Named Entity Recognition in Wikipedia
Dominic Balasuriya Nicky Ringland Joel Nothman Tara Murphy James R. Curran
School of Information Technologies University of Sydney
NSW 2006, Australia
{dbal7610,nicky,joel,tm,james}@it.usyd.edu.au
Abstract
Named entity recognition (NER) is used in many domains beyond the newswire text that comprises current gold-standard cor-pora. Recent work has used Wikipedia’s link structure to automatically generate near gold-standard annotations. Until now, these resources have only been evaluated on newswire corpora or themselves. We present the first NER evaluation on a Wikipedia gold standard (WG) corpus. Our analysis of cross-corpus performance on WG shows that Wikipedia text may be a harder NER domain than newswire. We find that an automatic annotation of Wikipedia has high agreement with WG and, when used as training data, outper-forms newswire models by up to 7.7%.
1 Introduction
Named Entity Recognition (NER) is the task of identifying and classifying people, organisations and other named entities (NE) within text. NERis central to manyNLPsystems, especially informa-tion extracinforma-tion and quesinforma-tion answering.
Machine learning approaches now dominate NER, learning patterns associated with individual entity classes from annotated training data. This training data, including English newswire from the MUC-6, MUC-7(Chinchor, 1998), andCO NLL-03(Tjong Kim Sang and De Meulder, 2003) com-petitive evaluation tasks, and the BBN Pronoun Coreference and Entity Type Corpus (Weischedel and Brunstein, 2005), is critical to the success of these approaches.
This data dependence has impeded the adapta-tion or porting of existing NER systems to new domains, such as scientific or biomedical text, e.g. Nobata et al. (2000). Similar domain sensi-tivity is exhibited by most tasks across NLP, e.g.
parsing (Gildea, 2001), and the adaptation penalty is still apparent even when the same set of named entity classes is used in text from similar domains (Ciaramita and Altun, 2005).
Wikipedia is an important corpus for informa-tion extracinforma-tion, e.g. Bunescu and Pas¸ca (2006) and Wu et al. (2008) because of its size, cur-rency, rich semi-structured content, and its closer resemblance to web text than newswire. Recently, Wikipedia’s markup has been exploited to auto-matically deriveNEannotated text for training sta-tistical models (Richman and Schone, 2008; Mika et al., 2008; Nothman et al., 2008).
However, without a gold standard, existing eval-uations of these models were forced to compare against mismatched newswire corpora or the noisy Wikipedia-derived annotations themselves. Fur-ther, it was not possible to directly ascertain the accuracy of these automatic extraction methods.
We have manually annotated 39,007 tokens of Wikipedia with coarse-grained named entity tags (WG). We present the first evaluation of Wiki-pedia-trained models on Wikipedia: theC&C NER tagger (Curran and Clark, 2003b) trained on (a) automatically annotated Wikipedia text (WP2) ex-tracted by Nothman et al. (2009); and (b) tradi-tional newswire NER corpora (MUC, CONLL and BBN). The WP2 model, though trained on noisy annotations, outperforms newswire models onWG by 7.7%. However, every model, including WP2, performs far worse onWGthan on the newswire.
We examined the quality ofWG, and found that our annotation strategy produced a high-quality, consistent corpus. Our analysis suggests that it is the form and distribution ofNEs in Wikipedia that make it a difficult target domain.
Finally, we compared WGwith the annotations extracted by Nothman et al. (2009), and found agreement comparable to our inter-annotator agreement, demonstrating that NEcorpora can be derived very accurately from Wikipedia.
2 Background
Traditional evaluations of NER have considered the performance of a tagger on test data from the same source as its training data. Although the majority of annotated corpora available consist of newswire text, recent practical applications cover a far wider range of genres, including Wikipedia, blogs, RSS feeds, and other data sources. Cia-ramita and Altun (2005) showed that even when moving a short distance, e.g. annotating WSJ text with the same scheme asCONLL’s Reuters, the
per-formance was 26% worse than on the original text. Similar differences are reported by Nothman et al. (2009) who compared MUC, CONLL and BBN annotations reduced to a common tag-set. They found poor cross-corpus performance to be due to tokenisation and annotation scheme mis-match, missing frequent lexical items, and naming conventions. They then compared automatically-annotated Wikipedia text as training data and found it also differs in otherwise inconsequen-tial ways from the newswire corpora, in particular lacking abbreviations necessary to tag news text. 2.1 Automatic Wikipedia annotation
Wikipedia, a collaboratively-written online ency-clopedia, is readily exploited inNLP, because it is large, semi-structured and multilingual. Its arti-cles often correspond to NEs, so it has been used for NErecognition (Kazama and Torisawa, 2007) and disambiguation (Bunescu and Pas¸ca, 2006; Cucerzan, 2007). Wikipedia links often spanNEs, which may be exploited to automatically create annotated NER training data by determining the entity class of the linked article and then labelling the link text with it.
Richman and Schone (2008) use article clas-sification knowledge from English Wikipedia to produceNE-annotated corpora in other languages (evaluated against NE gold standards for French, Spanish, and Ukrainian). Mika et al. (2008) ex-plored the use of tags from a CONLL-trained
tag-ger to seed the labelling of entities and evaluate the performance of a Wikipedia-trained model by hand.
We make use of an approach described by Noth-man et al. (2009) which is engineered to perform well on BBN data with a reduced tag-set (LOC, MISC, ORG, PER). They derive an annotated cor-pus with the following steps:
1. Classify Wikipedia articles into entity classes
2. Split the articles into tokenised sentences 3. Label expanded links according to targetNEs 4. Select sentences for inclusion in a corpus
To prepare the text, they use mwlib (Pedi-aPress, 2007) to parse Wikipedia’s native markup retaining only paragraph text with links, ap-ply Punkt (Kiss and Strunk, 2006) estimated on Wikipedia text to perform sentence boundary de-tection, and tokenise the resulting text using regu-lar expressions.
Nothman et al. (2009) infer additional NEs not provided by existing links, and apply rules to ad-just link boundaries and classifications to closer matchBBNannotations.
2.2 NERevaluation
Meaningful automatic evaluation of NER is dif-ficult and a number of metrics have been pro-posed (Nadeau and Sekine, 2007). Ambiguity leads to entities correctly delimited but misclas-sified, or boundaries mismatched despite correct classification.
Although the MUC-7 evaluation (Chinchor, 1998) defined a metric which was less sensitive to often-meaningless boundary errors, we consider only exact entity matches as correct, following the standard CONLLevaluation (Tjong Kim Sang,
2002). We report precision, recall andF-score for each entity type.
3 Creating the Wikipedia gold standard
We created a corpus by manually annotating the text of 149 articles from the May 22, 2008 dump of English Wikipedia. The articles were selected at random from all articles describing named en-tities, with a roughly equal proportion of arti-cle topics from each of the fourCONLL-03classes
(LOC,MISC,ORG,PER). We adopted Nothman et al.’s (2008) preprocessing described above to pro-duce tokenised sentences for annotation.
Only body text was extracted from the chosen articles for inclusion in the corpus. Four articles were found not to have any usable text, consisting solely of tables, lists, templates and section head-ings, which we remove. Their exclusion leaves a corpus of 145 articles.
3.1 Annotation
an-[COMPANY Aero Gare] was a kitplane manufacturer founded by [PERSONGary LeGare] in [CITY Mojave] ,
[STATECalifornia] to marketed the [PLANESea Hawker]
amphibious aircraft .
[ORGAero Gare] was a kitplane manufacturer founded by [PERGary LeGare] in [LOCMojave] , [LOC
Califor-nia] to marketed the [MISC Sea Hawker] amphibious
aircraft .
[image:3.595.331.500.172.318.2](a) Fine-grained annotation (b) Coarse-grained annotation Figure 1: An example of coarse and fine-grained annotation of Wikipedia text.
notators as annotation progressed, and eventually contained 96 tags.
We created a mapping from these fine-grained tags to the four coarse-grained tags used in the CONLL-03 data: PER, LOC, MISC andORG. This
enables evaluation with existingNERmodels. We believe this two-phase approach allowed anno-tators to defer difficult mapping decisions, (e.g. should an airport be classified as aLOC, ORG, or MISC?) which can then be made after discussion. The mapping could also be modified to suit a par-ticular evaluation task.
Figure 1 shows an example of the use of fine and coarse-grained tags to annotate a sentence. Tags such as PERSON correspond directly to coarse-grained tags, while most map to a more general tag, such as STATE and CITY mapping to LOC. PLANE is an example of a fine-grained tag that cannot be mapped to LOC, ORG, or PER. These tags may be mapped to MISC; some are not con-sidered entities under the CONLL scheme and are
left unlabelled in the coarse-grained annotation. Three independent annotators were involved in the annotation process. Annotator 1 annotated all 145 articles using the fine-grained tags. Annota-tors 2 and 3 then re-annotated 19 of these articles (316 sentences or 8030 tokens), amounting to 21% of the corpus. Annotator 2 used the fine-grained tags described above, while Annotator 3 used the four coarse-grainedCONLLtags. To measure
vari-ation, all three annotations of this common portion were mapped down to theCONLLtag-set and
inter-annotator agreement was calculated.
We found that 202 tokens were disagreed upon by at least one annotator (2.5% of all tokens annotated), and these discrepancies were then discussed by the three annotators. The inter-annotator agreement will be analysed in more de-tail in Section 5.
Sentences containing grammatical and typo-graphical errors were not corrected, so that the cor-pus would be as close as possible to the source text. Web text often contains errors, such as to
Train Test P R F
WP2 WG 66.5 67.4 66.9
BBN WG 59.2 59.1 59.2
CONLL WG 54.3 57.2 55.7
WP2 * WG* 75.1 67.7 71.2 BBN* WG* 57.2 64.1 60.4 CONLL* WG* 53.1 62.7 57.5 MUC* WG* 52.3 57.2 54.6 WP2 BBN 73.4 74.6 74.0
WP2 CONLL 73.6 64.9 69.0
WP2 * MUC* 86.2 68.9 76.6
BBN BBN 85.7 87.3 86.5 CONLL CONLL 85.3 86.5 85.9 MUC MUC 81.0 83.6 82.3
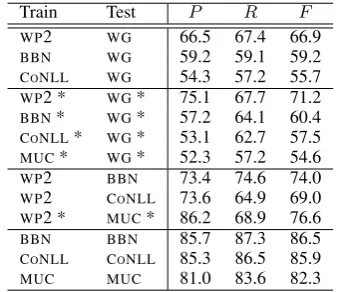
Table 2: Tagger performance on various corpora. Asterisks indicate thatMISCtags are ignored.
marketed the Sea Hawkerfrom the example in
Fig-ure 1, so anyNERsystem must deal with these er-rors. Sentences with poor tokenisation or sentence boundary detection were identified and corrected manually, since these errors are introduced by our processing and annotation, and do not exist in the source text.
The final corpus was created by correcting an-notation mistakes, with annotators 2 and 3 each correcting 50% of the corpus. The fine-grained tags were mapped to the four CONLL tags before
the final corrections were made. The finalWG cor-pus consists of the body text of 145 Wikipedia ar-ticles tagged with the fourCONLL-03tags.
4 NERon the Wikipedia gold-standard Nothman et al. (2009) have previously shown that that anNERsystem trained on automatically anno-tated Wikipedia corpora performs reasonably well on non-Wikipedia text. Having created our WG corpus of gold-standard annotations, we are able to evaluate the performance of these models on Wikipedia text.
We compare the C&C NE maximum-entropy tagger (Curran and Clark, 2003b) trained on gold-standard newswire corpora (MUC-7,BBNand CONLL-03) with the same tagger trained on
WG WP2 BBN CONLL-03 MUC-7
Test Train Train Test Train Test Train Test Tokens 39 007 3 500 032 901 849 129 654 203 621 46 435 83 601 60 436 Sentences 1 696 146 543 37 843 5 462 14 987 3 453 3 485 2 419
Articles 145 — 1 775 238 946 231 102 99
[image:4.595.120.479.62.126.2]NEs 3 558 288 545 49 999 7 307 23 498 5 648 4 315 3 540
Table 1: Corpus sizes.
too small to train a reasonableNERmodel on gold-standard Wikipedia annotations. Part-of-speech tags are added to all corpora using the C&C POS tagger (Curran and Clark, 2003a) before training and testing. 1 We evaluate each model on tradi-tional newswire evaluation corpora as well asWG. Table 1 gives the size of each corpus.
The results are shown in Table 2. TheWP2 tag-ger performed substantially better onWGthan tag-gers trained on newswire text, with a 7−11% in-crease in F-score compared to BBN and CO NLL-03, and a 16% increase compared toMUC-7, when miscellaneous NEs in the corpus are not consid-ered in the evaluation. The Wikipedia trained model thus outperforms newswire models on our new WGcorpus even though the training annota-tions were automatically extracted.
The WP2 tagger performed worse on WG than on gold-standard news corpora (BBNandCONLL),
with a 2−7% reduction in F-score. Further, the performance of WP2 on WGis 11−20% F-score lower than same-source evaluation results, e.g. BBN on BBN, CONLL on CONLL. Therefore,
de-spite WP2 showing an advantage in tagging WG due to their common source domain, we find that WG’s annotations are harder to predict than the newswire test data commonly used for evaluation. One possible explanation is that our WGcorpus has been inconsistently annotated. When NEs of miscellaneous type are not considered in the eval-uation (asterisks in Table 2), the performance of all taggers onWGimproves, withWP2demonstrating a 4% increase. This result suggests another par-tial explanation: that MISC NEs in Wikipedia are more difficult to annotate correctly, due to their poor definition and broad coverage. A third ex-planation is that the automatic conversion process proposed by Nothman et al. (2008) produces much lower quality training data than manual annota-tion. We explore these three possibilities below.
1Both taggers are available fromhttp://svn.ask.
it.usyd.edu.au/trac/candc.
Token Exact NEonly
[image:4.595.331.501.170.225.2]A1 and A2 0.95 0.99 0.88 A1 and A3 0.91 0.95 0.81 A2 and A3 0.91 0.96 0.79 Fleiss’ Kappa 0.92 0.97 0.83
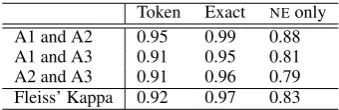
Table 3: Initial human inter-annotator agreement.
5 Quality of the Wikipedia gold standard
The low performance observed on WG may be due to the poor quality of its annotation. We en-sure that this is not the case by measuring inter-annotator agreement. The WGannotation process produced three independent annotations of a sub-set ofWG. These annotations were compared us-ing Cohen’sκ(Fleiss and Cohen, 1973) between pairs of annotators, and Fleiss’ κ (Fleiss, 1971), which generalises Cohen’s κ to more than two concurrent annotations.
Table 3 shows the three types of κ values cal-culated. Tokenis calculated on a per token basis, comparing the agreement of annotators on each token in the corpus; NE only, is calculated on the agreement between entities alone, excluding agreement in cases where all annotators agreed that a token was not a NE; Exact refers to the agreement between annotators where all annota-tors have agreed on the boundaries of a NE, but disagree on the type ofNE.
Annotator 1 originally annotated the entire cor-pus, and Annotators 2 and 3 then corrected exactly half of the corpus each after a discussion between the three annotators to resolve ambiguities. Landis and Koch (1977) determine that aκvalue greater than 0.81 indicates almost perfect agreement. By this standard, our three annotators were in strong agreement prior to discussion, with our Fleiss’κ values all greater than 0.81. Inconsistencies in the corpus due to annotation mistakes by Annotator 1 were corrected by Annotators 2 and 3.
bound-LOC MISC ORG PER H(C): WithO WithoutO TotalNEs %NEtokens
WG 28.5 20.0 25.2 26.3 0.98 2.0 3 558 17.1
BBN 22.4 9.8 46.4 21.3 0.61 1.7 49 999 9.6
MUC 33.3 — 40.7 26.1 0.52 1.5 4 315 8.1
[image:5.595.325.505.159.353.2]CONLL 30.4 14.6 26.9 28.1 0.98 1.9 23 498 17.1
Table 4: NEclass distribution, tag entropy andNEdensity statistics for gold-standard corpora andWG.
ary ambiguities, or disagreement as to whether a phrase constituted a NE at all. Higher inter-annotator agreement between Annotators 1 and 2 leads us to believe that the two-phase annotation strategy, where an initially fine-grained tag-set is reduced, results in more consistent annotation.
Our analysis demonstrates thatWGis annotated in a consistent and accurate manner and the small number of errors cannot alone explain the reduced performance figures.
6 Comparing gold-standard corpora
6.1 NEclass distribution
Table 4 compares the distribution of different classes ofNEs across different corpora on the four CONLLcategories. WGhas a higher proportion of PERandMISC NEs and a lower proportion ofORG NEs than theBBNcorpus. This is also found in the MUCcorpus, although comparisons toMUCare af-fected by its lack of aMISCcategory. TheCO NLL-03 corpus is most similar to WG in terms of the distribution of theNE classes, although CONLL-03
has a smaller proportion of MISC NEs than WG. An analysis of the lengths ofNEs inCONLLshows,
however, that they are very different to those in WG (see Table 8), perhaps explaining the differ-ence in performance observed.
Tag entropyH(C)was calculated for each cor-pus with respect to the 5 possible classes (4 NE classes, and the O tag, indicating non-entities). H(C) is a measure of the amount of information required to represent the classification of each to-ken in the corpus. Two calculations are made, in-cluding and exin-cluding the frequentO tag. Our re-sults (Table 4) suggest thatWG’s tags are least pre-dictable, with a tag entropy of 2.0 bits (without the O class) compared to 1.7 and 1.9 bits forBBNand CONLLrespectively.
6.2 Fine-grained class distribution
While the CONLL-03andMUC evaluation corpora
are marked up with only very coarse tags, theBBN corpus uses 29 coarse tags, many with specific subtypes, including NEs, descriptors of NEs and
MappedBBNtag WG BBN
PERSON 25.9 19.3
ORGANIZATION:OTHER 13.0 2.8
ORGANIZATION:CORPORATION 9.2 43.1
GPE:CITY 8.0 6.7
WORK OF ART:SONG 4.7 0.1
NORP 4.3 3.1
WORK OF ART:OTHER 4.1 1.3
GPE:COUNTRY 3.5 5.1
ORGANIZATION:EDUCATIONAL 3.0 0.9
GPE:STATE PROVINCE 2.8 2.8
ORGANIZATION:POLITICAL 2.6 0.6
EVENT:OTHER 2.5 0.4
ORGANIZATION:GOVERNMENT 2.0 7.5
WORK OF ART:BOOK 1.6 0.4
EVENT:WAR 1.6 0.1
FAC:OTHER 1.4 0.2
LOCATION:REGION 1.3 0.8
FAC:ATTRACTION 1.2 0.0
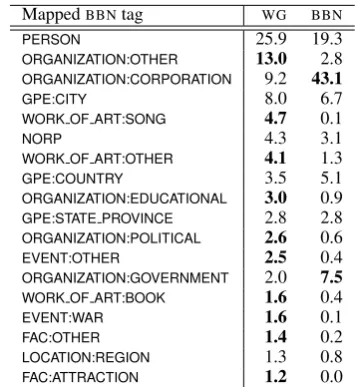
Table 5: Distribution of some fine-grained tags
non-NEs, intended as answer types for question answering (Brunstein, 2002). Non-NE types in-cludeMONEY andTIME, which are also tagged in
theMUCcorpus, and others such asANIMAL. When
evaluating the performance of the taggers, each of BBN’s 150 fine-grained tags was mapped to one of four coarse-grained classes or none, using a map-ping described in Nothman (2008).
However, since theWGcorpus was initially an-notated using 96 distinct classes, we map these tags to the corresponding fine-grained BBN NE classes. In some cases, the tags map exactly (e.g.COUNTRY mapped toLOCATION:COUNTRY);
in other cases, classes have to be merged or not mapped at all, where theBBNandWGannotations differ in granularity. Where possible, we map to fine-grainedBBNcategories.
We create mappings to a total of 36 BBNentity types, and apply them across theWGcorpus. Table 5 shows the distribution of the most common tags, calculated as a percentage of all counts of the 36 selected tags across each corpus. Tags for which there is at least a two-fold difference in proportion betweenBBNandWGare marked in bold.
The comparison is dominated by the presence of a disproportionate number of
com-1 2 3 4 5 6 7+ #NEs WG 53.0 77.0 88.9 94.8 96.6 98.2 100 712 BBN(train) 75.0 91.0 95.4 97.2 98.2 98.7 100 4 913 CONLL(train) 75.0 93.8 98.1 99.5 99.9 99.9 100 3 437
Table 6: ComparingMISC NElengths (cumulative).
Feature group WG BBN CONLL
Current token 0.88 0.89 0.93 CurrentPOS 0.43 0.57 0.48
Current word-type 0.42 0.49 0.48 Previous token 0.46 0.43 0.47 PreviousPOS 0.12 0.19 0.14 Previous word-type 0.07 0.14 0.12
Table 7: Feature-tag gain ratios.
pared to WG. It also mentions many more governmental organisations. Prominent cases of tags found in higher proportions inWGare works of art, organisations of type OTHER (e.g. bands,
sports teams, clubs), events and attractions. This comparison demonstrates that there are ob-servable differences inNEtypes between the news and Wikipedia domains. These differences are re-flected in the distribution of both coarse and fine-grained types of NEs. The more complex entity distribution in Wikipedia is a likely cause for re-ducedNERperformance onWG.
6.3 Feature-tag gain
Nobata et al. (2000) use gain ratio as an infor-mation-theoretic measure of corpus difficulty:
GR(C;F) = IH(C(;CF))
whereI(C;F) = H(C)−H(C|F)is the infor-mation gain of theNEtag distribution (C) with re-spect to a feature setF.
This gain ratio normalises the information gain over the tag entropy, which Nobata et al. (2000) suggest allows us to compare gain ratios between corpora. It also makes the impact of including the ‘O’ tag negligible for our calculations.
We apply this approach to measure the relative difficulty of tagging NEs in the WG corpus. Ta-ble 7 shows that WG tags seem generally harder to predict than those in newswire, on the basis of words, POStags or orthographic word-types (like those used in the Curran and Clark (2003b) tagger as proposed by Collins (2002)).
In particular, POS tags are less indicative than inBBNandCONLL, suggesting a wider variety of
1 2 3 4 5 6 7+
[image:6.595.313.523.150.205.2]WG 49.9 81.7 93.1 97.4 98.6 99.4 100 BBN(train) 57.4 83.3 92.9 97.4 99.1 99.6 100 CONLL(train) 63.1 94.5 98.4 99.4 99.8 99.9 100 MUC(train) 62.0 89.1 96.1 99.1 99.7 99.8 100
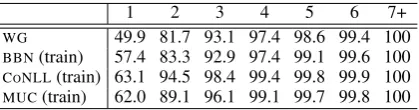
Table 8: Comparing allNElengths (cumulative).
grammatical functions inNE names in Wikipedia – this might be expected with more band names, and song and movie titles. Alternatively, it may be an indication that the POStagging is less reliable on Wikipedia using newswire-trained models.
The previous word’s orthographic form also provides less information, which may relate to ti-tles likeMr. andMrs., strong indicators ofPER en-tities, which are frequent in BBN and to a lesser extentCONLL, but are almost absent in Wikipedia.
6.4 Lengths of named entities
The number of tokens inNEs is substantially dif-ferent between WG and other gold-standard cor-pora. When compared with WG, other gold-standard corpora have a larger proportion of single-word NEs (between 7 and 13% more), as shown in Table 8. The distribution ofNE lengths in BBN is most similar to WG, but it still differs significantly in the proportion of single-wordNEs. Additionally, WG has a larger number of long multi-word NEs than the other gold-standard cor-pora. Longer entities are more difficult to clas-sify, since boundary resolution is more error prone and they typically contain lowercase words with a wider range of syntactic roles. This adds to the difficulty of correctly identifyingNEs inWG.
[image:6.595.90.273.151.226.2]1 2 3 4 5 6 7+ #NEs WG 49.2 82.9 94.2 98.0 99.2 99.8 100 2 846 BBN(train) 55.4 82.4 92.6 97.4 99.2 99.7 100 45 086 CONLL(train) 61.1 94.7 98.4 99.4 99.8 99.9 100 20 061
[image:7.595.152.446.60.116.2]MUC(train) 62.0 89.1 96.1 99.1 99.7 99.8 100 4 315
Table 9: Comparing non-MISC NElengths (cumulative).
# Sents # withNEs #NEs
WG 1 696 1 341 3 558
[image:7.595.319.512.159.255.2]WG WP2-style 571 298 569 WG WP4-style 698 425 831
Table 10: Size ofWGand auto-annotated subsets.
7 Evaluation of automatic annotation
We compared the gold-standard annotations in our WGcorpus to those sentences that were automati-cally annotated by Nothman et al. (2009). Their automatic annotation process does not retain all Wikipedia sentences. Rather, it selects sentences where, on the basis of capitalisation heuristics, it seems all named entities in the sentence have been tagged by the automatic process. We adopt this confidence criterion to produce automatically-annotated subsets of theWGcorpus.
Two variants of their automatic annotation pro-cedure were used: WP2 uses a few rules to infer tags for non-linked NEs in Wikipedia; WP4 has looser criteria for inferring additional links, and its over-generation typically reduced its performance as training data (Nothman et al., 2009).
A large proportion of sentences in our WG cor-pus cannot be automatically tagged with confi-dence. Sentence selection leaves 571 sentences (33.7%) after the WP2 process and 698 (41.2%) after the WP4process (see Table 10). The use of the more permissiveWP4process may lead to the labelling of moreNEs, but many may be spurious. We use three approaches to compare automatic and manual annotations ofWGtext: (a) treat each corpus as test data and evaluateNERperformance on each; (b) treat WP2 and WP4-style subsets as NERpredictions on theWGcorpus to calculate an F-score; and (c) treat the automatic annotations like human annotators and calculateκvalues.
We first evaluate the WP2 model on each corpus and find that performance is higher on automatically-annotated subsets ofWG(Table 11). This is unsurprising given the common automatic annotation process and the effects of the selection criterion. However, Nothman (2008) provides an
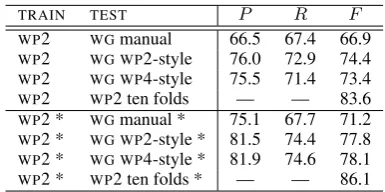
TRAIN TEST P R F
WP2 WGmanual 66.5 67.4 66.9 WP2 WG WP2-style 76.0 72.9 74.4 WP2 WG WP4-style 75.5 71.4 73.4
WP2 WP2 ten folds — — 83.6
[image:7.595.88.275.160.205.2]WP2 * WGmanual * 75.1 67.7 71.2 WP2 * WG WP2-style * 81.5 74.4 77.8 WP2 * WG WP4-style * 81.9 74.6 78.1 WP2 * WP2 ten folds * — — 86.1
Table 11: NER performance of the WP2-trained model on auto-annotated subsets ofWG.
κ NEκ P R F
[image:7.595.320.514.302.337.2]WP2-style 0.94 0.84 89.0 89.0 89.0 WP4-style 0.93 0.83 86.8 87.6 87.2
Table 12: Comparing WP2-style WG and WP4 -styleWGonWG. The automatically annotated data was treated as predicted annotations onWG.
F-score for theWP2model when evaluated on 10 folds of automatically-annotated (WP2-style) test data. ThisF-score is 8−10% higher than WP2’s performance on theWP2-style subset ofWG, sug-gesting thatWG’s text is somewhat more difficult to annotate than typical portions ofWP2-style text. We compare the annotations of WG text more directly by treating the automatic annotations as if they are the output from a tagger run on the 698 and 571 sentences that were confidently chosen. A reasonable agreement between the gold standard and automatic annotation is observed (Table 12), with F-scores of 87.2% and 89.0% achieved by WP2andWP4.
Table 12 also shows inter-annotator agreement calculated between the automatically annotated subsets and the gold-standard annotations inWG, using Cohen’sκin the same way as for human an-notators. The agreement was very high: equal or better than the agreement between human annota-tors prior to discussion and correction.
8 Conclusion
importance in Computational Linguistics. We annotated a corpus of Wikipedia articles (WG) with gold-standard NE tags. Using this new re-source as test data we have evaluated models trained on three gold-standard newswire corpora forNER, and compared them to a model trained on Wikipedia-derived NER annotations (Nothman et al., 2009). We found that thisWP2model outper-formed models trained onMUC,CONLL, andBBN
data by more than 7.7%F-score.
However, we found that all four models per-formed significantly worse on theWGcorpus than they did on news text, suggesting that Wikipedia as a textual domain is more difficult forNER. We initially suspected that annotation quality was re-sponsible, but found that we had very high inter-annotator agreement even before further discus-sion and correction of the corpus. This also val-idates our approach of creating many fine-grained categories and then reducing them down to the fourCONLLtypes.
To further examine the difficulty of taggingWG, we compared the distribution of fine-grained entity types in WG and BBN, finding a more even dis-tribution over a larger range of types in WG. We found that the standardNERfeatures such as cur-rent and previous POStags and words had lower predictive power on WG. We also compared the distribution of NEs lengths and showed that WG entities are longer on average (for instance song and book titles). This all suggests that Wikipedia is genuinely more difficult to automatically anno-tate with named entities than newswire.
Finally, we compared the common sentences between Nothman et al.’s (2009) automaticNE an-notation of Wikipedia andWG, directly measuring the quality of automatically deriving NE annota-tions from Wikipedia.
We found that WP2 agreed with our final WG corpus to a high degree, demonstrating that Wikipedia is a viable source of automatically an-notated NE annotated data, reducing our depen-dence on expensive manual annotation for training NERsystems.
Acknowledgements
We would like to thank the anonymous review-ers for their helpful feedback. This work was supported by the Australian Research Council un-der Discovery Project DP0665973. Dominic Bal-asuriya was supported by a University of
Syd-ney Outstanding Achievement Scholarship. Nicky Ringland was supported by a Capital Markets CRC High Achievers Scholarship. Joel Noth-man was supported by a Capital Markets CRC PhD Scholarship and a University of Sydney Vice-Chancellor’s Research Scholarship.
References
Ada Brunstein. 2002. Annotation guidelines for an-swer types. LDC2005T33, Linguistic Data Consor-tium, Philadelphia.
Razvan Bunescu and Marius Pas¸ca. 2006. Using en-cyclopedic knowledge for named entity disambigua-tion. In Proceedings of the 11th Conference of the European Chapter of the Association for Computa-tional Linguistics, pages 9–16.
Nancy Chinchor. 1998. Overview of MUC-7. In Pro-ceedings of the 7th Message Understanding Confer-ence.
Massimiliano Ciaramita and Yasemin Altun. 2005. Named-entity recognition in novel domains with ex-ternal lexical knowledge. In Proceedings of the NIPS Workshop on Advances in Structured Learning for Text and Speech Processing.
Michael Collins. 2002. Ranking algorithms for named-entity extraction: boosting and the voted per-ceptron. In Proceedings of the 40th Annual Meet-ing of the Association for Computational LMeet-inguis- Linguis-tics, pages 489–496.
Silviu Cucerzan. 2007. Large-scale named entity disambiguation based on Wikipedia data. In Pro-ceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Com-putational Natural Language Learning, pages 708– 716.
James R. Curran and Stephen Clark. 2003a. Investigat-ing GIS and smoothInvestigat-ing for maximum entropy tag-gers. InProceedings of the 10th Conference of the European Chapter of the Association for Computa-tional Linguistics, pages 91–98, Budapest, Hungary, 12–17 April.
James R. Curran and Stephen Clark. 2003b. Language independent NER using a maximum entropy tagger. In Proceedings of the 7th Conference on Natural Language Learning, pages 164–167.
Joseph L. Fleiss and Jacob Cohen. 1973. The equiv-alence of weighted kappa and the intraclass corre-lation coefficient as measures of reliability. Educa-tional and Psychological Measurement, 33(3):613.
Daniel Gildea. 2001. Corpus variation and parser per-formance. In2001 Conference on Empirical Meth-ods in Natural Language Processing (EMNLP), Pittsburgh, PA.
Jun’ichi Kazama and Kentaro Torisawa. 2007. Ex-ploiting Wikipedia as external knowledge for named entity recognition. InProceedings of the 2007 Joint Conference on Empirical Methods in Natural guage Processing and Computational Natural Lan-guage Learning, pages 698–707.
Tibor Kiss and Jan Strunk. 2006. Unsupervised mul-tilingual sentence boundary detection. Computa-tional Linguistics, 32(4):485–525.
J. Richard Landis and Gary G. Koch. 1977. The mea-surement of observer agreement for categorical data.
Biometrics, 33:159–174.
Peter Mika, Massimiliano Ciaramita, Hugo Zaragoza, and Jordi Atserias. 2008. Learning to tag and tag-ging to learn: A case study on wikipedia. IEEE In-telligent Systems, 23(5, Sep./Oct.):26–33.
David Nadeau and Satoshi Sekine. 2007. A sur-vey of named entity recognition and classification.
Lingvisticae Investigationes, 30:3–26.
Chikashi Nobata, Nigel Collier, and Jun’ichi Tsuji. 2000. Comparison between tagged corpora for the named entity task. InProceedings of the Workshop on Comparing Corpora, pages 20–27.
Joel Nothman, James R Curran, and Tara Murphy. 2008. Transforming Wikipedia into named entity training data. In Proceedings of the Australasian Language Technology Association Workshop 2008, pages 124–132, Hobart, Australia, December. Joel Nothman, Tara Murphy, and James R. Curran.
2009. Analysing Wikipedia and gold-standard cor-pora for NER training. In Proceedings of the 12th Conference of the European Chapter of the ACL (EACL 2009), pages 612–620, Athens, Greece, March.
Joel Nothman. 2008.Learning Named Entity Recogni-tion from Wikipedia. Honours Thesis. School of IT, University of Sydney.
PediaPress. 2007. mwlibMediaWiki parsing library.
http://code.pediapress.com.
Alexander E. Richman and Patrick Schone. 2008. Mining wiki resources for multilingual named en-tity recognition. InProceedings of the 46th Annual Meeting of the Association for Computational Lin-guistics: Human Language Technologies, pages 1– 9, Columbus, Ohio.
Erik F. Tjong Kim Sang and Fien De Meulder. 2003. Introduction to the CoNLL-2003 shared task: Language-independent named entity recogni-tion. InProceedings of the 7th Conference on Natu-ral Language Learning, pages 142–147, Edmonton, Canada.
Erik F. Tjong Kim Sang. 2002. Introduction to the CoNLL-2002 shared task: Language-independent named entity recognition. InProceedings of the 6th Conference on Natural Language Learning, pages 1–4, Taipei, Taiwan.
Ralph Weischedel and Ada Brunstein. 2005.
BBN Pronoun Coreference and Entity Type Cor-pus. LDC2005T33, Linguistic Data Consortium, Philadelphia.