Discourse Sense Classification from Scratch using Focused RNNs
Gregor Weiss, Marko Bajec University of Ljubljana
Faculty of Computer and Information Science Veˇcna pot 113, Ljubljana, Slovenia [email protected]
Abstract
The subtask of CoNLL 2016 Shared Task focuses on sense classification of multi-lingual shallow discourse relations. Ex-isting systems rely heavily on external resources, hand-engineered features, pat-terns, and complex pipelines fine-tuned for the English language. In this paper we de-scribe a different approach and system in-spired by end-to-end training of deep neu-ral networks. Its input consists of only sequences of tokens, which are processed by our novel focused RNNs layer, and followed by a dense neural network for classification. Neural networks implicitly learn latent features useful for discourse relation sense classification, make the ap-proach almost language-agnostic and in-dependent of prior linguistic knowledge. In the closed-track sense classification task our system achieved overall 0.5246
F1-measure on English blind dataset and
achieved the new state-of-the-art of0.7292
F1-measure on Chinese blind dataset.
1 Introduction
Shallow discourse parsing is a challenging natu-ral language processing task and sense classifica-tion is its most difficult subtask (Lin et al., 2014; Xue et al., 2015). Given text spans for argument 1 and 2, connective, and punctuation, the goal is to predict the sense of the discourse relation that holds between them. These text spans can appear in various orders, are not necessarily continuous, can spread across multiple sentences, and some-times connectives and punctuation are not even present. The CoNLL 2016 Shared Task (Xue et al., 2016) focuses on multilingual shallow dis-course parsing based on the English Penn
Dis-course TreeBank (PDTB) (Prasad et al., 2008) and Chinese Discourse TreeBank (CDTB) (Zhou and Xue, 2012). Evaluation is performed on separate test and blind datasets on the remote TIRA evalu-ation system (Potthast et al., 2014).
Existing systems for discourse parsing rely heavily on existing resources, hand-engineered features, patterns, and complex pipelines fine-tuned for the English language (Xue et al., 2015; Wang and Lan, 2015; Stepanov et al., 2015). Such features include word lists, part-of-speech tags, chunking tags, syntactic features extracted from constituent parse trees, path features built around connectives or specific words, production rules, dependency rules, Brown cluster pairs, features that disambiguate problematic connectives, and similar. Similar to our system, these pipelines sep-arately process explicit and non-explicit discourse relation types.
In this paper we describe a different approach and system inspired by end-to-end training of deep neural networks. Instead of engineering features and incorporating linguistic knowledge into them, its input consists of only sequences of tokens. They are processed by a neural network model that utilizes our novel focused recurrent neural networks (RNNs). It automatically learns latent features and how to allocate focus for our task. This way the system is independent of any prior knowledge, existing parsers, or external resources, what makes it almost language-agnostic. By only changing a few hyper-parameters, we successfully applied the same system to the English and Chi-nese datasets and achieved new state-of-the-art results on the Chinese blind dataset. Our sys-tem1 was developed in Python using the Keras li-brary (Chollet, 2015) that enables it to run on ei-ther CPU or GPU.
1http://github.com/gw0/conll16st-v34-focused-rnns/
The system architecture is described in Sec-tion 2, followed by details of layers in our neu-ral network and their training. Section 3 presents official evaluation results on English and Chinese datasets. Section 4 draws conclusions and direc-tions for future work.
2 System Overview
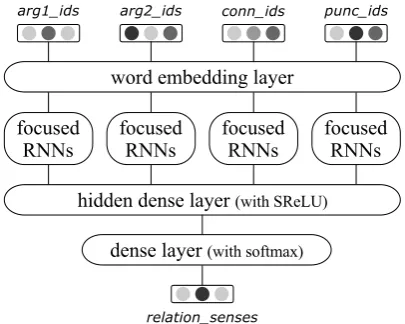
Our system for discourse sense classification of the CoNLL 2016 Shared Task consists of two sim-ilar neural network models build from three types of layers (see Figure 1). In the spirit of end-to-end training its input consists of only tokenized text spans that are mapped to vocabulary ids, which are processed by our neural network to classify each discourse relation into a sense category.
Important steps of our system are:
• Two modelsfor separately handling present and absent connectives in discourse relations.
• Input consists of four sequences of tokens mapped to vocabulary ids (for argument 1 and 2, connectives, and punctuations).
• Word Embeddings layer maps each token into a low-dimensional vector space using a lookup table.
• Focused RNNslayer focuses multiple RNNs onto different aspects of these sequences.
• Classificationis performed with a dense neu-ral network and logistic regression on top.
We used the same system on the English and Chinese datasets and each one uses two separate neural network models with only a few differences in its18parameters. Because of these differences, individual models are trained and applied com-pletely separately, although parts could be shared. Total number of trainable weights for both neural network models is1355661/1185006 for English and369972/1276761for Chinese.
2.1 Two models
[image:2.595.315.518.63.225.2]According to suggestions from related work we separately handle discourse relations with and without given connectives. For each case we train a separate neural network model with the same architecture, but different hyper-parameters. Throughout the paper we present those differences in parameters witha/b, whereapresents a value
Figure 1: Our neural network model for end-to-end training of sense classification. Two such models are separately trained for each language.
used for Explicit and AltLex relation types (where connectives are present) andbfor Implicit and En-tRel relation types (where connectives are absent).
2.2 Input
Initially a vocabulary of all words or tokens in the training dataset is prepared mapping each one to a unique token id. Four text spans representing in-dividual shallow discourse relations are tokenized and mapped into four sequences of vocabulary ids. Depending on the language these input se-quences are cropped to different maximal lengths, see Table 1. Out-of-vocabulary words that are not present during training are mapped to a special id.
Relation part English Chinese
Argument 1 100 500 Argument 2 100 500
Connective 10 10
Punctuation 2 2
Table 1: Maximal lengths of input sequences in our system for English and Chinese datasets.
2.3 Word embeddings
[image:2.595.339.494.511.582.2]regu-larization purposes we randomly drop embeddings during training with probability0.1.
Although the closed-track allowed the use of pre-trained skip-gram neural word embed-dings (Mikolov et al., 2013), we decided to learn them from scratch for each model separately.
2.4 Focused RNNs
These embeddings are processed by our novel fo-cused RNNs layer. Any recurrent neural network (RNN) can be used as its building block, but we decided to use the GRU layer (Chung et al., 2014). First a special focus RNN with4/6dimensions for English and4/5for Chinese is used to assign mul-tidimensional focus weights to the input sequence. For each focus dimension a separate RNN is ap-plied to the input sequence multiap-plied with corre-sponding focus weights. This way different RNNs can focus on different aspects of input sequences– in our case on different words and senses. Final outputs of these RNNs are concatenated and used in the classification layers. Our system uses sepa-rate RNNs with10/50dimensions for English and 20/30for Chinese. For regularization purposes we randomly drop0.33input gates of focus and sepa-rate RNNs,0.66recurrent connections of the focus RNN, and0.33of separate RNNs.
Note that our focused RNNs layer differs a lot from other attention mechanisms found in lit-erature. They are designed to only work with question-answering systems, use a weighted com-bination of all input states, and can focus on only one aspect of the input sequence.
2.5 Classification
Classification into discourse sense categories is performed using a dense neural network. Merged outputs of all focused RNNs are first processed by a dense layer with90/40 dimensions for English and100/90 for Chinese, followed by the SReLU activation function (Jin et al., 2015). The S-shaped rectified linear activation unit (SReLU) consists of piecewise linear functions and can learn both con-vex and non-concon-vex functions. Finally logistic re-gression, i.e. a dense layer followed by the soft-max activation function, is applied to get classi-fication probabilities. For regularization purposes we randomly drop connections before the second dense layers with probability0.5.
2.6 Training
Loss function suitable for our classification task is the categorical cross-entropy. Training is achieved with backpropagation and any gradient descent optimization, such as Adam optimizer. To paral-lelize and speed up the learning process we train in batches of 64 training samples. During train-ing we monitor the loss function on the validation dataset and stop if it does not increase in the last20 epochs. For regularization purposes we also intro-duce32random noise samples for each discourse relation during training. Weights used by the re-sulting system are those with the best encountered validation loss.
3 Evaluation
Datasets used by the CoNLL 2016 Shared Task consist of PDTB for English, CDTB for Chi-nese, and two unknown blind test datasets from Wikinews. For each language there is a train dataset for training models, validation dataset for monitoring the learning process, and test and blind test datasets for evaluating its performance.
Metric used for this subtask of CoNLL 2016 Shared Task is the F1-measure. It is computed
based on the number of predicted discourse rela-tion senses that match a gold standard relarela-tion.
3.1 Results for English
The training dataset from PDTB for English con-sists of1756documents with15246discourse re-lations that can be categorized into 15 different discourse relation senses.
Overall our system performs pretty well on all English datasets (see Table 2) despite not us-ing any external resources or hand-engineered features. As expected it performs best on the validation dataset, achieves slightly lower scores (0.5845) on the test dataset, and performs the worst on the blind dataset (0.5246) that contains a different writing style than PDTB. For only ex-plicit relations our system performs much better, close to inter-annotator agreement (91%) on de-velopment and test datasets, but without using any word lists or patterns like other systems. On the other hand non-explicit relations seem to be a much harder problem and the relatively small size of the training dataset does not contain enough in-formation.
Type Dev Test Blind
[image:4.595.73.289.61.161.2]Our only explicit 0.9181 0.8948 0.7525 Our only non-explicit 0.3458 0.3021 0.3308 Our all senses 0.6136 0.5845 0.5246 Best only explicit 0.9256 0.9022 0.7856 Best only non-explicit 0.4642 0.4091 0.3767 Best all senses 0.6797 0.6434 0.546 Table 2: OverallF1-measures of discourse relation
sense classification evaluated on different relation types on English datasets from our and best com-peting system of CoNLL 2016 Shared Task (Xue et al., 2016).
that our system performs consistently well on Contingency.Condition, Temporal.Async.Precedence,
and Temporal.Async.Succession, but fails on Com-parison.Concession, Expansion.Instantiation, and Expan-sion.Restatement.
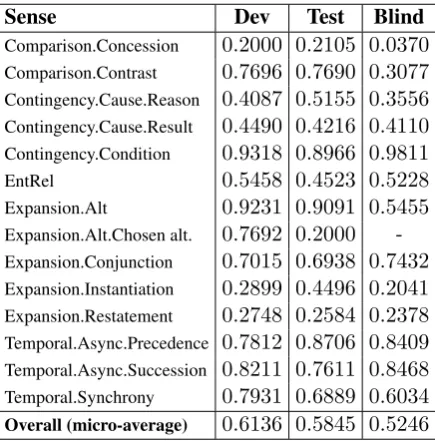
Sense Dev Test Blind
Comparison.Concession 0.2000 0.2105 0.0370
Comparison.Contrast 0.7696 0.7690 0.3077 Contingency.Cause.Reason 0.4087 0.5155 0.3556 Contingency.Cause.Result 0.4490 0.4216 0.4110
Contingency.Condition 0.9318 0.8966 0.9811 EntRel 0.5458 0.4523 0.5228 Expansion.Alt 0.9231 0.9091 0.5455
Expansion.Alt.Chosen alt. 0.7692 0.2000 -Expansion.Conjunction 0.7015 0.6938 0.7432 Expansion.Instantiation 0.2899 0.4496 0.2041
Expansion.Restatement 0.2748 0.2584 0.2378 Temporal.Async.Precedence 0.7812 0.8706 0.8409 Temporal.Async.Succession 0.8211 0.7611 0.8468 Temporal.Synchrony 0.7931 0.6889 0.6034 Overall (micro-average) 0.6136 0.5845 0.5246
Table 3: Per-senseF1-measures of discourse
rela-tion sense classificarela-tion evaluated on all relarela-tions on English datasets.
3.2 Results for Chinese
The training dataset from CDTB for Chinese con-sists of455documents with2445discourse rela-tions that can be categorized into10different dis-course relation senses.
Overall our system performs pretty well on all Chinese datasets (see Table 4) despite not using any external resources or hand-engineered fea-tures. Its overall performance is almost consis-tent across the validation, test (0.7011), and blind
(0.7292) datasets, although the last one probably contains a different writing style than CDTB. For only explicit relations our system performs much better on development and test datasets. For non-explicit relations the situation seems to be the op-posite. This inconsistencies indicate that the rel-atively small size of the training dataset does not contain enough information.
Type Dev Test Blind
[image:4.595.73.291.331.552.2]Our only explicit 0.9351 0.9271 0.7898 Our only non-explicit 0.6667 0.6407 0.7068 Our all senses 0.7206 0.7011 0.7292 Best only explicit 0.9610 0.9634 0.8039 Best only non-explicit 0.7353 0.7242 0.6338 Best all senses 0.7807 0.7701 0.6473 Table 4: OverallF1-measures of discourse relation
sense classification evaluated on different relation types on Chinese datasets from our and best com-peting system of CoNLL 2016 Shared Task (Xue et al., 2016).
Detailed per-sense analysis on all discourse re-lations is shown in Table 5. We see that our sys-tem performs consistently well onConjunction, Con-ditional, andTemporal, but does not perform at all on Alternative,EntRel, andProgression, because of
insuf-ficient number of samples.
Sense Dev Test Blind
Alternative - - 0.0000
Causation 0.6857 0.4545 0.6748 Conditional 1.0000 0.7500 0.7455 Conjunction 0.8175 0.8228 0.8145 Contrast 0.6957 0.8571 0.6612 EntRel 0.0000 0.0000 0.0000
Expansion 0.5641 0.4628 0.5436 Progression 0.0000 0.0000 0.0000 Purpose 0.8000 0.7857 0.5172
Temporal 1.0000 0.8649 0.7979 Overall (micro-average) 0.7206 0.7011 0.7292
Table 5: Per-senseF1-measures of discourse
rela-tion sense classificarela-tion evaluated on all relarela-tions on Chinese datasets.
4 Conclusion
fine-tuned pipelines. Our system consists of two neu-ral network models built from three types of lay-ers and is trained end-to-end. As a consequence it is almost language-agnostic and we have evalu-ated its performance on the English and Chinese datasets.
References
François Chollet. 2015. Keras. https://github.
com/fchollet/keras.
Junyoung Chung, Caglar Gulcehre, Kyunghyun Cho, and Yoshua Bengio. 2014. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv, pages 1–9.
Xiaojie Jin, Chunyan Xu, Jiashi Feng, Yunchao Wei, Junjun Xiong, and Shuicheng Yan. 2015. Deep Learning with S-shaped Rectified Linear Activation Units.
Ziheng Lin, Hwee Tou Ng, and Min-Yen Kan. 2014. A PDTB-Styled End-to-End Discourse Parser. Nat. Lang. Eng., 20(2):151–184.
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Distributed Representations of Words and Phrases and their Compositionality. Nips, pages 1–9.
Martin Potthast, Tim Gollub, Francisco Rangel, Paolo Rosso, Efstathios Stamatatos, and Benno Stein. 2014. Improving the Reproducibility of PAN’s Shared Tasks: Plagiarism Detection, Author Iden-tification, and Author Profiling. In Evangelos Kanoulas, Mihai Lupu, Paul Clough, Mark Sander-son, Mark Hall, Allan Hanbury, and Elaine Toms, editors,Inf. Access Eval. meets Multilinguality, Mul-timodality, Vis. 5th Int. Conf. CLEF Initiat. (CLEF 14), pages 268–299, Berlin Heidelberg New York, sep. Springer.
Rashmi Prasad, Nikhil Dinesh, Alan Lee, Eleni Milt-sakaki, Livio Robaldo, Aravind Joshi, and Bonnie Webber. 2008. The Penn Discourse TreeBank 2.0. Proc. Sixth Int. Conf. Lang. Resour. Eval., pages 2961–2968.
Evgeny Stepanov, Giuseppe Riccardi, and Ali Orkan Bayer. 2015. The UniTN Discourse Parser in CoNLL 2015 Shared Task: Token-level Sequence Labeling with Argument-specific Models. Proc. Ninet. Conf. Comput. Nat. Lang. Learn. - Shar. Task, (Dcd):25–31.
Jianxiang Wang and Man Lan. 2015. A refined end-to-end discourse parser. InProc. Ninet. Conf. Comput. Nat. Lang. Learn. Shar. Task, pages 17–24.
Nianwen Xue, Hwee Tou Ng, Sameer Pradhan, Rashmi Prasad, Christopher Bryant, and Attapol T. Ruther-ford. 2015. The CoNLL-2015 Shared Task on Shal-low Discourse Parsing. InProc. Ninet. Conf. Com-put. Nat. Lang. Learn. Shar. Task, pages 1–16.
Nianwen Xue, Hwee Tou Ng, Sameer Pradhan, Bon-nie Webber, Attapol Rutherford, Chuan Wang, and Hongmin Wang. 2016. The CoNLL-2016 Shared Task on Multilingual Shallow Discourse Parsing. In Proc. Twent. Conf. Comput. Nat. Lang. Learn. -Shar. Task, Berlin, Germany, aug. Association for Computational Linguistics.