An Operation Network for Abstractive Sentence Compression
Full text
Figure
Related documents
We propose a novel graph-based attention mechanism in a hierarchical encoder- decoder framework, and propose a hierarchical beam search algorithm to generate multi-sentence
We consider the problem of using sentence compression techniques to facilitate query- focused multi-document summarization.. We present a sentence-compression-based frame- work for
This paper presents a 2-step approach for sentence compression: we first generate an n-best list for each source sentence using a sequence labeling method, then rerank the
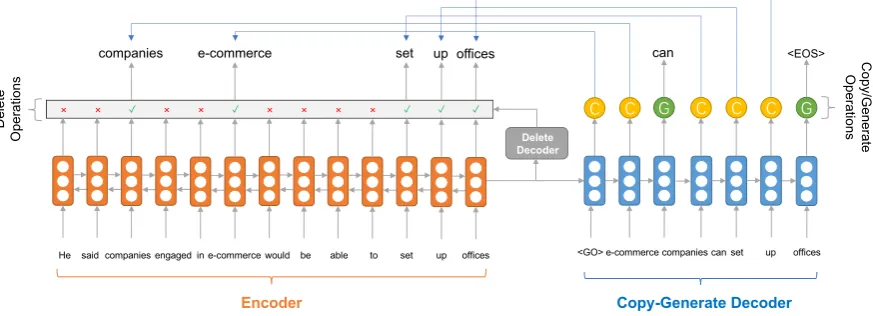
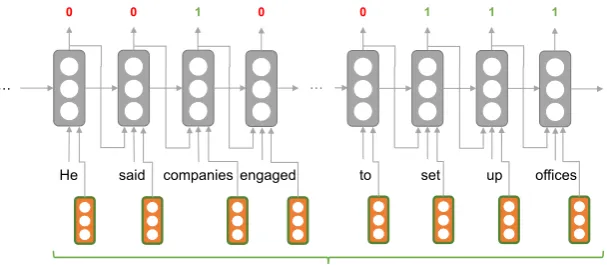
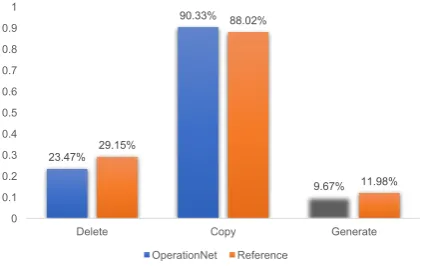
Con- ventional approaches to sentence compression ex- ploit various linguistic properties based on lexical information and syntactic dependencies (McDonald, 2006; Clarke and
% Dependency Tree Based Sentence Compression K atja Filippova and Michael Strube EML Research gGmbH Schlo? Wolfsbrunnenweg 33 69118 Heidelberg, Germany http //www eml research
Abstractive News Summarization based on Event Semantic Link Network Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics Technical Papers,
We consider the task of summarizing a cluster of related sentences with a short sentence which we call multi-sentence compression and present a simple ap- proach based on shortest
ILPSumm also outperforms the MSC-based method, i.e., our approach can generate more informative summaries by glob- ally maximizing content selection from multiple clusters
