2016 International Congress on Computation Algorithms in Engineering (ICCAE 2016) ISBN: 978-1-60595-386-1
1 INTRODUCTION
In human life and production activities, most of the information acquired is the visual information, such as the license plate, auto logo or vehicle model are re-quired to be recognized in daily traffic process. In the literature work, there is a need to recognize a great number of text information, and the information is often incomplete due to the action of nature. For ex-ample, the bill font may fade for years, resulting in difficulty in the commercial forensics or other com-mercial activities and other problems to be solved urgently. [1] The text plays a mainstay role in scientific and technological exchanges. The development of the text feature extraction and detection technology plays an important role in the progress in daily academic exchanges. As the technology of the big data becomes mature, how to quickly and accurately acquire and recognize the text features and convert into the text at the technology terminal is often found in reports. In Handwritten Script Recognition System for Languages with Diacritic Signs, Cosin, H. researches the applica-tion of the neural network in the handwritten script recognition and carries out classification detection through letters, words and fragments. In Identity Recognition using an Artificial Intelligence based on Artificial Immune System, Jadiel Caparrós da Silva researches the application of the artificial intelligence
in the recognition of the human facial expression, introduces the immune system in the algorithm and obtains a good recognition result. However, for the detection of more complex variants or the texts with missing information, currently, there is no effective technology for detection recognition or further repair [2]
, and the recognition rate and operating efficiency of the previous models is often not satisfactory with a longer period of recognition. Given that the image text is mostly the mass data, this paper applies the distrib-uted algorithm for parallel computing and SVM for the text feature recognition, establishment of a high-precision text detection model and improvement of its robustness based on the idea of big data.
2 MODELING
2.1 Distributed algorithm
The image text is mostly the mass data. The traditional process mode is not only time-consuming, but also presents a downward trend with the increase of accu-racy of the data size. The distributed system rapidly develops with the development of the computer hard-ware and the emergence of the big data concept, and its application gradually becomes mature. The distrib-uted parallel processing can not only improve the accuracy of the text detection, but also increase the
Text Detection Model Based on Parallel SVM Algorithm
Yan Zhang & Yufang Song
Department of Foreign Language, Qinhuangdao Institute of Technology, Qinhuangdao, Hebei, China
ABSTRACT: With the development of the computer science and technology, the advanced algorithm rapidly develops in the field of the text detection and recognition and reduction. However, how to establish a model to be faster and more accurate access to more complex variants or the texts with missing information is to be solved urgently. In this paper, MATLAB parallel computing toolbox is applied to develop the parallel SVM.And this paper improves the operational efficiency through the distributed algorithm and selects the appropriate algorithm parameters to improve the accuracy of the model detection through cross validation. Based on the parallel MATLAB platform of multiple computers, this paper carries out a simulation test and concludes that the accura-cy of the complex text detection is 98%. This paper establishes a text detection model that has a high accuraaccura-cy and a high robustness even in a complex background.
detection efficiency [3]. However, its programming difficulty and algorithm complexity are criticized by people. The parallel toolbox developed by MATLAB is not required to be developed from the bottom, but only needs to simply rewrite the programming lan-guages and add parafor-loops in a loop for loop opti-mization.
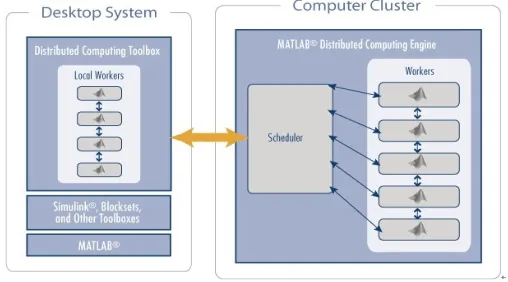
The parallel computing toolbox developed based on MATLAB platform is used to solve the above prob-lems. PCT of MATLAB provides two types of com-puting methods: dadafirst and jobfirst . The latter method can be used for computing after establishment of a complex model because the data has hereditability. MATLAB server has robustness for the scheduler, which can be compatible with MSCC, APBSpro and other scheduling packages. [4] The principle of the distribution is shown in Figure 1.
2.2 SVM principle
SVM is another new learning method after the emer-gence of the neural network. SVM makes
1 2
( , , n)
f x x x achieve a certain mapping link in 1
n
R →R criterion. Such algorithm is supported by the theory with reliable robustness and accuracy [5]. The theoretical basis of this model and the preferential criterion of the algorithm are shown in Figure 2.
Two types of problems can be realized based on SVM, that is, linear transformation criterion and non-linear transformation criterion. The training ma-trix is defined as follows:
i i
{(x ,y ),i
=
1, 2,l}Where: xi is part of the neighborhood rule (Ri),
then yi=1. If xi is a part of the neighborhood rule
(R≠Ri ), then, yi= −1 . The first class of the plane
or hyperplane is defined as follows:
0
wx b
+ =
(1)This set can converge the sample matrix in Ri and
i
R≠R, indicating that this matrix has a regular and clear neighborhood rule, that is:
1 1 i
i wx b wx b + ≥
+ ≤ −
Where:
1 1
i i
y y
=
= − i=1, 2,,l (2)
The link weight between a certain element in the matrix and a certain neighborhood in (2) is:
( ) | |
i y wxi i b w x bi
ε
= + = + (3)Map-Min-Max process is given to
w
andb
in(3). Substitute || ||
w
w and || || b
w into
w
andb
, the interval of the Euclidean space is defined as fol-lows:|| || i i
wx b
w
δ
= + (4) [image:2.516.131.385.58.199.2]The allowable interval of the Euclidean space for the convergence of this matrix in Ri and R≠Ri is defined as follows:
Figure 1. MATLAB Distribute computing principle.
Based on statistical learning theory ( Structural risk minimization criterion ( Support Vector Machine
Good model generalization abilit STL)
SR y Witho
M) (
ut dimension restrictio )
n
statisticalvectormachine
i
min
δ
=
δ
i=1, 2,,l (5)Map between the cardinal number of error in the sample matrix (matrix elements) N and allowable interval of the Euclidean space for the convergence in
i
Rand R≠Ri is as follows [6]:
2
2 ( R) N
δ
≤ (6)
Where: R=max ||xi||i=1, 2,,l
As can be seen from (6), the cardinal number of er-ror in the sample matrix (matrix elements) is deter-mined by
δ
.δ
and the matrix elements present a negative correlation trend. Therefore, to find an opti-mal set whether δ is the biggest key factor. For example,ε =|wxi+b| 1= , then the link weightbe-tween two elements is 2| | 2
|| || || || i
wx b
w w
+
= . The above
expression is portrayed by logic, that is:
2 || || min
2
. . (i i ) 1, 1, 2, ,
w
s t y wx b i l
+ ≥ = (7)
This problem can be transformed into the problem of Lagrangian function [7]. That is:
2 1
1
( , , ) || || [ ( ) 1]
2
l
i i i i
i
w b a w a y wx b
=
Φ = −
∑
+ − (8)Due to the computing limitation, the problem is transformed into another form:
αi
1 1 1
1
max Q( ) ( )
2
l l l
i j i j i j
i i j
a a y y x x
α
= = =
=
∑
−∑∑
(9)Ultimately, obtain the optimized vector-valued function:
* *
1
( ) sgn[ ( ) ]
l
i i i
i
f x a y xx b
=
=
∑
+ (10)It is not easy to converge the matrix due to the presence of abnormal elements, thus correcting the model with this problem and introducing the theory in the classical optimization methods to correct the range as [5]:
2
|| || min
2
( ) 1
. . 0 i i i i w C y wx b s t ε ξ ζ + + ≥ − ≥
∑
(11)Constraint equation set is shown as follows:
0
1, 2, , 0 i i i a C i n a y ≤ ≤ = =
∑
(12)The above problem is the linear classification crite-rion. For the non-linear transformation criterion, it is unable to transform in its domain, which must be mapped to the domain Rn[8].
3 MODEL SOLUTION
The text is the image with features. And the features are divided into the features with statistical signifi-cance and architectural features. The architectural features can be modeled and classified by defining the basis matrix. The architectural features in the image can be extracted by
Sobel
operator. Its basic defini-tion is as follows: The pixel matrix at the boundary can be weighted for solving the extremum. The mathematical description is as follows:[ ( 1, 1) 2 ( 1, ) ( 1, 1)]
[ ( 1, 1) 2 ( 1. 1)]
x
S f x y f x y f x y
f x y f x y
= + + + + + + +
− − − + − + (13)
[ ( 1, 1) 2 ( 1, ) ( 1, 1)]
[ ( 1, 1) 2 ( 1. 1)]
x
S f x y f x y f x y
f x y f x y
= − + + − + + −
− + − + + − (14)
Training for the text randomly selected to be tested can not only ensure the randomness of training re-quirement, but also achieve the diversity of the train-ing samples, so as to prevent misstrain-ing detection. And the text randomly selected is as follows: Four score and seven years ago, our fathers brought forth on this continent, a new nation, conceived in Liberty, and dedicated to the proposition that all men are created equal.
The feature detection shall be given to the text by
Sobeloperator, so as to obtain a multi-dimensional
[image:3.516.267.469.504.591.2]feature matrix. The feature visualization can be given to the samples to be tested through the MATLAB platform, as shown in Figure 3.
Figure 3. Testing sample characteristics.
adjusted to ensure the detection accuracy and numeri-cal stability.
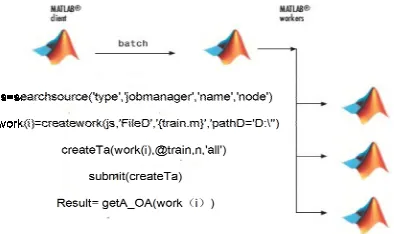
Three desktop computers in the group are intercon-nected with LAN. Detect the connectivity through Ping , operate GUI and start mdce. In the dispatching center, there is a need to add the host column and create Job detector and connecting points. In preparing the SVM function, there is a need to adopt parfor and other commands to extend the code to executable parallel state. This paper assigns SVM learning tasks to three computers. Its pseudo-code and schematic diagram is shown in Figure 4:
[image:4.516.269.466.189.306.2]Figure 4. Pseudo-code and schematic diagram.
There is no SVM parallel code in the toolbox, so train, Searchsource, Creatework and other independent function sets are self-prepared for computing. The features are extracted by Sobel operator, and the feature matrix is used as the training matrix to connect with SVM program and enter the test matrix for test-ing. This paper adopts jobs and tasks methods to create the parallel computing. The steps are as fol-lows:
(1) First, seek for a set distribution system by Searchsource and create the object scheduler js (i) by assigning the task management jobs.
(2) Create jobs on the object scheduler and name it as work (i); at the same time, define and train the text
feature matrix by train ( ); make definition and ad-dressing of the path and name of the module in the creatework ( ).
(3) Assign the work (i) as a set of jobs with the number of n; set up SVM parametric variations in train module and creatework module.
(4) Integrate the partitioning jobs into the back-ground through submit ( ), and complete the as-signed tasks.
(5) To take back the results and push to the host by the function of getA_OA( ) after the iterative compu-tation reaching the specified limit of error.
Figure 5. Schematic diagram of distributed computing pro-cess
The schematic diagram of the above process is shown in Figure 5. And the main code is shown as follows:
js=searchsource('type','jobmanager','name','node')
work(i)=creatework(js,'FileD','{train.m}','pathD='D:\'') createTa(work(i),@train,n,'all')
submit(createTa)
Result= getA_OA(work(i))
[image:4.516.54.250.193.306.2]SVM parameter selection in the third step has an important impact on the accuracy rate of learning. This paper adopts the random noise cross-validation method for optimization of parameters. After training,
[image:4.516.119.405.500.649.2]c= 0.25, g= 2, and the classification accuracy reaches 98%. The contour line of the parameter selection is shown in Figures 5 and 6.
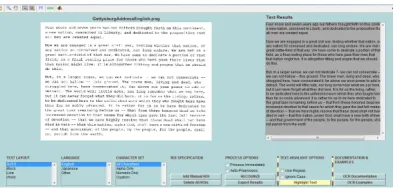
[image:5.516.56.253.187.281.2]The combination with the distributed algorithm and support vector machine requires using a large number of sub functions, so the user graph interaction inter-face is written to improve the universality of this model. Many functions can be free of being trans-ferred through writing GUI user interface, and there is only a need to click on the button for file leading-in and text detection. The prepared GUI interface and the final detection results are shown in Figure 7.
Figure 7. Final detection results.
4 CONCLUSION
As can be seen from the simulation results, the parallel computing based on the distributed algorithm can significantly improve the operational efficiency, and the SVM algorithm developed by the MATLAB par-allel computing toolbox is applied to achieve 98% of the model recognition rate. In terms of the parameter selection, the cross validation method introduced also has a good effect on the parameter selection. Moreo-ver, compared with the genetic algorithm, PSO algo-rithm and other complex algoalgo-rithms, the model is sim-
ple and effective. The establishment of the graphical user interface system improves the universality of the model and reduces the difficulty in use of the system, and it also has a good secondary development perfor-mance, thus bringing convenience to subsequent code optimization and module development for the users.
REFERENCES
[1] A. Suresh, & K. L. Shunmuganathan. 2012. Image Tex-ture Classification using Gray Level Co-Occurrence Ma-trix Based Statistical Features. European Journal of Sci-entific Research.
[2] J Canny. 1986. A computational approach to edge detec-tion. IEEE Transactions on Pattern Analysis and Ma-chine Intelligence.
[3] Yanqing Chen, & Ligong Wang. 2010. Sharp bounds for the largest eigenvalue of the signless Laplacian of a graph. Linear Algebra and Its Applications. (5). [4] S. Lee, & A. Nedic. 2013. Distributed random projection
algorith-m for convex optimization. IEEE Journal of Se-lected Topics in Signal Processing.
[5] C. H. Lee, D. D. Dershaw, D. Kopans, P. Evans, B. Monsees, D. Monticciolo, R. J. Brenner, L. Bassett, W. Berg & S. Feig. 2010. "Breast cancer screening with imaging: Recommendations from the Society of Breast Imaging and the ACR on the use of mammography, breast MRI, breast ultrasound, and other technologies for the detection of clinically occult breast cancer", J. Amer. Coll. Radiol., vol. 7, no. 1, pp: 18 -27.
[6] M. Bazzocchi, F. Mazzarella, C. Del Frate, F. Girometti & C. Zuiani 2007."CAD systems for mammography: A real opportunity? A review of the literature", Radiol Med., vol. 112, no. 3, pp: 329 -353