BanditSum: Extractive Summarization as a Contextual Bandit
Full text
Figure
Related documents
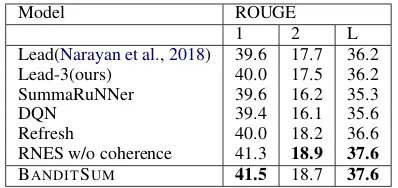
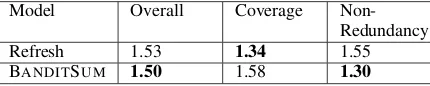
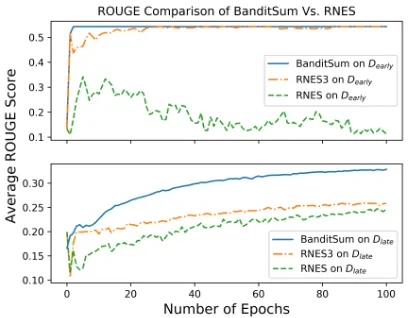
In this paper we argue that cross-entropy train- ing is not optimal for extractive summarization. Models trained this way are prone to generating verbose summaries with
Using Argumentative Zones for Extractive Summarization of Scientific Articles Proceedings of COLING 2012 Technical Papers, pages 663?678, COLING 2012, Mumbai, December 2012
Extractive summarization can be regarded as a classification problem. Given the features of a sentence, a machine-learning based classification model will judge how likely
While it is natural and tempting to view the linked web page as the source text from which the tweet is generated in an extractive summarization setting, it is unclear to what
Our contributions in this work are three-fold: a novel application of reinforcement learning to sen- tence ranking for extractive summarization; cor- roborated by analysis and
Fi- nally, we demonstrate that using EDUs as units of content selection instead of sentences leads to stronger summarization performance on these near-extractive datasets under
In this work, we model personalized recommendation of news articles as a contextual bandit problem, a principled approach in which a learning algorithm sequentially selects articles
According to number of document summarization may be single document or multi document, if we wants to classify according to approached then it may be
