Platforms for HPJava: Runtime Support
for Scalable Programming in Java
Sang Boem Lim
Contents
n
Overview of HPJava
n
Library support for HPJava
n
High-level APIs
n
Low-level API
n
Applications and performance
nContributions
Goals
n Our research is concerned with enabling parallel, high-performance
computation--in particular development of scientific software in the network-aware programming language, java.
n Issues concerned with the implementation of the run-time environment
underlying HPJava.
n High-level APIs (e.g. Adlib)
n Low-level API for underlying communications (e.g. mpjdev)
n Adlib is the first application-level library for HPspmd mode.
n The mpjdev API is a underlying communication library to perform actual
communications.
n Implementations of mpjdev:
n mpiJava-based implementation
n Multithreaded implementation
n LAPI implementation
SPMD Parallel Computing
n SIMD– A single control unit dispatches instructions to each processing
unit.
n e.g.) Illiac IV, Connection Machine-2, ect. n introduced a new concept, distributed arrays
n MIMD– Each processor is capable of executing a different program
independent of the other processors.
n asynchronous, flexible, but hard to program n e.g.) Cosmic Cube, Cray T3D, IBM SP3, etc.
n SPMD– Each processor executes the same program asynchronously.
Synchronization takes place only when processors need to exchange data.
n loosely synchronous model (SIMD+MIMD)
n HPF - an extension of Fortran 90 to support the data parallel
Motivation
n SPMD (Single Program, Multiple Data) programming has been
very successful for parallel computing.
n Many higher-level programming environments and libraries
assume the SPMD style as their basic model—ScaLAPACK, DAGH, Kelp, Global Array Toolkit.
n But the library-based SPMD approach to data-parallel
programming lacks the uniformity and elegance of HPF.
n Compared with HPF, creating distributed arrays and accessing
their local and remote elements is clumsy and error-prone.
n Because the arrays are managed entirely in libraries, the
compiler offers little support and no safety net of compile-time or compiler-generated run-time checking.
n These observations motivate our introduction of the HPspmd
model—direct SPMD programming supported by additional syntax for HPF-like distributed arrays.
HPspmd
n
Proposed by Fox, Carpenter, Xiaoming Li
around 1998.
n
Independent processes executing same
program, sharing elements of distributed
arrays described by
special syntax
.
n
Processes operate directly on locally owned
elements. Explicit communication needed in
program to permit access to elements owned
by other processes.
n
Envisaged bindings for base languages like
HPJava—Overview
n
Environment for parallel programming.
n
Extends Java by adding some predefined
classes and some extra syntax for dealing
with distributed arrays.
n
So far the only implementation of
HPspmd
model.
n
HPJava program translated to standard Java
program which calls
communication libraries
and parallel runtime system.
HPJava Example
Procs p = new Procs2(2, 2);
on(p) {
Range x = new ExtBlockRange(M, p.dim(0), 1), y = new ExtBlockRange(N, p.dim(1), 1); float [[-,-]] a = new float [[x, y]];
. . . Initialize edge values in ‘a’ (boundary conditions)
float [[-,-]] b = new float [[x,y]], r = new float [[x,y]]; // r = residuals do {
Adlib.writeHalo(a);
overall (i = x for 1 : N – 2) overall (j = y for 1 : N – 2) {
float newA = 0.25 * (a[i - 1, j] + a[i + 1, j] + a[i, j - 1] + a[i, j + 1] ); r [i, j] = Math.abs(newA – a [i, j]);
b [i, j] = newA; }
HPspmd.copy(a, b); // Jacobi relaxation. } while(Adlib.maxval(r) > EPS);
Processes and Process Grids
n An HPJava program is started concurrently in some set of processes.
n Processes named through “grid” objects:
Procs p = new Procs2 (2, 3);
n Assumes program currently executing on 6 or more processes.
n Specify execution in a particular process grid by on construct:
on(p) { . . . }
Distributed Arrays in HPJava
n Many differences between distributed arrays and ordinary arrays of Java. New kind of container type with special syntax.
n Type signatures, constructors use double brackets to
emphasize distinction:
Procs2 p = new Procs2(2, 3); on(p){
Range x = new BlockRange(M, p.dim(0)); Range y = new BlockRange(N, p.dim(1)); float [[-,-]] a = new float[[x, y]];
2-dimensional array block-distributed over p
a[0,0] a[0,1] a[0,2] a[1,0] a[1,1] a[1,2] a[2,0] a[2,1] a[2,2] a[3,0] a[3,1] a[3,2]
a[0,3] a[0,4] a[0,5] a[1,3] a[1,4] a[1,5] a[2,3] a[2,4] a[2,5] a[3,3] a[3,4] a[3,5]
a[0,6] a[0,7] a[1,6] a[1,7] a[2,6] a[2,7] a[3,6] a[3,7]
a[4,0] a[4,1] a[4,2] a[5,0] a[5,1] a[5,2] a[6,0] a[6,1] a[6,2] a[7,0] a[7,1] a[7,2]
a[4,3] a[4,4] a[4,5] a[5,3] a[5,4] a[5,5] a[6,3] a[6,4] a[6,5] a[7,3] a[7,4] a[7,5]
a[4,6] a[4,7] a[5,6] a[5,7] a[6,6] a[6,7] a[7,6] a[7,7] p.dim(0) p.dim(1) 0 0 1 1 2
M = N = 8
The Range hierarchy of
HPJava
BlockRange
Dimension CollapsedRange
IrregRange ExtBlockRange
CyclicRange
The
overall
construct
n
overall
—a distributed parallel loop
n
General form parameterized by index triplet:
overall (i = x for l : u : s) { . . .}
i =
distributed index
,
l = lower bound, u = upper bound, s = step.
n
In general a subscript used in a
distributed array element
must be a
distributed index
in the array range.
Irregular distributed data
structures
0 1
Size = 4 Size = 2 Size = 5 Size = 3
[0] [1] [2] [3]
n
Can be described as distributed array of
Java arrays.
float [[-]][] a = new float [[x]][];
overall (i = x : )
Historical Adlib I
n Adlib library was completed in the Parallel Compiler Runtime Consortium (PCRC).
n This version used C++ as an implementation language. n Initial emphasis was on High Performance Fortran (HPF). n Initially Adlib was not meant be user-level library. It was
called by HPF compiler-generate code when HPF translated user application.
n It was developed on top of portable MPI.
Historical Adlib II
n
Initially HPJava used a JNI wrapper interface
to the C++ kernel of the PCRC library.
n
This version of implementation had limitations
and disadvantages.
n Most importantly this version was hard and inefficient to support Java object types.
n It had performance disadvantages because all calls to C++ Adlib should go though JNI calls. n It did not provide a set of gather/scatter buffer
operation to better support HPC applications.
Collective Communication
Library
n Java version of Adlib is the first library of its kind developed from scratch for application-level use in HPspmd model.
n Borrows many ideas from the PCRC library, but for this project we rewrote high-level library for Java.
n It is extended to support Java Object types, to target Java based communication platforms and to use Java exception handling—making it “safe” for Java.
n Support collective operations on distributed arrays described by HPJava syntax.
n The Java version of the Adlib library is developed on top of mpjdev. The mpjdev API can be implemented portably on network platforms and efficiently on parallel
Java version of Adlib
n
This API intended for an application level
communication library which is suitable for
HPJava programming.
n
There are three main families of collective
operation in Adlib
n regular collective communications n reduction operations
n irregular communications
n
Complete APIs of Java Adlib have been
presented in Appendix A of my dissertation.
Regular Collective Communications I
n remap
n To copy the values of the elements in the source array to the
corresponding elements in the destination array.
void remap (T [[-]] dst, T [[-]] src) ;
n T stands as a shorthand for any primitive type or Object type of
Java.
n Destination and source must have the same size and shape but
they can have any, unrelated, distribution formats.
n Can implement a multicast if destination has replicated
distribution formats.
n shift
Regular Collective Communications II
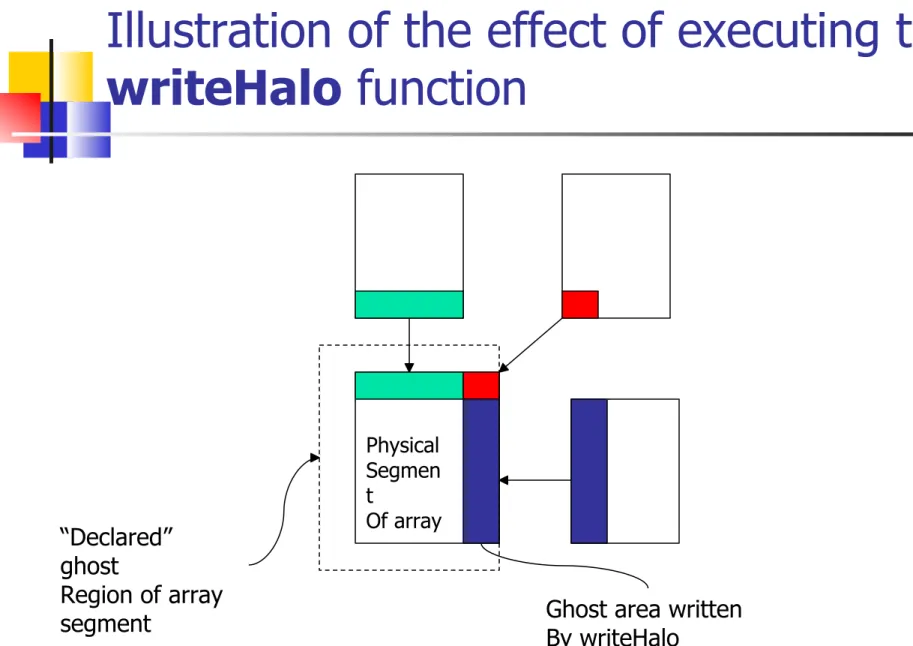
n writeHalo
void writeHalo (T [[-]] a);
n applied to distributed arrays that have ghost regions. It updates those regions.
n A more general form of writeHalo allows to specify that only a subset of the available ghost area is to be updated.
void writeHalo(T [[-]] a, int wlo, int whi, int mode);
wlo, whi: specify the widths at upper and lower ends of the bands to be update.
Solution of Laplace equation using
ghost regions
Range x = new ExtBlockRange(M, p.dim(0), 1);
Range y = new ExtBlockRange(N, p.dim(1), 1);
float [[-,-]] a = new float [[x, y]]; . . . Initialize values in ‘a’
float [[-,-]] b = new float [[x,y]], r = new float [[x,y]]; do {
Adlib.writeHalo(a);
overall (i = x for 1 : N – 2) overall (j = y for 1 : N – 2) {
float newA = 0.25 * (a[i - 1, j] + a[i + 1, j] + a[i, j - 1] + a[i, j + 1] ); r [i, j] = Math.abs(newA – a [i, j]);
b [i, j] = newA; }
HPspmd.copy(a, b);
} while(Adlib.maxval(r) > EPS);
a[0,0] a[0,1] a[0,2] a[1,0] a[1,1] a[1,2] a[2,0] a[2,1] a[2,2]
a[0,1] a[0,2] a[0,3] a[1,1] a[1,2] a[1,3] a[2,1] a[2,2] a[2,3]
a[3,0] a[3,1] a[3,2] a[4,0] a[4,1] a[4,1] a[5,0] a[5,1] a[5,2]
a[3,1] a[3,2] a[3,3] a[4,1] a[4,2] a[4,3] a[5,1] a[5,2] a[5,3] 0
0
1
1
a[3,0] a[3,1] a[3,2] a[3,1] a[3,2] a[3,3]
Illustration of the effect of executing the
writeHalo
function
“Declared” ghost
Region of array segment
Physical Segmen t
Of array
Ghost area written By writeHalo
Other features of Adlib
n
Provide reduction operations (e.g.
maxval() and sum()) and irregular
communications (e.g. gather() and
scatter()).
n
Complete API and implementation
Other High-level APIs
n
Java Grande Message-Passing Working Group
n formed as a subset of the existing Concurrency and Applications working group of Java Grande Forum. n Discussion of a common API for MPI-like Java
libraries.
n To avoid confusion with standards published by the original MPI Forum the API was called MPJ.
n
java-mpi
mailing list has about 195
subscribers.
mpiJava
n Implements a Java API for MPI suggested in late ’97. n mpiJava is currently implemented as Java interface
to an underlying MPI implementation—such as MPICH or some other native MPI implementation. n The interface between mpiJava and the underlying
MPI implementation is via the Java Native Interface (JNI).
n This software is available from
http://www.hpjava.org/mpiJava.html
Low-level API
n One area of research is how to transfer data between the Java program and the network while reducing
overheads of the Java Native Interface.
n Should do this Portably on network platforms and
efficiently on parallel hardware.
n We developed a low-level Java API for HPC message passing, called mpjdev.
n The mpjdev API is a device level communication
library. This library is developed with HPJava in mind, but it is a standalone library and could be used by
other systems.
mpjdev I
n Meant for library developer.
n Application level communication libraries like Java version of Adlib (or potentially MPJ) can be
implemented on top of mpjdev.
n API for mpjdev is small compared to MPI (only includes point-to-point communications)
n Blocking mode (like MPI_SEND, MPI_RECV)
n Non-blocking mode (like MPI_ISEND, MPI_IRECV)
n The sophisticated data types of MPI are omitted.
n provide a flexible suit of operations for copying data to and from the buffer. (like gather- and scatter-style
operations.)
mpjdev II
n mpjdev could be implemented on top of Java sockets in a portable network implementation, or—on HPC
platforms—through a JNI interface to a subset of MPI. n Currently there are three different implementations.
n The initial version was targeted to HPC platforms, through a JNI
interface to a subset of MPI.
n For SMPs, and for debugging on a single processor, we
implemented a pure-Java, multithreaded version.
n We also developed a more system-specific mpjdev built on the
IBM SP system using LAPI.
n A Java sockets version which will provide a more
portable network implementation and will be added in the future.
HPJava communication layers
Other application-level API
MPJ and
Java version of Adlib
mpjdev
Pure Java Native MPI
SMPs or
mpiJava-based Implementation
n Assumes C binding of native method calls to MPI from mpiJava as basic communication protocol.
n Can be divided into two parts.
n Java APIs (Buffer and Comm classes) which are used to call
native methods via JNI.
n C native methods that construct the message vector and
perform communication.
n For elements of Object type, the serialized data are stored into a Java byte [] array.
n copying into the existing message vector if it has space to hold
serialized data array.
n or using separate send if the original message vector is not
large enough.
Multithreaded Implementation
n
The processes of an HPJava program are
mapped to the Java threads of a single JVM.
n
This allows to debug and demonstrate
HPJava programs without facing the ordeal of
installing MPI or running on a network.
n
As a by-product, it also means we can run
HPJava programs on
shared memory parallel
computers
.
n e.g. high-end UNIX servers
LAPI Implementation
n The Low-level Application Programming Interface (LAPI) is a low level
communication interface for the IBM Scalable Powerparallel (SP) supercomputer Switch.
n This switch provides scalable high performance communication
between SP nodes.
n LAPI functions can be divided into three different characteristic
groups.
n Active message infrastructure: allows programmers to write and install
their own set of handlers.
n Two Remote Memory Copy (RMC) interfaces.
n PUT operation: copies data from the address space of the origin process into
the address space of the target process.
n GET operation: opposite of the PUT operation.
n We produced two different implementations of mpjdev using LAPI.
n Active message function (LAPI_Amsend) + GET operation (LAPI_Get)
n Active message function (LAPI_Amsend)
LAPI Implementation: Active message
LAPI Implementation: Active
message
Environments
n System: IBM SP3 supercomputing system with AIX 4.3.3 operating system and 42 nodes.
n CPU: A node has four processors (Power3 375 MHZ) and 2 gigabytes of shared memory.
n Network MPI Setting: Shared “css0” adapter with User Space (US) communication mode.
n Java VM: IBM’s JIT
n Java Compiler: IBM J2RE 1.3.1 with “-O” option. n HPF Compiler: IBM xlhpf95 with “-qhot” and “-O3”
options.
n Fortran 95 Compiler: IBM xlf95 with “-O5” option.
n HPJava can out-perform sequential Java by up to 17 times.
Multigrid
n The multigrids method is a fast algorithm for solution of linear and nonlinear problems. It uses hierarchy grids with
restrict and interpolate operations between current grids (fine grid) and restricted grids (coarse grid).
n General stratagem is:
n make the error smooth by performing a relaxation method.
n restricting a smoothed version of the error term to a coarse grid,
computing a correction term on the coarse grid, then interpolating this correction back to the original fine grid.
n Perform some step of the relaxation method again to improve the
n Speedup is relatively modest. This seems to be due to the complex
pattern of communication in this algorithm.
Speedup of HPJava Benchmarks
2.96 6 3.03 2.39 2.29 1.90 5122 9 4 3 2 Processors Multigrid Solver 36 25 16 9 4 Processors2D Laplace Equation
19.71 12.09 6.22 25.77 13.40 8.82 4.41 10242 16.93 10.58 7.70 4.03 5122 6.22 4.67 3.73 2.67 2562 32 16 8 4 2 Processors 5.43 4.75 3.45 2.72 1.58 323 7.47 8.92 4.85 3.00 1.67 643
HPJava with GUI
n Illustrate how our HPJava can be used with a Java graphical user interface.
n The Java multithreaded implementation of mpjdev makes it possible for HPJava to cooperate with
Java AWT.
n For test and demonstration of multithreaded
version of mpjdev, We implemented computational fluid dynamics (CFD) code using HPJava.
n Illustrates usage of Java object in our communication library.
n You can view this demonstration and source code at http://www.hpjava.org/demo.html
n Removed the graphical part of the CFD code and did performance tests on the
computational part only.
n Changed a 2 dimensional Java object distributed array into a 3 dimensional double
distributed array to eliminate object serialization overhead.
n Using HPC implementation of underlying communication to run the code on an SP.
LAPI mpjdev Performance
n We found that current version of Java thread synchronization is not implemented with high performance.
n The Java thread consumes more then five times a long as POSIX thread, to perform wait and awake thread function calls.
n 57.49 microseconds (Java thread) vs. 10.68 microseconds
(POSIX)
n This result suggests we should look for a new architectural design for mpjdev using LAPI.
n Consider using POSIX threads by calling JNI to the C instead
Contributions I
HPJava
n My main contributions to HPJava was to develop runtime communication libraries.
n Java version of Adlib has been developed as application-level
communication library suitable for data parallel programming in Java.
n The mpjdev API has been developed as device level communication
library.
n Other contributions: The Type-Analyzer for analyzing byte classes’ hierarchy, some part of the type-checker, and Pre-translator of HPJava was developed.
n Some Applications of HPJava and full test codes of Adlib and mpjdev were developed.
Contributions II
mpiJava
n
Main contribution to mpiJava project was to
add support for direct communication of Java
objects via serialization.
n
Complete set of test cases of mpiJava for
Java object types were developed.
Conclusions I
n We have discussed in detail the design and development of
high-level and low-high-level runtime communication libraries for HPJava.
n The Adlib API is presented as high-level communication library. This
API is intended as an example of an application communication library suitable for data parallel programming in Java.
n fully supports Java object types, as part of the basic data types.
n The API and usage of collective communications.
n based on low-level communication library called mpjdev.
n The mpjdev API is a device level communication library. This library
is developed with HPJava in mind, but it is a standalone library and could be used by other systems. Three different implementations are:
n mpiJava-based implementation n Multithreaded implementation n LAPI implementation
Conclusion II
n
Some benchmark results were presented.
n
We got good performance on simple
applications without any serious optimization.
For example:
n HPJava can out-perform sequential Java by up to 17 times.
n On large number of processors HPJava can get about 79% of the performance of HPF.