2018 International Conference on Computer, Communication and Network Technology (CCNT 2018) ISBN: 978-1-60595-561-2
Quality Scalable Video Coding Algorithm Based on Pattern Recognition
Xue-yan ZHANG*, Xin-yu AI and Hong-song LI
School of information and communication, Guilin University of Electronic Technology, Guilin, Guang Xi, China
*Corresponding author
Keywords: Video coding, Pattern recognition, Quality scalable video coding, SOM.
Abstract. A novel quality scalable video coding algorithm based on pattern recognition was proposed in this paper. The self-organizing map (SOM) was used for scalable video coding. A coarse pattern library and two fine pattern libraries were designed for the base layer coding and the enhancement layer coding, respectively. Experimental results show that the peak signal to noise ratio (PSNR) improvement of reconstructed video images is 1.06dB when the compression ratio is 100:1.
Introduction
Scalable Video Coding (SVC) was widely used in mobile Internet video communications. SVC was the expansion of the H.264/AVC video coding standard to meet new video applications. SVC has temporal, spatial, and quality scalability. Scalable High-Efficiency Video Coding (SHVC) not only supports temporal, spatial and quality, but supports hybrid scalability, depth of bit scalability
and gamut scalability [1-9]. For the quality scalability, it mainly includes Coarse Granular Scalable
(CGS) [10-11], Medium Granular Scalability (MGS)[12], Fine Granular Scalable (FGS)[13-14]. However,
those algorithms are so complex that they have a higher requirement for the processor.
Self-organizing mapping is a relatively efficient method of clustering. It simulates the human
brain learning process, which has been found wide applications in such areas as failure detection [15],
image and video processing [16-18], medical examination[19-20] and data mining[21-22]. To reduce the
complexity and improve the performance of SVC, a novel quality scalable video coding algorithm based on pattern recognition (PR-QSVC) was proposed. Experimental results show that the algorithm has a better performance than the traditional coarse-grain quality scalable coding algorithm.
Coding Scheme
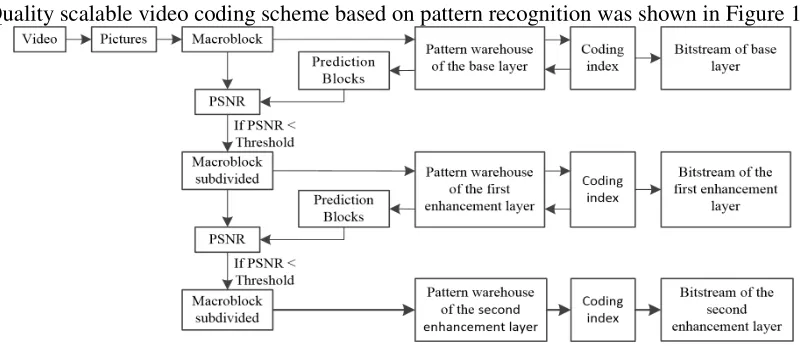
[image:1.612.86.487.533.706.2]Quality scalable video coding scheme based on pattern recognition was shown in Figure 1.
PR-QSVC carries out the following steps:
Step-1: Creating the pattern library. Dividing all frames of the video into macroblock as the training vector set. The Pattern library was trained by training vector set and get the base layer. Repeating this step, the first enhancement layer could get by reducing the size of the macroblock, and the second enhancement layer could get by reducing more size of the macroblock.
Step-2: Coding the base layer. Each video frame was divided into the macroblock. Then, the variance between the macroblock and each pattern vector were computed in the base layer. Selecting the pattern vector which has the smallest variance as the winning pattern vector. Lastly, putting the index of the winning pattern vector as the base layer stream.
Step-3: Coding the first enhancement layer. the first enhancement layer using the base layer stream was predicted. Then, computing the variance of the residual between the predicted macroblock and the original macroblock. If the variance is smaller than the preset threshold, the macroblock with a smaller size was divided and the first enhancement layer was coding, then, repeat Step-2. Finally, the first enhancement layer stream can get.
Step-4: Coding the second enhancement layer. Repeating Step-3, the second enhancement layer was coding as the second enhancement layer stream.
When the decoder receives the base layer, a low-quality video was decoded. When the decoder receive the first enhancement layer at the same time, a high-quality video can get. If the decoder receive all of the encoded data, the video can be decoded with the best quality.
Training the Pattern Library
The pattern library was trained with the following steps:
Step-1: Given a neural size of the network (N, M), N is the size of pattern library, M is the size of
each pattern vector.
Step-2: All of the pictures were divided into macroblock with a fixed size. The training vector set
{X(n), n=1, 2…, L} is consist of the macroblock, while L is the number of training vectors.
Step-3: Computing the variance of each vector in the training set. Sorting the training vectors in
ascending order with variance and dividing the sorted training vectors into two parts: {X1(n),
X2(n)}. Choosing the training vectors in each part at the same intervals. Then, putting them together
to form initial pattern library W(n) which contains N pattern vectors.
Step-4: Computing the distortion D(j) between the input vector and each pattern vector with some
distortion measure, and selecting the winning pattern vector as j*,
( )
*
0min1
j j N
D D j
≤ ≤ −
= (1)
Step-5: Modifying the winning pattern vector j* and its neighboring pattern vectors by the
following equation, ( ) ( ) ( ) ( ) ( ) ( ) ( ) * * , , 1
, others
j j
j
j
t a t t t j j N t
t t + − ∈ + =
W X W
W
W
(2)
( )
a t is the learning rate, which determines the modification amount of pattern vectors. N t
( )
isneighborhood function, which was used for adjusting the range of modification around the winning pattern vector.
Step-6: Repeating Step-2 to Step-5 until each pattern vector was trained.
Results
In the experiment, the foreman was chosen as the standard test video sequence. To evaluate the
(
)
2 PSN
MS 255 =10lg
R
E Y Y, '
(3)
Y represents the intensity of the luminance component in the original picture. And Y′ was
intensity the luminance component in the reconstruction picture. EMS was the Mean Square Error
between the original picture and the reconstructed picture. In addition, the compression ratio RC
was chosen as the measure of compression performance,
C=
i
o
B R
B
(4)
i
B represents the data size of the original picture, Bo was the data size of the compressed picture.
To compare the coding performance of three coding algorithms: PR-QSVC, CGS, and H.264/AVC, the Joint Scalable Video Model (JSVM) 9.19 were chosen as the evaluation model for SVC.
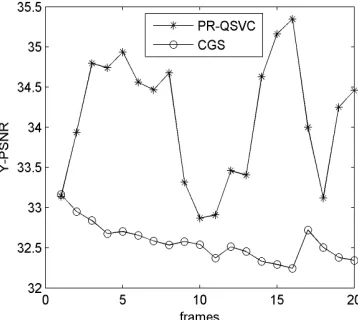
For the convenience of comparison, the three coding algorithms were set to the base layer (BL) and the two enhancement layers (EL). Figure 2 shows that the CGS algorithm has a stable quality of
base layer decoded pictures. However, for the whole,the quality of base layer decoded pictures of
[image:3.612.216.395.290.450.2]the PR-QSVC algorithm was better than CGS (TABLE.1).
Figure 2. The comparison of the quality of base layer decoded by PR-QSVC and CGS.
Table 1. The comparison of simulation results between PR-QSVC and CGStABLE 1.
Quality Layers R PR-QSVC CGS
y,PSN (dB) RC Ry,PSN (dB) RC
the BL 34.0406 155.3239 32.5687 166.3993
the first EL 35.2164 99.4589 34.8775 74.6308
the second EL 36.6563 36.0682 37.3735 36.7362
(a) The original image (b) Image of the BL
[image:3.612.153.463.487.729.2]Figure 3 shows the original picture and the reconstructed pictures which encoded by PR-QSVC. In the base layer, the reconstructed picture has a bad quality. It is obvious that the reconstructed picture of the first enhancement layer has much better quality than the base layer. In the second enhancement layer, the reconstructed picture has the best quality. So, it shows that the PR-QSVC
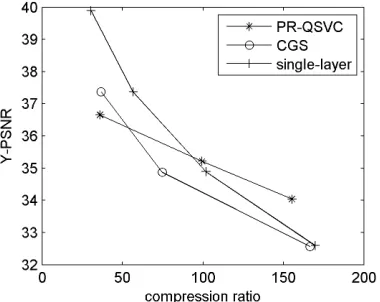
algorithm can realize SVC perfectly. The distortion curves ofcompression ratio were presented in
[image:4.612.213.403.174.325.2]Figure 4. The simulation results show that, compared with CGS, the peak signal to noise ratio (PSNR) improvement of reconstructed video images was about 1.06dB when the compression ratio is more than 100:1.
Figure 4. The comparison of PSNR between PR-QSVC, CGS, and Single-layer.
Conclusions
In this paper, a novel quality scalable video coding algorithm based on pattern recognition was proposed. Experimental results show that the coding algorithm has a better scalable coding performance. The next step is to combine SOM with temporal scalability and spatial scalability, a better scalable coding performance can get.
References
[1]Wang D, Zhu C, Sun Y, et al. Efficient Multi-Strategy Intra Prediction for Quality Scalable
High Efficiency Video Coding.[J]. IEEE Trans Image Process, 2017, pp (99):1-1.
[2]Hoangvan X, Ascenso J, Pereira F. Adaptive Scalable Video Coding: An HEVC-Based
Framework Combining the Predictive and Distributed Paradigms[J]. IEEE Transactions on Circuits & Systems for Video Technology, 2017, 27(8):1761-1776.
[3]Tang W L, Yang S H. Investigation and Performance Evaluation of Scalable High Efficiency
Video Coding[C]// IEEE International Conference on Computer and Information Technology. IEEE Computer Society, 2017:314-319.
[4]Yang S H, Vo P B. Adaptive Bit Allocation for Consistent Video Quality in Scalable High
Efficiency Video Coding[J]. IEEE Transactions on Circuits & Systems for Video Technology, 2017, 27(7):1555-1567.
[5]Wang D, Zhu C, Sun Y, et al. Efficient Multi-Strategy Intra Prediction for Quality Scalable
High Efficiency Video Coding[J]. IEEE Transactions on Image Processing, 2017, pp (99):1-1.
[6]Cabarat P L, Hamidouche W, Déforges O. Real-time and parallel SHVC hybrid codec AVC to
[7]Biatek T, Hamidouche W, Travers J F, et al. Optimal Bitrate Allocation in the Scalable HEVC Extension for the Deployment of UHD Services[J]. IEEE Transactions on Broadcasting, 2017, pp (99):1-16.
[8]He G, Hu J, Jiang H, et al. Scalable Video Coding Based on User’s View for Real-Time Virtual
Reality Applications[J]. IEEE Communications Letters, 2018, 22(1):25-28.
[9]Boyce J M, Ye Y, Chen J, et al. Overview of SHVC: Scalable Extensions of the High Efficiency
Video Coding Standard[J]. IEEE Transactions on Circuits & Systems for Video Technology, 2016, 26(1):20-34.
[10]Shi Z, Sun X, Xu J. CGS quality scalability for HEVC[C]//Multimedia Signal Processing
(MMSP), 2011 IEEE 13th International Workshop on. IEEE, 2011: 1-6.
[11]Lin H C, Peng W H, Hang H M, et al. Layer-Adaptive Mode Decision and Motion Search for
Scalable Video Coding with Combined Coarse Granular Scalability (CGS) and Temporal Scalability[C]// IEEE International Conference on Image Processing. IEEE, 2007: II-289-II-292.
[12]Castellanos W, Guerri J C, Arce P. Performance Evaluation of Scalable Video Streaming in
Mobile Ad hoc Networks[J]. IEEE Latin America Transactions, 2016, 14(1):122-129.
[13]Williamson D, Lynch-Wood G. Comparisons between the one-loop and two-loop solutions for
improving the coding efficiency of FGS[C]//MPEG-4. 2001 Proceedings of Workshop and Exhibition on. IEEE, 2016:79-82.
[14]Chen Y, Radha H, Van Der S M. System and method for fine granular scalable video with
selective quality enhancement[J]. 2001.
[15]Li X, Zhu D. An Adaptive SOM Neural Network Method to Distributed Formation Control of
a Group of AUVs[J]. IEEE Transactions on Industrial Electronics, 2018, pp (99):1-1.
[16]Hikawa H, Kaida K. Novel FPGA Implementation of Hand Sign Recognition System With
SOM–Hebb Classifier[J]. Circuits and Systems for Video Technology, IEEE Transactions on, 2015, 25(1): 153-166.
[17]Ramirez-Quintana J A, Chacon-Murguia M I. Self-adaptive SOM-CNN neural system for
dynamic object detection in normal and complex scenarios[J]. Pattern Recognition, 2015, 48(4):1137–1149.
[18]Ben Haj Ayech M, Amiri H. Content-based image retrieval in the topic space using SOM and
LDA[C]//Control, Engineering & Information Technology (CEIT), 2015 3rd International Conference on. IEEE, 2015: 1-6.
[19]Kim H G, Jang G J, Choi H J, et al. Recurrent neural networks with missing information
imputation for medical examination data prediction[C]//IEEE International Conference on Big Data and Smart Computing. IEEE, 2017:317-323.
[20]Mittal D, Gaurav D, Sekhar Roy S. An effective hybridized classifier for breast cancer
diagnosis[C]//Advanced Intelligent Mechatronics (AIM), 2015 IEEE International Conference on. IEEE, 2015: 1026-1031.
[21]Adeniyi D A, Wei Z, Yongquan Y. Automated web usage data mining and recommendation
system using K-Nearest Neighbor (KNN) classification method[J]. Applied Computing & Informatics, 2016, 12(1):90-108.
[22]Zhang H, Wang J. Design of Information Monitoring System Based on Internet of Things and