Rating Prediction based on Social User Reviews
V.R.R Lakshmi Kumari & E. Krishnaveni Reddy
1M. Tech Student, Department of CSE, Sridevi Women’s Engineering College, Village VattiNagulaPally,
Mandal Rajendra Nagar, District RangaReddy, Telangana, India.
2Associate Professor, Department of CSE, Sridevi Women’s Engineering College, Village VattiNagulaPally,
Mandal Rajendra Nagar, District RangaReddy, Telangana, India.
Abstract - Clients have seen a twist of survey sites. It introduces an extraordinary chance to share
client perspectives for different items client buy.
Client confront the data over-burdening issue. To
mine important data from surveys to comprehend a
client's inclinations and make a precise proposal is
critical. Customary recommender frameworks (RS)
think of some as components, for example, client's
buy records, item classes and geographic area. A
notion based rating expectation strategy (RPS) to
enhance forecast exactness in recommender
frameworks. Right off the bat, a social client
nostalgic estimation approach and ascertain every
client's notion on things/items. Furthermore, client
consider a client's own nostalgic properties as well
as mull over relational wistful impact. At that point,
client consider item notoriety, which can be
gathered by the nostalgic circulations of a client set
that mirror client's thorough assessment. Finally,
client combine three variables client assessment
similitude, relational nostalgic impact, and thing's
notoriety comparability into our recommender
framework to make an exact rating forecast. Client
direct an execution assessment of the three wistful
factors on a certifiable dataset gathered from Yelp.
Test comes about demonstrate the opinion can well
portray client inclinations, which help to enhance
the suggestion execution.
Keywords - Thing notoriety, Reviews, Rating expectation, Recommender framework, Sentiment
impact, User slant.
1. INTRODUCTION
Client proposed an opinion based rating
expectation technique in the system of grid
factorization. Clients make utilization of social
clients slant to gather evaluations. To start with,
client separate item highlights from client audits.
At that point, client discover the estimation words,
which are utilized to depict the item highlights. In
addition, client use assessment word references to
figure estimation of a particular client on a
thing/item. The fundamental commitments are as
per the following client propose a client wistful
estimation approach, which depends on the mined
notion words and conclusion degree words from
client audits. Client make utilization of notion for
rating forecast. Client slant likeness concentrates
on the client intrigue inclinations. Client opinion
impact reflects how the estimation spreads among
the put stock in clients. Thing notoriety closeness
demonstrates the potential significance of things.
Client meld the three elements client supposition
closeness, relational wistful impact, and thing
notoriety comparability into a probabilistic lattice
factorization system to do an exact suggestion. The
that client's social conclusion that client mined is a
key factor in enhancing rating forecast exhibitions.
2. RELATED WORK
As customers all know, it is an era of
information explosion, in which customer always
get huge amounts of information. Therefore, it is in
urgent need of picking out the useful and
interesting information quickly. Keeping in mind
the end goal to take care of this major issue,
suggestion framework emerges at the memorable
minute. Among the current suggestion calculations,
the thing based community oriented separating
proposal calculation is the most broadly utilized
one. Its principle is based on the user's evaluation
of items. The purpose is to find the similarity
between users, and recommend items to the target
user according to the records of the similar users.
However, the number of customers and products
keeps increasing at a high rate, which increases the
cost to find out the recommendation list for each
user. The efficiency of a single common computer
will not satisfy the requirement and the super
computer will cost too much. Keeping in mind the
end goal to take care of the issue, client propose to
utilize Map Reduce to execute the suggestion
framework. Besides, user distribute the job to some
computer clusters and the input file of the current
computer cluster only relies on the previous one or
the origin input. So the pipeline technology will be
adopted to improve the efficiency further. The
experiment shows that the method can merge the
ability of some common PC to process large-scale
data in a short time. Review expert collaborative
recommendation algorithm based on topic
relationship proposed by S. Gao, Z. Yu, L. Shi, X.
Yan, H. The project review information plays an
important role in the recommendation of review
experts. Customer aim to determine review expert's
rating by using the historical rating records and the
final decision results on the previous projects, and
by means of some rules, user construct a rating
matrix for projects and experts. For the data
sparseness problem of the rating matrix and the
"cold start" problem of new expert
recommendation, customer assume that those
projects/experts with similar topics have similar
feature vectors and propose a review experts
collaborative recommendation algorithm based on
topic relationship. Firstly, user obtain topics of
projects/experts based on latent Dirichlet allocation
(LDA) model, and build the topic relationship
network of projects/experts. At that point, through
the subject connection between
ventures/specialists, client discover a neighbour
gathering which imparts the biggest comparability
to target extend/master, and incorporate the
accumulation into the synergistic separating
proposal calculation in view of framework
factorisation. Finally, by learning the rating matrix
to get feature vectors of the projects and experts,
customer can predict the ratings that a target project
will give candidate review experts, and thus
achieve the review expert recommendation.
Investigations on genuine informational index
demonstrate that the proposed technique could
anticipate the audit master rating all the more
successfully, and enhance the suggestion impact of
survey specialists. Thing based community sifting
suggestion calculations proposed by Sarwar, G.
Karypis, J. Konstan, and J. Reidl. Recommender
frameworks apply learning revelation methods to
items or administrations amid a live collaboration.
These frameworks, particularly the k-closest
neighbor collective sifting based ones, are making
far reaching progress on the Web. The enormous
development in the measure of accessible data and
the quantity of guests to Web locales lately
represents some key difficulties for recommender
frameworks. These are creating superb proposals,
performing numerous suggestions every second for
many clients and things and accomplishing high
scope despite information sparsity. In customary
cooperative separating frameworks the measure of
work increments with the quantity of members in
the framework. New recommender framework
advances are required that can rapidly create
excellent proposals, notwithstanding for extensive
scale issues. To address these issues client have
investigated thing based synergistic separating
methods. Item based procedures initially break
down the client thing framework to recognize
connections between various things, and after that
utilization these connections to in a roundabout
way figure proposals for clients. Versatile
suggestion with social logical data proposed by M.
Jiang, P. Cui, F. Wang, W. Zhu, S. Yang
Exponential development of data produced by
online informal communities requests powerful and
versatile recommender frameworks to give helpful
outcomes. Conventional strategies wind up plainly
unfit in light of the fact that they overlook social
connection information; existing social suggestion
approaches consider informal organization
structure, however social logical data has not been
completely considered. It is critical and testing to
combine social relevant components which are
gotten from clients' inspiration of social practices
into social recommendation. User examine the
social proposal issue on the premise of brain
research and human science ponders, which display
two imperative variables: singular inclination and
social impact. Client initially display the specific
significance of these two factors in online conduct
expectation. At that point client propose a novel
probabilistic grid factorization strategy to
intertwine them in idle space. User further provide
a scalable algorithm which can incrementally
process the large scale data. User conduct
experiments on both Facebook style bidirectional
and Twitter style unidirectional social network data
sets. The empirical results and analysis on these
two large data sets demonstrate that method
significantly outperforms the existing approaches.
3. METHODOLOGY
The object is to discover successful pieces
of information from surveys and foresee social
client’s evaluations. Right off the bat remove item
highlights from client survey corpus, and afterward
client present the strategy for distinguishing social
clients assumption. Furthermore, client portray the
three wistful variables. Finally client combine
every one of them into assessment based rating
expectation strategy (RPS). The following
sub-sections describe more details. A. Extracting
Product Features Product features mainly focus on
the discussed issues of a product. User extract
product features from textual reviews using LDA
[11]. User mainly want to get the product features
including some named entities and some
product/item/service attributes. LDA is a Bayesian
model, which is utilized to model the relationship
of reviews, topics and words. In Fig. 1, the shaded
unshaded variables indicate the latent variables.
The bolt demonstrates a contingent reliance
between the factors and plates spoke to by the
case.
Fig1: LDA Graphical Representation
𝐕: the vocabulary, it has 𝑁𝑑 different
words. Each word is presented by the
corresponding label {1,2,⋯,𝑁𝑑 }.𝒘𝒊 ∈ {1,2,⋯,𝑁𝑑
}: the word, each word of a review is mapped to 𝑽
whose size is 𝑁𝑑 through character
matching.𝒅𝑚:the document/review of a user, it
corresponds to a word set of the review. A user
with only one document. All documents denote as
𝐷 = {𝑑1,𝑑2,⋯,𝑑𝑀}. 𝚪: the number of topics (const
scalar).𝛉->𝐦:the multinomial distribution of topics
specific to the document 𝑚.One proportion for each
document, Θ = {𝜃𝑚}𝑚=1 𝑀 (𝑀×𝛤 matrix) 𝛗⃗⃗⃗ 𝐤: the component for each topic, Φ = {𝜑⃗𝑘}𝑘=1 𝛤
(𝛤 × 𝑘 matrix) 𝒛𝒎,𝒏: the topic associated with the
𝑛-𝑡ℎ token in the document 𝑚. 𝒂,𝒃: Dirrichlet
priors to the multinomial distribution 𝜃 𝑚 and 𝜑 ⃗
𝑘.
4. SENTIMENT BASED RECOMMENDER MODEL
After taking the three sentimental factors
above into consideration, User have three important
constrain terms in rating prediction model. They
are: 1) Normalized user sentiment similarity 𝐶𝑢,𝑣∗
. 2) Normalized interpersonal sentiment influence
𝑆𝑢,𝑣 ∗ . 3) Normalized item reputation similarity
𝐼𝑖,𝑗 ∗ . As per the network factorization, we
intertwine the three components into the target
work as takes after: 𝛹(𝑹,𝑼,𝑷) = 1 2 ∑ (𝑅 ̂𝑢,𝑖
−𝑅𝑢,𝑖)2 +𝑢,𝑖 𝜆 2(‖𝑼‖𝐹 2 +‖𝑷‖𝐹 2) +𝛼 2 ((𝑈𝑢 −∑
𝐶𝑢,𝑣∗𝑣𝑈𝑣)(𝑈𝑢 −∑ 𝐶𝑢,𝑣∗𝑣𝑈𝑣)𝑇)𝑢 +𝛽 2∑ ((𝑈𝑢
−∑ 𝑆𝑢,𝑣∗ 𝑣𝑈𝑣)(𝑈𝑢 −∑ 𝑆𝑢,𝑣∗𝑣 𝑈𝑣)𝑇)𝑢 +𝛾 2∑
((𝑃𝑖 −∑ 𝐼𝑖,𝑗∗𝑗𝑃𝑗)(𝑃𝑖 −∑ 𝐼𝑖,𝑗∗𝑗𝑃𝑗)𝑇) ...Eq.(1)
Where 𝑅 ̂𝑢,𝑖 is the predicted rating value according
to Eq.(1). 𝑅𝑢,𝑖 is user u’s real ratings on item i, and
𝑅𝑢,𝑖 ∈ 𝑹𝑚×𝑛. 𝑼𝑚×𝑘 and 𝑷𝑛×𝑘 denote user
Potential Eigen vector and item Potential Eigen
vector respectively. 𝑈𝑢 and 𝑃𝑖 are k-dimensional
client particular and thing particular inert
component vectors of client u and thing i, and it is
the rank of the inactive frameworks 𝑼𝑚×𝑘 and
𝑷𝑛×𝑘. They are gotten by the inclination plunge
strategy [8]. The main term of Eq.(1) indicates the
deviation between the real appraising and forecast
score, the second thing of Eq.(1) is a regularization
term, which assumes a part if there should be an
occurrence of over-fitting. The idea of user
sentiment similarity is enforced by the third term,
which says that if two users have similar sentiment,
they may have similar latent feature 𝑈𝑢. The factor
of interpersonal sentiment influence is enforced by
the forth term, which means if a friend of the user
has clear like and dislike sentiment, the user may
trust him/her more. The idea of item reputation
similarity is enforced by the last term, which says
that if two items have similar reputation, they may
have similar latent feature 𝑃.
User get the corresponding matrix
factorization model as Eq(1), from which user can
obtain user latent profile 𝑈𝑢 and item latent profile
𝑃 𝑖 by optimization. The objective function is
minimized by the gradient decent approach. More
formally, the gradients of the objective function
with respect to the variables 𝑈𝑢 and 𝑃𝑖 are shown
as Eq(2) and Eq(3) respectively:
where 𝐹𝑣 denotes user v’s friends, similarly, 𝐹𝑖
denotes item i’s virtual friends. The underlying
estimations of 𝑈𝑢 and 𝑃 𝑖 are inspected from the
typical dispersion with zero mean. The client and
thing idle element vectors 𝑈𝑢 and 𝑃𝑖 are refreshed
in light of the past qualities to protect the speediest
diminishing of the target work at every cycle. User
set the step size ℓ=0.0002 and the iteration number
𝜏=500 to insure the decrease of the objective
function in training.
Sentiment Evaluation
Customer shall note that, the task of
phrase-level feeling dictionary development is
innately troublesome. Client need to exchange off
amongst accuracy and review. As an essential
stride towards utilizing assumption vocabulary for
RPS, client concentrate on the exactness as client
will just utilize the best 10 item highlights in
system, basically to avoid the negative effects of
wrong features as much as possible. Client expect
as the exploration in opinion investigation
progresses, the execution of structure will
additionally enhance also. Like [16], client assess
the opinion by changing every notion esteem 𝐸𝑢,𝑖
into a twofold esteem, specifically, 𝐸𝑢,𝑖 > 0, an
audit will be viewed as positive; 𝐸𝑢,𝑖 ≤ 0, a review
will be regarded as negative. When testing in a
labelled positive dataset, 𝐸𝑢,𝑖 ≤ 0, this case is
misclassification; When testing in a labelled
negative dataset, 𝐸𝑢,𝑖 > 0, this case is also the
misclassification. Client initially name each of the
5-star Yelp surveys as positive audits and name
every one of the 1-star Yelp surveys as negative
audits. Altogether, client have 57,193 positive
audits and 9,799 negative surveys. The insights and
assessment aftereffects of estimation calculation.
Client can see that the normal exactness on Yelp
dataset is 87.1%. The exactness on negative audit
corpus is 60.16%. However, sentiment algorithm
performance well on a larger positive review
corpus, the precision is 91.75%. With a specific
end goal to better assess assumption calculation,
client test opinion calculation on the other two open
datasets. Both of the two public datasets have the
same number of labelled positive reviews and
labelled negative reviews, the average precision is
72.7% and 73.5% respectively. User can also see
that sentiment algorithm performs better on
positive review corpus than negative review
corpus.
The product features that user cares about
are collected in the cloud including the words
“Brand”, “Price”, and “Quality”, etc. By separating
client supposition words from client audits, client
develop the opinion lexicons. What's more, the last
client is occupied with those item highlights, so in
light of the client audits and the feeling word
references, the last thing will be prescribed
appeared in Fig 2.
Fig 2:Construction of Sentiment dictionaries
Results
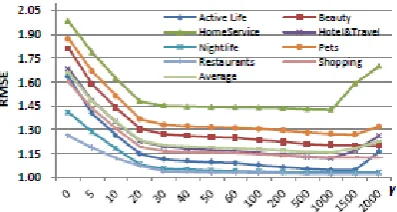
Fig 3:RMSE line chart of impact of item reputation
similarity factor on eight characters of yelp.
To discuss the impact of item reputation
similarity, we set α=0, 𝛽=0, and let 𝛾 ranges from
0 to 2000. From Fig.3 ,we can see that the RMSE
drops when 𝛾 ranges from 0 to 1000. Besides, the
RMSE increases in different degrees from 𝛾 =1000
to 2000 because of over-fitting. The average RMSE
of model under 𝛾=1000 is 1.156. Compared with
Basic MF, the average RMSE decreases about
30.2%. The result suggests that the item reputation
similarity can improve the performance of rating
prediction.
6. CONCLUSION
A suggestion show is proposed by mining
conclusion data from social clients audits. Client
combine client slant similitude, relational opinion
impact, and thing notoriety closeness into a bound
together network factorization system to
accomplish the rating expectation errand.
Specifically, client utilize social clients feeling to
indicate client inclinations. Besides, user
manufacture another relationship named relational
feeling impact between the client and companions,
which reflects how client’s companions impact
clients in a nostalgic point. Client acquire client's
printed surveys, client can quantitively gauge
client's opinion, and client use things' feeling
circulation among clients to gather thing's
notoriety. The test comes about exhibit that the
three wistful components make extraordinary
commitments to the rating expectation.
Additionally, it indicates noteworthy changes over
existing methodologies on a genuine dataset. In
future work,user can consider more semantic tenets
while investigating the specific circumstance, and
fine-grained assessment examination. In addition,
client can adjust or create other crossover
factorization models, for example, tensor
factorization or profound learning method to
coordinate expression level assumption
investigation.
7. REFERENCES
[1] R. Salakhutdinov, and A. Mnih, "Probabilistic
lattice factorization," in NIPS, 2008.
[2] X. Yang, H. Steck, and Y. Liu, "Circle-based
proposal in online interpersonal organizations, " in
Proc. eighteenth ACM SIGKDD Int. Conf. KDD,
New York, NY, USA, Aug. 2012, pp. 1267–1275.
[3] M. Jiang, P. Cui, R. Liu, Q. Yang, F. Wang, W.
Zhu, and S. Yang, "Social relevant proposal," in
proc. 21st ACM Int. CIKM, 2012, pp. 45-54.
[4] M. Jamali and M. Ester, "A framework
factorization system with trust proliferation for
proposal in informal communities," in Proc. ACM
conf. RecSys, Barcelona, Spain. 2010, pp. 135-142.
[5] Z. Fu, X. Sun, Q. Liu, et al., "Accomplishing
Efficient Cloud Search Services: Multi-Keyword
Ranked Search over Encrypted Cloud Data
Supporting Parallel Computing," IEICE
Transactions on Communications, 2015,
98(1):190-200.
[6] G. Ganu, N. Elhadad, A Marian, "Past the stars:
Improving rating expectations utilizing Review
content substance," in twelfth International
Workshop on the Web and Databases (WebDB
2009). pp. 1-6.
[7] J. Xu, X. Zheng, W. Ding, "Customized
proposal in light of surveys and evaluations
reducing the sparsity issue of community oriented
separating," IEEE International Conference on
e-business Engineering. 2012, pp. 9-16.
[8] X. Qian, H. Feng, G. Zhao, and T. Mei,
"Customized proposal consolidating client intrigue
and group of friends," IEEE Trans. Information and
information building. 2014, pp. 1763-1777.
[9] H. Feng, and X. Qian, "Proposal by means of
client's identity and social relevant," in Proc. 22nd
ACM worldwide gathering on data and information
administration. 2013, pp. 1521-1524.
[10] Z. Fu, K. Ren, J. Shu, et al., "Empowering
Personalized Search over Encrypted Outsourced
Data with Efficiency Improvement," IEEE
Transactions on Parallel and Distributed Systems,
2015:1-1.
[11] D.M. Blei, A.Y. Ng, and M. I. Jordan,
"Inactive Dirichlet Allocation," Journal of machine
learning research 3. 2003, pp. 993-1022.
[12] W. Zhang, G. Ding, L. Chen, C. Li , and C.
Zhang, " Generating virtual evaluations from
Chinese surveys to increase online proposals,"
ACM TIST, vol.4, no.1. 2013, pp. 1-17.
[13] Z. Xia, X. Wang, X. Sun, and Q. Wang, "A
Secure and Dynamic Multi-catchphrase Ranked
Search Scheme over Encrypted Cloud Data," IEEE
Transactions on Parallel and Distributed Systems,
[14] J. Weston, R. J. Weiss, H. Yee, "Nonlinear
idle factorization by installing different client
interests," seventh ACM, RecSys, 2013, pp. 65-68.
[15] J. Huang, X. Cheng, J. Guo, H. Shen, and K.
Yang, " Social proposal with relational impact," in
Proc. ECAI, 2010, pp. 601-606.
[16] Y. Lu, M. Castellanos, U. Dayal, C. Zhai,
"Programmed development of a setting mindful
feeling dictionary: an enhancement approach,"
World Wide Web Conference Series. 2011, pp.
347-356.
[17] T. Kawashima, T. Ogawa, M. Haseyama, "A
rating forecast strategy for web based business
application utilizing ordinal relapse in light of LDA
with multi-modular components," IEEE second
Global Conference on Consumer Electronics
(GCCE). 2013, pp. 260-261.
[18] K.H. L. Tso-Sutter, L. B. Marinho, L.
Schmidt-Thieme, "Tag-mindful recommender
frameworks by combination of community oriented
separating calculations," in Proceedings of the 2008
ACM symposium on Applied registering, 2008, pp.