International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
338
Robust Logo Matching and Recognition Based on Context
Dependency Similarity in Video Application
Suma R
1, Anita George
21Assistant Professor, 2PG Scholar, Computer Science and Engineering, St. Joseph’s College of Engineering and Technology,
Pala
Abstract— Logo matching and recognition is important for
brand advertising and surveillance applications and it discovers either improper or non-authorized use of logos. An effective method of logo matching and recognition for detecting logos in videos is proposed. Reference logos and logos extracted from the test video are seen as constellations of local features (interest points, regions, etc.).Scale Invariant feature Transform can robustly identify objects even among clutter and under partial occlusion and is invariant to uniform orientation, scaling and partially invariant to affine distortion and illumination changes. Context is a collection of interest points and Context Dependent Similarity Matrix is created to find interest point correspondences between two images in order to tackle logo detection.
Keywords— Context, Context Dependent Similarity,
interest points, logo detection and recognition, Matching
I. INTRODUCTION
Logos are graphic productions that emphasize a name,recall some real world objects or will simply display some abstract signs that have strong perceptual appeal. Logos often appear in images or videos of real world indoor or outdoor scenes superimposed on objects of any geometry,jerseys of players,shirts of persons,boards of shops or billboards and posters in sports playfields etc.A registered logo is unique to a company or institution and is a legal symbol used for example, for the identification of a company's products. Many people and organizations deal with logos, either in mass communication or business. The graphic layout is equally important to attract the attention of the customer and convey the message permanently and appropriately. In industry and commerce, they have the essential role to recall in the customer the expectations associated with a particular product or service.This economical relevance has motivated the active involvement of companies in soliciting smart image analysis solutions to scan logo archives to find evidence of similar or already existing logos, discover either improper or non-authorized use of their logo, unveil the malicious use of logos that have small variations with respect to the originals so to deceive customers, analyze videos to get statistics about how long time their logo has been displayed.
(a)
(b)
Fig. 1. (a) Examples of popular logos depicting real world objects, text, graphic signs, and complex layouts with graphic details. (b) Pairs
of logos with malicious small changes in details or spatial arrangements.
Logo detection and recognition in these scenarios has become important for a number of applications[1]. Among them, several examples such as the automatic identification of products on the web to improve commercial search-engines, the verification of the visibility of advertising logos in sports events are reported.
The proposed logo matching can be divided into three steps: 1) Video frames extraction 2) Context extraction 3) Matching. This paper is organized into five sections. In the next section some related works are discussed. Section III will describe the proposed method in details, and in Section IV, experimental results is shown. The section V presents our conclusions and last section tells about future scope.
II. RELATED WORKS
[image:1.612.335.549.241.417.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
339
A generic system for logo detection and recognition in images taken in real world environments must comply with contrasting requirements. On the one hand, invariance to a large range of geometric and photometric transformations is required to comply with all the possible conditions of image/video recording. Since in real world images logos are not captured in isolation, logo detection and recognition should also be robust to partial occlusions.Nowadays a large number of logo matching schemes are available.
In clustering based logo matching method[2] both test image and reference image may undergo both horizontal and pyramidal decomposition.This method undergo fusion of both reference image and test image.DWT(Discrete wavelet transform) can be used for fusing both test and reference image.A clustering algorithm called FCA(fuzzy clustering algorithm) is used for clustering matched area and unmatched area.
In content-based logo matching scheme[3]each image of the logo database is decomposed into its image components, i.e., its connected components. The abstract representation of image components is known as their Fourier descriptors.The contour points can be transformed into the frequency domain by the Discrete Fourier Transformation (DFT). The result can be transformed back into the spatial domain via the Inverse Discrete Fourier Transformation (IDFT) without any loss.It is a fast process but it is not invariant to translation,rotation,scalability.
In triangulation based logo matching scheme[4] a scalable logo recognition approach that extends the common bag-of-words model and incorporates local geometry in the indexing process.Features are locally grouped in triples using multi-scale Delaunay triangulation and represent triangles by signatures capturing both visual appearance and local geometry. Each class is represented by the union of such signatures over all instances in the class.The large scale recognition is a sub-linear search problem where signatures of the query image are looked up in an inverted index structure of the class models.
III. PROPOSED SYSTEM
This paper describes a new logo matching scheme based on image features extracted using SIFT[8](Scale invariant feature Transform) algorithm and matching is based on CDS(Context Dependent Similarity Matrix)[1].There will be logo image as reference image and a video for testing the genuinality of the logos.Matching between this reference image and the video is done.Video frames are extracted from the test video.Context of reference image and all the frames in the video are extracted.
Matching between the video frames and reference image is done. SIFT features are invariant to image scaling and rotation, and partially invariant to change in illumination and 3D camera viewpoint. They are well localized in both the spatial and frequency domains, reducing the probability of disruption by occlusion, clutter or noise.
A. Context Extraction
The scale invariant feature transform (SIFT) algorithm is used for context extraction.SIFT is invariant to image translation, scaling,rotation and partially invariant to illumination changes and affine projection. The context[1] is defined by the local spatial configuration of interest points in both SX and SY .SX corresponds to the reference image and SY corresponds to testing frame from the video.Formally, in order to take into account spatial information, an interest point xi ∈SX is defined as
xi = (ψg(xi ),ψf (xi ),ψo(xi ),ψs (xi ),ω(xi )) (1)
Where the symbol ψg(xi ) ∈ R 2 stands for the 2D
coordinates of xi while ψf (xi ) ∈ R c corresponds to the feature of xi (in practice c is equal to 128, i.e. the coefficients of the SIFT descriptor ). We have also an extra information about the orientation of xi (denoted ψo(xi ) ∈ [−π,+π]) which is provided by the SIFT gradient and about the scale of the SIFT descriptor (denoted ψs (xi )). Finally, we use ω(xi ) to identify the image from which the interest point comes from, so that two interest points with the same location, feature and orientation are considered different when they are not in the same image.
(a) (b)
Fig. 2. (a) Reference logo image (b) Testing Frame extracted from the Video.
Calculation of SIFT image features is performed through the three consecutive steps which are briefly described in the following:
[image:2.612.340.543.485.610.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
340
For this, the image is convolved with Gaussian filters at different scales, and then the difference of successive Gaussian-blurred images are taken. Keypoints are then taken as maxima/minima of the Difference of Gaussians (DoG) that occur at multiple scales. Specifically, a DoG image D(x,y,σ) is given by
D(x,y,σ) = L(x,y,kiσ) - L(x,y,kjσ) (2)
Where L(x,y,kσ) is the convolution of the original image I(x,y) ,with the Gaussian blur G(x,y,kσ) at scale kσ
i.e., L(x,y,kσ) * I(x,y) (3)
Hence a DoG image between scales kiσ and kjσ is just
the difference of the Gaussian-blurred images at scales kiσ
and kjσ. The convolved images are grouped by octave (an
octave corresponds to doubling the value of σ), and the value of ki is selected so that we obtain a fixed number of
convolved images per octave. Then the Difference-of-Gaussian images are taken from adjacent Difference-of-Gaussian-blurred images per octave.Once DoG images have been obtained, keypoints are identified as local minima/maxima of the DoG images across scales. This is done by comparing each pixel in the DoG images to its eight neighbors at the same scale and nine corresponding neighboring pixels in each of the neighboring scales. If the pixel value is the maximum or minimum among all compared pixels, it is selected as a candidate keypoint.
(a) (b)
Fig. 3. (a) Reference logo image keypoints (b) Testing Frame keypoints extracted from the video
Orientation assignment:In this step, each keypoint[8] is assigned one or more orientations based on local image gradient directions. This is the key step in achieving invariance to rotation as the keypoint descriptor can be represented relative to this orientation and therefore achieve invariance to image rotation.First, the Gaussian-smoothed image L(x,y,σ) at the keypoint's scale σ is taken so that all computations are performed in a scale-invariant manner.
For an image sample L(x,y) at scale σ, the gradient magnitude, m(x,y) , and orientation,θ(x,y) , are precomputed using pixel differences:
m(x,y) = (L(x+1,y) – L(x-1,y))2 + (L(x,y+1) – L(x,y-1))2 (4)
θ(x,y) = atan2 (L(x,y+1) – L(x,y-1),L(x+1,y) – L(x-1,y)) (5)
The magnitude and direction calculations for the gradient are done for every pixel in a neighboring region around the keypoint in the Gaussian-blurred image L. An orientation histogram with 36 bins is formed, with each bin covering 10 degrees. Each sample in the neighboring window added to a histogram bin is weighted by its gradient magnitude and by a Gaussian-weighted circular window with a that is 1.5 times that of the scale of the keypoint. The peaks in this histogram correspond to dominant orientations. Once the histogram is filled, the orientations corresponding to the highest peak and local peaks that are within 80% of the highest peaks are assigned to the keypoint. In the case of multiple orientations being assigned, an additional keypoint is created having the same location and scale as the original keypoint for each additional orientation.
[image:3.612.79.258.456.568.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
341
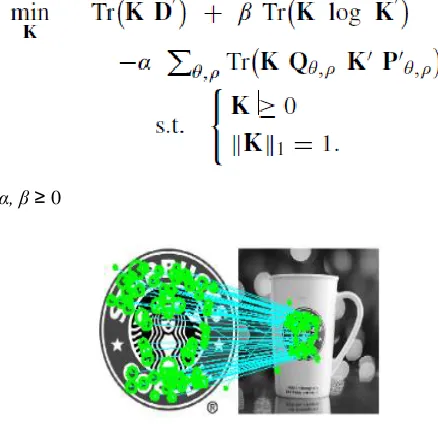
B. Context Dependent Similarity MatchingCDS matrix is created for finding interest point correspondences between two frames in order to tackle logo detection.Define k as a function which, given two interest points 𝑥,𝑦∈ 𝑆𝑋×𝑆𝑌 provides a similarity measure between them. For a finite collection of interest points, the sets 𝑆𝑋,𝑆𝑌 are finite.Function k as a matrix K that is
𝑲𝑥,𝑦=𝑘 𝑥,𝑦 in which the ― 𝑥.𝑦 element‖ is the similarity between x and y. Pθ,ρ, Qθ,ρ the intrinsic adjacency matrices that respectively collect the adjacency relationships
between the sets of interest points SX and SY , for each context segment,these matrices are defined as
Pθ,ρ,x,x_=gθ,ρ(x, x‘), Qθ,ρ,y,y‘ = gθ,ρ(y, y‘) where g is a
decreasing function of any (pseudo) distance involving (x, x‘), not necessarily symmetric.Similarity ‗K’ between two objects SX,SY is obtained by solving the minimization problem.
[image:4.612.49.268.355.576.2]α, β ≥ 0
Fig 4 : Context Dependent Matching
Algorithm for Context Dependent Similarity
Input:
Reference logo image: IX
Test frame: IY
CDS parameters: €, Na , Nr, α, β, τ.
Output:
A boolean value determining whether the reference logo in
IX is detected in IY .
Extract SIFT from IX , IY
Let SX := {x1, . . . , xn} and SY := {y1, . . . , ym} be respectively the list of interest points taken from both images
for i ← 1 to n do
Compute the context of xi, given €, Na , Nr ;
for j ←1 to m do
Compute the context of y j, given €, Na , Nr ;
Set t ←1, maxt ←30;
repeat
for i ←1 to n do
for j ←1 to m do
Compute CDS matrix entry K (t) xi ,y j, given α, β;
Set t ←t + 1;
until convergence (i.e., ||K(t ) − K(t−1)||2 ≠ 0) OR
t > maxt ;
K ← K(t);
for i ← 1 to n do
for j ←1 to m do
Compute Ky j | xi ←Kxi ,y j / ∑ m s=1 Kxi ,ys
A match between xi and y j is declared iff
Ky j |xi >=∑ms=j Kys | xi ;
if number of matches in SY > τ |SX | then
return true i.e. logo detection
else
return false;
It appears clearly that the context term is highly influential and that the probability of finding correct matches is dependent on setting of the parameters α/β and q
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
342
IV. EXPERIMENT RESULTS
[image:5.612.65.277.331.476.2]We compare our proposed matching and detection procedure against video google matching method and with RANSAC[6] verification. RANSAC based logo detection introduces a model(transformation) based criterion not necessarily consistent in practice. This criterion selects only the matches that satisfy an affine transformation between reference logos and test video. The Video Google[7] approach is closely related to our method as it introduces a spatial consistency criterion, according to which only the matches which share similar spatial layouts are selected .Experiments were conducted on MICC-logo dataset(as reference logo images) and advertisement videos from youtube .We had also tested video frames with partial appearance, perspective transformations, and low resolution to demonstrate the generality of our method.
Fig 5: Performance of our approach on the MICC logo dataset(as reference logo) and test frames from youtube advertisement videos in
case of partial appearance, perspective transformations, and low resolution .CDS is computed using α = β = 0.1, Nr = Na = 8, and τ =
0.5.
V. CONCLUSION
We introduced in this work a novel logo detection and localization approach based on a new class of similarities referred to as context dependent.
The strength of the proposed method resides in several aspects: (i) the inclusion of the information about the spatial configuration in similarity design as well as visual features, (ii) the ability to control the influence of the context and the regularization of the solution via our energy function, (iii) the tolerance to different aspects including partial occlusion, makes it suitable to detect both near-duplicate logos as well as logos with some variability in their appearance,the probability of success of matching and detection is high.
VI. FUTURE SCOPE
Further extensions of this work include the refinement of the definition of context in order to handle other rigid and non-rigid logo transformations.
REFERENCES
[1] Hichem Sahbi, Lamberto Ballan Giuseppe Serra, and Alberto Del Bimbo‖ Context-Dependent Logo Matching and Recognition‖IEEE Trans.Image processing, vol. 22, no. 3, march 2013
[2] A. Smeulders, M. Worring, S. Santini, A. Gupta, and R. Jain, ―Clustering based logo matching scheme ,‖ IEEE Trans. Pattern Anal. Mach. Intell., vol. 22, no. 12, pp. 1349–1380, Dec. 2000. [3] R. Datta, D. Joshi, J. Li, and J. Z. Wang, ―Content based logo
matching scheme: Ideas, influences, and trends of the new age,‖ ACM Comput. Surv., vol. 40, no. 2, pp. 1–60, 2008
[4] Yannis Kalantidis , Lluis Garcia Pueyo‖Scalable Triangulation-based Logo Recognition‖ National Technical University of Athens [5] R. Fergus, P. Perona, and A. Zisserman, ―Object class recognitionby
unsupervised scale-invariant learning,‖ in Proc. Conf. Comput. Vis. Pattern Recognit., vol. 2. Madison, WI, 2003, pp. 264–271. [6] J. Sivic and A. Zisserman, ―Efficient visual search of videos cast as
text retrieval,‖ IEEE Trans. Pattern Anal. Mach. Intell., vol. 31, no. 4, pp.591–606, Apr. 2009.
[7] A. Joly and O. Buisson, ―Logo retrieval with a contrario visual query expansion,‖ in Proc. ACM Multimedia, Beijing, China, 2009, pp. 581–584.