DATA DRIVEN SUFFIX LIST AND
CONCATENATION ALGORITHM FOR
TELUGU MORPHOLOGICAL
GENERATOR
SRIBADRI NARAYANAN.R
Computational Engineering and Networking, Amrita University, Amrita vishwa vidyapeetham, Ettimadai, Coimbatore, Tamil Nadu 641105, India
SARAVANAN.S
Computational Engineering and Networking, Amrita University, Amrita vishwa vidyapeetham, Ettimadai, Coimbatore, Tamil Nadu 641105, India
SOMAN K.P
Computational Engineering and Networking, Amrita University, Amrita vishwa vidyapeetham, Ettimadai, Coimbatore, Tamil Nadu 641105, India
[email protected] Abstract:
For Telugu, a highly inflectional, agglutinative and suffix oriented, developing a morphological generator is a challenging task. The demand for Telugu morphological generator has increased as machine translation systems are being developed for other languages to Telugu. Morphological generator is a computer program that generates the word forms by considering the lemma, part-of-speech tag information and morphological feature description as input. In this paper, we report our work on implementing a morphological generator for Telugu, which doesn’t require any orthographic and morphotactics rules, using an automated extraction of the suffix list and efficient algorithm for concatenating the lemma and the morphological features. The preliminary results obtained from this system are significant.
Keywords: Natural language processing; Machine translation; Telugu morphological generator.
1. Introduction
In the context where there are very few Telugu Morphological Generator (MG) available in the open domain compared to the morphological analyzer, the demand for the generator is very high. The morphological analyzer and generator for the one of the morphologically rich language Telugu [Brown (1991)] with agglutinative nature is very challenging task. Unlike the Telugu morphological analyzer, the much simpler problem the generator is still baffling. The MG is an essential tool for any Natural Language Processing (NLP) applications.
2. Related Works
For Indian languages different methodology has been used for MG. The effective approach for developing MG is using Finite State Transducers [Jurafsky et al. (2008)] where copious amount of orthographic and morphotactics rules are required. Using this approach MG for Indian languages like Tamil [Menon et al.(2009)] [Anandan et al. (2001)], Kannada [Vikram et al. (2007)], Malayalam [Jayan et al. (2009)] and Hindi [Bogel et al. (2010)] has been developed. Using Data driven approach MG for Hindi [Goyal et al. (2008)] and Tamil [Anand Kumar et al. (2010)] has been developed. Online Demo version of MG for Punjabi is available and a downloadable windows version of a morphological generator for Tamil is also available. Tel-More [Ganapathiraju et al. (2006)] Morphological generator for Telugu is based on linguistic rules and Perl program. 3. Morphological Generator for Telugu
MG is a piece of a program that generates the word forms by considering the lemma, part-of-speech tag information and morphological feature description as input. The morphological feature information are mapped to its equivalent the morphemes and these morphemes are glued with the lemma.
For example, pusTakam + N + ACC pusTakam + unu pusTakamunu
The MG process the input, ‘pusTakam + N + ACC’ and maps the morphological feature information with the equivalent morpheme. In our example ‘ACC‘is mapped to the morpheme ‘unu’. ‘N’(Noun) is the pos category of the word. The concatenation of the stem and morpheme is governed by the orthographic rules. ‘pusTakam + unu’ becomes pusTakamunu.
This paper describes the method that doesn’t require heuristics for mapping morphological feature information to the morpheme and for the spelling changes. Instead the mapping of the morphological feature description to the inflected forms is done automatically with the help of the suffix list. The suffix list is created in such a way that there is no need of the spelling rules.
4. Creation of Suffix Table Using Corpus Based Approach
The monolingual resources are gathered from various sources, tokenized and Romanized. Those Romanized words are categorized into noun and verb list. The suffix table creation for noun and verb has been done in the current system and can be extended to other pos categories too. The ample Romanized words are sorted. Using the simple regular expression, the words with the same stem are separated out and labeled.
Table 1. Sample pruned list of Romanized Telugu verb forms (PreProcessed)
chaduvuTunnadu pAduTunnadu chaduvuTunnadi pAduTAdu chaduvuTAdu pAduTunnadui chadivenu pAduTAdi AduTunnadu PAdenu Adenu … AduTunnadui ….
These words are grouped into three separate lists and labeled as ‘pAd’ list, ‘chad’ list and ‘Ad’ list. The lemmas of the respective list are cropped off. The following table 2 shows three such lists.
Table 2. Categorized Inflected form list labelled with the Stem
chad list pAd list Ad list
uvuTunnadu uTunnadu uTunnadu
uvuTunnadi uTAdu enu
uvuTAdu uTunnadui uTunnadui ivenu uTAdi … … enu …
These lists are compared against one another to form the paradigm list. In our example, ‘pAdu’ list and ‘Adu’ list are similar and this two make a one paradigm and labeled as ‘P2’. Thus the entire paradigms can be found similarly.
Table 3. List of Inflected forms tagged with Paradigm Number
P1 P2
uvuTunnadu uTunnadu
uvuTunnadi uTAdu
The remaining items where the lemmas are cropped off are the suffixes. These suffixes are tagged with the morphological feature information.
For example, uTunnadu is tagged as PRES_3SM* uTAdu is tagged as FUT_3SM†
uTunnadui is tagged as PRES_3SF‡
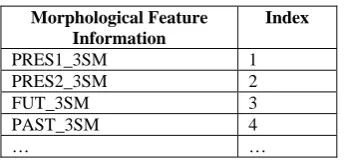
Though in Telugu, inflections of verb and noun are more than 3000 and 1000 respectively, we tagged commonly used inflections. To be precise, the suffixes of words collected from the monolingual corpora are tagged with the morphological feature (MF) information. Thus the suffix table is created by numbering the MF information of the suffixes and shown in table 4.
Table 4. Suffix Table
POS-1§ P1 P2 …
MF1 uvuTunnadu uTunnadu …
MF2 uvuTunnadi uTAdu …
MF3 uvuTAdu uTunnadui …
MF4 ivenu uTAdi …
MF5 … enu …
The input for the generator system is ‘Root + POS + Morpheme Information’. So having, lemmas listed under each paradigm may not be helpful in cases where the lemma and root forms are different. For example, pAdu + V + PRES_3SM pAduTunnadu and pAdu + V + FUT_3SM pAduTadu
Here the ‘pAd’ is the word that cropped off from the Romanized list and the list is labeled as ‘pAd’. For the given input, the paradigm of the word ‘pAdu’ is to be identified. If the paradigm list has the lemma of the word, the identification isn’t possible in this case, so the root form of the word is marked for its paradigm. Most of the cases, the lemma and root form are same and so it’s easy to identify the odd ones and label its root form against the paradigm number. The paradigm is shown in the table 5 with two paradigms.
Table 5. Paradigm Table
P1 P2
Root form Stem Root form Stem
chaduvu chad pAdu pAd
… Adu Ad
… …
5. Concatenation
A simple algorithm [Anand Kumar et al. (2010)] is devised to generate the word form given the input root word and MF lexical information. This algorithm requires three types of data, suffix table, paradigm table and MF information table. The MF description is shown in table 6.
Table 6. Morphological Feature Description Table
Morphological Feature Information
Index
PRES1_3SM 1 PRES2_3SM 2 FUT_3SM 3 PAST_3SM 4
… …
number (2), which is ‘TAdu’. The lemma and the suffix is glued together to form the complete word form (pAduTAdu).
In this method, the necessities of the orthographic rules and the morphotactics rules are completely eliminated.
5.1. Algorithm for Concatenation
input root + pos + morph feature concatenate (input) : return output
root, pos, morph-feature spilt (input, “+”) stem, paradigm-No paradigmTable (root, pos)
suffix suffixTable (index (morph-feature), paradigm-No) output join (stem, suffix)
The concatenation method doesn’t generate the correct word form if the information in any of the table is missing or wrong data.
6. Identification of the paradigm
For the root word that exists in the paradigm table, the concatenation algorithm gets the paradigm number and
Verb / Noun Forms
Inflected forms Child list 1
Stem Extractor
Inflected forms Paradigm 1
Inflected forms Paradigm 2
Inflected forms Paradigm n Paradigm Classifier
Stem 1
Inflected forms Child list 2
Inflected forms Child list n words with similar
stem are grouped together
Stem 2 Stem n
List with similar inflected forms are clustered together
Paradigm Table
P1 P2 Pn
---
--- ---
--- ---
---
Morph Features Info Table
Morph Info Index
PRES_3SM
PAST_3SF
---
--- Suffix Table
P1 P2 Pn
---
--- --- --- ---
--- MF1
MF2
suffix table. The paradigm identification is done based on the canonical form. The root words in the paradigm are segmented into individual characters and the each character is augmented with the consonant vowel representation.
For example, the word ‘pAdu’ is segmented to ‘pA du’ and the segmented characters are augmented with C-V and the C-V representation looks like ‘p-C A-LV d-C u-SV ’. The canonical form of the word ‘pAdu’ is C-LV-C-SV.
All the words in the paradigm table are converted to the C-V and canonical representation. This representation helps to identify the paradigm of the new word. For example, consider the root word ‘Adu’ and it’s not present in the paradigm table. The root word is converted to the CV and canonical representation. The identification procedure measures the similarity of this CV representation is to the existing word-paradigm. In this case ‘A-LV d-C u-SV’ is more similar to ‘p-C A-LV d-C u-SV’ and this is identified as paradigm P2. The similarity measure score is depends on both the CV and canonical representation.
7. Implementation
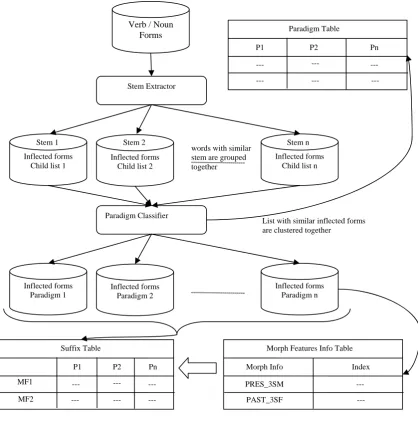
The morphological generator involves two stages, creation of the data and generation. The primary function of the former stage is to create the necessary data that required for the later stage. The data creation module does play a critical role in the creation of the three vital data, suffix table, paradigm table and morphological feature lookup table for the pos categories noun and verb. After the preprocessing stages like tokenization, pos-tagging and pruning the available list noun and verb inflected forms are processed. The stem extractor module gathers similar noun/verb forms and trims the stem from the lists. The stem is associated with its corresponding inflected forms list. The paradigm classifier does compare these lists with one another and classify accordingly. This module creates a paradigm table where stems are linked with the paradigm it belongs and collection of lists where each list is associated with its paradigm. These inflected forms in this collection are morphologically tagged and a lookup table for morphological tag and index is created. The suffix table is created with help of the morphologically tagged table and the inflected forms paradigms. Each column of the suffix table indicates the paradigm and the row indicates the morphological feature information.
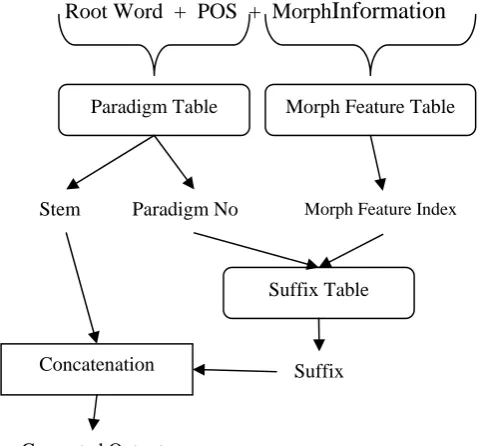
The block diagram for the creation of paradigm, morph-feature index and suffix table is shown in figure 2. Root Word + POS + Morph
Information
Paradigm Table Morph Feature Table
Stem Paradigm No Morph Feature Index
Suffix Table
Concatenation Suffix
Generated Output
In second stage of the morphological generator, the input which is in the format of ‘Root word + pos + morph information’ is processed to get the generated output. The concatenation algorithm is written in Java. The procedure takes root word and pos category as input and with help of paradigm table outputs the stem of the root word and the paradigm number that the stem associated with. From suffix table with the paradigm number and the morph feature index, the suffix that to be glued with the stem is fetched and it’s concatenated with the stem. If the root word isn’t found in the paradigm table, the paradigm identification algorithm computes the paradigm number.
8. Experiment and Results
The sentences from raw monolingual corpora are pos tagged and tokenized. Around 300,000 noun forms and 175, 000 verb forms are collected and pruned for creating suffix table and testing. 23,458 unique nouns and 2,734 unique verbs are classified into 47 and 39 paradigms respectively. 618 noun inflected forms and 948 verb inflected forms are morphologically tagged. 12% of nouns and verbs separated out from the word-paradigm list randomly from any paradigm for evaluating the paradigm identification module. 78% of the tested new nouns and 62% of the new verbs are chosen the correct paradigm. Out of the 14497044 and 2591832 generated noun forms and verb forms respectively. Around 147,000 and 152, 000 noun and verb forms respectively are chosen randomly and manually verified. Out of that 120, 407 nouns forms and 132,918 verb forms are generated correctly.
Table 7. Results
Generated Tested Accuracy Total Correctly Identified
Noun forms 1,44,97,044 147,000 82% Noun 23,458 18197
Verb forms 25,91,832 152, 000 87% Verb 2,734 1707
9. Conclusion
Though the accuracy of the paradigm identification is not the best, the overall generator’s accuracy is comparatively higher. The performance of this system can be improved by beefing up the monolingual corpora. The framework, developed for one of the Dravidian family language Telugu alongside with Telugu MG, can be easily extended to the other languages of the family such as Tamil, Malayalam and Kannada. The developed MG system which is integrated with the English to Telugu Machine Translation (MT) system helps to improve the MG performance and MT system as a whole.
References
[1] Brown C.P. (1991). The Grammar of the Telugu Language. New Delhi: Laurier Books Ltd.
[2] Daniel Jurafsky; James H Martin. (2008). Speech and Language Processing. 3rd ed. University of Colorado, Boulder: Pearson.
[3] Menon A. G.; Saravanan S; Loganathan R; Soman K. P. (2009): Amrita Morph Analyzer and Generator for Tamil: A Rule-Based Approach, Tamil Internet Conference, Cologne, Germany, pp. 239-243.
[4] Anandan P; Ranjini parthasarath; Geetha T.V. (2001): Morphological Generator for Tamil, Tamil Internet 2001 Conference, Kuala Lumpur, Malaysia.
[5] Vikram T.N; Shalini R. (2007): Development of Prototype Morphological Analyzer for the South Indian Language of Kannada, 10th international conference on Asian digital libraries, Heidelberg, Berlin, pp. 109-116.
[6] Jisha P.Jayan; Rajeev R.R; Rajendran S. (2009): Morphological Analyzer for Malayam - A Comparison of Different Approaches, in International Journal of Computer and Information Technology, pp. 155-166.
[7] Tina Bogel; Miriam Butt; Annette Hautli; Sebastian Sulger. (2010): Developing a Finite-State Morphological Analyzer for Urdu and Hindi, in LREC.
[8] Goyal V; Singh Lehal G. (2008): Hindi Morphological Analyzer and Generator, in Emerging Trends in Engineering and Technology, Washington, DC, USA.
[9] Anand Kumar M; Dhanalakshmi V; Rekha R U; Soman K.P; Rajendran S. (2010): A Novel Data Driven Algorithm for Tamil Morphological Generator, in International Journal of Computer Applications, pp. 52–56.