International Journal of Scientific Research in Computer Science, Engineering and Information Technology © 2017 IJSRCSEIT | Volume 2 | Issue 4 | ISSN : 2456-3307
Implementation of Frequent Pattern Mining On Un-rooted
Unordered Tree Using FRESTM
Savita S. Khadse
*1, Prof. Gurudev B. Sawarkar*
2 *1Department of Computer Science & Engineering1M.Tech Student, V.M. Institute of Engineering & Technology, Nagpur, Madhya Pradesh, India 2Assistant Professor, V. M. Institute of Engineering & Technology, Nagpur, Madhya Pradesh, India
ABSTRACT
Data mining issue to discover frequent restrictedly embedded subtree pattern from an arrangement of unordered un-rooted tree. In this paper we display frequent restrictedly embedded sub tree digger (FRESTM), is a productive calculation for mining frequent, unordered, un-rooted, embedded sub-trees in a database of marked trees. Our commitment is as per the following: The calculation identifies all embedded, unordered trees. Another comparability class expansion plot produces all hopeful trees and data tree. The thought of extension rundown joins is reached out to figure the recurrence of unordered trees. The execution assessment on a few engineered and certifiable data demonstrates that FRESTM is an effective calculation.
Keywords: Un-Rooted Tree, Pattern Mining, Pattern Matching, Embedded Sub-Tree, Frequent Sub-Trees
I.
INTRODUCTION
In recent researches, the primary issue of discovering frequent patterns from a database of diagrams has a few vital applications in various territories like bioinformatics, client web log examination, semi-organized XML data [12], web mining, RNA, phylogeny [15], essential trees, and science compound data [9].
A principle issue in numerous other data mining errands, for example, affiliation govern mining, arrangement and grouping. In spite of the fact that finding of frequent patterns (for instance shut patterns) has found more enthusiasm, creating proficient calculations for finding frequent patterns is yet vital, because the effectiveness of the calculations of discovering dense portrayals relies on upon the productivity of the frequent pattern mining calculations.
Though thing set mining and grouping mining have been considered widely before, as of late there has been huge enthusiasm for mining progressively complex pattern sorts, for example, trees and diagrams For instance a few calculations for tree mining have been proposed which incorporate TreeMiner [5], which mines embedded, requested trees, FreqT which mines
incited requested trees, FreeTreeMiner which mines instigated, unordered, free trees that is there is no unmistakable root. TreeFinder which mines embedded, unordered trees (yet it might miss a few patterns; it is not finished); and PathJoin, uFreqt [14], uNot [18], CMTreeMiner [4], and Hybrid Tree Miner which mine instigated, unordered trees. Our concentrate in this paper is on a total and proficient calculation for mining frequent, marked, unordered, un-rooted, embedded subtrees and diagrams. An effective calculation is presented for the issue of mining frequent, unordered, embedded sub trees in a dataset of trees. Our commitment is as per the following:
The main calculation counts all embedded, unordered trees.
Another independent proportionality class expansion conspire produces all applicant trees. Just conceivably frequent expansions are considered, yet some redundancy is permitted in the applicant era to make each class independent.
manufactured dataset and a genuine web log dataset to demonstrate that FRESTM is a productive calculation.
II.
RELATED WORK
To provide solution for the above issue there are diverse techniques recommended by different creators we will talk about some of them.
Zhang and Wang [3] advances supporting structure for a frequent assention subtrees issue for both rooted and un-rooted phylogenetic trees utilizing diverse data mining techniques. Portray sanctioned shape for rooted trees and phylogeny-mindful tree extension plot for making applicant subtrees level by level. To locate all frequent understanding subtrees in a given arrangement of rooted trees, utilizing Apriori-like approach.
Chehreghani acquaints OInduced [2] with mine frequent requested actuated tree patterns. It utilizes expansiveness first competitor era strategy. in the first place, log data is changed over into rooted requested trees, and an arrangement of frequent patterns are extricated, in view of these patterns, a basic classifier is worked to group distinctive clients. Auxiliary classifiers demonstrate higher execution contrasted with conventional classifiers.
Hereditary calculations [6] explain enhancement strategy for auxiliary pattern acknowledgment in a model-based acknowledgment framework utilizing credited social chart matching strategies. To enhance the GA-based ascribed social diagram matching arrangement to major, speedier merging rate and great quality mapping between a scene credited social chart, and show credited social diagram.
Leung and Suen [7] Elaborated top-down versatile way to deal with pattern matching and its application to complex written by hand Chinese character acknowledgment are talked about.
Zhihui [1] propose distinctive techniques to find restrictedly embedded subtree patterns. We learn properties of a standard type of unordered trees; Apriori-based strategies are expounded to produce all hopeful subtrees utilizing two techniques 1) pairwise joining 2) leg connection. Ascertaining the limited alter remove between a competitor subtree and a data tree restrictedly embedded subtree can be accomplished.
These strategies are joined into a calculation, named as (FRESTM).
Chi etal [4] proposed CMTreeMiner, which decide shut and maximal frequent sub-trees in a database of named rooted trees, where the rooted trees can be either requested or unordered. It mines both shut and maximal frequent sub-trees by navigating and figure tree that reliably ascertain all frequent sub-trees.
Zaki [5] display a tree mining illustration the issue of mining auxiliary patterns in a data set of Ribonucleic corrosive (RNA) atoms, can be spoken to as trees. The learning about a recently sequenced RNA, analysts are searching for basic topological patterns, and can give principle insights to the function of the RNA.
POTMiner [11] proposed An adaptable and parallelizable calculation to mine mostly requested trees. It can distinguish both initiated and embedded subtrees. It can likewise deal with both totally requested and very unordered trees.
Wang [9] presents Approximate-Tree-By-Example (ATBE), which permits off base indistinguishable trees. ATBE framework interfaces with the client through simple yet compelling question dialect graphical gadgets are given to smooth advance of inputing the inquiries.
Shasha and his group [8] Presents a productive and a few heuristics prompting rough arrangements. To the probabilistic slope climbing and bipartite matching procedures.
III.
IMPLEMENTATION
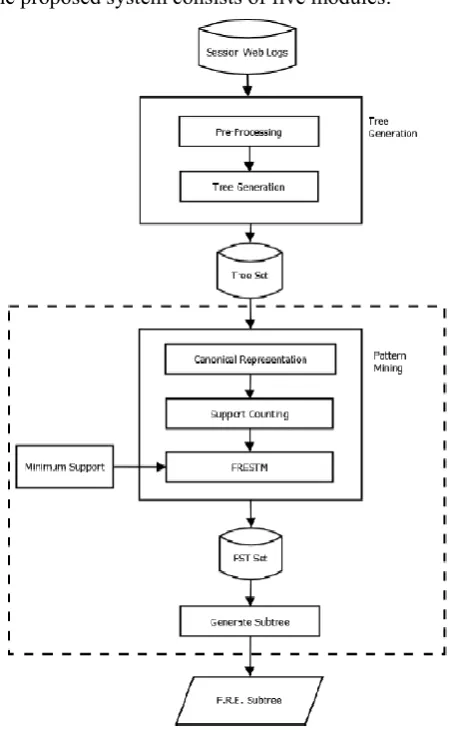
The proposed system consists of five modules:
Figure 1: System Architecture
A. Preprocessing and Tree Generation
In preprocessing web log characterizing will be done this incorporate evacuating deficient web log, lessening uproarious data and data set change. Tree era will change over session web logs to tree structure the session web logs are in type of related way.
B. Canonical Representation
In this, the produced tree will be changed over into unique portrayal, from a past from that had more than one conceivable portrayal. An unordered tree t is in its standard shape if no proportionate requested tree t' exists with profundity name succession of (t') ought to be not as much as profundity mark arrangement of (t), that is the sanctioned type of an unordered tree ought to bring about the lightest profundity name grouping among the greater part of its comparable requested trees. Straightforwardly expelling the last hub of a canonicalized tree "t" will bring about a buildup tree still in its accepted shape. Here specifically expelling
implies evacuating a hub without further
canonicalizing the subsequent tree. In this manner, if "t" is an unordered tree in its authoritative shape, at that point each descending sub-tree and each prefix of "t" is additionally consequently in its accepted frame.
C. Support Counting
To count the support, i.e., compute the event number, of a hopeful k-subtree pattern in the entire data set, naturally, we ought to run the restrictedly implanting recognition subroutine on the competitor pattern tree against all data trees one by one. In the event that the event number falls underneath minocc, which is
characterized as minsup ∗ |TS| where TS is the
arrangement of data trees, the hopeful pattern tree can be disposed of; something else, the competitor must be frequent. All the frequent k-subtrees will then be utilized to produce bigger contender for the subsequent pattern development handle.
The above procedure can be additionally upgraded by exploiting two Apriori-based properties. The primary property says that a (k + 1)- tree can't be frequent if any of its k-subtrees as of now isn't frequent, which is a fractional motivation behind why the utilization of the proportionality class is productive in our joining technique. The second property says, from the supporting data tree perspective, the supporting trees of the (k + 1)- subtree must be in the convergence set of the supporting trees of all its k-subtrees. This property really recommends an event list based pruning strategy where the event rundown of a subtree s is the rundown of data trees that bolster s (i.e., the rundown of supporting trees of s). In particular, given two k-subtrees that are in a similar proportionality class, we initially discover the crossing point rundown of the event arrangements of the two trees and afterward think about the cardinality of the convergence list with minocc. On the off chance that the cardinality is as of now not as much as minocc, we don't have to join the two subtrees. Else, we go along with them to get a (k + 1)- subtree, which at that point needs to finish the accepted test keeping in mind the end goal to be dealt with as a competitor tree to experience the bolster counting stage.
single mark (hub). On the off chance that the cardinality of the crossing point rundown is as of now littler than minocc, we don't have to play out the connection. Else, we extend the tree by utilizing the leg connection run the show.
D. FRESTM (Frequent restrictedly embedded subtree mining)
Apriori-based data mining strategy, which tolerably counts all hopeful subtrees from a given arrangement of unordered trees, level by level, utilizing the furthest right development strategies. Toward the begin frequent 1-subtrees and 2-subtrees are found. To say all frequent 1-subtrees, one by one that is frequent single names, we cross each hub of each tree to make a modified list structure for every unique mark showing up in the trees. In particular, for every unique name, we keep up a rundown of IDs of supporting trees, in which the name shows up. By contrasting IDs of supporting
trees and the given minsup, we can choose whether the name is frequent or not.
Figure 2 : Algorithm for discovering all frequent subtrees
E. Generate Subtree
The proposed calculation is an Apriori-based data mining strategy, which dynamically lists all hopeful subtrees from a given arrangement of unordered trees, level by level, utilizing the furthest right development techniques. Fig. 2 abridges the calculation.
In the introduction stage, frequent 1-subtrees and 2-subtrees are found first. To list all frequent 1-2-subtrees, i.e., frequent single marks, we navigate each hub of each tree to make a modified record structure for every unique name showing up in the trees. In particular, for every unique name, we keep up a rundown of IDs of supporting trees, meant by STL, in which the name shows up. By contrasting its |STL| and the given minsup, we can choose whether the mark is frequent or not. After all frequent 1-subtrees have been found, we can utilize the leg connection administer to join one hub to another to frame a 2-subtree having a parent-youngster combine. For each of the 2-subtrees, we play out the inserting recognition test and bolster counting to see if the pattern is frequent or not. Every one of the 2-subtrees are naturally canonicalized, in light of the fact that there is just a single topology for any 2-subtree, where one hub is the root and the other hub is the offspring of the root. See that diverse hubs may have a similar name; accordingly, all-to-all connections are utilized here to abstain from missing any competitor 2-subtrees. Beginning from frequent 2-subtrees, amid each of the subsequent cycles, the calculation calls the subroutine GENERATE_SUBTREES to become frequent subtrees level by level through pairwise joining and leg connection strategies.
See that when |FSTk| achieves zero, not any more frequent (k + 1)- subtrees can be produced and henceforth the finding procedure ends. If it's not too much trouble see that |FSTk| can be as little as one to permit self-joining and leg connection operations. The GENERATE_SUBTREES module in Fig. 3 is the basic piece of the calculation. This module is contained the accompanying functions: 1) proportionality class readiness; 2) competitor era (development); and 3) hopeful inserting recognition, all of which have been examined in the past subsections. The primary function isolates the frequent k-subtrees into various proportionality classes. The second and third functions are executed consecutively on each recently produced (k + 1)- subtree; the competitor created from the extension function will be passed to the applicant installing recognition function. The calculation in Fig. 13 additionally demonstrates how the convergence rundown of two event records (i.e., supporting trees records) ought to be utilized to skip unnecessary developments and how bolster counting is accomplished for a competitor pattern.
IV.
EXPERIMENTAL RESULTS
The running time of FRESTM on the datasets. It can be seen from the figure 4 that the time required by FRESTM. Scales up straightly as for the dataset estimate. This happens on the grounds that the more trees a dataset has the additional time is required for figuring event number of applicant sub-tree in the dataset.
Figure 4. Effect of dataset size on the running time of FRESTM
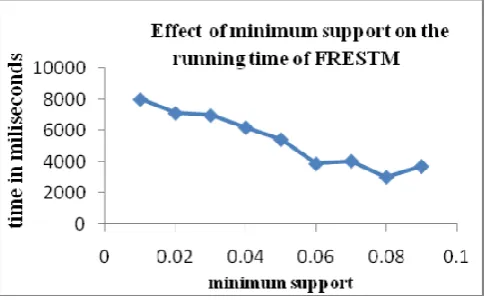
With little least, bolster esteem many long patterns with various marks were found by our calculation. As a result, much time was spent in finding these long patterns. Then again, with a substantial least bolster esteem the running time of our calculation diminished as few patterns fit the bill to be arrangement. As appeared in figure 5.
Figure 6. Effect on minimum support on the number of frequent Patterns
The quantity of frequent patterns recognized by the calculation diminishes as the base bolster esteem expands that is estimation of least bolster builds the sub-tree produced gets diminish. As appeared in figure 6.
V.
CONCLUSION
There are various tree mining calculations that work either on requested or unordered trees yet in this paper, we formalize a restrictedly embedded subtree mining issue, which has applications in numerous spaces where data can be spoken to as unrooted marked unordered trees. We take in the properties of the standard type of unordered trees and propose new tree extension systems that can effectively and proficiently produce all competitor subtrees. At that point, we present a limited alter remove based method to recognize the restrictedly installing connection between a pattern tree and a data tree. We plan an Apriori based calculation, FRESTM, to answer the tree mining issue. To the best of our insight, this is the primary calculation for finding restrictedly embedded subtree patterns in numerous Un-rooted unordered trees. Test result on certifiable data set gives great execution of our framework.
VI.REFERENCES
[1] Sen Zhang, Zhihui Du, and Jason T. L. Wang, “New Techniques for Mining Frequent Patterns in Unordered Trees,” IEEE TRANSACTIONS ON CYBERNETICS, VOL. 45, NO. 6 , pp. 1113–1125, JUNE 2015.
[2] M. H. Chehreghani, C. Lucas, and M. Rahgozar, “OInduced: An efficient algorithm for mining induced patterns from rooted ordered trees,” IEEE Trans. Syst., Man, Cybern. A, Syst. Humans, vol. 41, no. 5, pp. 1013– 1025, Sep. 2011.
[3] S. Zhang and J. T. L. Wang, “Discovering frequent agreement subtrees from phylogenetic data,” IEEE Trans. Knowl. Data Eng., vol. 20, no. 1, pp. 68–82, Jan. 2008.
[4] Y. Chi, Y. Xia, Y. Yang, and R. R. Muntz, “Mining closed and maximal frequent subtrees from databases of labeled rooted trees,” IEEE Trans. Knowl. Data Eng., vol. 17, no. 2, pp. 190–202, Feb. 2005.
[5] M. J. Zaki, “Efficiently mining frequent trees in a forest: Algorithms and applications,” IEEE Trans. Knowl. Data Eng., vol. 17, no. 8, pp. 1021–1035,Aug. 2005.
[6] K. G. Khoo and P. N. Suganthan, “Structural pattern recognition using genetic algorithms with specialized operators,” IEEE Trans. Syst., Man, Cybern. B, Cybern., vol. 33, no. 1, pp. 156–165, Feb. 2003. “Exact and approximate algorithms for unordered tree matching,” IEEE Trans. Syst., Man, Cybern., vol. 24, no. 4, pp. 668–678, Apr. 1994.
[9] J. T. L. Wang, K. Zhang, K. Jeong, and D. Shasha, “A system for approximate tree matching,” IEEE Trans. Knowl. Data Eng., vol. 6, no. 4, pp. 559–571, Aug. 1994. [10] Y. Chi, Y. Yang, and R. R. Muntz, “HybridTreeMiner: An efficient algorithm for mining frequent rooted trees and free trees using canonical forms,” in Proc. 16th Int. Conf. Sci. Statist. Datab. Manage., Santorini Island, Greece, Jun. 2004.
[11] A. Jiménez, F. Berzal, and J. Cubero, “POTMiner: Mining ordered, unordered, and partially-ordered trees,” Knowl. Inf. Syst., vol. 23, no. 2, May 2010, pp. 199–224. [12] M. L. Lee, L. H. Yang, W. Hsu, and X. Yang, “XClust: Clustering XML schemas for effective integration,” in Proc. 11th ACM Int. Conf. Inf. Knowl. Manage., McLean, VI, USA, Nov. 2002.
[13] L. Liu and J. Liu, “Mining frequent embedded subtree from tree-like databases,” in Proc. Int. Conf. Internet Comput. Inf. Serv., Hong Kong, Sep. 2011.
[14] S. Nijssen and J. N. Kok, “Efficient discovery of frequent unordered trees,” in Proc. 1st Int. Workshop Mining Graphs, Trees, Sequences (MGTS), 2003. [15] D. Shasha, J. T. L. Wang, and S. Zhang, “Unordered tree
mining with applications to phylogeny,” in Proc. IEEE Int. Conf. Data Eng., Boston, MA, USA, pp. 708–719, 2004.
[16] L. Zou, Y. Lu, H. Zhang, R. Hu, and C. Zhou, “Mining frequent induced subtree patterns with subtree-constraint,” in Proc. 6th IEEE Int. Conf. Data Mining (ICDM) Workshop, Hong Kong, Dec. 2006.