneficial at lower LODs, this inform ation could be used when rendering scenes th a t contain a large num ber of objects, like during crowd simulation. In certain highly detailed scenes with a large quantity of background or peripheral objects, when com putational time is limited it is useful to know th a t the visual fidelity can be improved by enhancing the salient features of natural objects. Furtherm ore, although less positive, when designing system s it may be helpful to know th a t the salient features of m an-m ade objects can not be found in this way. In our research, we also use the eye-tracker as a validation tool, to confirm previous results. In addition, it is used to record eye-movernents in order to evaluate the difference between task performance in our real and virtual setup.
2.4
Task perform ance
2.4 .1
In tr o d u c tio n
m o nitoring of eye-rnovem ents while a p a rtic ip a n t carries o u t a com plex n a tu ra l ta sk in a real world situ a tio n . T hese include food p re p a ra tio n , block copying, sandw ich m aking, n a tu ra l m an ip u latio n a n d h and w ashing tasks.
2 .4 .2
F am iliar ta sk s
L and an d H ayhoe [LHOla] com pared th e resu lts from two eye-tracking studies which investigated th e relationship betw een eye an d h a n d m ovem ents in food p re p a ra tio n tasks. T hey showed th a t task s could be divided into a series of actions perform ed on objects. T h e n ext o b ject in th e sequence was often focussed upon before any m an ip u latio n action occurred. T h e eyes usually fixate th e sam e object th ro u g h o u t th e action up o n it. However, th e y often fixated th e n e x t o b ject in th e task before th e previous action was com pleted. T hey described th e specific roles of th e individual fixations:
1. L ocating - establishing th e locations of o b jects for fu tu re use.
2. D irecting - establishing ta rg e t directio n prior to co n tact.
3. G uiding - supervising th e relative m ovem ents of two or th re e objects.
4. C hecking - establishing w h ether som e p a rtic u la r co ndition is m et, prior to th e te rm in a tio n of an action.
T hey concluded th a t eye-m overnents d u rin g th is kind of ta s k were nearly al ways consum ed by task related o b jects, so a tte n tio n is p rim arily top-dow n and influenced very little by th e b o tto m -u p salience of o bjects. G enerally, m an-m ade a rtifa c ts are th o u g h t of in reference to a task , w hich is possibly why we did n ot find any positive resu lts w hen we tried to a scertain th e ir salient features.
reta in e d over fixations is lim ited, th ey investigate how m uch of th e inform ation used d u rin g a task was o b tain du rin g previous fixations. M ore specifically how m uch inform ation is needed for guiding th e m ovem ents of th e h a n d s and eyes. T h e ir resu lts are largely in agreem ent w ith earlier research t h a t th e inform ation o b tain e d is often tra n sie n t and task-specific. T h ey say th a t a lot of n a tu ra l vision can be achieved w ith a “ju st-in -tim e ” representations.
Jo h an sso n et al. [JW BFOl] exam ined gaze-hand co o rd in atio n in a n a tu ra l m an ip u la tio n task, w here p a rtic ip a n ts h a d to grasp a n d m ove a b a r to a ta rg e t, an d found sim ilar results. T h e bar h a d to be m oved e ith e r d irectly or a ro u n d an obstacle, and th e n retu rn ed to th e s u p p o rt surface. R esults showed th a t p a rtic i p a n ts alm ost exclusively fixated c e rtain lan d m ark s critical for th e control of the task. C om pulsory landm arks included those a t w hich c o n ta c t events h appened. E xam ples of these included, th e grasp site on th e bar, th e ta rg e t, an d th e su p p o rt surface w here th e bar was retu rn ed after ta rg e t co n tact. O p tio n al lan d m ark s in cluded any obstacles in th e direct m ovem ent p a th an d th e tip of th e bar. T hey found th a t th e m oving b a r was never fixated upon. H a n d /b a r m ovem ents fol lowing gaze and were linked concerning landm arks. T hey found th a t m ost of the fixations in th eir task were d irecting fixations, as described above [LHOla]. T h ey conclude th a t gaze su p p o rts h and m ovem ent plam iing by m ark in g po in ts to which th e grasped object are th en directed. T hey d e m o n stra ted th a t p a rtic ip a n ts nearly always d irected gaze to o b jects involved in th e task an d , therefore, th e salience of gaze ta rg e ts arises from th e functional sensorim otor req u irem en ts of th e task.
task . T hey propose th a t look-ahead fixations are used to stra te g ica lly d istrib u te a tte n tio n an d visual resources to optim ise inform ation g a th e rin g d u rin g n a tu ra l tasks.
2.4.3
B lock -cop yin g tasks
In th e ir experim ents, Pelz et al. [PHLOl] stu d ied th e in te rac tio n s of eye, head, a n d h a n d m ovem ents du rin g a sim ple block-copying task . D uring th e task th ere were some fixations d ed icated to g ath erin g in fo rm atio n a b o u t th e p a tte rn . As well as these, o th e r fixations were used to visually guide h an d m ovem ents w hen picking up an d placing dow n blocks. P a rtic ip a n ts used c o o rd in a te d p a tte rn s of eye, head, an d h a n d m ovem ents in a fixed tem p o ral sequence. However, these p a tte rn s varied w ith respect to th e im m ediate task co n tex t. C o o rd in atio n was m ain tain ed by delaying th e h an d m ovem ents until th e eye was available to guide it. T h e ir resu lts suggests th a t observers m ain ta in c o o rd in a tio n by se ttin g up a tem porary, task specific co o rd in atio n betw een th e eye a n d hand.
2.4.4
D rivin g tasks
2 .4 .5
A d d itio n a l ta sk fin d in g s
In o th e r interestin g research, H ayhoe et al. [HBB98] showed t h a t fixation d u ra tions revealed effects of th e display changes t h a t were n o t revealed in th e percep tu a l rep o rt. In th eir experim ent th e y m ade ta sk relevant display changes du rin g saccadic eye-m ovem ents. T hey changed th e colour of th e ta rg e t o b jec t du rin g a saccade. D espite, results showing th a t th e length of fixations on th e m odels p a tte rn increased, d epending on th e point in th e task th a t th e change occurred, th ere was no verbal re p o rt of this. T his indicates t h a t th e visual inform ation th a t is retain ed across successive fixations depends on th e ta sk d em an d s a t th a t m om ent. T his is consistent w ith previous suggestions th a t visual rep re sen ta tio n s are lim ited and task d ep e n d en t [LHOla].
In th eir research Ling et al. [LH04] investigated w h eth er th e ch aracteristics, i.e., th e colour and size, of a 3D o b ject in te rac ted in an o b jec t sim ilarity task. To investigate this, th ey used dom elike objects, w ith varying sh a p e an d size as th e stim uli. T h e tasks included two discrim ination task s a n d one o b jec t sim ilarity task. P a rtic ip a n ts had to select th e o b jec t w hich was bigger th a n , th e sam e colour as, or m ost sim ilar to a reference object. T hey found th a t o b jects w ith a m ore s a tu ra te d colour ap p e are d larger. F u rth e r, th ey d e m o n stra te d th a t du rin g th e o bject sim ilarity task th ere was an in teractio n betw een th e two a ttrib u te s .
2 .4 .6
D isc u ssio n
needs to be ex tended to th e v irtu al world, if the knowledge is to be successfully used to aid rendering in com p u ter graphics.
2.5
Tasks in graphics and p ercep tio n
2 .5 .1
In tr o d u c tio n
R eccnt work in th e field of c o m p u ter g raphics includes research t h a t d em o n stra tes ex p erim entally th a t it is possible to render n o n -task rela te d o b jects in less d etail th a n task related ones. O th e r work investigates th e relatio n sh ip of delay and difficulty to user perform ance d u rin g a placem ent task . It also exam ines th e effects of preview ing, which occurs w hen c e rtain asp ects of a scene are show n in a prelude to a task. M oreover, we describe som e work designed to investigate how th e visual fidelity of real o b jects and self-avatars affects task perform ance in an im m ersive v irtu a l environm ent.
2 .5 .2
S e le c tiv e ren d erin g d u rin g ta sk s
Figure 2.4: A selective quality image, whereby it is uiostly rendered a t a low LOD except for the visual angle of the fovea (2 degrees) centred on each teapot. (Image from [CCW03] courtesy of Alan Chalmers.)
[image:48.532.47.517.62.726.2]task sem antics can be used to selectively render in high quality only the details of the scene th a t are attended to.
S undstedt et al. [SCCD04] take this further by investigating to w hat level viewers fail to notice degradations in image quality, between task and non-task related areas. They consider how an image can be selectively rendered when a user is performing a visual task in an environm ent (see Figure 2.5). In particular, they investigate to w hat level viewers fail to notice degradations in image quality, between non-task related areas and task related areas, when quality param eters such as image resolution, edge anti-aliasing, reflection and shadows are altered. Their results confirm th a t, at least for edge anti-aliasing, inattentional blindness can in fact be exploited to significantly reduce the rendered quality of a large portion of a scene, w ithout having any effect on th e viewers’ perception of the overall quality of the rendered image. Additionally, this research shows th a t, when performing tasks, the low quality of non-task related areas even w ithin the visual angle of the fovea, largely goes unnoticed.
2.5.3
Perform ance gains during tasks
T h is task related research by W atson et a i , a lth o u g h n ot d irectly rela te d to the are a of visual fidelity, is an interestin g ap p roach w hich could p e rh a p s be extended to in co rp o rate it. M oreover, it is also interestin g as task s of th is n a tu re involve the user in te rac tin g w ith th e scene, in com parison to a passive ta sk such as counting. In th eir work, th ey m easured placem ent errors and tim e in 3D o b ject placem ent tasks, and d e m o n stra te th e effects of delay and difficultly on results. Moveover, th ey exam ined th e effects of preview ing, by ind icatin g wfien an o b jec t was in the a p p ro p ria te position. P a rtic ip a n ts wore a head m o u n ted display and in te rac ted w ith th e environm ent using a plastic m ouse gripped like a pistol. T h e environm ent consisted of two rec tan g u la r yellow pedestals. O n to p of th e left p ed estal th e re was a tra n slu c e n t box and on top of th e right one th ere were two tra n slu c e n t squares, coplanar to two of th e right p e d e sta l’s vertical sides (see F igure 2.6). In one experim ent, p a rtic ip a n ts had to place a sphere into th e box on th e rig h t pedestal by releasing th e mouse. For th e second experim ent, preview ing was im plem ented by a colour change w hen th e sphere was in th e correct position over th e box b u t had not yet been released by th e mouse.
o
T h e stu d y had 3 levels of delay irnplem euted by ad d in g a delay d u rin g each fram e an d 6 levels of difficulty im plem ented by varying th e w id th of th e right pedestal. For th e second experim ent, preview ing was im plem ented by flashing th e sphere w hen it was in position. R esults for th e first ex p erim en t showed th a t placem ent errors an d tim e increased as delay and difficulty increased. D elay has a g rea ter im p act on perform ance w hen difficulty is high. R esu lts for th e second ex p erim ent shows th a t preview ing reduces placem ent tim es an d lim its th e effects of delay and difficulty. O ne possible direction w ith th is work w ould be to exam ine eye-rnovernents as well as m easuring erro r and tim e, while p a rtic ip a n ts carried o u t these tasks. It would be interestin g to see how eye-m overnents are affected by delay, difficulty and previewing.
As described in Section 3.3.2, P a rk h u rs t and N iebur [PN04] d e m o n stra te th a t th e behavioural costs associated w ith p ercep tu ally a d a p tiv e level of d e ta il (LOD ) techniques can be offset by th e behavioural perform ance gains d u rin g visual search task s on desktop system s. However, th ey m ake an im p o rta n t n ote th a t th e n a tu re of th e ta sk affects th e am o u n t of trade-off' and behavioural research t h a t is needed before p ercep tu ally a d a p tiv e rendering using LOD red u ctio n techniques can be exploited fully.
2.5.4
Tasks in virtu al en viron m en ts
oni-to re d in a real-space setu p , in several v irtu a l environm ents an d in a hy b rid setup. T h ey showed th a t, w hen the task was to m a n ip u la te real o b jec ts in a v irtu a l en vironm ent, th e task perform ance was brought closer to th a t of real space, th a n w hen m an ip u la tin g v irtu a l objects. O th e r research shows th a t providing generic self-avatars results in an increased sense of presence, com pared to providing no self-avatar [SU93, SU94]. However, th ey hypothesise th a t, if th e self-avatar was n o t a c cu ra te rep resen tatio n , th e sense of presence w ould be reduced.
T h e re have also been previous stu d ies com paring perform ance in real an d v ir tu a l setups. T hom pson et al. [TWG"*‘04] have show n th a t p a rtic ip a n ts are signifi c an tly less accu ra te a t ju d ging distances in visually im m ersive envirom nents th a n in th e real world. M oreover, M ohler et al. [MTCR~'^04] carried o u t stu d ie s using tread m ill-b ased v irtu a l environm ents to sim ulate th e p e rc e p tu a l-m o to r effects of a c tu a lly walking around in th e real world.
2 .5 .5
D isc u ssio n
We described som e of th e research into task perform ance an d analysis in c o m p u ter graphics. It d e m o n stra tes th a t task related asp ects of im ages can be rendered in high d etail, w ith little or no loss in th e overall visual fidelity. T h is suggests th a t th ere is p o ten tia l here to save on co m p u ta tio n a l resources. We also provide some inform ation a b o u t research on task s in v irtu a l environm ents. In ou r work we ex ten d upon this by building a fram ew ork which can be used to com pare task s in
a real an d v irtu a l scenario.


![Figure 2.3: A Focus Plus Context Screen. (Image from [BDDG03] courtesy of](https://thumb-us.123doks.com/thumbv2/123dok_us/1538304.697903/41.532.61.519.37.501/figure-focus-plus-context-screen-image-bddg-courtesy.webp)





