© 2018 IJSRCSEIT | Volume 3 | Issue 5 | ISSN : 2456-3307
Design and Implementation Radix based Booth Multiplier
Using High Speed Applications
M. Sandhya Rani1, K. Naveen Kumar Raju2
1M. Tech Student, Department of ECE, Vaagdevi Institute of Technology and Science, India
2Assistant Professor, Department of ECE, Vaagdevi Institute of Technology and Science, India
ABSTRACT
The multiplier dominated applications such as digital signal processing, wireless communications, and computer applications, high speed multiplier designs has always been a primary requisite. Radix 8 it is necessary to compute 3X, X being the multiplicand. In order to avoid the penalty due to this calculation, we propose decoupling it from the product and considering 3X as an extra operation within the application’s Dataflow Graph (DFG). Experiments show that typically there is enough slack in the DFGs to do this without degrading the performance of the circuit, which permits the efficient deployment of radix 8 multipliers that do not calculate the 3X multiple. Higher radix should produce even larger reductions, especially in terms of area .we are perform the improving the proposed work using the carry look ahead adder this adder is very fast adder then the other adders, it improves the delay of the proposed work. results are shown in XILINX 14.3ISE. Key words: DWT, Data flow graph, booth multiplier, verilog HDL.
I.
INTRODUCTION
Multiplication is one of the fundamental arithmetic operations utilized in nearly all sign processing algorithms of all instructions in abnormal clinical program are multiplications. In present state of affairs the elevated stage of integration added approximately by using modern VLSI generation has rendered possible the integration of many complex additives in a unmarried chip.
This has made the systems quicker and as a result beneficial for actual time packages like cell digital signal processing, multimedia applications, clinical computations etc. The developing market for rapid floating-factor processors, virtual sign processing chips, and pics processors has also created a demand for the excessive pace, vicinity-efficient multipliers. Current multiplier architectures range from small, low-overall performance shift and upload multipliers,
to massive, excessive performance array and tree multipliers. Taking this into attention various researchers have developed novel algorithms and circuit strategies to offer better speed and optimized use of silicon location. Multiplication is a three-step process.
Generation of partial products: Partial merchandise are generated from the inputs. Partial product is represented by means of a row of dots inside the figure. The partial product are all produced in parallel. There are several methods of generating the partial products.
are first summed up to offer simplest two rows (known as sum and carry rows) by way of the usage of special adder architectures,.
Addition of the two rows: Bring propagate adder: Sum and deliver rows together represent the result of multiplication. The final result is received handiest with the aid of adding sum and deliver rows together. The Discrete Wavelet Transform (DWT) performs a prime role in the fields of sign analysis, computer imaginative and prescient, object popularity, image compression and video compression trendy. The benefit of DWT over other traditional variations is that it plays multi resolution evaluation of signals with localization each in time and frequency. At present, many VLSI architectures for the DWT have been proposed to fulfill the requirements of real-time processing. The implementation of DWT in practical gadget has troubles. First, the complexity of wavelet transform is several times higher than that of DCT.
The principles and technique to contain multi speculation to HLS can be generalized and defined in detail. Although all the aforementioned techniques can be carried out immediately to sure DFGs which might be precisely inside the form of additive binary timber, there are cases where the DFG includes numerous additive trees as subcomponents. In such instances, the usage of multi speculation could be limited handiest to the ones additive bushes. For this cause, it is necessary to design an set of rules to pick out those additive structures wherein multi speculation may be applied, to broaden an automated technique to maintain the data path in a correct propagation addition is carried out afterwards. Every tree is processed till no greater deliver-propagation
additions are wanted. Regarding the scheduling and binding, due to the aforementioned operators’ restriction, a combined resource confined scheduling and binding algorithm has been carried out. In order to agenda operations, first they're ordered consistent with the inverse of their mobility, and then they are scheduled and bound if there's a appropriate unfastened FU. The electricity and power usage of the layout is completely characterized by the radix -8 booth multiplier Additionally,. The method takes advantage of unused Look Up Table inputs to lessen signal hobby in a layout at no additional good judgment fee. Though simplest restricted assessments have been completed using this DFG technique, initial improvements in energy and delay.
II.
EXISTING SYSTEM
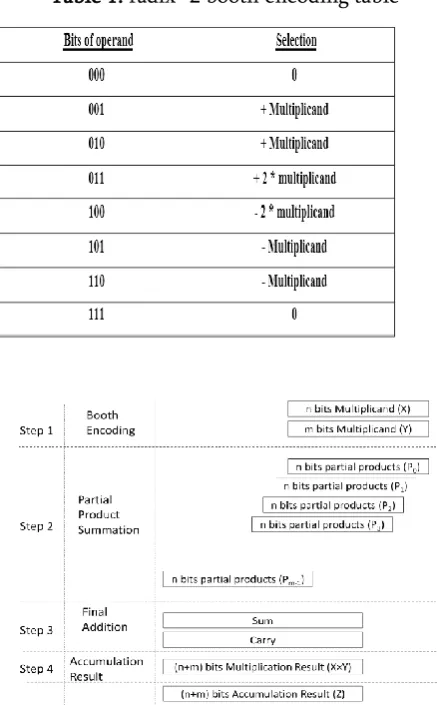
Radix -2 Booth multiplier:
A multiplier generator that creates a smaller range of partial merchandise will allow the partial product summation to be efficient and use much less hardware. The simple multiplication generator may be extended to lessen the wide variety of partial merchandise via grouping the bits of the multiplier into pairs, and selecting the partial merchandise from the set of 0, M, 2M or their complements, wherein M is the multiplicand. This reduces the quantity of partial merchandise, by means of a thing but also generates some extra-bits for the signal extension and the two’s complementation.
Multiplier and Accumulation structure the multiplier may be divided into four operation steps Booth set of rules, 2d step – partial product summation, third step – final addition, fourth step accumulation.
Step 1: Multiplication system achieved among n bits Multiplicand (X) and m bits Multiplier (Y).
Step 2: n bits Partial products (P0~Pj) might be generated after multiplying n bits and m bits.
Step three: Final addition between Partial products Summation (S) bits and Carry(C) bits.
Step 4: Accumulation results takes vicinity between multiplication effects (X*Y) and ultimately gets Accumulation Result (Z).
Table 1. radix -2 booth encoding table
Figure 1. Basic Arithmetic steps of Multiplication and Accumulation
Radix-4 Booth multiplier:
To keep away from the troubles in Radix -2 algorithm, attention of excessive speed multipliers is needed. One of the answers of figuring out excessive speed multipliers is to enhance parallelism which allows to lower the number of subsequent calculation levels. The original model of the Booth algorithm (Radix-2) had drawbacks .The variety of upload subtract operations and the range of shift operations are variable and come to be inconvenient in designing parallel multipliers. The set of rules turns into inefficient when there are remoted 1’s. These are conquer by the use of changed Radix-4 Booth multiplication algorithm.
This algorithm scans strings of 3 bits at a time as follows:
1) Extend the sign bit 1 role if important to ensure that n is even.
2) Append a 0 to the proper of the LSB of the multiplier.
3) According to the cost of every vector, each Partial Product will bhe zero, +y, y, +2y or -2y.
Table 2. Radix-4 Booth Encoding Table
At closing the addition of partial merchandise is finished by way of tree kind hybrid adder. The simulation end result of Radix-four Booth multiplier in which they may be binary inputs as input, one is multiplicand and any other one is multiplier. If both binary numbers are fantastic then it will perform sales space encoding.
Typically 3X is computed because the addition of 2X+X and −3X as its negation, increasing the essential direction of the multiplier. We leverage the lifestyles of slack cycles within the records course to compute those 3X multiples. In this way we are able to take benefit of the larger height reduction produced by the radix-eight recoding as opposed to the radix 4-based totally one.
III.
PROPOSED SYSTEM
Radix-8 booth multiplier:
The performance much like a traditional radix four Booth multiplier, but with place and energy ranging between the radix 4 and radix eight Booth implementations. Leveraging the slack that frequently seems when scheduling a DFG, on this paper we advocate precalculating the 3X tough multiples to installation highly efficient radix 8 Booth multipliers, achieving execution time financial savings with appreciate to both radix 4 and radix eight Booth implementation styles, while getting a place and an power lower than the radix -four implementation and near the radix eight one.
Table 3. Radix 8 Booth Recoder
Implementation:
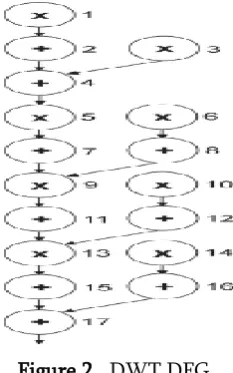
In order to reveal the standards of multi hypothesis over entire data paths, our techniques can be carried out to the Discrete Wavelet Transform (DWT) benchmark. Depicts the DWT DFG. Operations are labeled with numbers. Note that every operation desires two operands, but for the sake of clarity, primary enter’ arrows aren't proven.
Figure 2. DWT DFG
Figure 4. conventional scheduling with non-speculative.
Scheduling and Binding: Assignment of each operation to a time slot corresponding to a clock cycle or time interval.
Resource Allocation : Selection of the kinds of hardware additives and the variety for each kind to be included in the very last implementation.
Module Binding : Assignment of operation to the allocated hardware components.
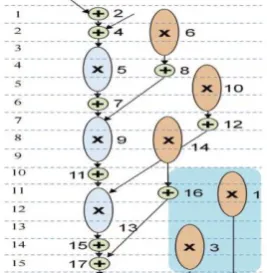
Figure 5. DWT scheduled and bound
Resource-constrained (RC) scheduling:
It includes the construction of an activity timetable, i.E. The dedication of a start and finish time for each project hobby, respecting the priority relations and the restricted availability of the renewable assets. Given a hard and fast of operations with a partial ordering which determines the precedence family members, a fixed of practical unit types, a kind
function to map the operations into the practical unit sorts, and resource constraints .For each purposeful unit type. - Find a (most appropriate) agenda for the set of operations that obeys the partial ordering and utilizes handiest the to be had practical units.
ASAP: As quickly as feasible - Sort the operations topologically in line with their facts /manipulate waft ,Schedule operations in the looked after order by means of setting them within the earliest viable manipulate step.
ALAP: As late as possible - Sort the operations topologically according to their data / control flow; - Schedule operations in the reversed order by placing them in the latest possible control step.
We are using ASAP technique for the RC scheduling.
Figure 6. DWT scheduled and bound with RC-module scheduling
Including The 3x Calculations:
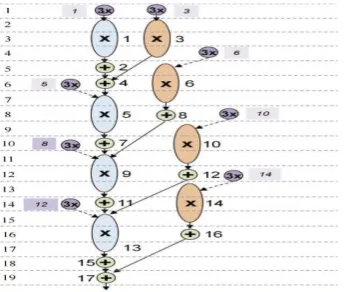
Figure 7. Correct inclusion of the 3X node
Figure 8. DWT scheduled and bound after the inclusion of the 3X multiples pre calculation
Carry look ahead adder:
We are using the adder carry look ahead adder .why because the adder is increase the speed of the addition . The ripple-carry adder, its limiting factor is the time it takes to propagate the carry. The carry look-ahead adder solves this problem by calculating the carry signals in advance, based on the input signals. The result is a reduced carry propagation time. To be able to understand how the carry look-ahead adder works, we have to manipulate the Boolean expression dealing with the full adder. We are using the carry look ahead adder that is faster adder then the ripple carry adder.
Adding is a hugely important operation. In addition to carrying out the additions that our programs specify, processors must also add for the following reasons:
Array access involves an addition, we need to
add the index to the base address of the array.
Object field accesses involve an addition, we
need to add the field offset to the base address of the object.
Most local variable accesses involve additions
as well, of a stack offset to the base stack address.
Change of control instructions involve adding
offsets to the current instruction address.
After every instruction, we need to add one to
the current instruction address to go on to the next instruction.
Figure 9
To make the carry generator from 4 bits to n bits, we need only add AND gates and inputs for the OR gate. The largest AND gate in the carry section has always n+1 inputs and the number of AND gates requirements is n. Therefore the design of a 16 bits adder needs the last carry generator section to have AND gates, where the biggest AND gate has inputs in group
The carry look ahead adder is a faster circuit for adding binary numbers because it reduces the propagation time of carry values.
Doing more work does not necessarily make
a circuit slower. Circuits are inherently parallel, and you only count serial operations when discussing speed.
Designing circuits involves trade-offs among
IV.
RESULTS
Block diagram:
Figure 10 Technology schimatic:
Figure 11 Simulation result:
Figure 12
Area:
Figure 13
V.
CONCLUSIONS
In order to overcome the delay limitation imposed by the 3X calculation, we first decouple this computation and introduce it as an independent operation in the DFG. The proposed flow achieves faster data paths than the previous both multipliers the with an energy consumption lower than and close in general to the radix 8 implementation.
VI.
REFERENCES
[1]. S. Gupta, A. Nicolau, N. D. Dutt, and R. K. Gupta, SPARK : aparallelizing approach to the high-level synthesis of digital circuits .Kluwer Academic Publishers, 2004.
[2]. P. Coussy and A. Morawiec, High-Level
Synthesis: From Algorithm toDigital Circuit, 1st ed. Springer Publishing Company, 2008.
[3]. A. A. D. Barrio, R. Hermida, and S. O. Memik, "Exploring the energy efficiency of multispeculative adders," in ICCD, 2013, pp. 309–315.
[4]. A. A. D. Barrio, R. Hermida, S. O. Memik, J. M. Mendias, and M. C.Molina, "Improving circuit performance with multispeculative additivetrees in high-level synthesis," Microelectronics Journal, vol. 45, no. 11,pp. 1470–1479, Nov. 2014.
[5]. P. M. Kogge and H. S. Stone, "A parallel algorithm for the efficientsolution of a general class of recurrence equations," IEEE Transactionson Computers, vol. C-22, no. 8, pp. 786–793, Aug 1973.
[6]. J. L. et al., "An algorithmic approach for generic parallel adders," inICCAD, 2003, pp. 734–740. [7]. P.-M. Seidel, L. McFearin, and D. Matula,
[8]. M. Ercegovac and T. Lang, Digital Arithmetic, 1st ed. MorganKauffman, 2003.
[9]. I. Koren, Computer Arithmetic Algorithms, 2nd ed. AK Peters, 2002.
[10]. E. J. King and E. E. Swartzlander, "Data-dependent truncation schemefor parallel multipliers," in Signals, Systems amp; Computers, 1997.Conference Record of the Thirty-First Asilomar Conference on, vol. 2,Nov 1997, pp. 1178–1182 vol.2.
[11]. H. J. Ko and S. F. Hsiao, "Design and application of faithfully rounded and truncated multipliers with combined deletion, reduction, truncation and rounding," IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 58, no. 5, pp. 304–308, May 2011.