2017 2nd International Conference on Computer Science and Technology (CST 2017) ISBN: 978-1-60595-461-5
A Method of Personalized Recommendation
Based on Differential Privacy
Jie LING and Bo MA
a*School of Computer, Guangdong University of Technology, Guangzhou, China
*Corresponding author
Keywords: Collaborative filtering, Differential privacy, Bayesian network.
Abstract. Research shows that an attacker can predict the user's rating record by observing the recommended results of the recommendation system, which will pose a great threat to the privacy of the user. Traditional recommendation system built on a collaborative filtering approach; it is difficult to provide a strict privacy protection. In this paper, a personalized recommendation method based on differential privacy preserving (DPP) is proposed. Bayesian network is used to optimize the addition of differential privacy noise, which can balance the data availability and privacy. Meanwhile, add the external attributes to construct the Bayesian network to semantically verify the recommended results, improve the recommended accuracy rate. The experimental results verified the feasibility and effectiveness of the method.
Introduction
Ramakrishnan et al. first proposed privacy security issues in the recommended system in 2001[1], after which Narayanan et al. identified some users by studying the data set released by Netflix and IMDB [2]. By observing the changes in the recommended results over a period of time, Calandrino et al. inferred the historical score and behavior of a user by combining the relevant background knowledge [3]. The security problem of the recommended system gradually become the research focus of privacy protection.
JianhuaLiu et al. proposed personalized information filtering recommendation method based on simple Bayesian classifier, which alleviates the sparseness and improves the accuracy of searching for the nearest neighbor [4]. AS Tewari et al. proposed a book recommendation system based on content filtering, collaborative filtering and association rule mining [5]. McSsherry et al. applied the differential privacy in the collaborative filtering recommendation system, which described the differential privacy treatment for the item-to-item covariance matrix, and expanded that it is feasible to implement differential privacy protection without the accuracy of the recommendation [6].
But the existing methods that combine privacy protection and recommended methods, there are still many limitations, mainly in two issues:
(1) The noises introduced by DPP can affect the usability of data. In order to implement privacy protection, this sacrifice can’t be avoided, but the vast majority of methods do not take into account the diversity of attributes. If the value of a property is too simple, adding too much noise can’t improve the security of the attributes; for the attribute which has large value range adding too little noise can’t protect data as well.
recommendation system is that the personalized semantics can’t be reflected, and the recommendation based on the association rules is only based on the relationship between the number of records and the type, and the rules are only on the surface. Ontology can be used to express semantics, but in the face of a large number of users, to build the appropriate ontology is scientific and effective yet to be verified.
In view of the above problems, this paper proposed a personalized recommendation method based on differential privacy, which combines the Bayesian network and collaborative filtering, and improves the use of differential privacy. The experimental results show that this method provides more personalized recommendation results while ensuring the security of privacy data.
Related Concepts Differential Privacy
When dataset and have the same attribute structure, the difference between them is no more than one record, the relationship is | Δ |≤ 1. We call and is a pair of adjacent datasets.
Definition 1: (ε-differential privacy) With a random algorithm M, is the set that consisted by all outputs of M. For any pair of adjacent data set and , and any subset ⊆S . If the algorithm M satisfies:
Pr[M( )∈ ] ≤ × Pr[M( )∈ ]. (1)
So, M provides ε - differential privacy protection. ε is a privacy budget.
In order to achieve differential privacy protection methods, Laplace mechanism is one of the most basic difference privacy Implementation Mechanisms.
Definition 2:(Laplace mechanism) A given data set D, with a function f: D→ , the function sensitivity is Δf, then the random algorithm M(D) = f(D) + Y provides a differential privacy protection, wherein Y ~ Lap (Δ f / ε) is a random noise that obedience scale parameter Δf/εof Laplace distribution.
Collaborative Filtering
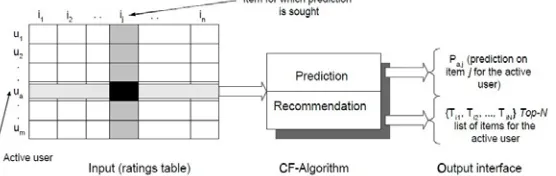
[image:2.612.180.458.523.611.2]Collaborative filtering recommended the basic idea is based on the user's preferences and other similar interests of the user's choice to recommend the project to the user. The basic process shown in Figure 1:
Figure 1. Collaborative Filtering process.
= | |
| | | | (2)
Where G (u) represents the set of items that user U likes, and G (v) is the collection of items that user V likes.
Personalized Recommendation Method Method Model
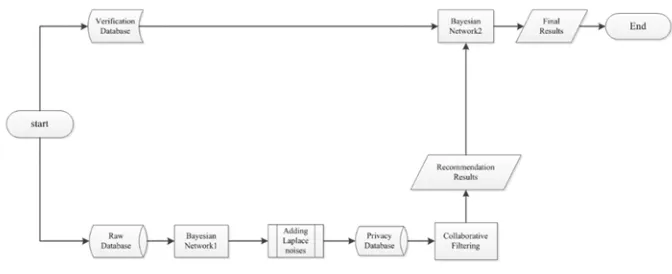
[image:3.612.137.473.357.494.2]Semantic verification and differential privacy noise is the two key steps of this recommended method. In this paper, we have a property to represent the degree of preference of the project when the verification database is constructed. The attribute values are: like, generally, dislike. Obtain the user score record from the network to build the database DB1, and according to DB1 to establish the Bayesian network N1, combined with DB1 and N1, adding Laplace noise, get the privacy dataset P. At the same time, according to the questionnaire survey and the results of the relevant comments, build the verification database DB2 and the establishment of Bayesian calibration network N2, using collaborative filtering recommendation algorithm in P to recommend, and then use the Bayesian calibration network N2 on the recommended results of the school Check, reject the recommended results that do not meet the requirements, and get more credible recommendations. The model of this method is shown in Figure 2:
Figure 2. Personalized recommendation method model.
Method implementation
Let the model in the following scenario: recommend the set of items to the user , where ∈ , is the probability that the item is recommended. The method is divided into two phases, the steps are as follows:
Phase I:
Input: Dataset , parameter k. Output: Privacy data set P. 1. Initialize P = ∅;
2. Constructing Bayesian Network by ; 3. For i = k + 1 to d:
4. Construct the joint distribution of attribute node , It is Pr[ , ];
6. The negative values in Pr[ , ] are zeroed and normalized; 7. Pr[ | ] is extracted from Pr[ , ] and P is added; 8. End for;
9. For i = 1 to k:
10. Pr[ | ] is extracted from Pr[ , ] and P is added; 11. End for;
Get the privacy data set P. Phase II:
Input: Dataset .
Output: Recommended result .
1. The Bayesian verification network is constructed by .
2. Using the cosine recognition formula, we find the user with the highest similarity to in , where x is set as needed.
3. Select in , G_i as the input of , get the probability of to , and calculate the average result of ;
4. Sort the results of ̅ select the maximum value of the n kinds of items composed of recommended to the user ;
Get the recommendation result.
Experiments and Results Analysis
The experimental dataset uses a recognized MovieLens dataset in the recommended field, containing 943 users for a total of 100,000 ratings for 1682 movies, with a score of not less than 20 for each user, with a score of 1-5. The checking dataset selected 300 records, in the school for students to conduct a questionnaire survey, 300 records, including professional categories, gender, preferences for a certain type of film.
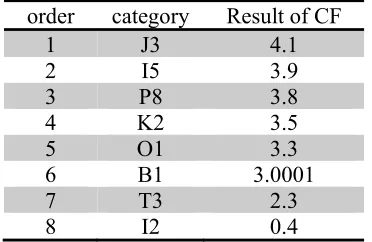
[image:4.612.214.400.446.567.2]Part of collaborative filtering recommendation are shown in Table 1:
Table 1. Part of collaborative filtering recommendation.
order category Result of CF
1 J3 4.1
2 I5 3.9
3 P8 3.8
4 K2 3.5
5 O1 3.3
6 B1 3.0001
7 T3 2.3
8 I2 0.4
Table 2. Part of results after Semantic verification.
order category Result of CF “Likes” “General “Dislike”
1 P8 3.8 0.00041 0.000422 0.00066
2 K2 3.5 0.00012 0.000432 0
3 J3 4.1 0.00008 0.0005 0
4 O1 3.3 0 0.000422 0.00088
5 T3 3.0001 0 0 0.03334
6 B1 3.00001 0 0 0.000218
7 I5 2.3 0 0 0
8 I2 0.4 0 0 0
Table 2 shows part of the results of the Bayesian network semantic check, "likes", "general", "dislikes" are preferences for users. It can be seen from Table 2 that the recommended order of Bayesian network calibration is different from that of collaborative filtering. Analysis found that compared to the simple collaborative filtering recommendation, joined the preferences field, the semantic check after the recommendation results are more personalized.
In the differential privacy protection, the privacy protection budget ε is an important index to determine the level of privacy protection. The level of privacy protection is inversely proportional to the value of ε. In the experiment, we set the privacy protection budget ε to [0.1, 1]. In this paper, the root mean square error (RMSE), which is recognized in the recommended field, is used as the evaluation criterion:
RMSE = | |∑ , ̂ (3)
[image:5.612.203.431.455.699.2]Where is the true score of the user for the project , ̂ is the predicted score, T is the training data set,| |represents the size of the training data set, and the lower RMSE value means higher predictive accuracy.
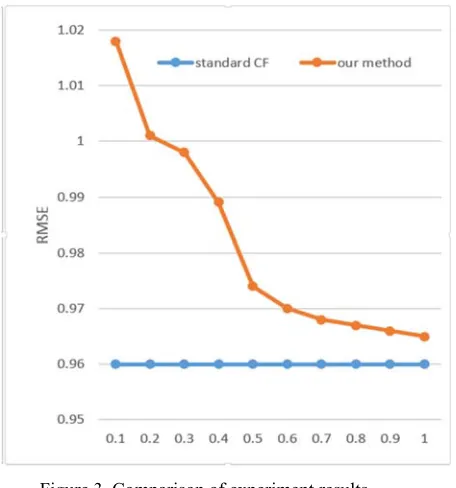
Figure 3. Comparison of experiment results.
according to the ratio of 8: 2, which is divided into five groups of unrelated training data and test data in the same way. Respectively, in the data set on the application of this algorithm and the object-based CF algorithm, the experimental results in the five sets of data on the results of the mean. Figure 3 shows the results of the comparative experiment, we can see that with the increase in privacy budget, the availability of data increased. At ε< 0.5, the RMSE value decreases sharply with the increase of ε. This indicates that the effect of noise on the usability of the data. When ε ≥ 0.5, the result of the algorithm tends to be gentle, that is, the method can achieve good compromise between data availability and privacy protection under the general privacy protection requirement.
Conclusions
Privacy protection is a very challenging issue in the recommended system: in order to provide a better user experience, we need to continuously improve the recommended accuracy; on the other hand, the precise recommendation will expose the user's privacy information, which will lead to loss of users’ trusts in the recommendation system. Therefore, it is important to do the balance between precision recommendation and privacy protection. In this paper, the application of differential privacy technology in the recommendation system, according to the Bayesian network node attribute in the data set of the importance - weight to join the noise, while use another Bayesian network to verify the results of the test results show that, not only to ensure that the privacy protection, but also let the recommended results more personalized, better accuracy. Compared with the existing research results, the feasibility and effectiveness of this method has been verified.
Acknowledgments
This work is supported by the science and technology project of Guangdong Province
(No.2015B010128014,2015B090906015,2014B090908010) and science and
technology the project of Guangzhou (No.201604010077,201604010048).
References
[1] Ramakrishnan, N, et al. Privacy risks in recommender systems[J]. IEEE Internet Computing, 2001, 5(6): 54.
[2] Narayanan, A., Shmatikov, V. How to break anonymity of the Netflix prize dataset[J]. arXiv preprint cs/0610105, 2006.
[3] Calandrino, J. A., et al. " You Might Also Like:" Privacy Risks of Collaborative Filtering[C]//Security and Privacy (SP), 2011 IEEE Symposium on. IEEE, 2011: 231-246.
[4] Liu, J. A Personalized Information Filtering Method Based on Simple Bayesian Classifier[M]//Advances in Electronic Commerce, Web Application and Communication. Springer Berlin Heidelberg, 2012: 609-614.
[5] Tewari, A. S., et al. Book recommendation system based on combine features of content based filtering, collaborative filtering and association rule mining[C]//Advance Computing Conference (IACC), 2014 IEEE International. IEEE, 2014: 500-503.
bayesian networks[C]//Proceedings of the 2014 ACM SIGMOD international conference on Management of data. ACM, 2014: 1423-1434.
[7] Zhang, X., Wu, Y., Wang, X. Differential privacy data release through adding noise on average value[C]//International Conference on Network and System Security. Springer Berlin Heidelberg, 2012: 417-429.
[8] Bielza, C., Larrañaga, P. Discrete Bayesian network classifiers: a survey[J]. ACM Computing Surveys (CSUR), 2014, 47(1): 5.