Comparative Analysis Of Fuzzy Clustering
Algorithms In Data Mining
Binsy Thomas
Department of Computer Engineering Pillai‟s Institute of Information Technology,
Navi Mumbai, India.
Madhu Nashipudimath
Department of Information Technology Pillai‟s Institute of Information Technology,
Navi Mumbai, India.
Abstract- Data clustering acts as an intelligent tool, a method that allows the user to handle large volumes of data effectively. The basic function of clustering is to transform data of any origin into a more compact form, one that represents accurately the original data. Clustering algorithms are used to analyze these large collection of data by means of subdividing them into groups of similar data. Fuzzy clustering extends the crisp clustering technique in such a way that instead of an object belonging to just one cluster at a time, the object belongs to one or more clusters at the same time with appropriate membership values assigned to the object in a cluster. This paper addresses the major issues associated with the conventional partitional clustering algorithms, namely difficulty in determining the cluster centers and handling noise or outlier points. Integration of fuzzy logic in data mining subjugates these traditional methods to handle natural data which are often vague. The study provides an analysis of two fuzzy clustering algorithms videlicet fuzzy c- means and adaptive fuzzy clustering algorithm and its illustration on different fields.
Keywords – Adaptive fuzzy, Fuzzy sets, Fuzzy Clustering, Fuzzy C- means, K-means.
I. INTRODUCTION
Data Mining or Knowledge discovery refers to a variety of techniques that have developed in the fields of databases, machine learning and pattern recognition. The process of finding useful patterns and information from raw data is often known as Knowledge discovery in databases or KDD. Data mining is a particular step in this process involving the application of specific algorithms for extracting patterns (models) from data.
Cluster analysis has been widely applied in many areas such as data mining, geographical data processing, medicine, classification of statistical findings in social studies and so on. Clustering techniques are used for data mining if the task is to group similar objects into the same classes whereas objects of different classes show different characteristics [3]. Most of these domains deal with massive collections of data. Hence the methods to handle them must be efficient both in terms of the number of data set scans and memory usage [1]. It is a technique for breaking data down into related components in such a way that patterns and order becomes visible. It aims at sifting through large
volumes of data in order to reveal useful information in the form of new relationships, patterns, or clusters, for decision-making by a user [2].
Clustering techniques fall into a group of undirected data mining tools. The goal of undirected data mining is to discover structure in the data as a whole. Clustering technique is used for combining observed objects into clusters (groups), which satisfy the main criteria:
Each group or cluster is homogeneous; objects that belong to the same group are similar to each other.
Each group of cluster should be different from other clusters, that is, objects that belong to one cluster should be different from the objects of other clusters.
This paper provides an overview of the conventional clustering technique, its advantages and limitations, fuzzy clustering and its algorithm: fuzzy c-means clustering and adaptive fuzzy clustering method, its applications and how adaptive fuzzy is superior to c-means clustering in handling outlier points. Section 2 describes the basic notions of conventional clustering and also introduces k-means clustering algorithm. In Section 3 we explain the limitations of conventional clustering. Section 4 introduces the fuzzy clustering. Section 5 is about fuzzy c-means clustering algorithm, adaptive fuzzy clustering method and its illustration explaining how fuzzy c-means is inferior to the adaptive c-means algorithm. Section 6 concludes the paper.
II. CONVENTIONAL CLUSTERING TECHNIQUE
Clustering is a fundamental method in data mining and pattern recognition areas. Clustering techniques can be classified into supervised clustering-demands human interaction to decide the clustering criteria and the unsupervised clustering- decides the clustering criteria by itself. The two types of classic clustering techniques:
Hierarchical
Partitional
2) Partitional: Partitioned clustering techniques create a one level partitioning of the data points. Unsupervised clustering includes partitional clustering methods. Given a database of objects, a partitional clustering algorithm constructs partitions of the data, where each cluster optimizes a clustering criterion.
K-means algorithm and its different variations are the most well-known and commonly used partitioning methods. K-means is one of the simplest unsupervised learning algorithms that solve the well-known clustering problem. Partitional clustering techniques attempt to segment data by grouping related attributes in uniquely defined clusters. Each data point in the sample space is assigned to only one cluster. In partitioning the data, only cluster centers are moved and none of the data points are moved. Thus clustering is an iterative process of finding better and better cluster centers in each step. The value „k‟ stands for the number of cluster seeds initially provided for the algorithm. This algorithm takes the input parameter „k‟ and partitions a set of m objects into k clusters. The technique work by computing the distance between a data point and the cluster center to add an item into one of the clusters so that intra-cluster similarity is high but inter-cluster similarity is low. A common method to find the distance is to calculate to sum of the squared difference as shown in equation (1) and it is known as the Euclidian distance.
dk = ||n Xjk − C j i||2
(1) where,
dk : is the distance of the kth data point. n : is the number of attributes in a cluster. Xjk : is jth value of the kth data point. Cji : is the jth value of the ith cluster center.
The cluster centers are randomly initialized and we assign a data point xi into a cluster to which it has minimum distance. When all the data points have been assigned to clusters, new cluster centers are calculated by finding the weighted average of all data points in a cluster. The cluster center calculation causes the previous centroid location to move towards the center of the cluster set. This is continued until there is no change in cluster centers. The k means algorithm is efficient in handling crisp data.
III. LIMITATIONSONCONVENTIONAL
CLUSTERING
In the conventional clustering process, each data sample is assigned to only one cluster and all clusters are regarded as disjoint collection of the data set. In practice there are many cases, in which the clusters are not completely disjoint and the data could be classified as belonging to one cluster almost as well to another. Therefore, the separation of the clusters becomes a fuzzy notion, and representation
of the data can be more accurately handled by fuzzy clustering methods. It is necessary to describe the data in terms of fuzzy clusters [4].
IV. FUZZY CLUSTERING
Traditional clustering approaches generate partitions; in a partition, each instance belongs to one and only one cluster. Hence, the clusters in a hard clustering are disjointed. Fuzzy clustering for instance extends this notion and suggests a soft clustering schema. In this case, each pattern is associated with every cluster using some sort of membership function, namely, each cluster is a fuzzy set of all the patterns. Larger membership values indicate higher confidence in the assignment of the pattern to the cluster. The purpose of clustering is to identify natural groupings of data from a large data set to produce a concise representation of a system's behavior. A hard clustering can be obtained from a fuzzy partition by using a threshold of the membership value. The most popular fuzzy clustering algorithm is the fuzzy c-means (FCM) algorithm. Even though it is better than the hard K-means algorithm at avoiding local minima, FCM can still converge to local minima of the squared error criterion. The design of membership functions is the most important problem in fuzzy clustering; different choices include those based on similarity decomposition and centroids of clusters. Fuzzy clustering allows natural grouping of data in a large data set and provides a basis for constructing rule-based fuzzy model [5].
V. FUZZYCLUSTERINGMETHODS
The results of traditional clustering approaches are not appropriate to define clusters as modules in product design. Fuzzy clustering approaches can use fuzziness related to product design features and provide more useful solutions. The different fuzzy clustering methods are described as follows.
A. Fuzzy C-Means Clustering Method
be more. The algorithm calculates the membership value μ with the formula,
μj xi = 1 dji
1 m−1
1 dki
1 m−1 p
k=1
(2)
where
μj(xi) :is the membership of xi in the jth cluster dji: is the distance of xi in cluster cj
m: is the fuzzification parameter p: is the number of specified clusters dki :is the distance of xi in cluster Ck
B. Limitations Of Fuzzy C-Means
The fuzzy c-means approach to clustering suffers from several constrains that affect the performance. The main drawbacks are due to the restriction that the sum of membership values of a data point xi in all the clusters must be equal to one as in expression (3). This restriction tends to give high membership values for the outlier points. So the algorithm has difficulty in handling outlier points. Secondly the membership of a data point in a cluster depends directly on the membership values of other cluster centers and this sometimes happens to produce undesirable results. It also has problems in handling high dimensional data sets and a large number of prototypes[16]. FCM is sensitive to initialization and is easily trapped in local optima[17].
𝜇𝑗 𝑥𝑗 = 1
𝑝
𝑗 =1 (3)
C. Illustration On Fuzzy C-Means
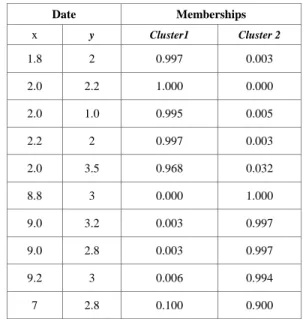
Fig 1 shows a 10-point data set with two clusters and two outlying points. Input data points are marked with a „+‟ and the points found by FCM are marked with „x‟. The table 1 tabulates the found partition matrix. Though the solution is an approximately correct one, the locations of the found points are not satisfactory since they should be at the centers of the diamond like patterns.
Fig 1:10 point data set used as input to FCM..
TABLE I. MEMBERSHIP VALUES CALCULATED BY FCM
Date Memberships
x y Cluster1 Cluster 2
1.8 2 0.997 0.003
2.0 2.2 1.000 0.000
2.0 1.0 0.995 0.005
2.2 2 0.997 0.003
2.0 3.5 0.968 0.032
8.8 3 0.000 1.000
9.0 3.2 0.003 0.997
9.0 2.8 0.003 0.997
9.2 3 0.006 0.994
7 2.8 0.100 0.900
The found points are at (2.0, 2.2) and (8.7,3.0) instead of ideal placement at(2.0,2.0) and (9.0,3.0) It is clear that the points located away from the diamond patterns have influenced FCM‟s solution in that they have “pulled” the points away from the ideal locations. It is noted that, as expected, the membership values per each point add up to one.
It is viewed that every outlier point can be associated with one cluster in the data in the sense that it would be lying close to that cluster. Also, that the few points in a data set cannot be said to be close to any cluster, and is considered as noise points. In general, we perceive that outliers should be recognized as “satellite” points to a given cluster and given an appropriately high degree of membership with that cluster. However, their presence should not affect the accuracy of determining the location of the clusters. For noise points, we perceive that they should not receive significant memberships with any of the clusters.
D. Adaptive Fuzzy C-Means
fuzzy set. Secondly, the AFCM employs splitting and merging methods for forming the clusters. It determines the splitting by averaging the cluster memberships that weigh the cohesion degree; and decides the merging by the number of samples in both clusters that weigh independency degree. This clustering algorithm arbitrarily chooses initial cluster centers. Therefore, the AFCM provides a statistical method based on the sample space density to initialize the number of clusters and cluster centers, so that the adaptive capability of the algorithm can be enhanced.
Adaptive fuzzy clustering algorithm is similar to c-means algorithm in many ways and it supports the concept of partial memberships for data points in clusters. It also gives the higher accuracy of clustering results with fuzzy mathematics [6]. The main difference is that it removes the restrictions imposed in c-means algorithm through expression (3). The algorithm calculates fuzzy membership values for a data points through a new method as given in exp. 4
𝜇𝑗 𝑥𝑖 =
𝑛 ∗ (𝑑1
𝑗𝑖) 1 𝑚−1
(𝑑1
𝑘𝑖) 1 𝑚−1 𝑛
𝑧=1 𝑝
𝑘−1
(4)
Where,
μj(xi) : is the membership of xi in the jth cluster dji : is the distance of xi in cluster cj
m : is the fuzzification parameter p : is the number of specified clusters n : is the number of data points dki : is the distance of xi in cluster Ck
In the place of exp.(3),the algorithm imposes a new constrain given in exp.(5) which says the sum of membership values of all the points in all the cluster centres must be equal to the number of data points n.
𝜇𝑗 𝑥𝑖 = 𝑛 𝑛
𝑖=1 𝑝
𝑗 =1
(5)
During the iteration cycle, the algorithm calculates new cluster centres using the same exp (3). The maximum membership value generated by adaptive fuzzy clustering algorithm is not limited to one. When conventional fuzzy membership distributions are required (within a range of zero to one) these can be generated by the process of normalization. Normalization finds the maximum membership among all clusters and rescales the memberships from this maximum using exp (5).
𝜇𝑖𝑘𝑛𝑜𝑟𝑚 𝑥𝑖 =
𝜇𝑖𝑘𝑜𝑙𝑑(𝑥 𝑖)
max 𝜇𝑘𝑜𝑙𝑑 (6)
where,
i=1 to n ; k=1 to p
𝜇𝑖𝑘𝑛𝑜𝑟𝑚(𝑥𝑖) : the normalized membership of xi in kth cluster.
𝜇𝑖𝑘𝑜𝑙𝑑(𝑥𝑖): is the old (original) membership p: is the number of specified clusters n: is the number of data points
max () : returns the maximum membership value in the kth cluster
E. Strengths of Adaptive Fuzzy C- Means
The adaptive fuzzy clustering algorithm is efficient in handling data with outlier points or natural data with uncertainty and vagueness since the algorithm is not restricted by the exp. (3). It accomplishes this by virtue of its unique partial membership features for data items in different clusters so that the clusters grow naturally to reveal hidden patterns. The algorithm tends give only small membership values to outlier points. The time required per iteration in Adaptive Fuzzy Clustering Means is one sixth of the time required by FCM. This new approach gives us a new version of fuzzy clustering which can be used for unsupervised training and other applications.
F. Illustration based on c-means and adaptive fuzzy-c-means clustering
The standard FCM uses generally to measure the similarity between an object xj and a class given by its center vi a distance which grants the same importance for the features taken into account in the clustering process. The performance of this algorithm is compared to the standard version of the FCM [7].
has achieved a compromise that allowed the reduction of noise while producing accurate edges[7].
Fig 2. Segmentation results using FCM(GL), FCM(µ) and ADFCM(T=55) algorithms for Panda synthetic images.
The robustness face to noise and the accuracy of the edges between regions have been shown. However, the choice of the threshold T is strongly dependent on used images.
VI. CONCLUSION
Fuzzy clustering, which constitute the oldest component of soft computing, are suitable for handling the issues related to understandability of patterns, incomplete/noisy data, mixed media information and human interaction, and can provide approximate solutions faster. Conventional clustering algorithms face difficulties in handling natural data. This paper enlightens the study on conventional and different fuzzy clustering algorithms and its application on various fields.
REFERENCE
[1] S. Asharafa ,M, Narasimha Murty, “An adaptive rough fuzzy single pass algorithm for clustering large data sets”, Pattern Recognition 36 (2003) 3015 – 3018.
[2] Raju G, Binu Thomas, Sonam Tobgay and Th. Shanta Kumar, “Fuzzy clustering methods in data mining: A comparative case analysis” 2008 International Conference on Advanced Computer Theory and Engineering.
[3] Fernando Crespoa, Richard Weberb,”A methodology for dynamic data mining based on fuzzy clustering” , Fuzzy Sets and Systems 150 (2005) 267–284
[4] Dr.G.Padmavathi,Mr.Muthukumar,”Image segmentation using fuzzy c means clustering method with thresholding for underwater images”, Int. J. Advanced Networking and Applications Vol 02, Issue: 02, Pages: 514-518 (2010) [5] A. Elmzabi, M. Bellafkih, M. Ramdani, K. Zeitouni.
“Conditional fuzzy clustering with adaptive method”, IPMU´04, 4-9 July 2004, Perugia – Itali.
[6] Vuda. Sreenivasarao, Dr. S. Vidyavathi, “Comparative analysis of fuzzy c-mean and modified fuzzy possibilistic c-mean algorithms in data mining”, IJCST Vol. 1, Issue 1, September 2010.
[7] Divya Jain1 & Vipin Tyagi, “Pattern Recognition Technique based on Adaptive Fuzzy k- means Clustering using Domain Knowledge” International Journal of Computer Applications (0975 – 8887) Volume 29– No.2, September 2011.
[8] Mohamed Walid Ayech, Karim El Kalti, Bechir El Ayeb, “Image Segmentation Based on Adaptive Fuzzy-C-Means Clustering” 2010 International Conference on Pattern Recognition.
[9] Pawan Kumar, Mr. Pankaj Verma, Rakesh Shrma,” Comparative analysis of fuzzy c mean and hard c mean
algorithm” International Journal of information Technology and Knowledge Management July-December 2010, Volume 2. [10] Binu Thomas, Raju G., and Sonam Wangmo,” A Modified
Fuzzy C-Means Algorithm for Natural Data Exploration” 2009 World Academy of Science, Engineering and Technology 49. [11] J. Han and M. Kamber, “Data Mining Concepts and
Techniques”. Elsevier (2003).
[12] Lei Jiang and Wenhui Yang, “A Modified Fuzzy C-Means Algorithm for Segmentation of Magnetic Resonance Images” Proc. VIIth Digital Image Computing: Techniques and Applications, pp. 225-231, 10-12 Dec. 2003, Sydney. [13] U. Fayyad and R. Uthurusamy, “Data mining and knowledge
discovery in databases”, Commn. ACM, vol. 39, pp. 24–27, 1996.
[14] Ussama Fayyad, Gregory Piatetsky-Shapiro and Padhriac Smyth, “The KDD Process for extracting useful Knowledge from volumes of data”,Commn ACM, vol 39, No.11, 1996 [15] Chih-Cheng Hung!, Wenping Liu and Bor-Chen Kuo,“A New
Adaptive Fuzzy Clustering Algorithm For Remotely Sensed Images”.
[16] Roland Winkler, Frank Klawonn, Rudolf Kruse,” Problems of Fuzzy c-Means Clustering and Similar Algorithms with High Dimensional Data Sets”, Challenges at the Interface of Data Analysis, Computer Science, and Optimization Studies in Classification, Data Analysis, and Knowledge Organization2012,pp 79-87.